从头到尾的一次模型搭建训练测试流程
写在前面:本博客仅作记录学习之用,部分图片来自网络,如需使用请注明出处,同时如有侵犯您的权益,请联系删除!
文章目录
- 前言
- 1.数据加载
- 2.模型构建
- 3.训练
-
- 3.1参数设置
- 3.2数据集加载
- 3.3模型保存
- 3.4 优化器选择及参数
- 3.5 前向传播和梯度计算
- 3.6日志记录
- 3.7损失曲线
- 4.测试
- 5.生成requirement.txt
- 6.损失以及部分指标曲线
-
- 6.1混淆矩阵
- 6.2 ROC曲线
- 7.readme.md
- 8.训练代码:
- 致谢
前言
本博客仅为学习记录之用,目的在于后续若需要相关的有资可查。在言语上恐有诸多纰漏,如有错误,欢迎指出交流学习!
本博客所包含的大致内容: 一个简单的模型搭建流程,包括:***数据加载、模型结构、训练网络、指标计算及绘图、README.md撰写***等等。相关涉及内容:***解析命令行的简单使用;记录日志;混淆矩阵;ROC曲线***等。
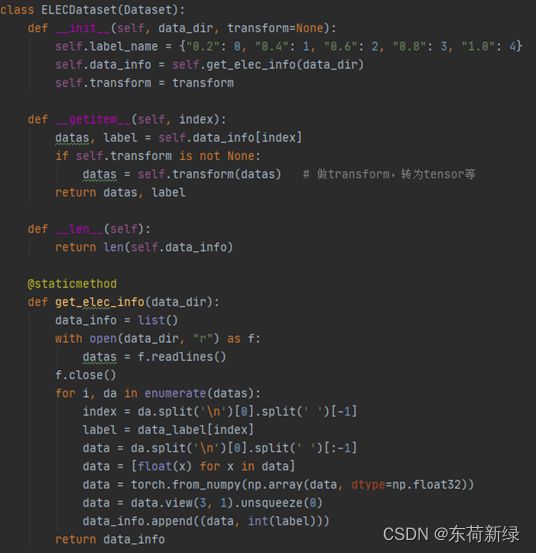
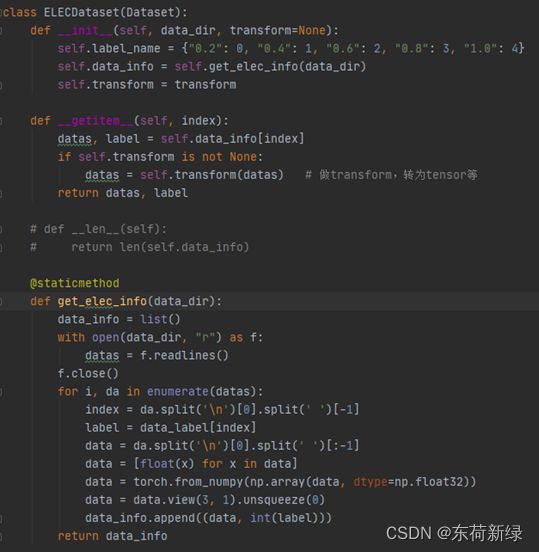
1.数据加载
先放程序,内容简单,后文有涉及到相关的函数介绍。
import numpy as np
import torch
from torch.utils.data import Dataset
class ELECDataset(Dataset):
def __init__(self, data_dir, transform=None):
self.label_name = {"0.2": 0, "0.4": 1, "0.6": 2, "0.8": 3, "1.": 4}
self.data_info = self.get_elec_info(data_dir)
self.transform = transform
def __getitem__(self, index):
datas, label = self.data_info[index]
return datas, label
def __len__(self):
return len(self.data_info)
@staticmethod # 静态方法
def get_elec_info(data_dir):
data_info = list()
with open(data_dir, "r") as f:
datas = f.readlines()
f.close()
for i, da in enumerate(datas):
index = da.split('\n')[0].split(' ')[-1]
label = data_label[index]
data = da.split('\n')[0].split(' ')[:-1] # 获取数据
data = [float(x) for x in data] # 强制类型转化
data = torch.from_numpy(np.array(data, dtype=np.float32)) # 转化为tensor
data = data.view(3, 1).unsqueeze(0)
