神经结构搜索资料NAS
神经结构进化搜索资料
近年来, 深度神经网络 (DNNs) 在许多人工智能任务中取得卓越表现,然而网络设计严重依赖专家知识,这是一个耗时且易出错的工作。于是, 作为自动化机器学习 (AutoML) 的重要子领域之一, 神经结构搜索 (NAS) 受到越来越多的关注, 旨在以自动化的方式设计表现优异的深度神经网络模型。[1]
目前主要的神经架构搜索可以分为以下三种,如下表1所示[2](以下是对参考文献二的整理)
表1
| 神经架构搜索算法 |
特点 |
| 强化学习(RL) |
需要数千个GPU工作好几天才能够完成预期的效果,例如CIFAR-10图像分类数据集,显示很难广泛应用。 |
| 基于梯度NAS算法 |
相比于强化学习,更加有效率,但是由于优化器的选择可能会导致病态,并且需要专家知识 |
| 基于演化计算的NAS算法 成为ENAS算法 |
广泛应用于解决非凸优化问题,甚至目标函数数学表达式未知的问题。 |
EC(Evolutionary Computation)是一种基于种群演化的算法,模拟物种或行为的进化
对自然界中的种群进行优化,以解决具有挑战性的优化问题。ENAS是通过EC来搜索最优DNN架构的过程,ENAS算法根据其他搜索策略可以进一步划分,如下图1所示,进化计算技术中根据优化方法采用的搜索策略,可以分为进化算法(evolution algorithm),群体智能(swarm intelligence)和其他方法。目前论文研究中进化算法占绝大多数,进一步遗传算法(GA)又占一大部分,遗传编程(GP)和进化策略(ES)均属于进化算法。群体智能算法中又包括粒子群优化方法(PSO)和蚁群算法(ACO)。同时,在其他分类中也存在差分进化(DE),萤火虫算法(FA)等,算法具体介绍可参考论文

图 1
ENAS算法的具体流程图如下图2所示。首先群体初始化,确定编码策略,从初始空间中构建个体,然后评估个体适应度。初始化完成后,进入群体进化阶段,从初始化群体中随机选择个体作为父代。根据搜索空间,进行交叉、变异等进化操作,对生成的个体评估其适应度。根据群体更新策略,选择保留的个体,加入到群体中,直到满足条件,返回最优的个体。上面算法主要涉及搜索空间的设计,编码,群体更新策略,以及评估加速方法。
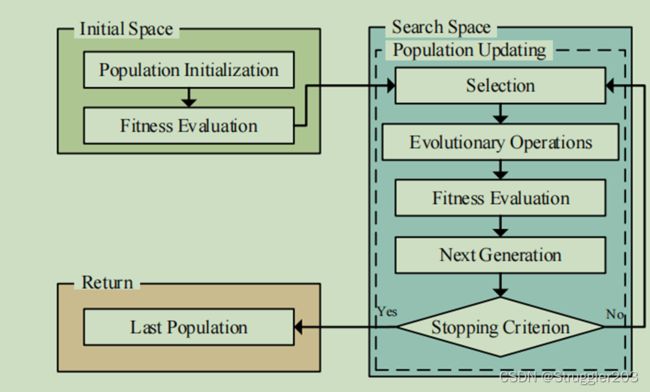
图2
以下将会分开具体介绍ENAS算法流程图中的每一部分
- 搜索空间
搜索空间包含组成有效个体的基本单元以及所有候选参数,根据搜索空间中基本单元的不同,大致分为三类,layer-based,block-based和cell-based搜索空间,此外,有些算法没有考虑基本单元内部参数,而是关心单元间的连接,这样的搜索空间称作topology-based空间。同时,搜索空间中的约束也是非常重要的,这表示人参与的程度。较多的约束可以得到较好的结构,但阻止了任何不在约束中的新结构。另外,不同大小的搜索空间也会影响搜索效率。(具体见论文5、6页)。
当前,搜索空间主要关注三方面,固定深度,丰富的初始化以及部分固定结构。固定深度表明群体中的所有个体结构有着相同的深度。丰富的初始化表示结构具有良好的设计,通常是人工设计的。部分固定结构意味着网络结构中有部分是确定的。相对较少的约束表明没有前面三个方面要求的较强的约束。
一般而言,初始化以及进化过程中的搜索空间是相同的,有时初始化时会加入一些人为约束,使得进化过程的搜索空间将大于初始化的搜索空间。
- 编码策略
每种ENAS方法在开始第一个阶段之前,需要确定如何将网络编码成个体。一般根据进化过程中个体长度是否变化,将编码策略分为固定长度编码以及可变长度编码。使用固定长度编码,在进化过程中个体拥有相同的长度。但是,需要定义一个合适的最大长度,因为这关系到网络结构的最优深度,但这依赖一定的专业知识以及经验。可变长度编码包含结构的更多细节以及更自由的表示,当面临一个新问题时,可以随机设置编码长度。(具体参考论文第6、7页)。
- 群体更新
通常现有ENAS算法中不同进化计算方法的更新机制不同,导致群体更新策略也各不相同。当前的ENAS研究中,EA-based算法占大多数,而GA-based是最受欢迎的方法。具体算法如下表二所示,(参考论文8、9页)
