神经结构搜索(Neural Architecture Search, NAS)学习
神经结构搜索(Neural Architecture Search, NAS)学习
目录:
- 参考文献
- NAS基础知识整理
- A Study on Encodings for Neural Architecture Search论文学习
- Cream of the Crop: Distilling Prioritized Paths For One-Shot Neural Architecture Search论文学习
一、参考文献
1、本文对两篇NeurIPS 2020收录的论文进行阅读整理,分别是:
[1]Colin White,Willie Neiswanger,Sam Nolen,Yash Savani:A Study on Encodings for Neural Architecture Search,NeurIPS 2020;
论文:https://papers.nips.cc/paper/2020/file/ea4eb49329550caaa1d2044105223721-Paper.pdf
代码:https://github.com/naszilla/naszilla
[2]Houwen Peng, Hao Du, Hongyuan Yu, Qi Li, Jing Liao, Jianlong Fu:Cream of the Crop: Distilling Prioritized Paths For One-Shot Neural Architecture Search,NeurIPS 2020;
论文:https://papers.nips.cc/paper/2020/file/d072677d210ac4c03ba046120f0802ec-Paper.pdf
代码:https://github.com/microsoft/cream.git
2、阅读过程中觉得可以延伸阅读的论文:
[1]Regularized Evolution for Image Classifier Architecture Search,AAAI 2019;
论文:https://ojs.aaai.org/index.php/AAAI/article/view/4405/4283
[2]Neural Architecture Search with Bayesian Optimisation and Optimal Transport,NeurIPS 2018;
论文:https://papers.nips.cc/paper/2018/file/f33ba15effa5c10e873bf3842afb46a6-Paper.pdf
[3]Gabriel Bender, Pieter-Jan Kindermans, Barret Zoph, Vijay Vasudevan, Quoc Le :Understanding and Simplifying One-Shot Architecture Search,PMLR 2018;
论文:http://proceedings.mlr.press/v80/bender18a/bender18a.pdf
[4]Chenglin Yang, Lingxi Xie, Chi Su, Alan L. Yuille:Snapshot Distillation: Teacher-Student Optimization in One Generation,CVPR 2019;
论文:https://openaccess.thecvf.com/content_CVPR_2019/papers/Yang_Snapshot_Distillation_Teacher-Student_Optimization_in_One_Generation_CVPR_2019_paper.pdf
二、NAS基础知识整理
(1)NAS定义
- 神经结构搜索(Neural Architecture Search,NAS)是指给定一个称为搜索空间的候选神经网络结点集合,通过控制器按照某种搜索算法策略从集合中搜索出子网络结构,并使用某种性能评估策略评估性能。评估结果将返回给搜索策略,用于调整下一次的神经结构选择,迭代直到搜索出符合要求的神经网络
(2)经典NAS方法
- 使用RNN作为控制器产生子网络
- 对子网络进行训练和评估,得到网络性能(如正确率),然后更新控制器的参数(利用强化学习 + 策略梯度)
- ENAS:提高了NAS的搜索效率
- ENAS将搜索空间表示为一个有向无环图(DAG),任一子图代表一个网络结构,每个结点代表局部计算,结点间的有向连接代表信息的流动
- 权重共享:不同的网络结构共享整个有向无环图结点上的参数,减少搜索时间
(3)NAS核心要素
- 定义搜索空间:定义可以搜索的神经网络结构的集合,即解的空间。其规模决定了搜索难度和搜索时间
- 全局搜索空间
- 基于细胞的搜索空间:堆叠 + 拼接,减少搜索代价,提高结构可迁移性
- 执行搜索策略采样网络:定义如何在搜索空间中寻找最优网络结构,本质上是一个迭代优化超参数的过程
- 穷举算法:
- 随机搜索(Random Search):从搜索空间中随机选取网络结构信息并训练,最终得到性能最优的模型
- 网格搜索(Grid Search):超参数优化,对于每个超参数取值指定一个有限集,使用笛卡尔积得到若干组参数,使用每组超参数训练模型后挑选验证集误差最小的即为最优结构
- 基于离散空间的搜索策略:
- 基于强化学习(Reinforcement Learning):将网络结构的搜索看作智能体的动作,使用得到的子网络在数据上的表现作为智能体的奖励值。
- 智能体与环境交互 + 智能体执行动作 + 环境中回馈
- 目标:回馈最大化
- 三个关键因素:
- 状态(State):当前搜索过程已确定了的部分神经结构
