大数据—— Clickhouse 介绍与引擎的使用
一、Clickhouse 介绍
1.1 Clickhouse 介绍
ClickHouse 是一个用于联机分析(OLAP)的列式数据库管理系统(DBMS)。最初 是一款名为 Yandex.Metrica 的产品,主要用于 WEB 流量分析。ClickHouse 的全称是 Click Stream,Data WareHouse,简称 ClickHouse。
1.2 Clickhouse 的分布式架构
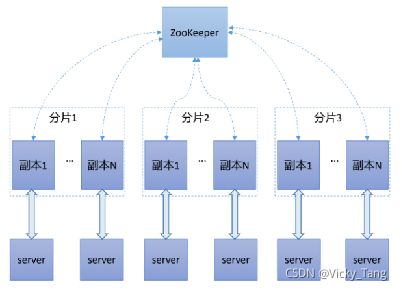
1.3 Clickhouse 的特性
(1)真正的面向列的DBMS
在一个真正的面向列的DBMS中,没有任何“垃圾”存储在值中。例如,必须支持定长数值,以避免在数值旁边存储长度“数字”。例如,十亿个UInt8类型的值实际_上应该消耗大约1 GB的未压缩磁盘空间,否则这将强烈影响CPU的使用。由于解压缩的速度(CPU 使用率)主要取决于未压缩的数据量,所以即使在未压缩的情况下,紧凑地存储数据(没有任何“垃圾”)也是非常重要的。另外,ClickHouse 是- -个DBMS,而不是一一个单- -的数据库。ClickHouse 允许在运行时创建表和数据库,加载数据和运行查询,而无需重新配置和重新启动服务器。
(2)数据压缩
数据压缩可以提高性能。ClickHouse除了在磁盘空间和CPU消耗之间进行不同权衡的高效通用压缩编解码器之外,ClickHouse还提供针对特定类型数据的专用编解码器,这使得ClickHouse能够与更小的数据库(如时间序列数据库)竞争并 超越它们。
(3)磁盘存储的数据
ClickHouse被设计用于工作在传统磁盘上的系统,它提供每GB更低的存储成本,但如果可以使用SSD和内存,它也会合理的利用这些资源。
(4)多核并行处理
多核多节点并行化大型查询。
(5)在多个服务器上分布式处理
在ClickHouse中,数据可以驻留在不同的分片上。每个分片可以是用于容错的一组副本。查询在所有分片上并行处理。
(6)SQL支持
(7)向量化引擎
数据不仅按列存储,而且由矢量-列的部分进行处理。这使我们能够提高高CPU使用性能。
(8)实时数据更新
ClickHouse支持主键表。为了快速执行对主键范围的查询,数据使用合并树(MergeTree)以增量的方式有序的存储。由于这个原因,数据可以不断地添加到表中。添加数据时无锁处理。
(9)索引
按照主键对数据进行排序,这将帮助ClickHouse在几十毫秒以内完成对数据特定值或范围的查找。
(10)支持在线查询
在没有对数据做任何预处理的情况下以极低的延迟处理查询并将结果加载到用户的页面中。
(11)支持近似计算
- 系统包含用于近似计算各种值,中位数和分位数的集合函数。
- 支持基于部分(样本)数据运行查询并获得近似结果。在这种情况下,从磁盘检索比例较少的数据。
- 支持为有限数量的随机密钥(而不是所有密钥)运行聚合。在数据中密钥分发的特定条件下,这提供了相对准确的结果,同时使用较少的资源
(12)数据复制和对数据完整性的支持
使用异步多主复制。写入任何可用的副本后,数据将分发到所有剩余的副本。系统在不同的副本上保持相同的数据。数据在失败后自动恢复,在一些少数的复杂情况下需要手动恢复。
1.4 ClickHouse的缺点
(1)不支持事务。
(2)不擅长Update/Delete操作。仅能用于批量删除或修改数据。
(3)不擅长根据主键按行粒度进行查询( 虽然支持),故不应该把ClickHouse当作Key-Value数据库使用。
二、ClickHouse 的数据类型

2.1 整型
固定长度的整型,包括有符号整型或无符号整型。
整型范围(-2^n-1 ~2^n-1-1) :
Int8 -[-128: 127]
Int16- [-32768 : 32767]
Int32 - [-2147483648 : 2147483647]
Int64 - [-9223372036854775808 : 9223372036854775807]
无符号整型范围(0~2^n-1): 没有负数。
UInt8- [0 : 255]