表二
| 群体更新算法 |
具体算法 |
算法简介 |
||
| 进化算法 |
Elitism |
精英主义方法会保留最高适应度的个体,但这种方法容易损失种群多样性,导致种群落入局部最优 |
||
| Discard the worst or the oldest |
丢弃最坏的个体与精英主义相似,从种群中移除最低适应度的个体。也有选择丢弃种群中最老的个体,这种方法可以更多的探索搜索空间不用过早的选择好模型 |
|||
| roulette wheel selection |
轮转法会根据群体中个体的适应度分配一个概率,无论好坏,将决定个体是否存活(或被丢弃) |
|||
| tournament selection |
锦标赛选择法从等概率采样的个体中选择最好的一个 |
|||
| Others |
在一些论文中,强调基因比存活个体更重要,基因可以表示结构中的任何成分。 |
|||
| 群体智能 |
粒子群优化(PSO) |
启发来自鱼群,利用群体中的个体对信息的共享使整个群体的运动再问题求解空间中产生从无序到有序的演化过程,从而获得最优解 |
||
| 蚁群算法(ACO) |
由自然界中蚂蚁觅食的行为而启发,每个蚂蚁根据信息素的指导从一个节点到另一个节点构建出一个结构,每代更新信息素,从而吸引下一代蚂蚁进行探索,由于信息素是逐渐衰减的,这也鼓励其他蚂蚁探索其他区域。最终得到一个最优结构。 |
|||
| 其他方法 |
进化差分(DE) |
首先,产生足量的随机变量,作为初始的可能解。接着进行突变、交叉、选择计算,一轮后,检查是否满足终止条件,若未满足,则重新突变、交叉、选择计算,最终输出最后一轮的最佳解 |
||
| 萤火虫算法(FA) |
是一种模仿萤火虫之间信息交流,相互吸引集合,算法中,每个萤火虫的位置代表了一个待求问题的可行解,而萤火虫的亮度表示该萤火虫位置的适应度,亮度越高的萤火虫个体在解空间中的位置越好 |
|||
| 爬山算法(HCA) |
是一种局部搜索算法,再增加高度的方向上连续移动,以找到山峰或最佳解决问题的方法。再达到峰值时终止,其中没有邻居具有更高的值 |
|||
| Coronavirus optimization algorithm(CVOA) |
通过模拟病毒传播以及感染健康个体从而发现最优结构 |
|||
4、评估加速
在进化NAS算法中,通常网络评估过程是最耗费时间的。几乎所有的方法评估个体,首先要进行训练,然后在验证集/测试集上评估效果。由于结构正变得越来越复杂,训练每一个结构要花费大量时间使其收敛。因此,有了各种不同的方法来缩短评估时间,减少计算资源消耗。常见的加速评估过程的方法有权重继承,早停,减小训练集,以及群体记忆,如下表3所示。
表3
| 评估加速算法 |
简介 |
| 权重继承 |
因为进化操作不会完全打破个体结构,新生成的个体的一些结构和它们父代相同。因而相同部分的权重可以很容易的继承过来。由于权重继承,不需要再从头训练网络。 |
| 早停策略 |
早停策略已被广泛用于NAS方法中,最简单的方式是设置一个固定且相对较小的训练epoch。但是,早停策略也导致评估个体表现不准确,特别对于大型,复杂结构 |
| 减少训练集 |
使用与大数据集相似特性的数据集子集,可以有效的缩短时间。一般与迁移学习结合将搜索出的模型迁移到大型数据集上 |
| 群体记忆 |
重用群体中前面出现过的结构信息。在基于群体方法,特别是基于遗传的算法中,会在后代中保留群体内表现良好的个体。有时下一代个体直接继承它们父代所有的结构信息,因此,不需要再重新评估该个体 |
参考文献
[1] 李航宇,王楠楠,朱明瑞,杨曦,高新波.神经结构搜索的研究进展综述[J].软件学报,2022,33(01):129-149.DOI:10.13328/j.cnki.jos.006306.
[2] Liu Y, Sun Y, Xue B, et al. A survey on evolutionary neural architecture search[J]. IEEE Transactions on Neural Networks and Learning Systems, 2021.