- 动作(Action):在当前状态向结构加入新的结点
- 奖励(Reward):每个动作带来的对预定搜索目标的增益。每个动作的奖励决定了是否在当前状态选择该动作
- 基于进化算法(Evolutionary Alogrithm):选择 + 重组 + 变异
- 迭代直到达到最大迭代次数或变异后网络的性能不再提升
- 预设定的结构变异操作 → 新的候选,训练 + 评估 → 加入种群
- 从种群中挑选结构训练并评估,留下高性能网络而淘汰低性能网络
- 对网络结构进行编码,维护结构的集合(种群)
- 基于强化学习(Reinforcement Learning):将网络结构的搜索看作智能体的动作,使用得到的子网络在数据上的表现作为智能体的奖励值。
- 基于连续空间的搜索策略:
- 基于梯度的方法(Gradient-Based Method):搜索空间连续 + 目标函数可微
- Neural Architecture Optimization:基于encode-decode框架
- 将网络结构映射到连续空间中表示(embedding),空间中每个点对应一个网络结构
- 在空间上定义准确率的预测函数,对embedding进行优化,网络收敛后,再将这个表示映射回网络结构
- DARTS:Differentiable Architecture Search,提出可微结构搜索方法,将结点连接和激活函数组成矩阵,每个元素代表了连接和激活函数的权重,将候选操作在搜索时使用softmax函数进行混合,从而使得搜索空间连续化并且目标函数可微。搜索结束后,将从混合操作中选取权重最大的操作作为最终网络
- Neural Architecture Optimization:基于encode-decode框架
- 贝叶斯优化(Bayesian Optimization):从细节上指定如何探索搜索空间,本质上是一个迭代优化超参数的过程
- 基于梯度的方法(Gradient-Based Method):搜索空间连续 + 目标函数可微
- 穷举算法:
- 对采样的网络进行性能评估:定义如何评估搜索出的网络结构的性能,性能评估策略指能够降低性能评估成本的特定方法
- 主要评估标准:
- 提高分类精度
- 提高计算速度
- 两个方面入手:
- 减少训练时间
- 基于小规模代理任务:使用和实际任务同类型但规模更小或分辨率更低的数据集进行结构搜索,在搜索过程中用神经结构在代理任务上的性能来估计它在实际任务上的性能,当搜索完成后再将神经结构迁移到实际任务上
- 减少卷积核数量
- 快速评估模型性能
- 基于训练曲线:将神经结构只训练少量的迭代次数并在训练过程中记录神经结构的性能曲线,通过已有的性能曲线来预测未来的性能并提前停止训练预期性能不好的神经结构
- 基于搜索出的网络结构:基于网络结构提取特征信息拟合模型性能
- 减少训练时间
- 主要评估标准:
(4)NAS搜索加速策略
- 权重共享(Weight Sharing):DSO-NAS方法从一个完全连接的模块开始,通过引入缩放因子以缩放操作之间的信息流,然后对模块中的无用连接进行稀疏正则化,也就是去掉不重要的操作,得到最优结构
- 一次性结构搜索(One-Shot):将所有结构视为超图的不同子图,共享超图的权重,在一个过参数化的大网络中进行搜索,交替地训练网络权重和模型权重,最终只保留其中一个子结构
- 网态映射(Network Morphisms):将网络进行变形,同时保持其功能不变
(5)NAS核心目标
- 全自动的神经结构搜索方法,针对特定的任务,通过算法自动学习出适用的深度神经结构
三、A Study on Encodings for Neural Architecture Search论文学习
1、论文概要
论文由Abacus.AI公司、卡内基美隆大学合作完成,是NeurIPS 2020的论文之一。
近几年中,基于编码方式的NAS方法不断涌现,然而即使对每个结构的编码方式进行很小的更改,也会对NAS算法的性能有很大影响。这就存在一个问题:之前提出的基于编码方式的各种NAS算法中,不同编码的影响程度如何?
为此,本文拟探索不同编码方式对现有网络结构搜索算法的影响,从理论和实验两个方面进行研究分析:首先,通过基于邻接矩阵的编码和基于路径的编码(见图1)两种范式下,定义了八种不同的编码方式;其次,对各编码方式的扩展效果、对依赖于编码方式的三个NAS子过程(包括随机均匀采样结构特征,更改操作、边或路径,训练预测模型过程),进行了大量实验分析;最后,在文中总结不同子过程下常用的NAS算法 (例如贝叶斯优化的高斯过程、年龄进化算法、局部搜索算法、随机搜索算法等) 的最佳编码方式,从而可以作为未来研究工作的指南。
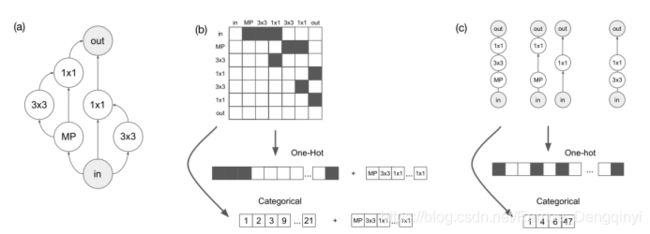 图1 神经结构a的基于邻接矩阵编码以及基于路径的编码,同时展示One-Hot编码及分类邻接矩阵编码方式
图1 神经结构a的基于邻接矩阵编码以及基于路径的编码,同时展示One-Hot编码及分类邻接矩阵编码方式
2、论文动机
(1)论文动机:
- 对神经结构的编码方式进行了首次正式研究
(2)对NAS神经结构编码方式进行研究:
- 基于邻接矩阵的编码
- One-hot邻接矩阵编码
- 分类邻接矩阵编码
- 连续邻接矩阵编码
- 基于路径的编码
- One-hot路径编码
- 截断的One-hot路径编码
- 分类路径编码
- 连续路径编码
- 截断连续路径编码
3、论文主要内容
(1)两种范式下编码方式对比:
- 基于邻接矩阵的编码
- 优点:
- 直观,容易理解
- 缺点:
- 结点是在矩阵中任意分配的索引
- 一个结构能够拥有许多不同的表示形式
- 优点:
- 基于路径的编码
- 优点:
- 结点不是任意分配的索引
- 同形结构会自动映射到相同的编码中
- 缺点:
- 不同的结构会映射到相同的编码上
- 优点:
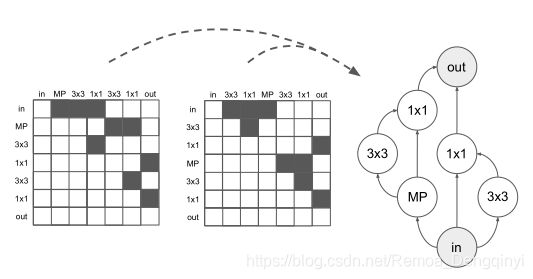 图2 右边所示网络结构拥有的左边两种不同的邻接矩阵表示形式
图2 右边所示网络结构拥有的左边两种不同的邻接矩阵表示形式
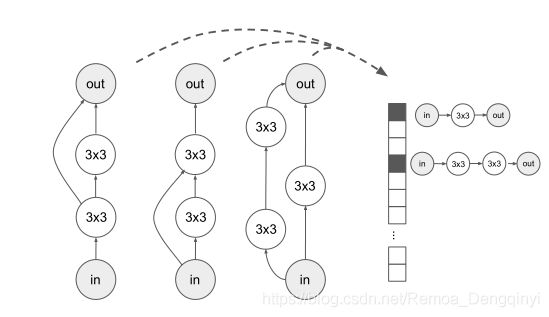 图3 三种不同网络结构映射为同一种编码
图3 三种不同网络结构映射为同一种编码
(3)依赖于编码方式的三个NAS子过程:
- 样本随机结构:
- 随机、均匀地采样编码每个特征
- 扰动结构:固定概率随机对编码每个特征统一采样
- 更改操作
- 增删边
- 增删路径
- 训练预测模型过程:
- 采用高斯过程的贝叶斯优化调参:结构编码之间的编辑距离
- 神经网络模型:编码→预测结构准确性
(4)论文中总结不同子过程下常用的NAS算法的最佳编码方式的实验结果:
以下展示的实验结果图片中缩写所对应的注释:
- Adj. 邻接矩阵编码
- Cont. Adj. 连续邻接矩阵编码
- Path 路径编码
- Trunc. Path 截断路径编码
- Trunc. Cont. Path 截断连续路径编码
- Uniform 均匀随机变量编码
- Cat. Adj. 分类邻接矩阵编码
- Cat. Path 分类路径编码
- Trunc. Cat. Path 截断分类路径编码
- Cat. Adj. 分类邻接矩阵编码
- Cat. Path 分类路径编码
- NASBOT Neural Architecture Search with Bayesian Optimisation and Optimal Transport
a)子过程1:样本随机结构
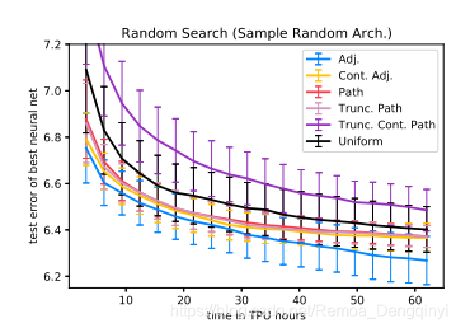 图4 随机搜索 其中邻接矩阵编码效果最好
图4 随机搜索 其中邻接矩阵编码效果最好
b)子过程2:扰动结构
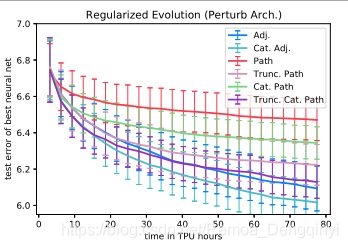 图5 年龄进化算法 其中分类邻接矩阵编码效果最好
图5 年龄进化算法 其中分类邻接矩阵编码效果最好
 图6 局部搜索算法 其中邻接矩阵编码效果最好
图6 局部搜索算法 其中邻接矩阵编码效果最好
c)子过程3:训练预测模型过程
 图7 采用高斯过程的贝叶斯优化调参 其中NASBOT及连续邻接矩阵编码效果最好
图7 采用高斯过程的贝叶斯优化调参 其中NASBOT及连续邻接矩阵编码效果最好
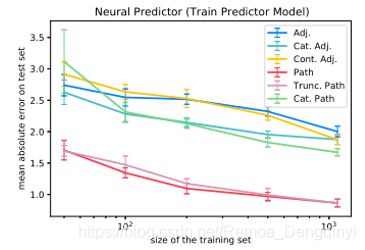 图8 神经预测模型 其中路径编码效果最好
图8 神经预测模型 其中路径编码效果最好
 图9 BANANAS数据集上对三个 子例程进行实验 其中截断路径及连续邻接矩阵编码效果最好
图9 BANANAS数据集上对三个 子例程进行实验 其中截断路径及连续邻接矩阵编码效果最好
4、论文重点内容翻译
Abstract
Neural architecture search (NAS) has been extensively studied in the past few years. A popular approach is to represent each neural architecture in the search space as a directed acyclic graph (DAG), and then search over all DAGs by encoding the adjacency matrix and list of operations as a set of hyperparameters. Recent work has demonstrated that even small changes to the way each architecture is encoded can have a significant effect on the performance of NAS algorithms (White et al., 2019; Ying et al., 2019). In this work, we present the first formal study on the effect of architecture encodings for NAS, including a theoretical grounding and an empirical study. First we formally define architecture encodings and give a theoretical characterization on the scalability of the encodings we study. Then we identify the main encoding-dependent subroutines which NAS algorithms employ, running experiments to show which encodings work best with each subroutine for many popular algorithms. The experiments act as an ablation study for prior work, disentangling the algorithmic and encoding-based contributions, as well as a guideline for future work. Our results demonstrate that NAS encodings are an important design decision which can have a significant impact on overall performance.