data_info.append((data, int(label)))
return data_info
其中 getitem 的是类中一个特殊方法,类对象可类似字典,根据key取值(dict[‘key’]),如类对象Object[‘key’],系统会自动调用__getitem__方法,然后返回该方法定义return值。当字典取值时key不存在,会抛出异常,而类对象的key是否存在,都会调用__getitem__方法并返回其规定的值。
@staticmethod:即静态方法,用于修饰类中的方法,使其可以在不创建类实例的情况下调用方法,执行效率较高。静态方法不可以引用类中的属性或方法,其参数列表也不需要约定的默认参数self。静态方法就是类对外部函数的封装,有助于优化代码结构和提高程序的可读性。下面是对静态方法的简单对比。
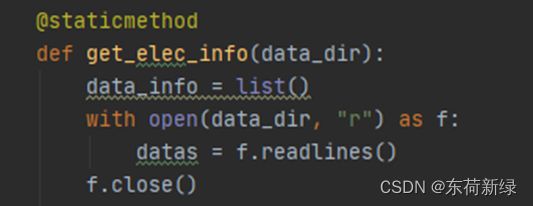 without self without self
|
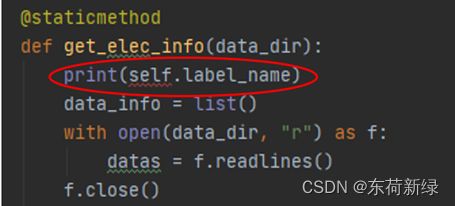 use self but geting a err use self but geting a err
|
 不同的函数 不同的函数
|
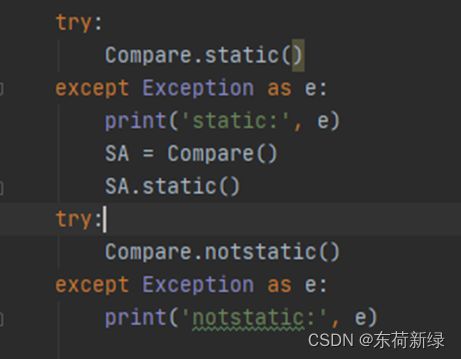 尝试调用 尝试调用
|

由此可见非静态方法是需要self的,相反静态方法无需self.
@classmethod:和静态方法的调用一样,都是通过类就可以直接调用。区别:类方法,需要传入该类,定义类方法的时候要传一个默认的参数cls,静态方法则不用。
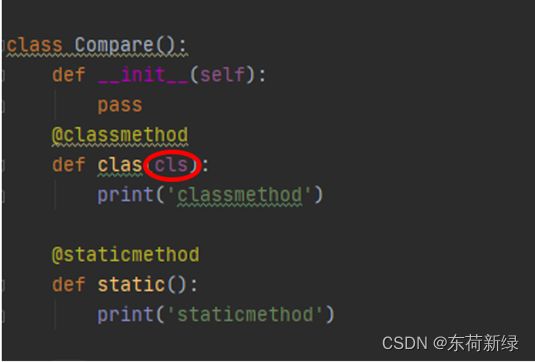 具有cls 具有cls
|
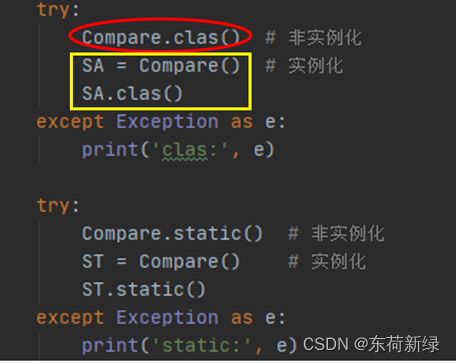 调用方法 调用方法
|
 输出结果 输出结果
|
数据加载,关于len()
 with len() with len()
|
 without len() without len()
|
调用len()

|

|
 正常 正常
|
 报错 报错
|
以上程序的类中定义了__len__()函数,*args是可变长度的参数,它接收到数据后打包成元组,再利用for循环将数据传递给列表。当在命令窗口写入len(c1)时,由于定义的__len__()的返回值是返回具体的实例对象的列表长度,所以在命令窗口直接输入len(c1)就可以输出列表的长度。首先__len__()的作用是返回容器中元素的个数,要想使len()函数成功执行,必须要在类中定义__len__()。
2.模型构建
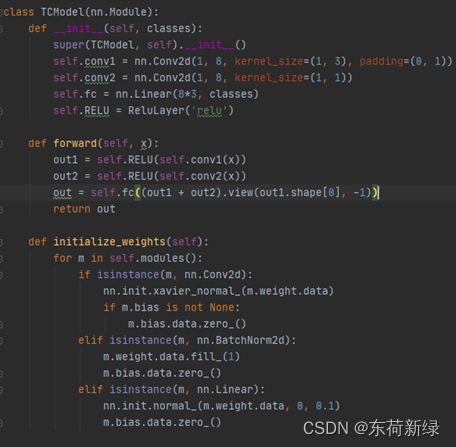 卷积和激活函数 卷积和激活函数
|
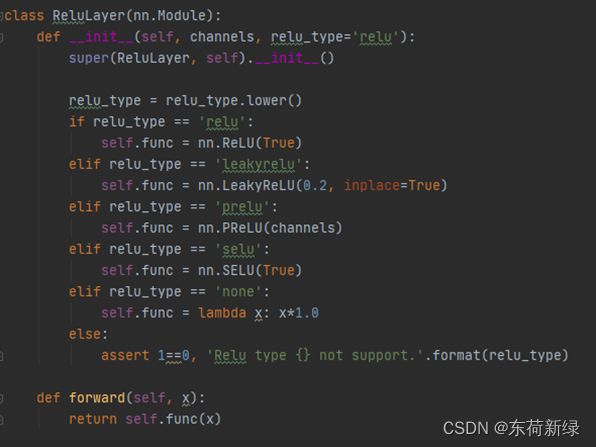 激活函数的选择 激活函数的选择
|
模型简单仅涉及到两个卷积和全连接以及激活函数。TCM(Two Convolution Model)继承nn.model,并行卷积相加后全连接,简单如斯,除开前向传播就是初始化。
其中String.lower():将字符串中的所有大写字母转换为小写字母。String.upper():将字符串中的所有小写字母转换为大写字母。
