Temporal Segment Networks:Towards Good Practices for Deep TSN论文精读笔记
Temporal Segment Networks:Towards Good Practices for Deep TSN论文精读笔记
这篇论文首先解决了双流卷积网络只能处理较短视频帧的缺陷,论文的主要贡献是提出了Temporal Segment Network,他基于长范围时间结构建模,结合了稀疏时间采样策略和视频级别监督,使得神经网络能够处理较长的时间段,且效果较好。其次,论文还确定了很多很好用的技巧,比如如何进行数据增强,如何完成模型的初始化,如何使用网络,如何防止过拟合,等等。
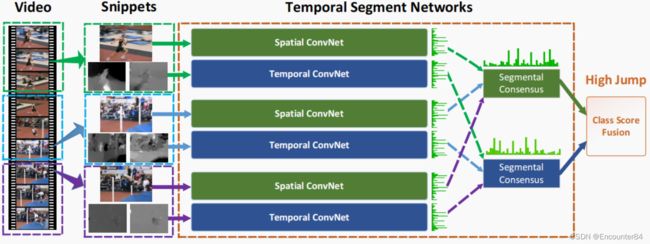
TSN的网络结构如下图所示,它也是由双流网络衍生而来。two-stream卷积网络的一个问题是它无法对长时间范围的视频进行建模,因为它的空间网络只处理一帧图像,而时间网络处理单张空间图像之后的密集帧,因此它对于时间上下文的访问是有限的。对于比较长的动作视频来说,双流卷积网络这样密集采样的方式就表现的不太好,因此,作者提出了TSN,也就是从整个视频中稀疏地采样一系列短片段的方式。
由下图可知,作者将一段视频分成了K个部分segment(图示中是3个部分),从每个部分中随机抽取一张图像帧和图像帧之后的几帧光流帧snippet,将图像帧和光流帧分别输入空间流和时间流卷积神经网络,虽然从图例上来看,有三个双流网络,但是这三个双流网络都是共享参数的。这样,视频的每个部分都会得到空间流和时间流的两个概率分布,接着,k个部分的空间网络得出的概率分布和时间网络得出的概率分布分别采用段共识函数The segmental consensus function进行融合来产生段共识segmental consensus,也就是将结果进行一个融合,这个段共识函数可以是加乘,也可以是average或者max,甚至也可以用LSTM来做一个预测,总之就是将每个snippet的预测结果进行一个融合。最后,空间流卷积网络得出的结果再和时间流网络得出的结果进行加权平均,就能得到最后的分类结果了。
用数学公式来表示的话是这样:给定一段视频V,把他按相等间隔分成K段 { S 1 , S 2 , ⋯ , S K } \left\{S_{1}, S_{2}, \cdots, S_{K}\right\} {S1,S2,⋯,SK},接着,TSN按照如下方式对一系列片段进行建模:
TSN ( T 1 , T 2 , ⋯ , T K ) = H ( G ( F ( T 1 ; W ) , F ( T 2 ; W ) , ⋯ , F ( T K ; W ) ) ) \operatorname{TSN}\left(T_{1}, T_{2}, \cdots, T_{K}\right)=\mathcal{H}\left(\mathcal{G}\left(\mathcal{F}\left(T_{1} ; \mathbf{W}\right), \mathcal{F}\left(T_{2} ; \mathbf{W}\right), \cdots, \mathcal{F}\left(T_{K} ; \mathbf{W}\right)\right)\right) TSN(T1,T2,⋯,TK)=H(G(F(T1;W),F(T2;W),⋯,F(TK;W)))
其中 ( T 1 , T 2 , ⋯ , T K ) (T_{1}, T_{2}, \cdots, T_{K}) (T1,T2,⋯,TK)代表片段序列,每个片段 T k T_k Tk从它对应的段 S k S_k Sk中随机采样得到。 F ( T k ; W ) F\left(T_{k} ; W\right) F(Tk;W) 函数代表采用 W W W 作为参数的卷积网络作用于短片段 T k T_{k} Tk ,函数返回 T k T_{k} Tk 相对于所有类别的得分。段共识函数 G G G 结合多个短片段的类别得分输出以获得他们之间关于类别假设的共识。基于这个共识,预测函数 H H H 预测整段视频属于每个行为类别的概率(本文 H H H 选择了Softmax函数)。结合标准分类交叉熵损失 ,关于部分共识的最终损失函数 G G G 的形式为:
L ( y , G ) = − ∑ i = 1 C y i ( G i − log ∑ j = 1 C exp G j ) \mathcal{L}(y, \mathbf{G})=-\sum_{i=1}^{C} y_{i}\left(G_{i}-\log \sum_{j=1}^{C} \exp G_{j}\right) L(y,G)=−i=1∑Cyi(Gi−logj=1∑CexpGj)
其中, C C C 是行为总类别数, y i y_{i} yi 是类别 i i i 的groundtruth,实验中片段的数量 K K K 设置为 3 。本工作中共识函数 G G G 采用最简单的形式,即 G i = g ( F i ( T 1 ) , … , F i ( T K ) ) G_{i}=g\left(F_{i}\left(T_{1}\right), \ldots, F_{i}\left(T_{K}\right)\right) Gi=g(Fi(T1),…,Fi(TK)) ,采用用聚合函数 g g g从所有片段中相同类别的得分中推断出某个类别分数 G i G_{i} Gi 。聚合函数 g g g 采用均匀平均法来表示最终识别精度。