UInt16- [0 : 65535]
UInt32- [0 : 4294967295]
UInt64- [0 : 18446744073709551615]
2.2 浮点型
Float32 - float
Float64 - double
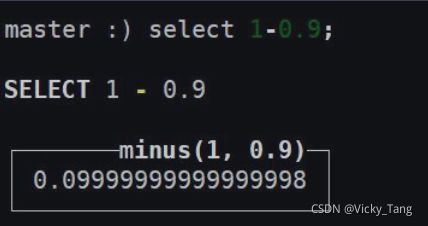
建议尽可能以整数形式存储数据。例如,将固定精度的数字转换为整数值,如时间用毫秒为单位表示,因为浮点型进行计算时可能引起四舍五入的误差。
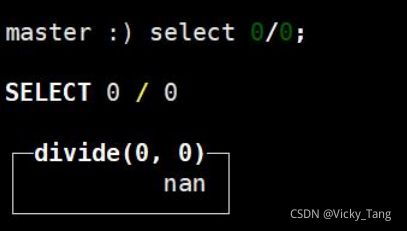
inf 正无穷
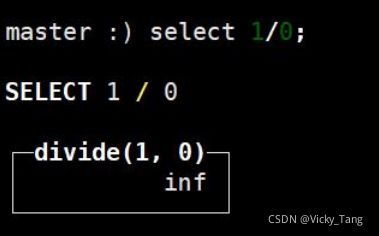
-inf 负无穷
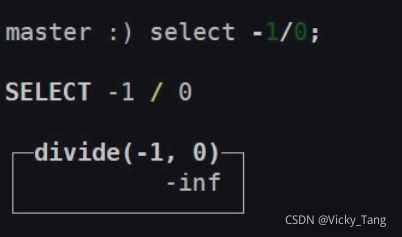
nan 非数字
2.3 布尔类型(没有)
clickhouse没有布尔类型,可以使用UInt8 类型,利用枚举将取值限制为0或1。
2.4 字符串
String
字符串可以任意长度的。它可以包含任意的字节集,包含空字节。
FixedString(N)
固定长度N的字符串,N必须是严格的正自然数。当服务端读取长度小于N的字符串时候,通过在字符串末尾添加空字节来达到N字节长度。当服务端读取长度大于N的字符串时候,将返回错误消息。
与String 相比,极少会使用FixedString, 因为使用起来不是很方便。
2.5 枚举
包括Enum8和Enum16类型。Enum只支持'string'= int的对应类型。
Enum8用'String'= Int8对描述。
Enum16用'String'= Int16对描述。

 可以通过 cast 转换函数,打印出来对应的值。
可以通过 cast 转换函数,打印出来对应的值。

2.6 数组
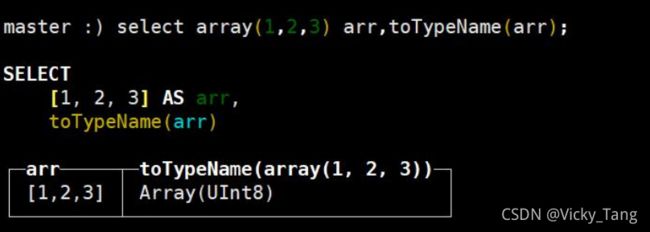
Array(T):由T类型元素组成的数组。
T可以是任意类型,包含数组类型。但不推荐使用多维数组,ClickHouse 对多维数组的支持有限。例如,不能在MergeTree表中存储多维数组。
创建数组方式1,使用array 函数:
创建数组方式 2:使用方括号:

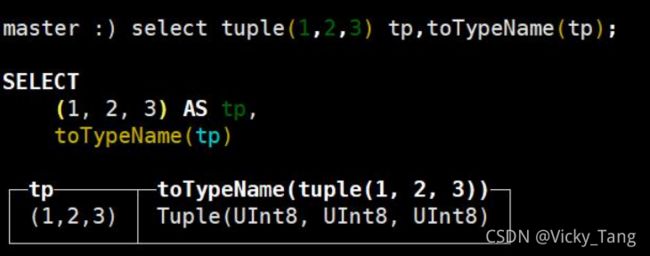
2.7 元组
创建元组方式 1,使用 tuple 函数:
创建元组方式 2,使用()即可:

2.8 日期
目前ClickHouse 有三种时间类型
Date接受年月-日的字符串比如2019-12-16'
Datetime接受年月-日时:分:秒的字符串 比如2019-12-16 20:50:10'
Datetime64接受年一月一日时:分:秒,亚秒的字符串比如' 2019-12-16 20:50:10.66'
所有的时间日期函数都可以在第二个可选参数中接受时区参数。示例: Asia/ Yekaterinburg。在这种情况下,它们使用指定的时区而不是本地(默认)时区。
SELECT
toDateTime('2021-01-01 23:00:00') AS time,
toDate(time) AS date_local,
toDate(time, 'Asia/Yekaterinburg') AS date_yekat,
toString(time, 'US/Samoa') AS time_samoa;

常用的日期处理函数:
now() # 2020-04-01 17:25:40 取当前时间
toYear() # 2020 取日期中的年份
toMonth() # 4 取日期中的月份
today() # 2020-04-01 今天的日期
yesterday() # 2020-03-31 昨天的额日期
toDayOfYear() # 92 取一年中的第几天
toDayOfWeek() # 3 取一周中的第几天
toHour() # 17 取小时
toMinute() # 25 取分钟
toSecond() # 40 取秒
toStartOfYear() # 2020-01-01 取一年中的第一天