神经结构搜索在过去几年被广泛研究。一种流行的方法是将搜索空间中的每一神经结构表示为有向无环图(DAG),然后通过邻接矩阵和操作列表编码作为一组超参数,搜索所有的DAGs。最近的工作表明,即使对每个结构的编码方式进行很小的更改,也会对NAS算法的性能有很大影响(White等人,2019;Ying等人,2019)。在这项工作中,我们提出关于NAS结构编码效果的第一个正式研究,包括理论基础和实证研究。首先我们正式定义结构编码,并对所研究编码的可扩展性进行理论上的特性描述。然后我们确定NAS算法使用的主要依赖于编码的子例程,运行实验来显示对于许多流行算法,哪种编码方式在每个子例程中工作得最好。实验充当了之前工作的消融实验,解开了基于算法和编码的贡献,以及对未来工作的指南。我们的结果证明,NAS编码是一项重要的设计决策,能够对整体性能产生重大影响。
-
extensively adv. 广泛地,普遍
-
theoretical grounding phr. 理论基础
-
an empirical study phr. 实证研究
-
theoretical characterization phr. 理论描述
-
scalability n. 可扩展性,可伸缩性
-
subroutine n. 子例程,子程序
-
act as phr. 充当,担任
-
ablation study phr. 消融实验
-
disentangle v. 解开,松开
-
design decision phr. 设计决策
3 Encodings for NAS
We denote a set of neural architectures a by A (called a search space), and we define an objective function L : A → R, where L(a) is typically a combination of the neural network accuracy, model parameters, or FLOPS. We define a neural network encoding as an integer d and a multifunction e : A → R^d from a set of neural architectures A to a d-dimensional Euclidean space R^d , and we define a NAS algorithm A which takes as input a triple (A,L,e), and outputs an architecture a, with the goal that L(a) is as close to max a∈A L(a) as possible. Based on this definition, we consider an encoding e to be a fixed transformation, independent of L. In particular, NAS components that use L to learn a transformation of an input architecture (such as graph convolutional networks or autoencoders), are considered part of the NAS algorithm rather than the encoding. This is consistent with prior defintions of encodings (Ying et al., 2019; Talbi, 2020).
我们用A表示一组神经结构a(称为搜索空间),并且定义了一个目标函数L:A → R,其中L(a)通常是一个神经网络正确率、模型参数或者每秒浮点计算的组合。我们定义了一个编码为整型d和多功能e的神经网络: A → R^d,从一组神经结构A到d维欧几里得空间R^d,然后我们定义了一个NAS算法A,该算法的输入是一个三元组(A, L, e),输出是一个结构a,目标是让L(a)尽可能接近max a∈A L(a) 。基于这个定义,我们认为编码e是独立于L的一种固定变换。特别是,使用L来学习输入结构转换的NAS组件(例如图卷积神经网络或自动编码机),被视为NAS算法的一部分,而不是编码的一部分。这与编码的先前定义是一致的 (Ying 等人, 2019; Talbi, 2020)。
-
a set of phr. 一组
-
typically adv. 通常,一般
-
consider v. 认为
-
be consistent with phr. 符合,与…一致
We define eight different encodings split into two paradigms: adjacency matrix-based and path-based encodings. We assume that each architecture is represented by a DAG with at most n nodes, at most k edges, and q choices of operations on each node. For brevity, we focus on the case where nodes represent operations, though our analysis extends similarly to formulations where edges represent operations. Most of the following encodings have been defined in prior work (Ying et al., 2019; White et al., 2019; Talbi, 2020), and we will see in the next section that each encoding is useful for some part of the NAS pipeline.
我们定义了八种不同的编码方式,分为两种范式:基于邻接矩阵的编码和基于路径的编码。我们假设每一结构通过有向无环图(DAG)表示,它最多含有n个结点,最多含有k条边以及每一结点最多有q种操作选择。为简洁起见,我们将重点放在结点代表操作的情况,尽管我们的分析类似于边代表操作的表述。以下大部分编码已经在先前的工作中得到定义(Ying等人,2019;White等人,2019;Talbi,2020)。我们将会在下一节看到每一种编码对于NAS管道的某些部分很有用。
-
paradigm n. 范例,范式
-
for brevity phr. 为简洁起见
Adjacency matrix encodings. We first consider a class of encodings that are based on representations of the adjacency matrix. These are the most common types of encodings used in current NAS research. For visualizations of these encodings, see Figure A.1 (b).