T S N \mathrm{TSN} TSN 是可微的,至少有次梯度,这个由 g g g 函数的选择决定。这使我们可以用标准反向传播算法,利用多个片段来联合优化模型参数 W W W 。在反向传播过程中,模型参数 W W W 关于损失值 L L L 的梯度为:
∂ L ( y , G ) ∂ W = ∂ L ∂ G ∑ k = 1 K ∂ G ∂ F ( T k ) ∂ F ( T k ) ∂ W \frac{\partial \mathcal{L}(y, \mathbf{G})}{\partial \mathbf{W}}=\frac{\partial \mathcal{L}}{\partial \mathbf{G}} \sum_{k=1}^{K} \frac{\partial \mathcal{G}}{\partial \mathcal{F}\left(T_{k}\right)} \frac{\partial \mathcal{F}\left(T_{k}\right)}{\partial \mathbf{W}} ∂W∂L(y,G)=∂G∂Lk=1∑K∂F(Tk)∂G∂W∂F(Tk)
其中,K是TSN使用的段数。TSN从整个视频中学习模型参数而不是一个短的片段。与此同时,通过对所有视频固定 K K K ,作者提出了一种稀疏时间采样策略,其中采样片段只包含一小部分帧。与先前使用密集采样帧的方法相比,这种方法大大降低计算开销。
这篇论文还有一个巨大的贡献就是提出了几种深度学习训练中好用的技巧,以避免过拟合:
1.Cross Modality Pre-training,这里Modality指的就是图像和光流,也可以理解成多模态。作者这里的意思是,图像里面可以有ImageNet这么大的一个数据集做预训练,所以在网络训练的时候,可以直接在上面进行微调。但是在光流网络上,并没有一个很大的光流数据集去做预训练,如果只从一个小的数据集上面从头训练的话,可能效果不会太好,那么怎样才能去做一个有效的预训练呢?作者认为可以把ImageNet上面预训练好的模型迁移给光流模型,唯一的区别在于,图像卷积网络接受的RGB图像,只有RGB三个channel,而光流网络的输入是10张光流图,总共有20个channel,为了解决这个区别,作者改变了光流卷积网络的第一层,他把RGB三个channel预训练好的参数进行了一下平均,这样三个channel就变成了一个通道,这样需要20个channel的话,直接复制20遍就可以了。首先,通过线性变换将光流场离散到从0到255的区间,这使得光流场的范围和RGB图像相同,然后,修改RGB模型第一个卷积层的权重来处理光流场的输入。作者发现这种方式工作效率很好,可以提升五六个点。
2.Regularization Techniques,这里作者讲了一个模型正则化的技巧。Batch Normalization将估计每个batch内的激活均值和方差,并使用它们将这些激活值转换为标准高斯分布。这一操作虽可以加快训练的收敛速度,但由于要从有限数量的训练样本中对激活分布的偏移量进行估计,也会导致过拟合问题,作者因此提出了一种partial BN的方法,因为本来的BN可以微调的话,数据集比较小的话,一调就又可能会过拟合,但是如果把所有BN层都冻住均值和方差参数的话,迁移学习的效果也会比较差,因此作者提出,除了第一层BN层(因为网络输入改变了,所以第一层必须要做出调整,才能适应新的输入or数据集,由于光流的分布和RGB图像的分布不同,第一个卷积层的激活值将有不同的分布,于是,我们需要重新估计的均值和方差),后面的BN层全部冻住,以避免过拟合。与此同时,在BN-Inception的全局pooling层后添加一个额外的dropout层,来进一步降低过拟合的影响。dropout比例设置:空间流卷积网络设置为0.8,时间流卷积网络设置为0.7。
3.Data Augmentation因为行为识别的数据集比较小,所以数据增强的方式很有用处。作者提出了两种数据增强的方式:角裁剪corner cropping和尺度抖动scale jittering,corner cropping是因为作者在进行随机裁剪时,随机裁剪出来的图形经常在图像的正中间或者中间附近,很难剪裁到图像边角的位置,所以作者在这篇论文中强制在图像的边角进行裁剪。第二种时scale jittering,作者希望改变输入图像的长宽比来进行数据增强。作者的方法是:首先将输入的图片resize到256X340,裁剪区域的宽和高随机从{256,224,192,168} 中选择,意思就是可能会裁剪出256X256的图像,也有可能裁剪出256X224的图像,这样裁剪方式就比较多样化,一共有16种裁剪方式。
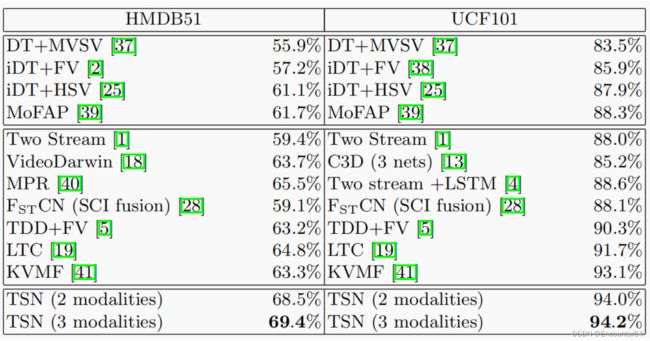
最后的实验结果细节我没有仔细看,还是可以发现作者提出的TSN表现SOTA: