论文阅读笔记-AGMB-Transformer: Anatomy-Guided Multi-Branch Transformer Networkfor Automated Evaluation
目录
摘要
1.引言
2.相关工作
3.方法
3.1 AGMB网络模型
3.2 Multi-Branch transfomer Network背景知识
3.2.1 Group convolution
3.2.2 Self-attention:
3.2.3 multi-head self- attention:
3.2.4 positional encoding:
3.2.5 Transformer 机制
3.3 Multi-Branch transfomer Network
3.4 Branch Fusion Module
3.5 超参数
摘要
-对X线图像治疗结果的准确评估是根管治疗中一个重要且具有挑战性的步骤,因为对治疗结果的错误解释会阻碍及时的随访,这对患的治疗结果至关重要。目前,评价都是手工进行的,既耗时、主观,又容易出错。本文旨在利用计算机视觉和人工智能领域的研究进展,实现这一过程的自动化,为根管治疗结果的评估提供一种客观、准确的方法。提出了一种新的解剖引导多分支变压器(AGMB-变压器)网络,首先提取一套解剖特征,然后利用它们引导多分支变压器网络进行评价。具体地说,我们设计了一种多项式曲线拟合分割策略来提取解剖特征。此外,还设计了一个分支融合模块和一个多分支结构,包括我们的渐进式transformer和group multi-head self-attetion(GMHSA),以关注全局和局部特征,以准确诊断。
作者想解决的问题:通过人工智能对X线图像治疗结果的准确评估,解决手工耗时出错问题。
作者解决问题的理论/模型:①提出了一种新型的深度学习架构,称为AGMB ②加入了分支融合模块和一个多分支结构。
这个方法的优越性(创新点)在哪?:①采用了多分支结构和分支融合模型。 ②通过Transformer和group multi-head self-attention 与CNN融合,可以保证关注局部特征的同时还关注到了全局特征
1.引言
据我们所知
•这是首次实现了一种自动、准确的根管治疗评估方法,在临床实践中可能为根管治疗带来显著的好处。
•为了有效地提取解剖线索,我们提出了一种新的解剖特征提取器,适用于检测口腔
•射线图像中的模糊边界。通过对检测到的地标进行拟合的多项式曲线,实现了精确的牙尖区域分割。
•我们结合群卷积和渐进式transformer的优点,设计了一个多分支transformer网络,其中渐进式transformer实现了多尺度的attention,并通过group attention减少了计算量。我们的网络结构解决了卷积的固有局部问题,实现了多分支结构特征融合。
背景介绍:为什么研究这个课题:①手工评估多个x射线图像是一件费时而繁琐的工作。②人工评估。由于需要高水平的专业知识,结果很容易出错,而且由于不可避免的观察者间的可变性,结果是高度主观的。
研究进行到了哪个阶段:①牙根的顶端区域边界,这是最重要的解剖线索评估,很难使用传统的边缘检测方法提取,因为牙齿的边界不清楚和不规则。过度曝光或曝光不足 ②牙根可能被头部的其他骨骼和组织所掩盖,无法描述足够的视觉信息进行评估。
使用理论基于哪些假设:①landmark detection strategy ② polunomial curve fitting approach ③ Transformer以及self -attention 。 ④ group convolution
2.相关工作
在本文中,我们提出了一种基于深度学习的方法来评估根管治疗的结果。我们的方法包括两个主要组成部分:一种依赖于分割方法的解剖特征提取器,以及遵循分类方法的根管治疗评估方法。本研究主要涉及医学图像分类和分割两个领域。
本部分提出的相关研究缺陷:CNN受到了内在限制,它们更关注本地信息,因此不能处理全局特征。
依据此提出的解决办法:transformer机制采用了位置编码(positional coding),可以通过transformer机制来建模提取的局部特征的远程依赖性,从而获取全局特征
3.方法
3.1 AGMB网络模型
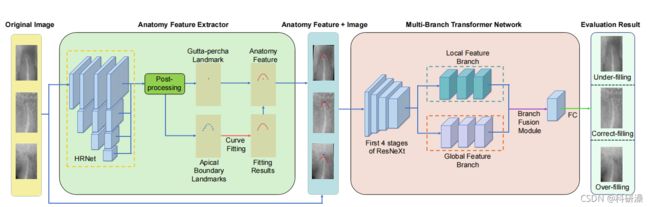
3.2 Multi-Branch transfomer Network背景知识