邻接矩阵编码。首先我们考虑一类基于邻接矩阵表示的编码。这是在当前的NAS研究中最常用的编码类型。有关这些编码的可视化展示,见图A.1(b)。
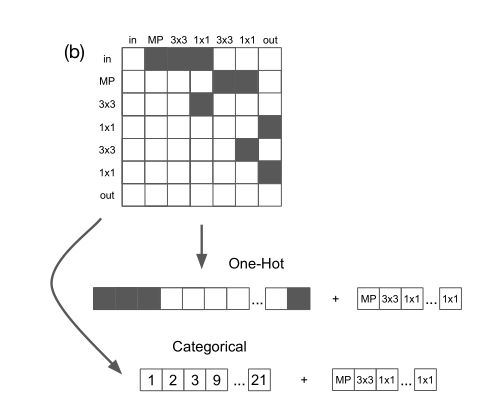 图A.1 (b) a的邻接矩阵表示,展示两种编码
图A.1 (b) a的邻接矩阵表示,展示两种编码
The one-hot adjacency matrix encoding is created by row-major vectorizing (i.e. flattening) the architecture adjacency matrix and concatenating it with a list of node operation labels. Each position in the operation list is a single integer-valued feature, where each operation is denoted by a different integer. The total dimension is n(n − 1)/2 + n. In the categorical adjacency matrix encoding, the adjacency matrix is first flattened (similar to the one-hot encoding described previously), and is then defined as a list of the indices each of which specifies one of the n(n − 1)/2 possible edges in the adjacency matrix. To ensure a fixed length encoding, each architecture is represented by k features, where k is the maximum number of possible edges. We again concatenate this representation with a list of operations, yielding a total dimensionality of k + n. Finally, the continuous adjacency matrix encoding is similar to the one-hot encoding, but each of the features for each edge can take on any real value in [0,1], rather than just {0,1}. We also add a feature representing he number of edges, 1 ≤ K ≤ k. The list of operations is encoded the same way as before.The architecture is created by choosing the K edges with the largest continuous features. The dimension is n(n−1)/2+n+1. The disadvantage of adjacency matrix-based encodings is that nodes are arbitrarily assigned indices in the matrix, which means one architecture can have many different representations (in other words, e^−1 is not onto).
One-hot邻接矩阵编码是通过行优先向量化(即展平)结构邻接矩阵和结点操作标签列表连接而创建的。操作列表上的每一位置是一个单一的整型值特征,其中每一操作都由不同的整型值表示。总的维度是n(n - 1)/2 + n。在分类邻接矩阵编码中,邻接矩阵首先被展平(类似于之前描述的one-hot编码),然后邻接矩阵定义为一个索引列表,每一个索引指向邻接矩阵中n(n - 1)/2个可能边。为了确保固定长度的编码,每一结构表示为k个特征,其中k是最大可能边数。我们再次将此表示形式与一系列操作连接起来,得出总维度为k + n。最后,连续邻接矩阵编码类似于one-hot编码,但是每一条边的每一特征能够表示为在[0, 1]区间上的任意实数值,而不仅仅表示为0和1。我们还添加了一个表示边数(1 ≤ K ≤ k)的特征。这个操作列表的编码方式和从前相同。通过选择具有最大连续特征的K条边来创建结构,维度是n(n-1)/2 + n + 1。基于邻接矩阵编码的缺点在于结点是在矩阵中任意分配的索引,意味着一个结构能够拥有许多不同的表示形式(换句话说,e^-1不存在)
-
vectorize v. 向量化,矢量化
-
flatten v. 平面化
-
concatenate v. 连接
-
arbitrarily adv. 反复地,任意地
Path-based encodings. Path-based encodings are representations of a neural architecture that are based on the set of paths from input to output that are present within the architecture DAG. For visualizations of these encodings, see Figure A.1 (c).
基于路径的编码。基于路径的编码是一个神经结构的表示形式,该神经结构基于一组从输入到输出的有向无环图中的路径。有关这些编码的可视化展示,见图A.1(c)
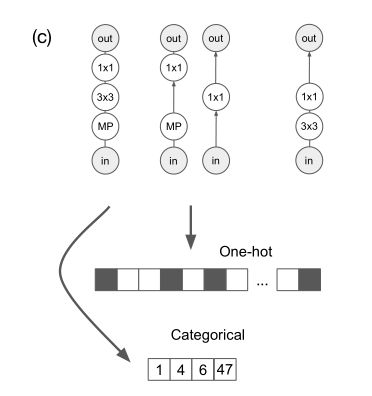 图A.1(c) a的基于路径表示,展示两种编码
图A.1(c) a的基于路径表示,展示两种编码
The one-hot path encoding is created by giving a binary feature to each possible path from the input node to the output node in the DAG (for example: input–conv1x1– maxpool3x3–output). The total dimension is Sum(i=0 to n) q^i = (q^(n+1) − 1)/(q − 1). The truncated one-hot path encoding, simply truncates this encoding to only include paths of length x. The new dimension is Sum(i=0 to x) q^i . The categorical path encoding, is defined as a list of indices each of which specifies one of the Sum(i=0 to x) q^i possible paths. The continuous path encoding consists of a real-valued feature [0,1] for each potential path, as well as a feature representing the number of paths. Just like the one-hot path encoding, the continuous path encoding can be truncated. Path-based encodings have the advantage that nodes are not arbitrarily assigned indices, and also that isomorphisms are automatically mapped to the same encoding. Path-based encodings have the disadvantage that different architectures can map to the same encoding (e is not onto).