3.训练
有了数据、和简单的模型,下一步就是如何将两者联系起来,即加载数据进行模型训练。
3.1参数设置
对于参数,一般会有训练轮数epoch,学习率、batchsize等等,当然也会有关于模型的参数,比如分类数。
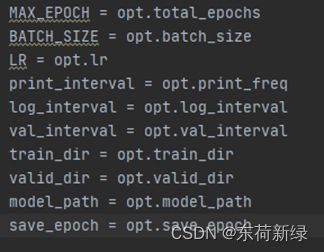
|
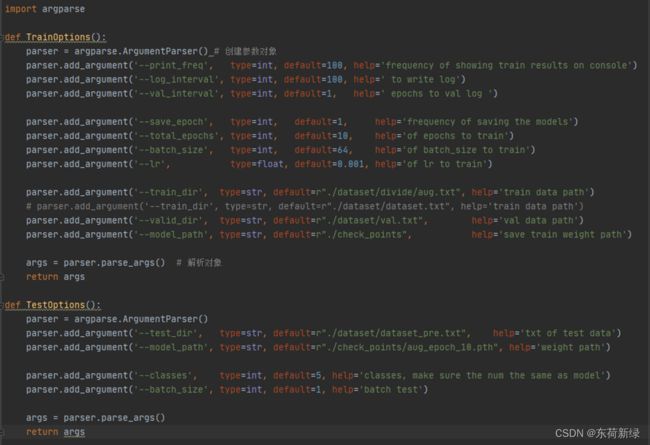 解析命令行 解析命令行
|
3.2数据集加载
实例化数据加载的类。
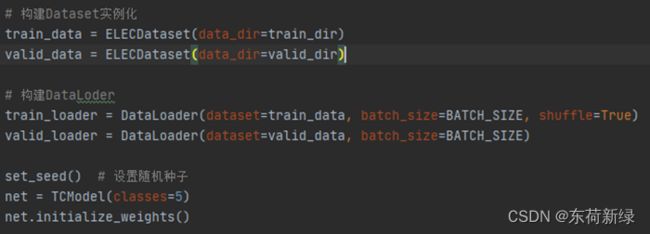
3.3模型保存
采取torch.save()函数进行保存

3.4 优化器选择及参数

3.5 前向传播和梯度计算
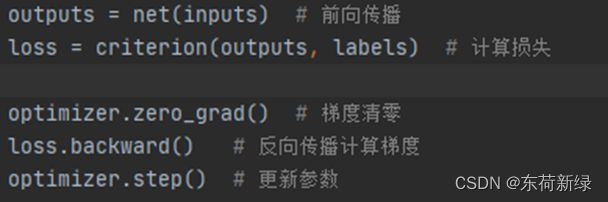
3.6日志记录
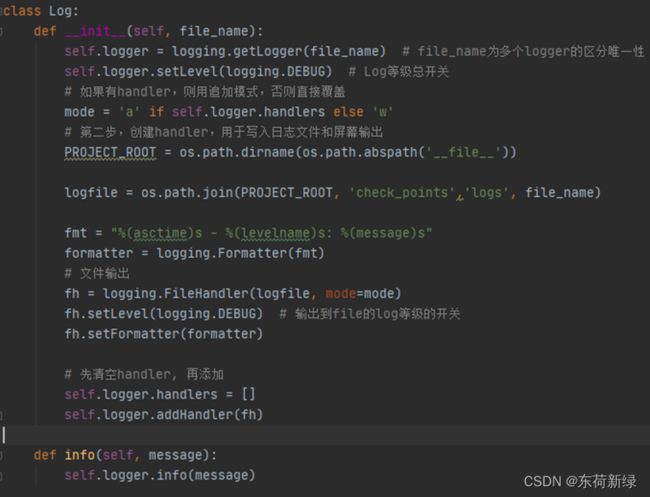
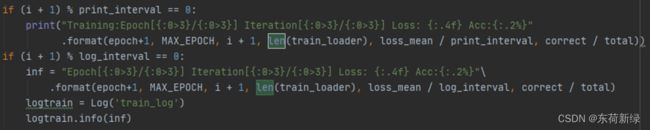

3.7损失曲线

4.测试
加载保存的模型文件,测试前使用eval()函数


5.生成requirement.txt
若没有pipreqs库,则使用以下命令:
pip install pipreqs
在命令行运行下列语句即可:
不存在requirement.txt
pipreqs ./ --encoding=utf8
覆盖已经存在requirement.txt,添加–force
pipreqs ./ --encoding=utf8 –force
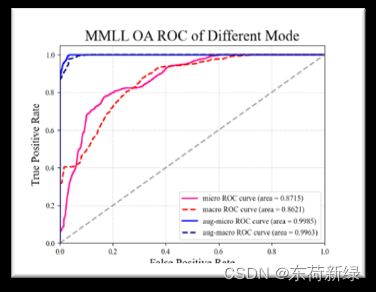
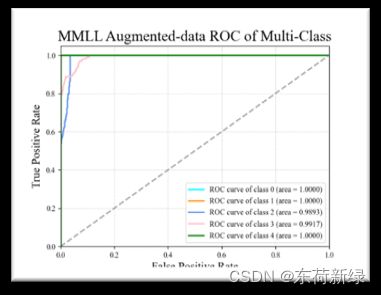
6.损失以及部分指标曲线
此处以MMLL为例,本为了和TCM对比,采取的函数一模一样,仅作示例。
| Original | Augment |
|---|---|
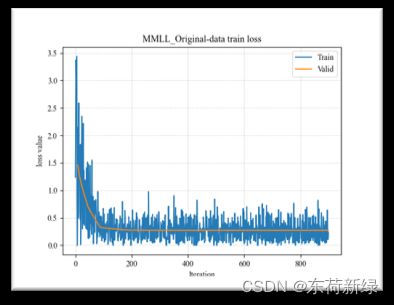 |
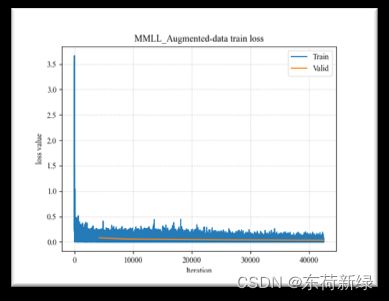 |
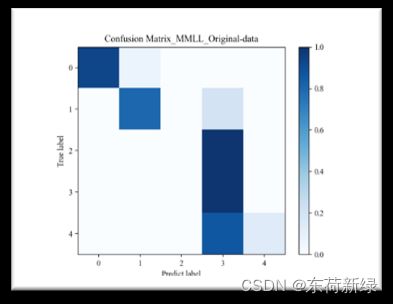 |
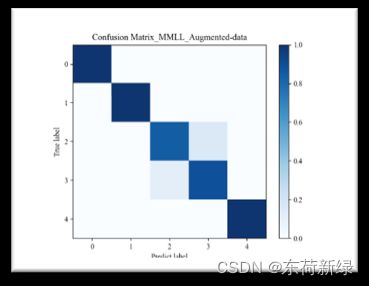 |
 |
 |
6.1混淆矩阵
def show_confMat(confusion_mat, classes_name, set_name, out_dir):
confusion_mat_N = confusion_mat.copy()# 归一化
for i in range(len(classes_name)):
confusion_mat_N[i, :] = confusion_mat[i, :] / confusion_mat[i, :].sum()
mpl.rcParams['font.family'] = 'Times New Roman'
cmap = plt.cm.get_cmap('Blues')
plt.imshow(confusion_mat_N, cmap=cmap)
