TSN泛读【Temporal Segment Networks: Towards GoodPractices for Deep Action Recognition】
目录
0、前沿
1、标题
2、摘要
3、结论
4、重要图表
5、解决了什么问题
6、采用了什么方法
7、达到了什么效果
0、前沿
泛读我们主要读文章标题,摘要、结论和图表数据四个部分。需要回答用什么方法,解决什么问题,达到什么效果这三个问题。 需要了解更多视频理解相关文章可以关注视频理解系列目录了解当前更新情况。
TSN论文下载:
https://arxiv.org/pdf/1608.00859.pdf https://arxiv.org/pdf/1608.00859.pdf
https://arxiv.org/pdf/1608.00859.pdf
1、标题
Temporal Segment Networks: Towards Good Practices for Deep Action Recognition
时间分段网络:深度视频动作识别实用技巧
2、摘要
Deep convolutional networks have achieved great success for visual recognition in still images. However, for action recognition in videos, the advantage over traditional methods is not so evident. This paper aims to discover the principles to design effective ConvNet architectures for action recognition in videos and learn these models given limited training samples.
Our first contribution is temporal segment network (TSN), a novel framework for video-based action recognition. which is based on the idea of long-range temporal structure modeling. It combines a sparse temporal sampling strategy and video-level supervision to enable efficient and effective learning using the whole action video.
The other contribution is our study on a series of good practices in learning ConvNets on video data with the help of temporal segment network. Our approach obtains the state-the-of-art performance on the datasets of HMDB51 (69.4%) and UCF101 (94.2%). We also visualize the learned ConvNet models, which qualitatively demonstrates the effectiveness of temporal segment network and the proposed good practices.
https://github.com/yjxiong/temporal-segment-networks.
深度卷积网络在静态图像的视觉识别中已经取得了巨大的成功。但是在视频的动作识别任务中,与传统方法相比优势并不明显。本文旨在发现视频的动作识别任务中,设计一个有效卷积网络架构的原则,并在有限的训练样本下学习这些模型。
我们的第一个贡献是TSN,它是一个新颖的视频动作识别框架。这是基于long-rang时间结构模型的一个想法。它结合一个稀疏的时间抽样策略和视频级别的监督,使得能够高效并有效的学习使用整个行动视频。
我们的另一个贡献是,我们研究了一系列在视频数据卷积网络上好用的技巧来优化时间分段网络学习。我们的方法获取SOTA,HMDB51(69.4%),UCF101(94.2%)。我们还将学习到的卷积网络模型可视化,定性地证明了时间分段网络的有效性和所提出的良好实践。
3、结论
In this paper, we presented the Temporal Segment Network (TSN), a video-level framework that aims to model long-term temporal structure. As demonstrated on two challenging datasets, this work has brought the state of the art to a new level, while maintaining a reasonable computational cost. This is largely ascribed to the segmental architecture with sparse sampling, as well as a series of good practices that we explored in this work. The former provides an effective and efficient way to capture long-term temporal structure, while the latter makes it possible to train very deep networks on a limited training set without severe overfitting.
这篇文章中,我们提出的TSN,是一个旨在建模长时间视频结构的框架。正如在两个具有挑战性的数据集上所展示的那样,这项工作将SOTA提升到了一个新的水平,同时保持了合理的计算成本。这在很大程度上归因于分段式结构与稀疏抽样,以及我们在这项工作中探索的一系列良好实践。前者提供了一种有效且高效的方法来捕获长时间结构,而后者使在有限的训练集上训练非常深的网络成为可能,而不会出现严重的过拟合。
4、重要图表
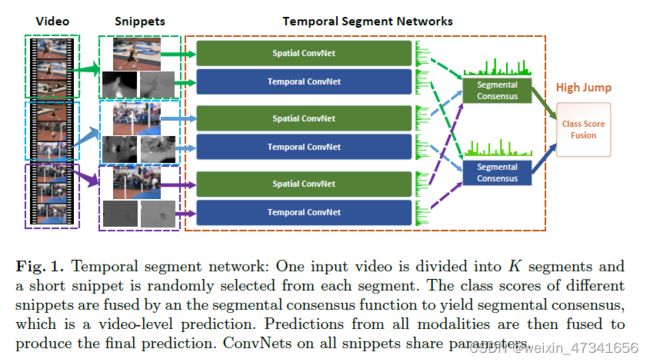
图1:时间分段网络:一个视频被分为K段(segment),从每段中随机选取一小片(snippet)。利用片段共识函数融合不同snippet的分类分数,得到片段共识,即视频级预测。然后将来自所有模式的预测融合,产生最终的预测。卷积在所有snippets上共享参数。

