Python Pandas read_csv()导入csv或者txt
读文本文件的主要方法: read_csv()
read_csv() 可接受以下常用参数:
> filepath_or_buffer : various 文件路径
> sep : str, 默认 read_csv()分隔符为',',read_table()方法,分隔符为 \t
delimiter : str, default None sep的替代参数.
delim_whitespace : boolean, default False 指定是否将空格 (e.g. ’ ’ or ‘\t’)当作delimiter。 等价于设置 sep=’\s+’. 如果这个选项被设置为 True,就不要给 delimiter 传参了.
准备一份实验数据

使用read_csv函数读取文件:

我们可以使用head(n)或者tail(n)函数读取数据的前或者后n条数据,默认读取5条

大家能够看到的是准备的数据十分整齐,每个数据之间都是一个空格,所以被正确的解析出来了。那么如果数据之间有多个空格呢?
比如下面的数据:

我们在运行一次:

大家可以看到多处的空格也别解析出来了。。。那么有什么办法解决吗?
在来看下sep 参数:
sep用来指定分隔符。如果不指定参数,则会尝试使用逗号分隔。分隔符长于一个字符并且不是‘\s+’,将使用python的语法分析器。并且忽略数据中的逗号。正则表达式例子:’\r\t’
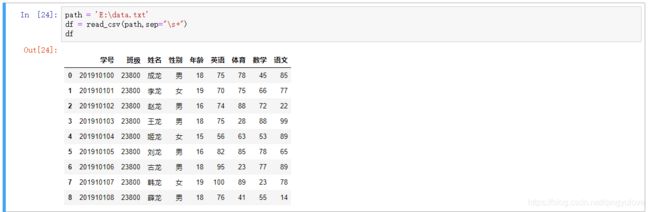
那么这里又有问题了,如果我们的数据本身有一个就是空值呢?
比如:

执行结果:

大家可以看到数据错位了。。。可见使用‘\s+’是可能会导致数据错误,所以还得慎用。除非你能确保数据是规范的。
header
选择默认值或header=0时,将首行设为列名。如果列名被传入明确值就令header=None。注意,当header=0时,即使列名被传参也会被覆盖。
准备数据文件


标题可以是指定列上的MultiIndex的行位置的整数列表,例如 [0,1,3]。在列名指定时,若某列未被指定,读取时将跳过该列 (例如 在下面的例子中第二列将被跳过).注意,如果 skip_blank_lines=True,此参数将忽略空行和注释行, 因此 header=0 表示第一行数据而非文件的第一行.
这种方式适用于拥有多行标题的时候。

names
列名列表的使用. 如果文件不包含列名,那么应该设置header=None。 列名列表中不允许有重复值.

usecols
返回列名列表的子集. 如果该参数为列表形式, 那么其值必须为有效的索引值或者列名。

usecols最常见的使用是callable的方式, 可调用函数将根据列名计算, 返回可调用函数计算结果为True的名称

prefix
当没有header时,可通过该参数为数字列名添加前缀, e.g. ‘X’ for X0, X1, …

mangle_dupe_cols
列名有重复时,解析列名将变为 ‘X’, ‘X.1’…’X.N’而不是 ‘X’…’X’。

如果该参数为 False ,那么当列名中有重复时,前列将会被后列覆盖。
小伙伴们就先不要尝试设置为False,应该是Pandas版本的问题,这个如果设置为False,会得到如下错误:
![]()
dtype
指定某列或整体数据的数据类型

skiprows
需要忽略的行数,可以直接指定行号,也可以通过callable的方式, 可调用函数将根据行计算, 返回可调用函数计算结果为True的名称


skipfooter
跳过文件末尾的若干行,默认值为0.

注意这个参数不支持c引擎,如果要用的话,就使用上面的方式。如果有中文,那么请指定编码格式。
comment
如果comment这个参数指定的话,那么会忽略整行comment语句,当然了空行也会忽略。


注意这个参数只能是单个字符,不然会的到下面的错误。
![]()
至于是什么你随意。。。比如我们把开头为2的当作注释:

skip_blank_lines
是否跳过空行,如果值为False,那么将不会跳过空行。(数据还是拿上面的为例)

当然了,还有许多参数这里没有介绍,希望大家谅解。。。