NLP 学习笔记之 Seq2seq
基础知识储备:
首先知道计算机把语言当作sequence
有一些标识符
BOS:begining of sequence,代表序列开始。
EOS:End of sequence,代表序列结束。
UNK: 低频词或未在词表中的词
PAD: 补全字符
Epoch(时期):
当一个完整的数据集通过了神经网络一次并且返回了一次,这个过程称为一次>epoch。(也就是说,所有训练样本在神经网络中都 进行了一次正向传播 和一次反向传播 )
然而,当一个Epoch的样本(也就是所有的训练样本)数量可能太过庞大(对于计算机而言),就需要把它分成多个小块,也就是就是分成多个Batch 来进行训练。
Batch(批 / 一批样本):
将整个训练样本分成若干个Batch。
Batch_Size(批大小):
每批样本的大小。 样本数量/ 批次数= batch size
batchSize表示批次大小,如bathSize=5,代表模型处理完5个样本后,进行一次前向传播和反向传播;
Iteration(一次迭代):
训练一个Batch就是一次Iteration
一 Recurrent Neural Networks
一个RNN包括隐藏状态h、一个可选的输出y,可变长度输入序列x, X = {x1, x2, … xT}。

二 encoder decoder 结构
模型主要学习基于一个可变长度的序列条件下另一个可变长度序列的概率.
Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation 论文名称
这篇文章首次提出 GRU 的模型,并针对传统的统计机器翻译,提出了 Encoder-Decoder 模型。
传统的统计机器翻译大概是这样:基于短语进行翻译。显然这样的准确率不高。具体可以查阅维基百科:统计机器翻译
而我们人工翻译一般是这样:整句话读入(encoder)、在脑海里面翻译成我们自己理解的语言(汇总)、输出翻译后的句子(decoder)。
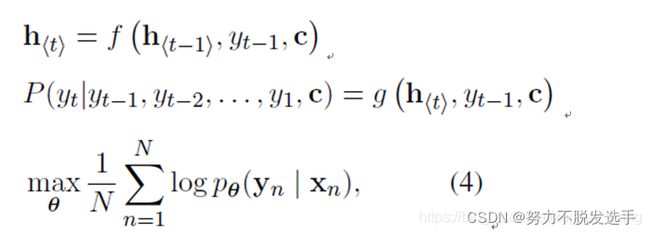
三 Seq2Seq结构
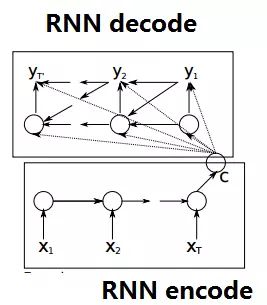
seq2seq属于encoder-decoder结构的一种,这里看看常见的encoder-decoder结构,基本思想就是利用两个RNN,一个RNN作为encoder,另一个RNN作为decoder。encoder负责将输入序列压缩成指定长度的向量,这个向量就可以看成是这个序列的语义,这个过程称为编码。获取语义向量最简单的方式就是直接将最后一个输入的隐状态作为语义向量C。
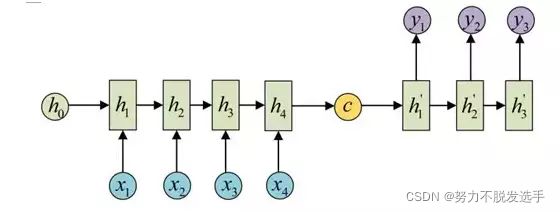
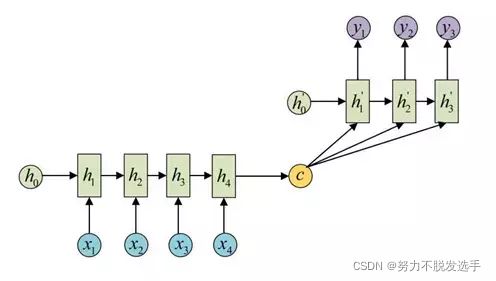
常见的是字符预测例子或者时间序列预测。为了得到概率分布,一般会在RNN的输出层使用softmax激活函数,就可以得到每个分类的概率。(在对话生成任务中,即得到词典中每个单词出现的概率)
Softmax 在机器学习和深度学习中有着非常广泛的应用。尤其在处理多分类(C分类数 > 2)问题,分类器最后的输出单元需要Softmax 函数进行数值处理。关于Softmax 函数的定义:

对于encoder-decoder模型,设有输入序列x1, x2, x3… xT,输出序列y1, y2, y3… yT,输入序列和输出序列的长度可能不同。那么其实就需要根据输入序列去得到输出序列可能输出的词概率,于是有下面的条件概率,x1,x2,x3…xT发生的情况下,y1,y2,y3…yT发生的概率等于P(yt| v, y1,y2…yt-1)连乘,如下公式所示。![]()
其中v,表示x1,x2…xt对应的隐含状态向量(输入中每个词的词向量)
ht = f( ht-1, yt-1, v ),decode编码器中隐含状态与上一时刻状态、上一时刻输出和状态v都有关(这里不同于RNN,RNN是与当前时刻的输入相关,而decode编码器是将上一时刻的输出输入到RNN中。于是decoder的某一时刻的概率分布
![]()
对于训练样本,我们要做的就是在整个训练样本下,所有样本的p(y_1,y_2,…,y_T|x_1,…,x_T)概率之和最大。对应的对数似然条件概率函数为
![]()
使之最大化.
四 GRU
GRU(Gate Recurrent Unit)
当重置门(reset gate)r接近0时,隐藏状态将会忽略上一个隐藏状态,只是用当前的输入进行重置。这将有效的容许隐藏状态丢弃一些和未来无关的信息。捕捉短期依赖的单元更倾向于拥有更多的reset gate。
更新门(update gate)控制上一个隐藏状态的信息有多少会传递到当前隐藏状态。捕捉短期依赖的单元更倾向于拥有更多的update gate
ps:
实现一个 seq2seq 一些会用到的包
torch.nn.utils.rnn pad sequence 把句子拉长 默认max_length 45
五: 选择目标序列 greedy(贪心) / Beam (集束)search
构建seq2seq模型,并训练完成后,我们只要将源句子输入进训练好的模型,执行一次前向传播就能得到目标句子,但是值得注意的是:
seq2seq模型的decoder部分实际上相当于一个语言模型,相比于RNN语言模型,decoder的初始输入并非0向量,而是encoder对源句子提取的信息。因此整个seq2seq模型相当于一个条件语言模型,本质上学习的是一个条件概率,即给定输入(x),学习概率分布(P(y|x))。得到这个概率后,对应概率最大的目标句子(y)就是模型认为的最好的输出。我们不希望目标的输出是随机的(这相当于对学习的概率分布(P(y|x))随机取样),但要选择最好的句子(y)需要在decoder的每一步遍历所有可能的单词,假如目标句子的长度为(n),词典大小为(v),那么显然,可能的句子数量是(v^n),这显然是做不到的。
但是有个容易混淆的点
beam search的 那个 beam size N到底怎么用。
第一步 先选出概率最高的N个
第二步来说:一步选择了N种结果后,其中的每种结果再次预测出N种结果,然后将这个预测出来的N * N种结果,进行排序,选择前N种,再继续第三步…
详细讲述 贪心和集束的一个blog
一文讲清楚 Viterbi