One-hot路径编码通过给每一条可能的路径提供二进制特征创建,在有向无环图中从输入结点到输出结点(例如:输入-1x1卷积层-3x3最大池化层-输出)。总维度是Sum(i=0 to n) q^i = (q^(n+1) − 1)/(q − 1)。截断的one-hot路径编码,将截断这种编码为仅包括长度为x的路径。新的维度为:Sum(i=0 to x) q^i。分类路径编码,定义为索引列表。每一索引指向Sum(i=0 to x) q^i中一条可能的路径。连续路径编码包括每一可能路径的实数值特征[0, 1],以及代表路径数的特征。就像one-hot路径编码一样,连续路径编码也能够被截断。基于路径的编码的优势在于结点不是任意分配的索引,并且同形结构会自动映射到相同的编码中。基于路径的编码的缺点在于不同的结构能够映射到相同的编码上(换句话说,e不存在)
-
truncate v. 缩短,截去
-
simply adv. 仅
-
isomorphism n. 同形,类质同像
四、Cream of the Crop: Distilling Prioritized Paths For One-Shot Neural Architecture Search论文学习
1、论文概要
本文由微软亚洲研究院、清华大学、中国科学院、香港城市大学合作完成,是NeurIPS 2020的论文之一。
在One-Shot神经结构搜索中,虽然通过超网络预训练,不断地提取子网,并采用权重共享方法,给子网赋权,对子网的准确率进行验证,直到找到最好的子网为止。单次权重排序可能导致子网没有获得足够的训练,训练过程中计算资源消耗巨大,这就产生了一些问题:如何解决子网训练不足?如何提高训练过程灵活性从而降低计算资源开销?
针对以上问题,本文提出了一种优先路径提取方法,即通过在超网络中随机采样一条路径,训练该路径以更新相应的共享权重,在验证集上评估该路径的性能,并将性能好的路径存储到“优先路径面板”这个集合中(见图12)。其中,一条路径可视为一个网络结构。优先路径面板中的网络结构可以作为教师提升其他子网的训练,当有子网的性能超过优先路径面板性能最差的路径时,就将其替换实现面板的动态更新,通过这种方式可以有效解决子网训练不足的问题。同时,可以直接从优先路径面板中选择性能最佳的子网作为最终结构,不需要进一步在超网络上执行搜索,可以有效降低计算成本。
具体来说,训练过程主要包括三个迭代阶段(见图10),首先是优先路径选择阶段,通过元网络M从优先路径面板选择最佳拟合模型,输出ρ;然后从优先路径面板中提取知识到权重共享子网络,通过两个构造的目标函数求加权平均值;最后通过交叉熵损失函数计算子网验证损失,以改善自身的元网络,通过执行策略采样以及从自身的奖励中学习来进行强化学习。在ImageNet上的运行结果表明,在当前已有的主流方法中,本文提出的基于优先路径的One-Shot方法为最佳,在各种算力下,都取得了最少的计算资源消耗(GPU days),并且TOP-1准确度及TOP-5准确度均为最高。
 图10 基于优先路径方法的One-Shot神经结构搜索方法
图10 基于优先路径方法的One-Shot神经结构搜索方法
2、论文动机
(1)论文动机:
- 现有主要方法中存在一些局限性
- One-Shot 网络结构搜索算法:
- 主要步骤分为两个阶段:
- 训练阶段:训练超网络,使得超网络参数收敛至一定程度
- 搜索阶段:从超网络中不断提取子网,权重共享,给子网赋权,验证子网准确率,找到最好子网
- 优点:降低计算开销
- 局限性:超网络中每个子网络无法得到足够的训练(单次权重排序结构不足以反映真实性能);训练超网络成本很高,计算资源消耗巨大
- 主要步骤分为两个阶段:
- 教师模型:
- 优点:预先训练教师网络,再训练子网
- 局限性:限制搜索算法灵活性;全新的搜索任务可能没有可用的教师模型
- One-Shot 网络结构搜索算法:
(2)结合One-Shot NAS方法,提出:
- 提取优先路径方法:实现结构间知识转移,无需外部教师模型
- 面板引入:定义“优先路径面板”集合,在超网络中随机采样路径,训练并更新权重,经验证集上评估后将高性能路径存储到集合中;
- 协作训练:面板中网络结构作为教师提升其他子网训练;
- 优胜劣汰:当有子网性能超过面板中最差性能路径时,将二者替换以实现集合动态更新,有效解决子网训练不足问题;
- 结构选择:直接从面板中选择性能最佳子网作为最终结构,无需在超网络上进一步搜索,有效降低计算成本。
- 该方法找到的FLOPs模型,在ImageNet mobile setting上Top-1精度为79.2%,提高了4.5%的SPOS baseline(如图10)
- 在COCO验证集上平均准确率为33.2%,优于最新的MobileNetV3
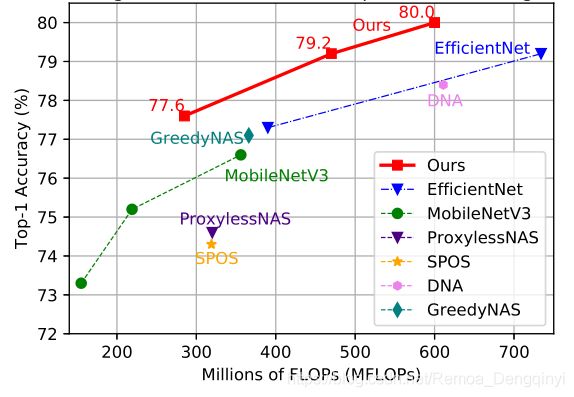 图11 ImageNet mobile setting(小于600M浮点运算数量)下本优先路径方法与其他典型方法比较
图11 ImageNet mobile setting(小于600M浮点运算数量)下本优先路径方法与其他典型方法比较
附注:FLOPS和FlOPs的区别:
- FLOPS:FLoating-point Operations Per Second,每秒浮点运算次数,用于衡量硬件或操作系统性能
