街景字符编码识别Task03-CNN发展介绍及Pytorch构建CNN模型
Task03:字符识别模型
学习目标
- 学习CNN基础知识和发展史
- 使用Pytorch框架构建CNN模型,并完成训练
目录
一、卷积神经网络
二、卷积神经网络模型发展
1.LeNet 模型
2.AlexNet模型
3.VGG模型
4.GoogLeNet模型
5.ResNet模型
三、Pytorch构建CNN模型
1.定义CNN模型结构
2.定义好训练、验证和预测模块
3.迭代训练和验证模型
四、参考
一、卷积神经网络
卷积神经网络(Convolutional Neural Network)简称CNN,是图像识别领域的深度神经网络模型。
CNN中的二维卷积核,常用于处理图像数据。如下最下面蓝色的代表输入图片,图片上有窗口为3x3的卷积核在扫描图片,图片输入和卷积核做互相关运算,并加上一个标量偏置来得到上方绿色的特征图谱输出。卷积层的模型参数包括卷积核和标量偏置,可认为下面的卷积核有3x3+1=10个参数。
卷积核移动时有填充和步幅,通过卷积核的移动,可以对给定形状的输入改变其输出形状。填充(padding)是指在输入图片的高和宽的两侧填充元素(通常是0元素)。在互相关运算中,卷积核在输入数组上滑动,每次滑动的行数与列数即是步幅(stride)。
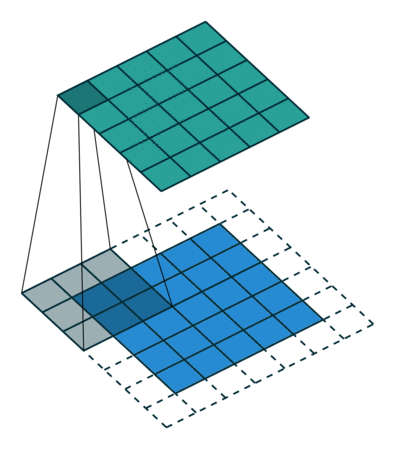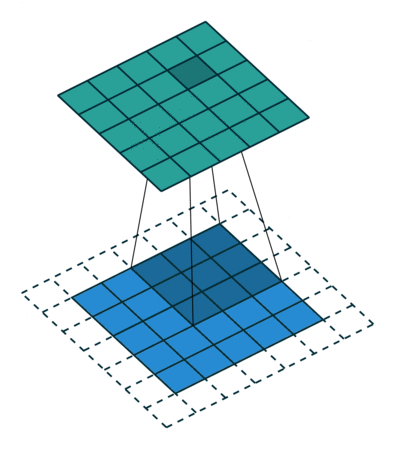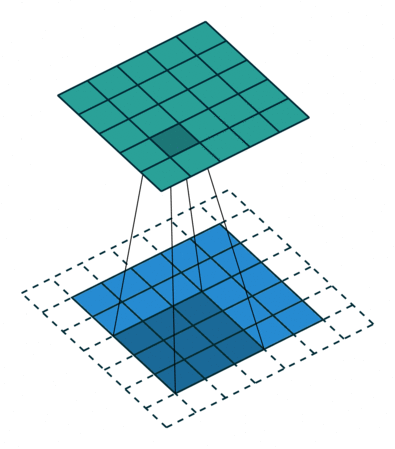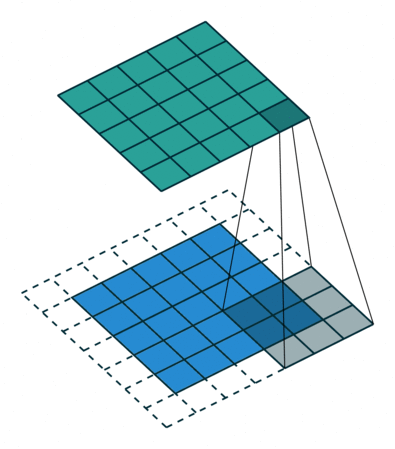
窗口为3x3的卷积核在图片上扫描与运算的过程如下:
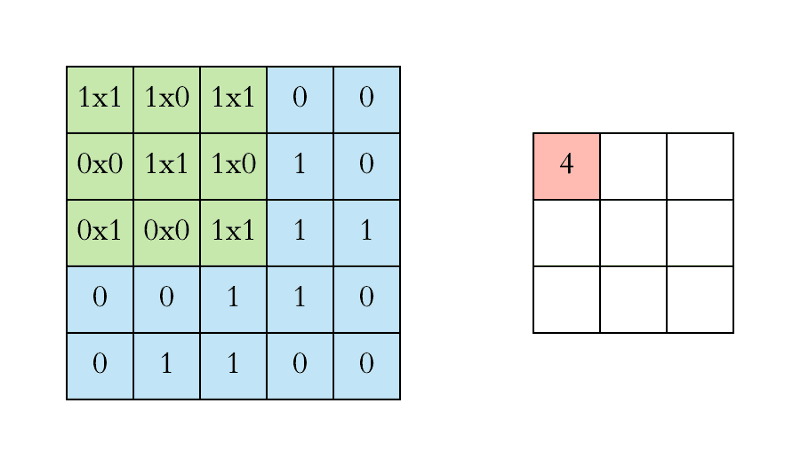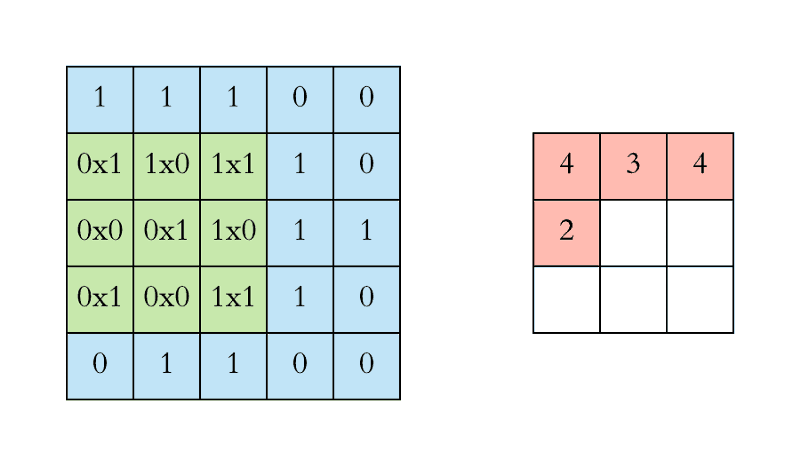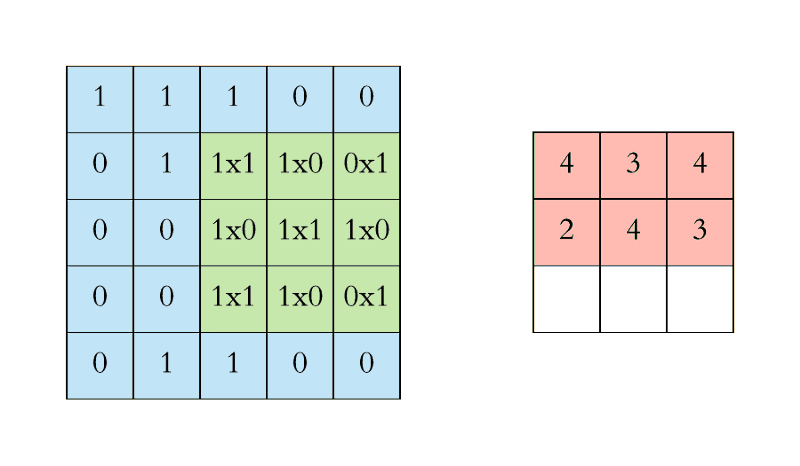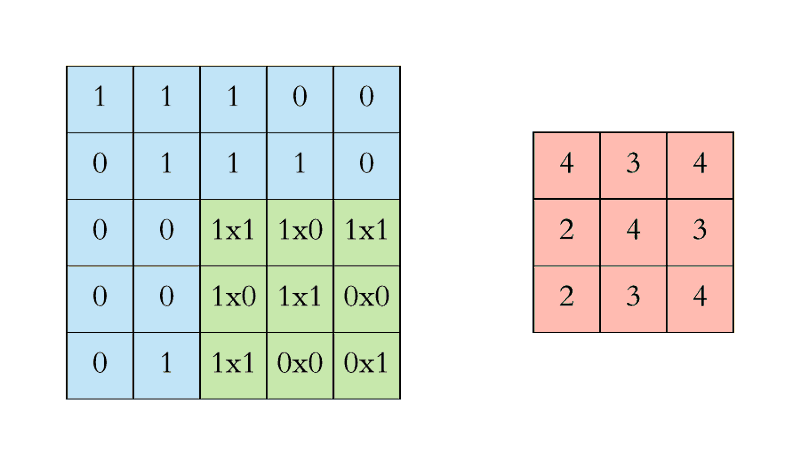
多输入通道和多输出通道
1. 以上的输入和输出都是二维数组,但真实数据的维度经常更高。例如,彩色图像在高和宽2个维度外还有RGB(红、绿、蓝)3个颜色通道。假设彩色图像的高和宽分别是h和w(像素),那么图片可以表示为一个3×h×w的多维数组。
2. 将大小为3的这一维称为通道(channel)维。卷积层的输出也可以包含多个通道,设卷积核输入通道数和输出通道数分别为ci和co,高和宽分别为h和w。如果希望得到含多个通道的输出,我们可以为每个输出通道分别创建形状为ci×h×w的核数组,将它们在输出通道维上连结,卷积核的形状即co×ci×h×w。
池化
池化层主要用于缓解卷积层对位置的过度敏感性。同卷积层一样,池化层每次对输入数据的一个固定形状窗口(又称池化窗口)中的元素计算输出,池化层直接计算池化窗口内元素的最大值或者平均值,该运算也分别叫做最大池化或平均池化。图像处理中的卷积神经网络一般使用二维池化层。
二、卷积神经网络模型发展
CNN发展过程中主要诞生了五大经典模型,它们分别是LeNet、AlexNet、GoogLeNet、VGG、ResNet。
1.LeNet 模型
LeNet分为卷积层块和全连接层块两个部分:
卷积层块里的基本单位是卷积层后接平均池化层。卷积层用来识别图像里的空间模式,如线条和物体局部;之后的平均池化层则用来降低卷积层对位置的敏感性,对卷积层输出的结果进行采样,压缩图像尺寸大小。卷积层块由两个这样的基本单位重复堆叠构成。