 3.2.1 Group convolution
3.2.1 Group convolution
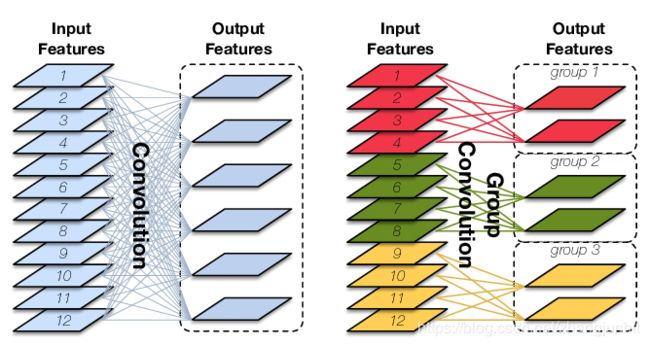
Group Convolution顾名思义,则是对输入feature map进行分组,然后每组分别卷积。假设输入feature map的尺寸仍为C∗H∗W,输出feature map的数量为N个,如果设定要分成G个groups,则每组的输入feature map数量为C/G,每组的输出feature map数量为N/G,每个卷积核的尺寸为C/G∗K∗K,卷积核的总数仍为N个,每组的卷积核数量为N/G,卷积核只与其同组的输入map进行卷积,卷积核的总参数量为N∗C/G∗K∗K。
解决的问题:减少参数量,分成G组,则该层的参数量减少为原来的1/G
3.2.2 Self-attention:
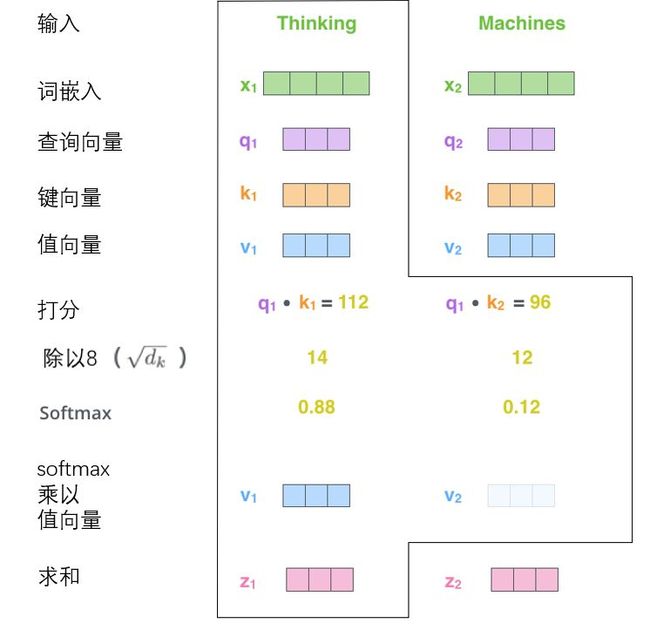
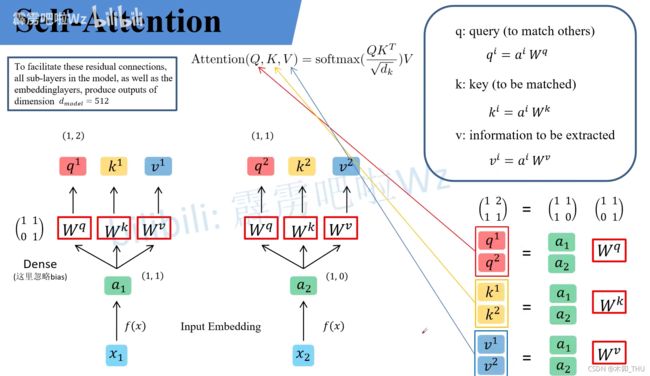
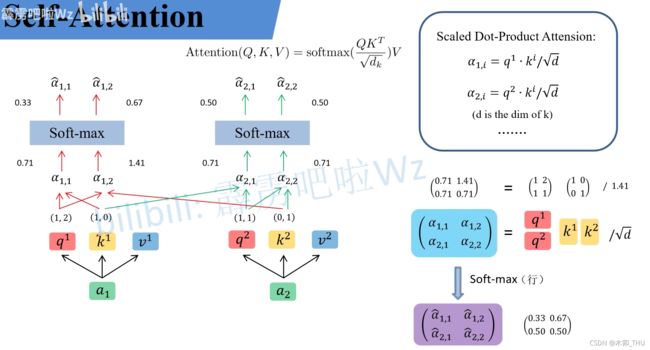
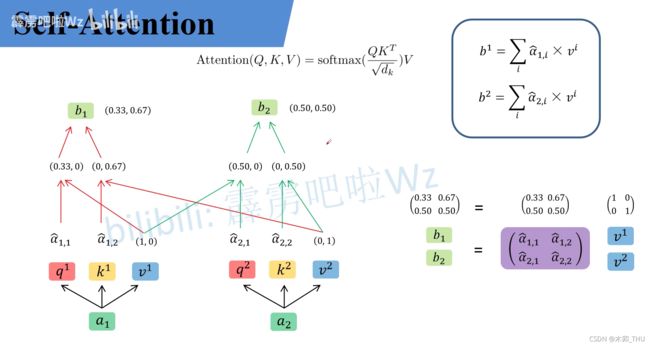
3.2.3 multi-head self- attention:
解决的问题:将模型分为多个头,形成多个子空间,可以让模型去关注不同方面的信息。
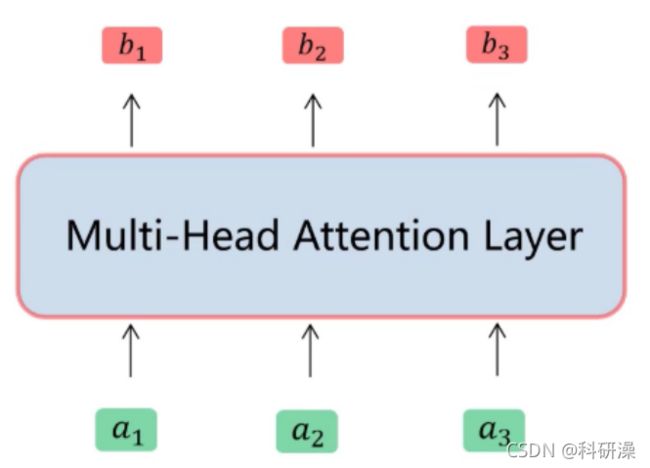
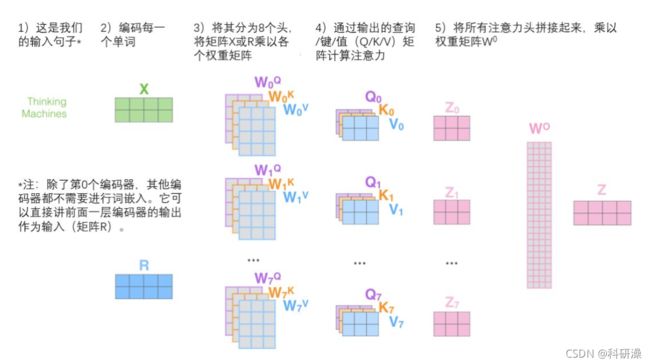
在源码中就是将a1平分给每个head,multi-head self attention 的head设为8,因此会将a1常常等分为8份。
3.2.4 positional encoding:
解决的问题:定位位置信息。因为Self-Attention相对于传统的RNN在输入计算时没有输入先后顺序,而是采用并行化的思想来加快运算,但是这样丧失了序列的顺序性。因此为了不损失顺序性,在将序列输入之前还需要结合位置编码(Positional Encoding)

