Python实现孤立森林(IForest)+SVR的组合预测模型
只讨论性能,不考虑关联性,降噪数据未填补。
1.引入数据集
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
from sklearn.metrics import confusion_matrix
from sklearn.metrics import classification_report
from sklearn.metrics import explained_variance_score
from sklearn.ensemble import RandomForestRegressor
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
import pandas as pd
import numpy as np
import time
from sklearn import metrics
import csv
data=[]
traffic_feature=[]
traffic_target=[]
csv_file = csv.reader(open('turang.csv'))
for content in csv_file:
content=list(map(float,content))
if len(content)!=0:
data.append(content)
traffic_feature.append(content[0:4])
traffic_target.append(content[-1])
data=np.array(data)
traffic_feature=np.array(traffic_feature)
traffic_target=np.array(traffic_target)
df=pd.DataFrame(data=data,columns = ['土壤温度','空气湿度','空气温度','光照强度','土壤水分'])
df| 土壤温度 | 空气湿度 | 空气温度 | 光照强度 | 土壤水分 | |
|---|---|---|---|---|---|
| 0 | 37.77 | 27.00 | 39.90 | 68150.99 | 9.88 |
| 1 | 37.80 | 28.83 | 40.03 | 63989.96 | 9.85 |
| 2 | 37.82 | 26.82 | 40.20 | 63039.88 | 9.78 |
| 3 | 37.96 | 24.33 | 39.90 | 62988.95 | 9.77 |
| 4 | 37.77 | 24.03 | 39.60 | 59670.04 | 9.80 |
| ... | ... | ... | ... | ... | ... |
| 3078 | 28.57 | 91.17 | 17.23 | 861.47 | 28.30 |
| 3079 | 28.52 | 90.90 | 17.17 | 861.55 | 28.30 |
| 3080 | 28.50 | 89.80 | 17.15 | 861.76 | 28.28 |
| 3081 | 28.49 | 86.70 | 17.27 | 861.98 | 28.27 |
| 3082 | 28.46 | 84.50 | 17.43 | 860.32 | 28.28 |
3083 rows × 5 columns
2.标准化
scaler = StandardScaler() # 标准化转换
scaler.fit(traffic_feature) # 训练标准化对象
traffic_feature= scaler.transform(traffic_feature) # 转换数据集
feature_train,feature_test,target_train, target_test = train_test_split(traffic_feature,traffic_target,test_size=0.1,random_state=10)3.SVR
from sklearn.svm import SVR
import matplotlib.pyplot as plt
start1=time.time()
model_svr = SVR(C=1,epsilon=0.1,gamma=10)
model_svr.fit(feature_train,target_train)
predict_results1=model_svr.predict(feature_test)
end1=time.time()
SVRRESULT=predict_results1
plt.plot(target_test)#测试数组
plt.plot(predict_results1)#测试数组
plt.legend(['True','SVR'])
fig = plt.gcf()
fig.set_size_inches(18.5, 10.5)
plt.title("SVR") # 标题
plt.show()
print("EVS:",explained_variance_score(target_test,predict_results1))
print("R2:",metrics.r2_score(target_test,predict_results1))
print("Time:",end1-start1)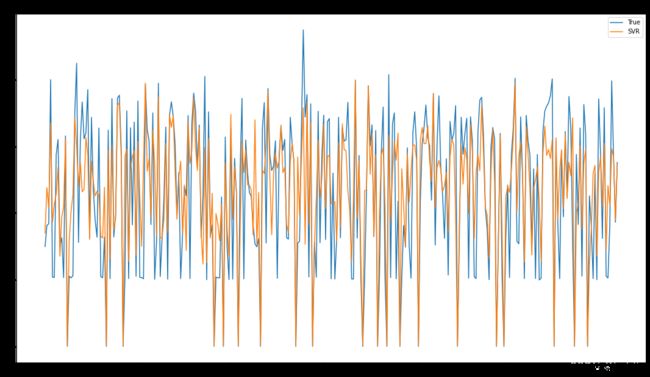
EVS: 0.6563954626493961 R2: 0.6536622059850858 Time: 0.3603041172027588
4.引入IForest降噪
from sklearn.ensemble import IsolationForest
model_isof = IsolationForest()
outlier_label = model_isof.fit_predict(df)
# 将array 类型的标签数据转成 DataFrame
outlier_pd = pd.DataFrame(outlier_label, columns=['outlier_label'])
# 将标签数据与原来的数据合并
data_merge = pd.concat((df, outlier_pd), axis=1)
normal_source = data_merge[data_merge['outlier_label']==1]
normal_source5.测试效果
IF_traffic_feature=normal_source.values[:,[0,1,2,3]]
IF_traffic_target=normal_source.values[:,[4]]
scaler.fit(IF_traffic_feature) # 训练标准化对象
IF_traffic_feature= scaler.transform(IF_traffic_feature) # 转换数据集
feature_train,feature_test,target_train, target_test = train_test_split(IF_traffic_feature,IF_traffic_target,test_size=0.1,random_state=10)
from sklearn.svm import SVR
import matplotlib.pyplot as plt
start1=time.time()
model_svr = SVR(C=1,epsilon=0.1,gamma=10)
model_svr.fit(feature_train,target_train)
predict_results1=model_svr.predict(feature_test)
end1=time.time()
plt.plot(target_test)#测试数组
plt.plot(predict_results1)#测试数组
plt.legend(['True','SVR'])
fig = plt.gcf()
fig.set_size_inches(18.5, 10.5)
plt.title("SVR") # 标题
plt.show()
print("EVS:",explained_variance_score(target_test,predict_results1))
print("R2:",metrics.r2_score(target_test,predict_results1))
print("Time:",end1-start1)
EVS: 0.5487895968648998 R2: 0.5255880566754088 Time: 0.2094569206237793
效果不怎么样...可能是数据集或者未数据填补的原因。