sklearn学习总结
参考地址:https://www.huaweicloud.com/articles/93b502c692cb89a70681d28cf500475c.html
Sklearn (全称 Scikit-Learn) 是基于 Python 语言的机器学习工具。它建立在 NumPy, SciPy, Pandas 和 Matplotlib 之上。
Sklearn 里面有六大任务模块:分别是分类、回归、聚类、降维、模型选择和预处理
要使用上述六大模块的方法,可以用以下的伪代码(通用伪代码):
分类 (Classification):
from sklearn import SomeClassifier
from sklearn.linear_model import SomeClassifier
from sklearn.ensemble import SomeClassifier
SomeClassifier = RandomForestClassifier(随机森林)
回归 (Regression):
from sklearn import SomeRegressor
from sklearn.linear_model import SomeRegressor
from sklearn.ensemble import SomeRegressor
SomeRegressor = LinearRegression(线性回归器)
聚类 (Clustering):
from sklearn.cluster import SomeModel
SomeModel = KMeans(K 均值聚类)
降维 (Dimensionality Reduction):
from sklearn.decomposition import SomeModel
SomeModel = PCA(主成分分析)
模型选择 (Model Selection):
from sklearn.model_selection import SomeModel
SomeModel = GridSearchCV(网格追踪法)
预处理 (Preprocessing):
from sklearn.preprocessing import SomeModel
SomeModel = OneHotEncoder(独热编码)
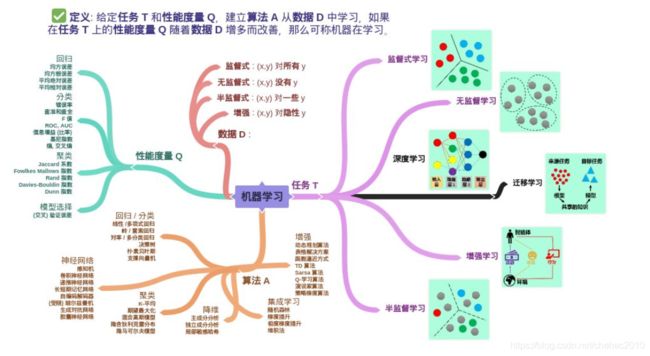
机器学习定义:汤姆米切尔 (Tom M.Mitchell)
假设用性能度量 P 来评估机器在某类任务 T 的性能,若该机器通利用经验 E 在任务 T 中改善其性能 P,那么可以说机器对经验 E 进行了学习。
机器学习包含:
数据 (Data)、任务 (Task)、性能度量 (Quality Metric)、模型 (Model)
结构化和非结构化
结构化数据 (structured data) 是由二维表结构来逻辑表达和实现的数据。非结构化数据是没有预定义的数据,不便用数据库二维表来表现的数据。
对于以上的非结构数据:
深度学习的卷积神经网络 (convolutional neural network, CNN) 对图像数据做人脸识别或物体分类
深度学习的循环神经网络 (recurrent neural network, RNN) 对语音数据做语音识别或机器对话,对文字数据做文本生成或阅读理解
增强学习的阿尔法狗 (AlphaGo) 对棋谱数据学习无数遍最终打败了围棋世界冠军李世石和柯洁
计算机追根到底还是只能最有效率的处理数值型的结构化数据,如何从原始数据加工成计算机可应用的数据会在后面讲明。
结构化数据
机器学习模型主要使用的是结构化数据,即二维的数据表。非结构化数据可以转换成结构化数据,比如把
图像类数据里像素张量重塑成一维数组
文本类数据用独热编码转成二维数组
性能度量
回归和分类任务中最常见的误差函数以及一些有用的性能度量如下。

回归任务的误差函数估量在数据集 D 上模型的连续型预测值 h(x) 与连续型真实值 y 的距离,h(x) 和 y 可以取任意实数。误差函数是一个非负实值函数,通常使用 ED[h] 来表示。图表展示如下。
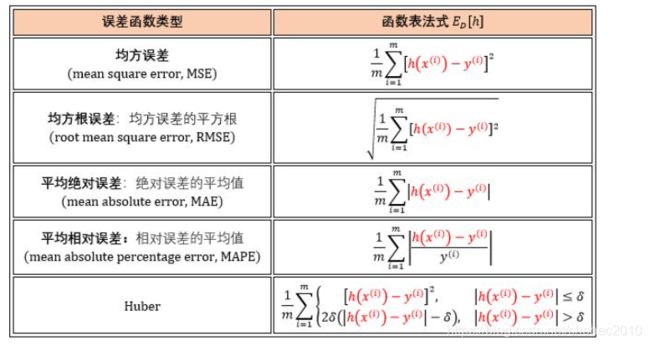
分类任务的误差函数估量在数据集 D 上模型的离散型预测值 h(x) 与离散型真实值 y 的不一致程度,惯例是 y 和 h(x) 取±1,比如正类取 1 负类取 -1。图表展示如下。

错误率:分类错误的样本数占样本总数的比例称为错误率 (error rate),相应的分类正确的样本数占样本总数的比例称为精度 (accuracy)。在 10 个样本中有 2 个样本分类错误,则错误率为 20%,而精度为 80%。
查准率和查全率:错误率和精度虽然常用,但是不能满足所有任务需求。假定用训练好的模型预测骑士赢球,显然,错误率衡量了多少比赛实际是赢球但预测成输球。但是若我们关心的是“预测出的比赛中有多少是赢球”,或“赢球的比赛中有多少被预测出了”,那么错误率这个单一指标显然就不够用了,这时需要引进更为细分的性能度量,即查准率 (precision) 和查全率 (recall)。
其他概念比如混淆矩阵、ROC、AUC 我们再下帖的实例用到时再细讲。
sklearn的数据有哪些:
-
打包好的数据:对于小数据集,用 sklearn.datasets.load_*
-
分流下载数据:对于大数据集,用
sklearn.datasets.fetch_* -
随机创建数据:为了快速展示,用 sklearn.datasets.make_*
API 其实都是估计器:
估计器 (estimator) 当然是估计器
预测器 (predictor) 是具有预测功能的估计器
转换器 (transformer) 是具有转换功能的估计器
定义:任何可以基于数据集对一些参数进行估计的对象都被称为估计器。
两个核心点:1. 需要输入数据,2. 可以估计参数。估计器首先被创建,然后被拟合。
访问超参数“.”,访问训练参数使用‘_’