toStartOfMonth() # 2020-04-01 取当月的第一天
formatDateTime(now(),'%Y-%m-%d') # 2020*04-01 指定时间格式
toYYYYMM() # 202004
toYYYYMMDD() # 20200401
toYYYYMMDDhhmmss() # 20200401172540
dateDiff()
......三、表引擎
3.1 表引擎的介绍
表引擎是ClickHouse 的一大特色。如果对MySQL熟悉的话,或许你应该听说过InnoDB。可以说,表引 擎决定了如何存储表的数据。
包括:
数据的存储方式和位置,写到哪里以及从哪里读取数据。
支持哪些查询以及如何支持。
并发数据访问。
索引的使用(如果存在)。
是否可以执行多线程请求。
数据复制参数。
表引擎的使用方式就是必须显式在创建表时定义该表使用的引擎,以及引擎.使用的相关参数。
特别注意:引擎的名称大小写敏感。
3.2 表引擎的分类

3.3 Log系列表引擎
3.3.1 Log系列表引擎的介绍
Log系列表引擎功能相对简单,主要用于快速写入小表(1百万行左右的表), 然后全部读出的场景。即一次写入多次查询。
3.3.2 Log系列表引擎的特点
数据存储在磁盘上。
当写数据时,将数据追加到文件的末尾。
不支持并发读写,当向表中写入数据时,针对这张表的查询会被阻塞,直至写入动作结束。
不支持索引。
不支持原子写:如果某些操作(异常的服务器关闭)中断了写操作,则可能会获得带有损坏数据的表。
不支持ALTER操作(这些操作会修改表设置或数据,比如delete、update 等等)。
3.3.3 Log系列表引擎的区别
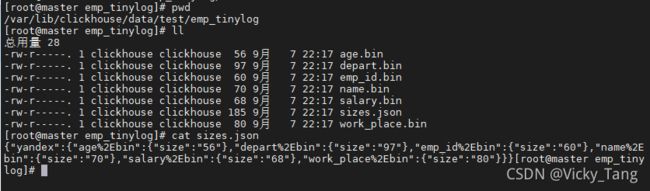
TinyLog是Log系列引擎中功能简单、性能较低的引擎。它的存储结构由数据文件和元数据两部分组成。其中,数据文件是按列独立存储的,也就是说每一个列字段都对应一一个文件。 除此之外,TinyLog 不支持并发数据读取。
StripLog支持并发读取数据文件,当读取数据时,ClickHouse 会使用多线程进行读取,每个线程处理一个单独的数据块。另外,StripLog 将所有列数据存储Log支持并发读取数据文件,当读取数据时,ClickHouse会使用多线程进行读取,每个线程处理-~个单独的数据块。Log引擎会将每个列数据单独存储在一个独立文件中。
3.3.4 TinyLog
该引擎适用于一次写入,多次读取的场景。对于处理小批数据的中间表可以使用该引擎。值得注意的是,使用大量的小表存储数据,性能会很低。
CREATE TABLE emp_tinylog (
emp_id UInt16 COMMENT'员工id',
name String COMMENT'员工姓名',
work_place String COMMENT'工作地点',
age UInt8 COMMENT'员工年龄',
depart String COMMENT '部门',
salary Decimal32(2) COMMENT '工资'
)ENGINE=TinyLog();
INSERT INTO emp_tinylog
VALUES (1,'tom','上海',25,'技术部',20000),(2,'jack','上海',26,'人事部',10000);
INSERT INTO emp_tinylog
VALUES (3,'bob','北京',33,'财务部',50000),(4,'tony','杭州',28,'销售事部',50000);
可以在/var/lib/clickhouse/data查看CK中的数据。TinyLog引擎表每一列都对应的文件。在sizes.json文件内使用JSON格式记录了每个. bin 文件内对应的数据大小的信息。
当我们执行ALTER操作时会报错,说明该表引擎不支持ALTER操作。
ALTER TABLE emp_tinylog DELETE WHERE emp_id= 5;
ALTER TABLE emp_inylog UPDATE age = 30 WHERE emp_id= 4;