文本数据经过了Embedding层后,我们会得到一个三维的数据,第一维表示共有几句话, 第二位表示每句话有多少个字,第三维数据表示,每个字使用多少数据进行表示。
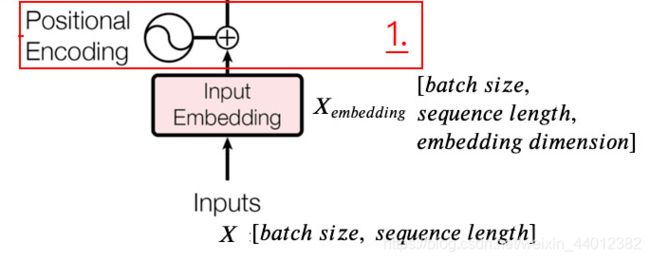
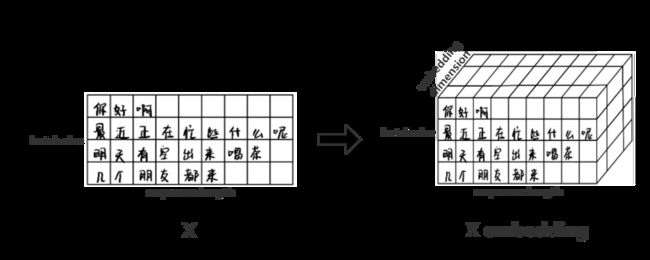