有监督:model.fit( X_train, y_train )
无监督:model.fit( X_train )
线性回归里超参数 normalize=True(表示线性回归进行标准化)
print( model.coef_ ) 表示获取参数w
print( model.intercept_ ) 表示获取截距bmodel.labels_(K 均值里聚类标签 labels_)
K 均值里超参数 n_clusters=3()
解释一下 KMeans 模型这几个参数:
model.cluster_centers_:簇中心。三个簇那么有三个坐标。
model.labels_:聚类后的标签
model.inertia_:所有点到对应的簇中心的距离平方和 (越小越好)
预测器
定义:预测器在估计器上做了一个延展,延展出预测的功能。
两个核心点:1. 基于学到的参数预测,2. 预测有很多指标。最常见的就是 predict() 函数:
估计器都有 fit() 方法,预测器都有 predict() 和 score() 方法
model.predict(X_test):评估模型在新数据上的表现
model.predict(X_train):确认模型在老数据上的表现
设置超参数 mutli_class 为 multinomial 因为有三种鸢尾花,是个多分类问题。
predict(),预测的类别是什么
predict_proba() 预测该类别的信心如何
score() 返回的是分类准确率
decision_function() 返回的是每个样例在每个类下的分数值
KMeans 模型里也有 score() 函数,输出是值是它要优化的目标函数的对数。
转换器
定义:转换器也是一种估计器,两者都带拟合功能,但估计器做完拟合来预测,而转换器做完拟合来转换。
核心点:估计器里 fit + predict,转换器里 fit + transform。
1、将分类型变量 (categorical) 编码成数值型变量 (numerical)
2、规范化 (normalize) 或标准化 (standardize) 数值型变量
LabelEncoder & OrdinalEncoder
LabelEncoder 和 OrdinalEncoder 都可以将字符转成数字,但是
LabelEncoder 的输入是一维,比如 1d ndarray
OrdinalEncoder 的输入是二维,比如 DataFrame
特征缩放
数据要做的最重要的转换之一是特征缩放 (feature scaling)。当输入的数值的量刚不同时,机器学习算法的性能都不会好。
具体来说,对于某个特征,我们有两种方法:
1、标准化 (standardization):每个维度的特征减去该特征均值,除以该维度的标准差。
2、规范化 (normalization):每个维度的特征减去该特征最小值,除以该特征的最大值与最小值之差。
五大元估计器,分别带集成功能的 ensemble,多分类和多标签的 multiclass,多输出的 multioutput,选择模型的 model_selection,和流水线的 pipeline。
-
ensemble.BaggingClassifier
-
ensemble.VotingClassifier
-
multiclass.OneVsOneClassifier
-
multiclass.OneVsRestClassifier
-
multioutput.MultiOutputClassifier
-
model_selection.GridSearchCV
-
model_selection.RandomizedSearchCV
-
pipeline.Pipeline
总结
Sklearn 里面设计 API 遵循五大原则。
一致性
所有对象的接口一致且简单,在「估计器」中
-
创建:model = Constructor(hyperparam)
-
拟参:
-
有监督学习 -
model.fit(X_train, y_train) -
无监督学习 - model.fit(X_train)
-
在「预测器」中
-
有监督学习里预测标签:
y_pred = model.predict(X_test) -
无监督学习里识别模式:idx_pred = model.predict( Xtest)
在「转换器」中
-
创建:
trm = Constructor(hyperparam) -
获参:trm.fit(X_train)
-
转换:X_trm = trm.transform(X_train)
可检验
所有估计器里设置的超参数和学到的参数都可以通过实例的变量直接访问来检验其值,区别是超参数的名称最后没有下划线 _,而参数的名称最后有下划线 _。举例如下:
-
通例:model.hyperparameter
-
特例:SVC.kernel
-
通例:model.parameter_
-
特例:SVC.support_vectors_
标准类
Sklearn 模型接受的数据集的格式只能是「Numpy 数组」和「Scipy 稀疏矩阵」。超参数的格式只能是「字符」和「数值」。
不接受其他的类!
可组成
模块都能重复「连在一起」或「并在一起」使用,比如两种形式流水线 (pipeline)
-
任意转换器序列
-
任意转换器序列 + 估计器
有默认
Sklearn 给大多超参数提供了合理的默认值,大大降低了建模的难度。
总结一套机器学习的初级框架:
确定任务:是「有监督」的分类或回归?还是「无监督」的聚类或降维?确定好后基本就能知道用 Sklearn 里哪些模型了。
数据预处理:这步最繁琐,要处理缺失值、异常值;要编码分类型变量;要正规化或标准化数值型变量,等等。但是有了 Pipeline 神器一切变得简单高效。
训练和评估:这步最简单,训练用估计器 fit() 先拟合,评估用预测器 predict() 来评估。
选择模型:启动 Model Selection 估计器里的 GridSearchCV 和 RandomizedSearchCV,选择得分最高的那组超参数 (即模型)。