![]()
3.3.5 StripLog
相比TinyLog而言,StripeLog 拥有更高的查询性能( 拥有.mrk标记文件,支持并行查询),同时其使用了更少的文件描述符(所有数据使用同一个文件保存)。
CREATE TABLE emp_stripelog (
emp_id UInt16 COMMENT '员工id',
name String COMMENT'员工姓名',
work_place String COMMENT '工作地点',
age UInt8 COMMENT '员工年龄',
depart String COMMENT '部门',
salary Decimal32(2) COMMENT '工资'
)ENGINE=StripeLog;
--插入数据
INSERT INTO emp_stripelog
VALUES (1,'tom','上海',25,'技术部',20000),(2,'jack','上海',26,'人事部',10000);
INSERT INTO emp_stripelog
VALUES (3,'bob','北京',33,'财务部',0000),(,'tony','杭州',28,'销售事部',50000);
--查询数据
select * from emp_stripelog;
进入默认数据存储目录,查看底层数据存储形式。

可以看出StripeLog表引擎对应的存储结构包括三个文件:
data.bin:数据文件,所有的列字段使用同一个文件保存,它们的数据都会被写入data.bin.
index.mrk:数据标记,保存了数据在data.bin文件中的位置信息(每个插入数据块对应列的offset),利用数据标记能够使用多个线程,以并行的方式读取data.bin内的压缩数据块,从而提升数据查询的性能。
sizes.json:元数据文件,记录了data.bin和index.mrk大小的信息。
注意: StripeLog 引擎将所有数据都存储在了一个文件中,对于每次的INSERT操作,ClickHouse 会将数据块追加到表文件的末尾,StripeLog 引擎同样不支持ALTER UPDATE和ALTER DELETE操作。
3.3.6 Log
Log引擎表适用于临时数据,一次性写入、测试场景。Log引擎结合了TinyLog ;表引擎和Stripelog表引擎的长处,是Log系列引擎中性能最高的表引擎。
CREATE TABLE emp_log(
emp_id UInt16 COMMENT '员工id',
name String COMMENT '员工姓名',
work_place String COMMENT '工作地点',
age UInt8 COMMENT '员工年龄',
depart String COMMENT '部门',
salary Decimal32(2) COMMENT '工资'
)ENGINE=Log;
-- 插入数就
INSERT INTO emp_log VALUES (1,'tom','上海',25,'技术部',20000),(2,'jack','上海',26,'人事部',1000);
INSERT INTO emp_log VALUES (3,'bob','北京',33,'财务部',50000),(4,'tony','杭州',28,'销售事部',50000);
Log 引擎的存储结构:

_marks.mrk:数据标记,统一保存了数据在各个.bin文件中的位置信息。利用数据标记能够使用多个线程,以并行的方式读取。.bin 内的压缩数据块,从而提升数据查询的性能。Log 表引擎会将每一列都存在-一个文件中,对于每一次的INSERT操作,都会对应一个数据块。
3.4 MergeTree系列表引擎
在所有的表引擎中,最为核心的当属MergeTree系列表引擎,这些表引擎拥有最为强大的性能和最广泛的使用场合。对于非MergeTree系列的其他引擎而言,主要用于特殊用途,场景相对有限。而MergeTree系列表引擎是官方主推的存储引擎,支持几乎所有ClickHouse核心功能。
3.4.1 MergeTree