图2:4中输入模式:RGB图片,RGB差分,光流场,弯曲光流场
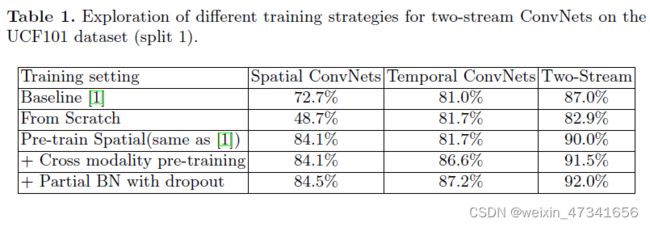
表1:不同训练策略的双流卷积网络在UCF101数据集的研究
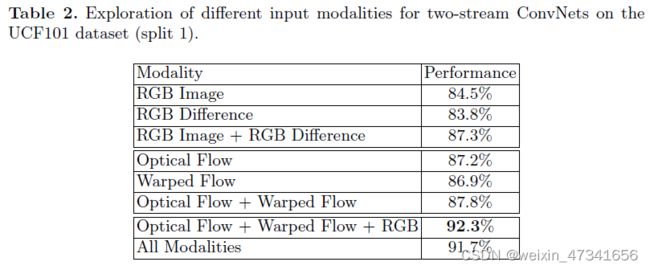
表2:不同输入模式的双流卷积网络在UCF101数据集的研究

表3:不同共识函数的时间分段网络在UCF101数据集的研究
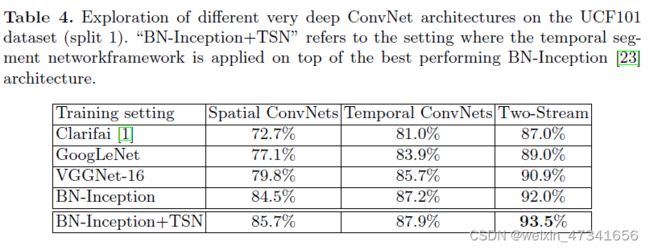
表4:不同卷积网络架构在UCF101数据集的研究
“BN-Inception+TSN”指的是将时间分段网络框架应用于性能最好的BN-Inception架构之上的设置。
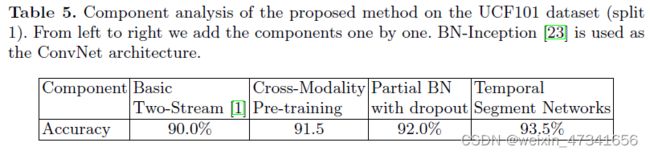
表5:在UCF101数据集上对该方法进行组分分析。从左到右依次叠加,网络使用了BN-Inception。

表6: 比较TSN和其他SOTA方法。我们分别给出使用两种输入(RGB+Flow) 和三种输入模式(RGB+Flow+Warped Flow)的结果。

图3:使用DeepDraw可视化动作识别卷积模型。我们比较了三种设置(1)不用预训练(2)使用预训练(3)使用时间分段。对于空间卷积,我们绘制了三个生成的可视化彩色图像。对于时间卷积,我们用灰度绘制x(左)和y(右)方向的流图。需要说明的是,所有这些图像都是由纯粹随机的像素生成的。
5、解决了什么问题
深度卷积网络在图片分类任务上很厉害,视频分类上很拉跨。
6、采用了什么方法
使用TSN和一些好的技巧
7、达到了什么效果
刷新视频分类SOTA,HMDB51(69.4%),UCF101(94.2%)。可以处理长视频