- FLOPs:FLoating-point OPerations,浮点运算数,算力,用来衡量算法/模型复杂度
3、论文主要内容
(1)提出基于优先路径的方法,主要包括三个部分:
- 超网络(Hyper Network):包含搜索空间中所有子网络的大网络
- 优先路径面板(Prioritized Path Board):动态变化,根据面板中路径性能,实时更新优先路径
- 元网络(Meta Network):即子网的学习状态(验证损失)
(2)训练过程主要包括三个迭代阶段(如图11):
- 优先路径选择:元网络M从优先路径面板选择最佳拟合模型,输出ρ
- 从优先路径中提取知识:通过两个目标函数求加权平均值
- 元网络更新:观察子网验证损失,进行强化学习
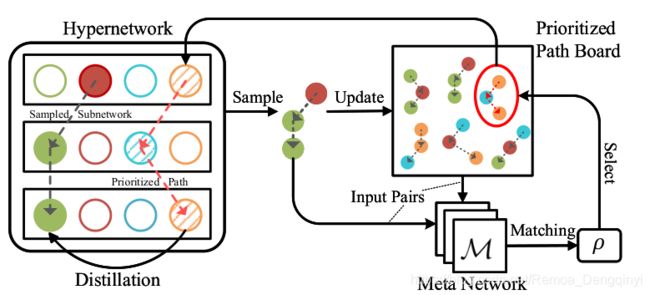 图12 提取优先路径方法训练流程
图12 提取优先路径方法训练流程
(3)实现目标:
- 直接从优先路径面板中选择性能最佳的子网作为最终结构,不用进一步在超网络上执行搜索
(4)实验结果:
- 当前已有方法中,提取优先路径方法为最佳,在各种算力下,都取得了最少的计算资源消耗(GPU days),TOP-1准确度及TOP-5准确度均为最高
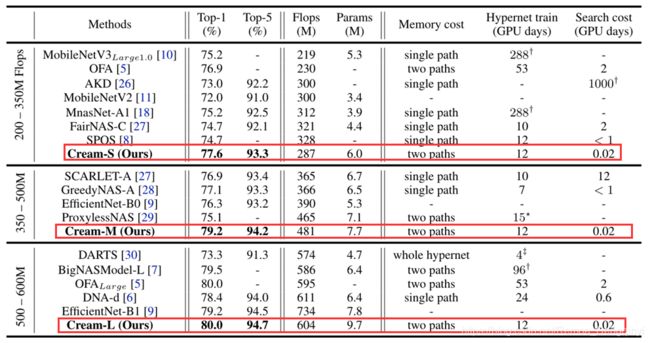 图13 各先进的NAS方法在ImageNet上的运行结果
图13 各先进的NAS方法在ImageNet上的运行结果
4、论文重点内容翻译
Abstract
One-shot weight sharing methods have recently drawn great attention in neural architecture search due to high efficiency and competitive performance. However, weight sharing across models has an inherent deficiency, i.e., insufficient training of subnetworks in the hypernetwork. To alleviate this problem, we present a simple yet effective architecture distillation method. The central idea is that subnetworks can learn collaboratively and teach each other throughout the training process, aiming to boost the convergence of individual models. We introduce the concept of prioritized path, which refers to the architecture candidates exhibiting superior performance during training. Distilling knowledge from the prioritized paths is able to boost the training of subnetworks. Since the prioritized paths are changed on the fly depending on their performance and complexity, the final obtained paths are the cream of the crop. We directly select the most promising one from the prioritized paths as the final architecture, without using other complex search methods, such as reinforcement learning or evolution algorithms. The experiments on ImageNet verify such path distillation method can improve the convergence ratio and performance of the hypernetwork, as well as boosting the training of subnetworks. The discovered architectures achieve superior performance compared to the recent MobileNetV3 and EfficientNet families under aligned settings. Moreover, the experiments on object detection and more challenging search space show the generality and robustness of the proposed method. Code and models are available at https://github.com/microsoft/cream.git.