MergeTree在写入一批数据时,数据总会以数据片段的形式写入磁盘,且数据片段不可修改。为了避免片段过多,ClickHouse 会通过后台线程,定期合并这些数据片段,属于相同分区的数据片段会被合成-一个新的片段。这种数据片段往复合并的特点,也正是合并树名称的由来。
特点:
需要指定主键,数据按照主键排序。
可以使用分区,可以通过PARTITION KEY语句指定分区字段,开发中一般按月进行分区。
支持数据副本,保证安全性。
支持数据采样。
格式:
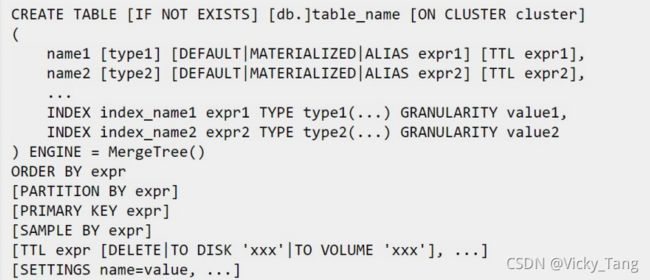
ENGINE - 引擎名和参数。MergeTree 无参数。
ORDERBY - 排序键。可以是一-组列的元组或任意的表达式。例如: ORDER BY
(CounterlD, EventDate)。
如果没有使用PRIMARYKEY显式指定的主键,ClickHouse会使用排序键作为主键。
PARTITIONBY - 分区键,可选项。
要按月分区,可以使用表达式toYYYMM(date_ column) ,这里的date_ column 是一个Date 类型的列。分区名的格式会是"YYYMM"。
PRIMARY KEY - 如果要选择与排序键不同的主键,在这里指定,可选项。
默认情况下主键跟排序键(由ORDERBY子句指定)相同。
因此,大部分情况下不需要再专门指定-一个PRIMARY KEY子句。
SAMPLE BY - 用于抽样的表达式,可选项。
如果要用抽样表达式,主键中必须包含这个表达式。例如: .
SAMPLE BY intHash32(UserlD) ORDER BY (CounterlD, EventDate,intHash32(UserlD))。
TTL - 数据的存活时间。在MergeTree中,可以为某个列字段或整张表设置TTL。当时间到达时,如果是列字段级别的TTL,则会删除这一-列的数据;如果是表级别的TTL,则会删除整张表的数据。可选项。
SETTINGS - 控制MergeTree 行为的额外参数,可选项:
index_ granularity — 索引粒度。索引中相邻的 【标记】间的数据行数。默认值8192
use_ minimalistic _part_ header_in_zookeeper 一 ZooKeeper 中数据片段存储方式。如果use_minimalistic_part_header_in_zookeeper=1 ,ZooKeeper 会存储更少的数据。
min_merge_bytes_to_use_direct_io — 使用直接I/0 来操作磁盘的合并操作时要求的最小数据量。合并数据片段时,ClickHouse会计算要被合并的所有数据的总存储空间。如果大小超过了min_merge_bytes_to_use_direct_io设置的字节数,则ClickHouse将使用直接I/O 接口(O_DIRECT选项)对磁盘读写。如果设置min_ merge_ .bytes_ to_ use_ _direct_ io=0,则会禁用直接l/0。 默认值: 10* 1024* 1024* 1024字节。(大于10G直接IO,小于10G缓冲IO)。
CREATE TABLE emp_mergetree (
emp_id UInt16 COMMENT'员工id',
name String COMMENT'员工姓名',
work_place String COMMENT '工作地点',
age UInt8 COMMENT '员工年龄',
depart String COMMENT'部门',
salary Decimal32(2) COMMENT'工资'
)ENGINE=MergeTree()
ORDER BY emp_id
PARTITION BY work_place;
--插入数据
INSERT INTO emp_mergetree VALUES (1,'tom','上海',25,'技术部',20000),(2,'jack','上海',26,'人事部',10000);