plt.colorbar()
xlocations = np.array(range(len(classes_name)))
# plt.xticks(xlocations, classes_name, rotation=60)
plt.yticks(xlocations, classes_name)
plt.xlabel('Predict label')
plt.ylabel('True label')
plt.title('Confusion_Matrix_' + set_name)
# for i in range(confusion_mat_N.shape[0]):
# for j in range(confusion_mat_N.shape[1]):
# plt.text(x=j, y=i, s=int(confusion_mat[i, j]), va='center', ha='center', color='red', fontsize=10)
plt.savefig(os.path.join(out_dir, set_name + '.png'))
plt.show()
plt.close()
6.2 ROC曲线
ROC曲线指受试者工作特征曲线/接收器操作特性曲线(receiver operating characteristic curve),是反映敏感性和特异性连续变量的综合指标,是用构图法揭示敏感性和特异性的相互关系,它通过将连续变量设定出多个不同的临界值,从而计算出一系列敏感性和特异性,再以敏感性为纵坐标、(1-特异性)为横坐标绘制成曲线,曲线下面积越大,诊断准确性越高。在ROC曲线上,最靠近坐标图左上方的点为敏感性和特异性均较高的临界值。 (1)AUC指标本身和模型预测score绝对值无关,只关注排序效果,因此特别适合排序业务。AUC 反应了太过笼统的信息。无法反应召回率、精确率等在实际业务中经常关心的指标。(2)AUC对分值本身不敏感,故常见的正负样本采样,并不会导致AUC的变化。(3)AUC非常适合评价样本不平衡中的分类器性能
def ROC(inp, nclass=5): # roc:(Receiver operating characteristic)
if (inp[2] == inp[-1]).all():
print('=')
y_one_hot = label_binarize(inp[0], classes=[0, 1, 2, 3, 4])
n_classes = y_one_hot.shape[1]
fpr = dict()
tpr = dict()
roc_auc = dict()
fp = dict()
tp = dict()
ro = dict()
for i in range(n_classes):
fpr[i], tpr[i], thresholds = metrics.roc_curve(y_one_hot[:, i], inp[2].reshape(len(inp[0]), nclass)[:, i])
roc_auc[i] = metrics.auc(fpr[i], tpr[i])
fp[i], tp[i], thresholds = metrics.roc_curve(y_one_hot[:, i], inp[-1].reshape(len(inp[0]), nclass)[:, i])