全连接层块:其中的向量全部展开成一维向量,一维向量与权重向量进行点积运算,在加上一个偏置,通过激活函数后输出,得到新的神经元输出。

在卷积层块中,每个卷积层都使用5×5的窗口,并在输出上使用sigmoid激活函数。第一个卷积层输出通道数为6,第二个卷积层输出通道数则增加到16。全连接层块含3个全连接层。它们的输出个数分别是120、84和10,其中10为输出的类别个数。
卷积神经网络就是含卷积层的网络,LeNet交替使用卷积层和最大池化层后接全连接层来进行图像分类。
2.AlexNet模型
AlexNet模型首次证明了学习到的特征可以超越⼿⼯设计的特征,⼀举打破计算机视觉研究的前状。它有以下四点特征:
1)8层变换,其中有5层卷积和2层全连接隐藏层,以及1个全连接输出层。
2)将sigmoid激活函数改成了更加简单的ReLU激活函数。
3)用Dropout来控制全连接层的模型复杂度。
4)引入数据增强,如翻转、裁剪和颜色变化,从而进一步扩大数据集来缓解过拟合。
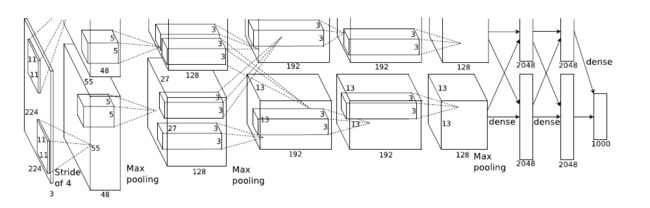
3.VGG模型
VGG模型中通过重复使⽤简单的基础块来构建深度神经网络模型。基础块为卷积+池化层。模型中有数个相同的填充为1、窗口形状为3×3的卷积层,接上一个步幅为2、窗口形状为2×2的最大池化层。卷积层保持输入的高和宽不变,而池化层则对其减半。最常见的是vgg16和vgg19模型。其中vgg16网络结构如下:

VGGNet各级别网络结构参数组合如下
4.GoogLeNet模型
LeNet、AlexNet和VGG:先以由卷积层构成的模块充分抽取空间特征,再以由全连接层构成的模块来输出分类结果。与它们三种模型不同,GoogLeNet模型由如下的Inception基础块组成,Inception块相当于⼀个有4条线路的⼦⽹络,该结构将CNN中常用的卷积(1x1,3x3,5x5)、池化操作(3x3)堆叠在一起,一方面增加了网络的宽度,另一方面也增加了网络对尺度的适应性。它通过不同窗口形状的卷积层和最⼤池化层来并⾏抽取信息,并使⽤1×1卷积层减少通道数从而降低模型复杂度。

5.ResNet模型
ResNet模型是当前应用最为广泛的CNN特征提取网络。
其中不得不提到ResNet模型中残差学习的概念。如下图,若将输入设为X,将某一有参网络层设为H,那么以X为输入的此层的输出将为H(X)。一般的CNN网络如Alexnet/VGG等会直接通过训练学习出参数函数H的表达,从而直接学习X -> H(X)。而残差学习则是致力于使用多个有参网络层来学习输入、输出之间的参差即F(X) = H(X) - X,即学习X -> F(X)+ X。其中X这一部分为直接的identity mapping(恒等映射),而F(X) = H(X) - X 则为有参网络层要学习的输入与输出之间的残差。

越深的网络的层数能够提取到输入图像越丰富的的特征表示。但是对于之前的非残差网络,简单地增加深度会导致梯度弥散或梯度爆炸的问题,而ResNet模型成功的解决了网络深度的问题,ResNet模型可以变得很深,目前已有的甚至超过1000层。研究和实验表明,加深的残差网络能够比简单叠加层生产的深度网络更容易优化,并且因为深度的增加,模型的效果也得到了明显提升。一种ResNet的网络结构如下图所示。

三、Pytorch构建CNN模型
1.定义CNN模型结构
class SVHN_Model1(nn.Module):
def __init__(self):