INSERT INTO emp_mergetree VALUES (3,'bob','北京',33,'财务部',50000),(4,'tony','杭州',28,'销售事部',50000);
-- 查询数据
select * from emp_mergetree;
可以在对应的/var/lib/clickhouse/data/test/emp_mergetree 表目录下看到插入的三条数据被放入了不同子目录中。

任何一个批次的数据写入都会产生一个临时分区,不会纳入任何一个已有的分区。写入后的某个时刻(大概10-15分钟后),ClickHouse 会自动执行合并操作(等不及也可以手动通过optimize执行),把临时分区的数据,合并到已有分区中。
--例如继续插入数据:
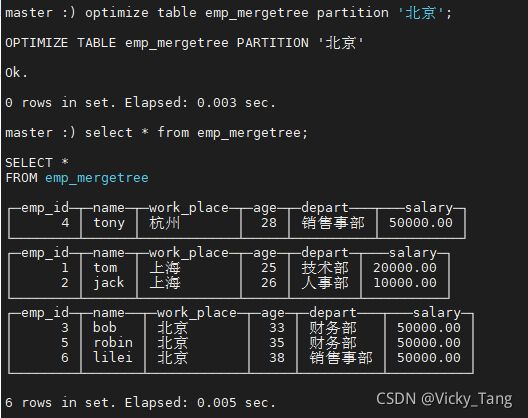
INSERT INTO emp_mergetree VALUES (5,'robin','北京',35,'财务部',50000),(6,'lilei','北京',38,'销售事部',50000);
发现数据没有合并

手动触发合并
optimize table emp_mergetree partition '北京';再次查询就能看到数据合并
插入相同主键,相同分区数据
INSERT INTO emp_mergetree VALUES (1,'sam','上海',35,'财务部',50000); 触发合并
optimize table emp_mergetree partition '上海';再次查询: (发现数据没有去重,说明主键没有去重功能,没有唯一约束性)
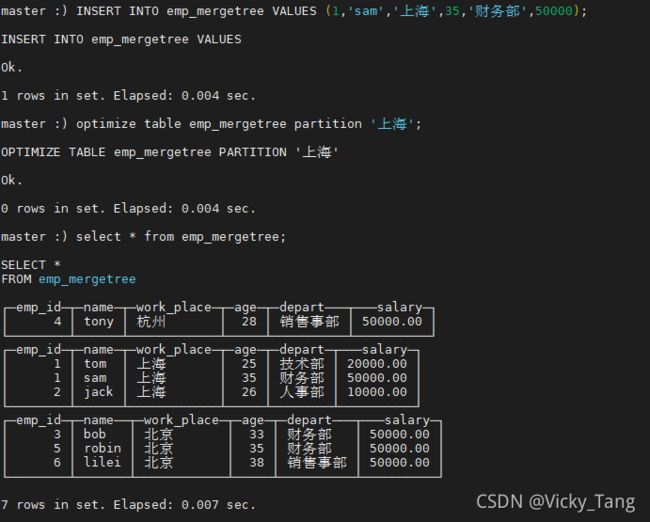
在 MergeTree 中主键并不用于去重,而是用于索引,加快查询速度。
3.4.2 ReplacingMergeTree
MergeTree表引擎无法对相同主键的数据进行去重,ClickHouse 提供了ReplacingMergeTree引擎,可以针对相同主键的数据进行去重,它能够在合并分区时删除重复的数据。值得注意的是,ReplacingMergeTree只是在一定程度上解决了数据重复问题,但是并不能完全保障数据不重复。
格式:

ver 一 版本列。类型为UInt*, Date或DateTime。 可选参数。
在数据合并的时候,ReplacingMergeTree 从所有具有相同排序键的行中选择一行留下:
如果ver列未指定,保留最后一条。
如果ver 列已指定,保留ver值最大的版本。
示例:
CREATE TABLE emp_replacingmergetree (
emp_id UInt16 COMMENT '员工 id',
name String COMMENT '员工姓名',
work_place String COMMENT '工作地点',
age UInt8 COMMENT '员工年龄',
depart String COMMENT '部门',
salary Decimal32(2) COMMENT '工资'
)ENGINE=ReplacingMergeTree()
ORDER BY (emp_id,name)
PRIMARY KEY emp_id
PARTITION BY work_place;
--插入数据
INSERT INTO emp_replacingmergetree VALUES (1,'tom','上海',25,'技术部',20000),(2,'jack','上海',26,'人事部',10000);
INSERT INTO emp_replacingmergetree VALUES (3,'bob',' 北 京 ',33,' 财 务 部 ',50000),(4,'tony',' 杭 州 ',28,' 销 售 事 部 ',50000);
插入相同分区相同主键、相同分区相同 ORDER BY 键的数据:
INSERT INTO emp_replacingmergetree VALUES (1,'susan','上海',26,'技术部',20000),(1,'tom','上海',26,'技术部',30000);