ro[i] = metrics.auc(fp[i], tp[i])
fpr["micro"], tpr["micro"], _ = metrics.roc_curve(y_one_hot.ravel(), inp[2].ravel())
roc_auc["micro"] = metrics.auc(fpr["micro"], tpr["micro"])
all_fpr = np.unique(np.concatenate([fpr[i] for i in range(n_classes)]))
mean_tpr = np.zeros_like(all_fpr)
for i in range(n_classes):
mean_tpr += np.interp(all_fpr, fpr[i], tpr[i])
mean_tpr /= n_classes
fp["micro"], tp["micro"], _ = metrics.roc_curve(y_one_hot.ravel(), inp[-1].ravel())
ro["micro"] = metrics.auc(fp["micro"], tp["micro"])
all_fp = np.unique(np.concatenate([fp[i] for i in range(n_classes)]))
mean_tp = np.zeros_like(all_fp)
for i in range(n_classes):
mean_tp += np.interp(all_fp, fp[i], tp[i])
mean_tp /= n_classes
lw = 2
plt.figure(1)
mpl.rcParams['font.family'] = 'Times New Roman'
plt.grid(visible=True, ls=':')
fpr["macro"] = all_fpr
tpr["macro"] = mean_tpr
roc_auc["macro"] = metrics.auc(fpr["macro"], tpr["macro"])
plt.plot(fpr["micro"], tpr["micro"],
label='micro ROC curve (area = {0:0.2f})'
''.format(roc_auc["micro"]),
color='deeppink', linestyle='-', linewidth=2)
plt.plot(fpr["macro"], tpr["macro"],
label='macro ROC curve (area = {0:0.2f})'
''.format(roc_auc["macro"]),
color='red', linestyle='--', linewidth=2)
fp["macro"] = all_fp
tp["macro"] = mean_tp
ro["macro"] = metrics.auc(fp["macro"], tp["macro"])
plt.plot(fp["micro"], tp["micro"],