super(SVHN_Model1, self).__init__() # 第一句话,调用父类的构造函数
model_conv = models.resnet18(pretrained=True)#引用resne18的预训练模型
model_conv.avgpool = nn.AdaptiveAvgPool2d(1)
model_conv = nn.Sequential(*list(model_conv.children())[:-1])
self.cnn = model_conv
self.fc1 = nn.Linear(512, 11)
self.fc2 = nn.Linear(512, 11)
self.fc3 = nn.Linear(512, 11)
self.fc4 = nn.Linear(512, 11)
self.fc5 = nn.Linear(512, 11)
def forward(self, img):
feat = self.cnn(img)
# print(feat.shape)
feat = feat.view(feat.shape[0], -1)
c1 = self.fc1(feat)
c2 = self.fc2(feat)
c3 = self.fc3(feat)
c4 = self.fc4(feat)
c5 = self.fc5(feat)
return c1, c2, c3, c4, c5街景字符编码识别的baseline模型中,使用了残差网络renset18作为特征提取模块,另外,模型的类SVHN_Model继承pytorch自带的基类nn.Module,在类的__init__构造函数中申明各个层的定义,在forward函数中实现层之间的连接关系,forward函数里就是网络前向传播的过程,本例在其中构造了五个并行的基于resnet预训练特征层+输出层的模型结构,每个模型都是11个输出,因为之前的字符个数有11个,分别是0~9和X代表的空字符。
2.定义好训练、验证和预测模块
def train(train_loader, model, criterion, optimizer):
# 切换模型为训练模式
model.train()
train_loss = []
for i, (input, target) in enumerate(train_loader):
if use_cuda:
input = input.cuda()
target = target.cuda()
c0, c1, c2, c3, c4 = model(input)
loss = criterion(c0, target[:, 0]) + \
criterion(c1, target[:, 1]) + \
criterion(c2, target[:, 2]) + \
criterion(c3, target[:, 3]) + \
criterion(c4, target[:, 4])
# loss /= 6
optimizer.zero_grad()
loss.backward()
optimizer.step()
if i % 100 == 0:
print('trainloss',loss.item())
train_loss.append(loss.item())
return np.mean(train_loss)
def validate(val_loader, model, criterion):
# 切换模型为预测模型
model.eval()
val_loss = []
# 不记录模型梯度信息
with torch.no_grad():