--手动触发合并操作
optimize table emp_replacingmergetree final;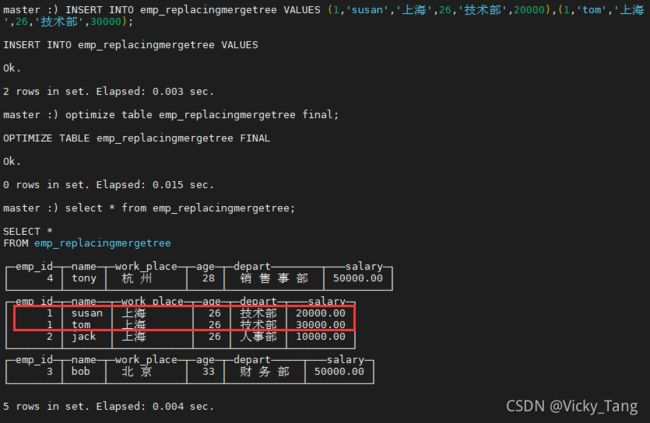
插入不同分区相同 ORDER BY 键的数据:
INSERT INTO emp_replacingmergetree VALUES (1,'tom','北京',26,'技术部',40000);
--手动触发合并操作:
optimize table emp_replacingmergetree final;
ReplacingMergeTree 是支持去重的,并且是按照 ORDERBY 排序键为基准进行 去重的,而不是主键。
- 通过测试得到结论:
-
实际上是使用 order by 字段作为唯一键
-
去重不能跨分区
-
只有合并分区才会进行去重
-
认定重复的数据保留版本字段值最大的
-
如果版本字段相同则按插入顺序保留最后一笔
-
3.4.3 SummingMergeTree
该引擎继承自MergeTree。 区别在于,当合并SummingMergeTree 表的数据片段时,ClickHouse会把所有具有相同主键的行合并为一-行,该行包含了被合并的行中具有数值数据类型的列的汇总值。即如果存在重复的数据,会对对这些重复的数据进行合并成- - 条数据,类似于group by的效果。
如果用户只需要查询数据的汇总结果,不关心明细数据,并且数据的汇总条:件是预先明确的,即GROUP BY的分组字段是确定的,可以使用该表引擎。

columns-包含了将要被汇.总的列的列名的元组。叫选参数。
所选的列必须是数值类型,并且不可位于主键中。
如果没有指定columns',ClickHouse会把所有不在主键中的数值类型的列都进行汇总。
示例:
CREATE TABLE emp_summingmergetree (
emp_id UInt16 COMMENT '员工 id',
name String COMMENT '员工姓名',
work_place String COMMENT '工作地点',
age UInt8 COMMENT '员工年龄',
depart String COMMENT '部门',
salary Decimal32(2) COMMENT '工资'
)ENGINE=SummingMergeTree(salary)
PARTITION BY work_place
ORDER BY (emp_id,name) -- 注意排序 key 是两个字段
PRIMARY KEY emp_id -- 主键是一个字段
;
-- 插入数据
INSERT INTO emp_summingmergetree VALUES (1,'tom','上海',25,'技术部',20000),(2,'jack','上海',26,'人事部',10000);
INSERT INTO emp_summingmergetree VALUES (3,'bob',' 北 京 ',33,' 财 务 部 ',50000),(4,'tony',' 杭 州 ',28,' 销 售 事 部 ',50000);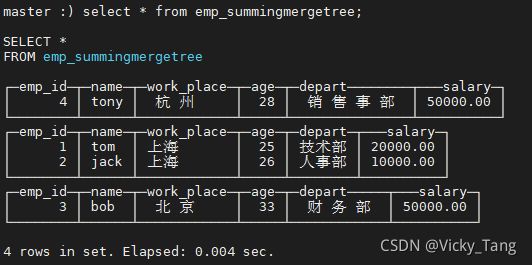
当我们再次插入具有相同 emp_id,name 的数据时
INSERT INTO emp_summingmergetree VALUES (1,'tom','上海',25,'信息部',10000),(1,'tom','北京',26,'人事部',10000);
-- 执行合并操作
optimize table emp_summingmergetree final; 
通过测试得到结论:
SummingMergeTree 用 ORBER BY 排序键作为聚合数据的条件 Key。即如果排 序 key 是相同的,则会合并成一条数据,并对指定的合并字段进行聚合。
以数据分区为单位来聚合数据。当分区合并时,同-一-数据分区内聚合Key相同的数据会被合并汇总,而不同分区之间的数据则不会被汇总。
如果没有指定聚合字段,则会按照非主键的数值类型字段进行聚合。.