label='aug-micro ROC curve (area = {0:0.2f})'
''.format(ro["micro"]),
color='blue', linestyle='-', linewidth=2)
plt.plot(fp["macro"], tp["macro"],
label='aug-macro ROC curve (area = {0:0.2f})'
''.format(ro["macro"]),
color='navy', linestyle='--', linewidth=2)
plt.plot([0, 1], [0, 1], c='#808080', lw=lw, ls='--', alpha=0.7)
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate', fontsize=15)
plt.ylabel('True Positive Rate', fontsize=15)
plt.title('ROC of Different Mode', fontsize=20)
plt.legend(loc="lower right")
plt.show()
7.readme.md
8.训练代码:
def train(opt):
MAX_EPOCH = opt.total_epochs
BATCH_SIZE = opt.batch_size
LR = opt.lr
print_interval = opt.print_freq
log_interval = opt.log_interval
val_interval = opt.val_interval
train_dir = opt.train_dir
valid_dir = opt.valid_dir
model_path = opt.model_path
save_epoch = opt.save_epoch
# 构建Dataset实例化
train_data = ELECDataset(data_dir=train_dir)
valid_data = ELECDataset(data_dir=valid_dir)
# 构建DataLoder
train_loader = DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
valid_loader = DataLoader(dataset=valid_data, batch_size=BATCH_SIZE)
set_seed() # 设置随机种子
net = TCModel(classes=5)
net.initialize_weights()
criterion = nn.CrossEntropyLoss() # 选择损失函数
optimizer = optim.SGD(net.parameters(), lr=LR, momentum=0.9) # 选择优化器
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.1) # 设置学习率下降策略
train_curve = list() # plt绘图
valid_curve = list()
print('Start Train !')