for i, (input, target) in enumerate(val_loader):
if use_cuda:
input = input.cuda()
target = target.cuda()
c0, c1, c2, c3, c4 = model(input)
loss = criterion(c0, target[:, 0]) + \
criterion(c1, target[:, 1]) + \
criterion(c2, target[:, 2]) + \
criterion(c3, target[:, 3]) + \
criterion(c4, target[:, 4])
# loss /= 6
val_loss.append(loss.item())
return np.mean(val_loss)
def predict(test_loader, model, tta=10):
model.eval()
test_pred_tta = None
# TTA 次数
for _ in range(tta):
test_pred = []
with torch.no_grad():
for i, (input, target) in enumerate(test_loader):
if use_cuda:
input = input.cuda()
c0, c1, c2, c3, c4 = model(input)
output = np.concatenate([
c0.data.cpu().numpy(),
c1.data.cpu().numpy(),
c2.data.cpu().numpy(),
c3.data.cpu().numpy(),
c4.data.cpu().numpy()], axis=1)
# c0.data.numpy(),
# c1.data.numpy(),
# c2.data.numpy(),
# c3.data.numpy(),
# c4.data.numpy()
test_pred.append(output)
test_pred = np.vstack(test_pred)
if test_pred_tta is None:
test_pred_tta = test_pred
else:
test_pred_tta += test_pred
return test_pred_tta在模型训练阶段,梯度和损失函数是变化的,因此记得有如下三项操作,分别是
1.optimizer.zero_grad():将上一个迭代所计算的梯度进行清零;
2.loss.backward():误差反向传播,计算本次迭代梯度值
3.optimizer.step() :更新网络的权值参数
在模型预测阶段,模型参数已经固定,因此不要以上步骤,不需要记录模型的梯度信息。
3.迭代训练和验证模型
model = SVHN_Model1()
criterion = nn.CrossEntropyLoss()#交叉熵
optimizer = torch.optim.Adam(model.parameters(), 0.001)
best_loss = 1000.0
use_cuda = True#gpu训练
if use_cuda:
model = model.cuda()
for epoch in range(1):
train_loss = train(train_loader, model, criterion, optimizer) #wxd去掉epoch