3.2.5 Transformer 机制
transformer机制的黑箱图大概结构如下所示:
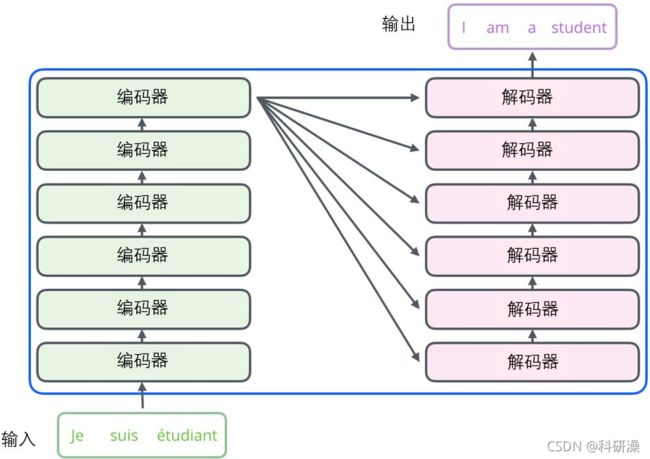
其编码器和解码器的大概结构如下:

一个编码器接收向量列表作为输入,接着将向量列表中的向量传递到自注意力层进行处理,然后传递到前馈神经网络层中,将输出结果传递到下一个编码器中。

残差模块
编码器中的细节:每个编码器中的每个子层(子注意力,前馈网络)的周围都会有一个残差连接,并且都跟随一个“层→归一化”步骤

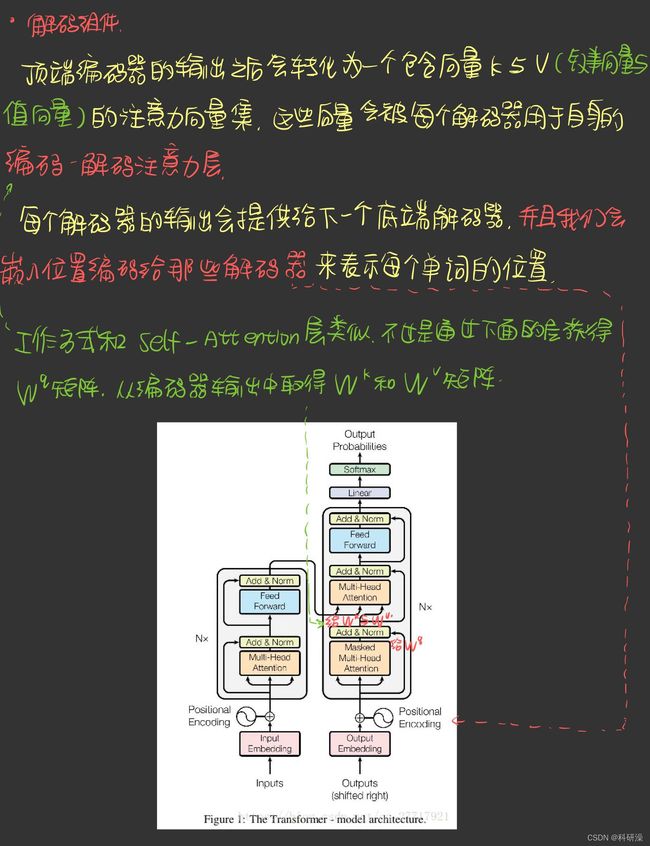
最终的线性变换和softmax

3.3 Multi-Branch transfomer Network
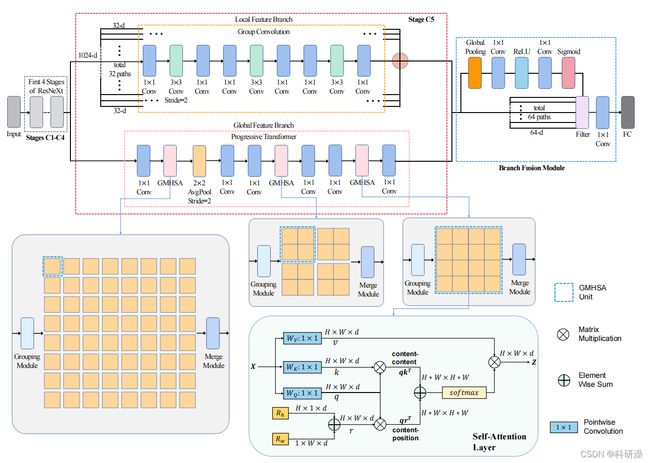
X表示分组模块后获得的特征块,Z表示自注意力层的输出。分组模块将C x H x W 的原始特征块划分为 N x C x H x W 的小块,并分别对N个小特征块进行自注意力操作。合并模块在分组操作后将特征块合并恢复为原始特征块排列。
3.4 Branch Fusion Module

3.5 超参数