for epoch in range(MAX_EPOCH):
loss_mean = 0.
correct = 0.
total = 0.
net.train()
for i, data in enumerate(train_loader):
inputs, labels = data
outputs = net(inputs) # 前向传播
loss = criterion(outputs, labels) # 计算损失
optimizer.zero_grad() # 梯度清零
loss.backward() # 反向传播计算梯度
optimizer.step() # 更新参数
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).squeeze().sum().numpy()
loss_mean += loss.item()
train_curve.append(loss.item())
if (i + 1) % print_interval == 0:
print("Training:Epoch[{:0>3}/{:0>3}] Iteration[{:0>3}/{:0>3}] Loss: {:.4f} Acc:{:.2%}"
.format(epoch+1, MAX_EPOCH, i + 1, len(train_loader), loss_mean / print_interval, correct / total))
if (i + 1) % log_interval == 0:
inf = "Epoch[{:0>3}/{:0>3}] Iteration[{:0>3}/{:0>3}] Loss: {:.4f} Acc:{:.2%}"\
.format(epoch+1, MAX_EPOCH, i + 1, len(train_loader), loss_mean / log_interval, correct / total)
logtrain = Log('train_log')
logtrain.info(inf)
loss_mean = 0.
scheduler.step() # 更新学习率
if (epoch+1) % save_epoch == 0 and epoch > 0: # 保存权重
if train_dir.split('/')[-1] == 'aug.txt':
torch.save(net.cpu().state_dict(), os.path.join(model_path, f'aug_epoch_{epoch+1}.pth'))
else:
torch.save(net.cpu().state_dict(), os.path.join(model_path, f'epoch_{epoch+1}.pth'))
if (epoch+1) % val_interval == 0:
correct_val = 0.
total_val = 0.
loss_val = 0.
net.eval()
with torch.no_grad():
for j, data in enumerate(valid_loader):
inputs, labels = data
outputs = net(inputs)
loss = criterion(outputs, labels)
_, predicted = torch.max(outputs.data, 1)
total_val += labels.size(0)
correct_val += (predicted == labels).squeeze().sum().numpy()
loss_val += loss.item()
loss_val_epoch = loss_val / len(valid_loader)
valid_curve.append(loss_val_epoch)
inf = "Epoch[{:0>3}/{:0>3}] Iteration[{:0>3}/{:0>3}] Loss: {:.4f} Acc:{:.2%}"\
.format(epoch+1, MAX_EPOCH, j + 1, len(valid_loader), loss_val_epoch, correct_val / total_val)
logtrain = Log('val_log')
logtrain.info(inf)
train_x = range(len(train_curve))
train_y = train_curve
train_iters = len(train_loader)
valid_x = np.arange(1, len(valid_curve) + 1) * train_iters * val_interval - 1
valid_y = valid_curve
plt.plot(train_x, train_y, label='Train')
plt.plot(valid_x, valid_y, label='Valid')
plt.legend(loc='upper right')
plt.ylabel('loss value')
plt.xlabel('Iteration')
plt.savefig(os.path.join(model_path, 'logs', 'loss'))
plt.show()
if __name__ == '__main__':
opt = TrainOptions()
train(opt)
致谢
欲尽善本文,因所视短浅,怎奈所书皆是瞽言蒭议。行文至此,诚向予助与余者致以谢意。