One-Shot权重共享方法由于它的高效率及富有争力的性能,最近在神经结构搜索中引起了极大的关注。然而,模型之间的权重共享有其固有的缺陷,即在超网络中的子网无法得到足够的训练。为了减轻这个问题,我们提出了一种简单而高效的结构提取方法。中心思想是子网络能够在整个训练过程中进行协作学习和相互教授,目的是促进各个模型的收敛。我们介绍了优先路径的概念,它指的是在训练过程中表现出卓越性能的候选结构。从优先路径中提取知识能够促进子网络的训练。因为优先路径根据它们的性能和复杂性而动态改变,所以最终得到的路径是最优秀的。我们直接从优先路径中选择最有希望的一个结构作为最终的结构,无需使用其他复杂的搜索方法,例如强化学习或进化算法。在ImageNet数据集上的实验证明,这种路径提取方法能够提高超网络的收敛率以及性能,也增加了子网络的训练。与最新的MobileNetV3和EfficientNet系列在对齐设置下相比,发现的结构取得了更好的表现。此外,在目标检测和更具挑战性的搜索空间上的实验表明了该提出方法的通用性和鲁棒性。代码和模型可以在https://github.com/microsoft/cream.git中获得。
-
draw great attention phr. 引起极大关注
-
boost v. 促进,增加
-
convergence n. 收敛
-
refer to phr. 参考,指的是
-
change on the fly phr. 动态改变
-
depending on phr. 根据,取决于
-
the cream of the crop phr. 精英,精华,最优秀的
-
convergence ratio phr. 收敛比,收敛率
-
aligned a. 达成一致的,对齐的
1 Introduction
In this paper, we present prioritized paths to enable the knowledge transfer between architectures, without requiring an external teacher model. The core idea is that subnetworks can learn collaboratively and teach each other throughout the training process, and thus boosting the convergence of individual architectures. More specifically, we create a prioritized path board which recruits the subnetworks with superior performance as the internal teachers to facilitate the training of other models. The recruitment follows the selective competition principle, i.e., selecting the superior and eliminating the inferior. Besides competition, there also exists collaboration. To enable the information transfer between architectures, we distill the knowledge from prioritized paths to subnetworks. Instead of learning from a fixed model, our method allows each subnetwork to select its best-matching prioritized path as the teacher based on the representation complementary. In particular, a meta network is introduced to mimic this path selection procedure. Throughout the course of subnetwork training, the meta network observes the subnetwork’s performance on a held-out validation set, and learns to choose a prioritized path from the board so that if the subnetwork benefits from the prioritized path, the subnetwork will achieve better validation performance.
在本文中,我们提出了优先路径来使得知识在结构之间转移,而无需外部的教师模型。关键思想是子网能够在整个训练过程中进行协作学习和相互教授,从而促进了各个结构的收敛。更具体地说,我们创建了一个优先路径面板,招收性能优异的子网作为内部教师来促进其他模型的训练。招收遵循选择性竞争原则,即选择优等、淘汰劣等。除了竞争以外,也存在协作。为了使结构间的信息传递成为可能,我们将知识从优先路径提取到子网。我们的方法不是从固定的模型中学习,而是允许每一子网根据表示的补充去选择它的最优匹配的优先路径作为教师。特别地,引入元网络来模仿这种路径选择过程。在整个子网的训练过程中,元网络会在验证集上观察子网的性能,并学习从优先路径面板中选择优先路径,以便如果子网受益于优先路径,则子网将取得更好的验证性能。
-
transfer v. 转移
-
recruit v. 招募,招收
-
follow v. 跟随,遵循
-
instead of phr. 代替,而不是
-
representation complementary phr. 表示的补充
-
minic v. 模仿
-
the course of phr. 过程中
-
held-out Hold-out is when you split up your dataset into a ‘train’ and ‘test’ set. The training set is what the model is trained on, and the test set is used to see how well that model performs on unseen data. A common split when using the hold-out method is using 80% of data for training and the remaining 20% of the data for testing.“保留”是指你将数据集分成“训练”和“测试”两部分。训练集是模型的训练对象,而测试集则用来观察模型在未见数据上的表现如何。在使用保留方法时,一个常见的分歧是使用80%的数据进行训练,其余20%的数据进行测试。
Such prioritized path distillation mechanism has three advantages. First, it does not require introducing third-party models, such as human-designed architectures, to serve as the teacher models, thus it is more flexible. Second, the matching between prioritized paths and subnetworks are meta-learned, which allows a subnetwork to select various prioritized paths to facilitates its learning. Last but not the least, after hypernetwork training, we can directly pick up the best performing architecture from the prioritized paths, instead of using either reinforcement learning or evolutional algorithms to further search a final architecture from the large-scale hypernetwork.
这种优先路径提取机制有三个优点。第一,它不需要引入第三方模型(例如人工设计的结构)来作为教师模型,因此它更加灵活。第二,优先路径和子网之间的匹配是元学习的,允许一个子网选择各种优先路径来促进它的学习。第三,在超网络训练之后,我们能够直接从优先路径中得到最优性能的结构,而不是使用强化学习或者进化算法从大规模超网络中进一步搜索最终的结构。
-
mechanism n. 机制,原理
-
flexible a. 灵活