val_loss = validate(val_loader, model, criterion)
val_label = [''.join(map(str, x)) for x in val_loader.dataset.img_label]
val_predict_label = predict(val_loader, model, 1)
val_predict_label = np.vstack([
val_predict_label[:, :11].argmax(1),
val_predict_label[:, 11:22].argmax(1),
val_predict_label[:, 22:33].argmax(1),
val_predict_label[:, 33:44].argmax(1),
val_predict_label[:, 44:55].argmax(1),
]).T
val_label_pred = []
for x in val_predict_label:
val_label_pred.append(''.join(map(str, x[x!=10])))
val_char_acc = np.mean(np.array(val_label_pred) == np.array(val_label))
print('Epoch: {0}, Train loss: {1} \t Val loss: {2}'.format(epoch, train_loss, val_loss))
print('验证集精度:',val_char_acc)
# 记录下验证集精度
if val_loss < best_loss:#pytorch 需要手动存储自己想要的最优模型。
best_loss = val_loss
torch.save(model.state_dict(), './model.pt')以上程序,可以看出pytorch神经网络训练的基本步骤如下:
1、准备数据集(这一步在上篇已经阐述,DataLoader和Dataset);
2、定义网络结构:model = SVHN_Model1(),具体为类的继承及其__init__函数和forward函数的重写;
3、定义损失函数:criterion = nn.CrossEntropyLoss()#交叉熵;
4、定义优化算法:optimizer = torch.optim.Adam(model.parameters(), 0.001);
5、设置训练轮次epoch数,迭代训练;
6、通过验证集评估模型;
7、通过测试集评估模型。
其中第7步,下一篇继续讨论。
四、参考
[1]https://www.boyuai.com/elites/course/cZu18YmweLv10OeV
[2]https://blog.csdn.net/liu941027/article/details/78297462
[3]https://www.jianshu.com/p/70b6f5653ac6
[4]https://www.jianshu.com/p/93990a641066
[5]https://www.cnblogs.com/alanma/p/6877166.html
[6]天池竞赛:https://tianchi.aliyun.com/competition/entrance/531795/
[7]https://github.com/datawhalechina/team-learning/
[8]https://www.cnblogs.com/rainsoul/p/11377102.html