如果两行数据除了排序字段相同,其他的非聚合字段不相同,那么在聚合发生时,会保留最初的那条数据,新插入的数据对应的那个字段值会被舍弃。
3.4.4 Aggregatingmergetree
该表引擎继承自MergeTree,可以使用AggregatingMergeTree 表来做增量数据统计聚合。如果要按一组规则来合 并减少行数,则使用AggregatingMergeTree是合适的。AggregatingMergeTree 是通过预先定义的聚合函数计算数据并通过二进制的格式存入表内。与SummingMergeTree的区别在于: SummingMergeTree对非主键列进行sum聚合,而AggregatingMergeTree则可以指定各种聚合函数。
示例:
CREATE TABLE emp_aggregatingmergeTree (
emp_id UInt16 COMMENT '员工 id',
name String COMMENT '员工姓名',
work_place String COMMENT '工作地点',
age UInt8 COMMENT '员工年龄',
depart String COMMENT '部门',
salary AggregateFunction(sum,Decimal32(2)) COMMENT '工资' )ENGINE=AggregatingMergeTree()
PARTITION BY work_place
ORDER BY (emp_id,name) -- 注意排序 key 是两个字段
PRIMARY KEY emp_id -- 主键是一个字段
;对于AggregateFunction类型的列字段,在进行数据的写入和查询时与其他的表引擎有很大区别,在写入数据时,需要调用** -State函数;而在查询数据时, 则需要调用相应的-Merge函数。对于上面的建表语句而言,需要使用sumState**函数进行数据插入。
-- 需要使用 INSERT…SELECT 语句进行数据插入
INSERT INTO TABLE emp_aggregatingmergeTree
SELECT 1,'tom','上海',25,'信息部',sumState(toDecimal32(10000,2));
INSERT INTO TABLE emp_aggregatingmergeTree
SELECT 1,'tom','上海',25,'信息部',sumState(toDecimal32(20000,2));
-- 查询
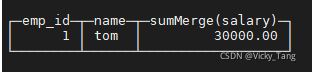
SELECT emp_id, name , sumMerge(salary) FROM emp_aggregatingmergeTree GROUP BY emp_id,name;
上面演示的用法非常的麻烦,其实更多的情况下,我们可以结合物化视图一 起使用,将它作为物化视图的表引擎。而这里的物化视图是作为其他数据表上层 的一种查询视图。
AggregatingMergeTree 通常作为物化视图的表引擎,与普通 MergeTree 搭配使用。
-- 创建一个 MereTree 引擎的明细表
-- 用于存储全量的明细数据
-- 对外提供实时查询
CREATE TABLE emp_mergetree_base (
emp_id UInt16 COMMENT '员工 id',
name String COMMENT '员工姓名',
work_place String COMMENT '工作地点',
age UInt8 COMMENT '员工年龄',
depart String COMMENT '部门',
salary Decimal32(2) COMMENT '工资'
)ENGINE=MergeTree()
ORDER BY (emp_id,name)
PARTITION BY work_place;
-- 创建一张物化视图
-- 使用 AggregatingMergeTree 表引擎
CREATE MATERIALIZED VIEW view_emp_agg
ENGINE = AggregatingMergeTree()
PARTITION BY emp_id
ORDER BY (emp_id,name) AS SELECT emp_id, name, sumState(salary) AS salary
FROM emp_mergetree_base
GROUP BY emp_id,name;
-- 向基础明细表 emp_mergetree_base 插入数据
INSERT INTO emp_mergetree_base VALUES (1,'tom','上海',25,'技术部',20000),(1,'tom','上海',26,'人事部',10000);
-- 查询物化视图
SELECT emp_id, name , sumMerge(salary)
FROM view_emp_agg
GROUP BY emp_id,name;
3.4.5 CollapsingMergeTree
CollapsingMergeTree就是一种通过以增代删的思路,支持行级数据修改和删除的表引擎。它通过定义一.个sign标记位字段,记录数据行的状态。如果sign标记为1,则表示这是一行有效的数据;如果sign标记为-1,则表示这行数据需要被删除。当CollapsingMergeTree分区合并时,同一数据分区内,sign 标记为1和-1的一组数据会被抵消删除。
每次需要新增数据时,写入一行sign标记为1的数据;需要删除数据时,则写入一行sign标记为-1的数据。

示例:
CREATE TABLE emp_collapsingmergetree (
emp_id UInt16 COMMENT '员工 id',
name String COMMENT '员工姓名',
work_place String COMMENT '工作地点',
age UInt8 COMMENT '员工年龄',
depart String COMMENT '部门',
salary Decimal32(2) COMMENT '工资',
sign Int8
)ENGINE=CollapsingMergeTree(sign)
ORDER BY (emp_id,name)
PARTITION BY work_place;
CollapsingMergeTree同样是以ORDER BY 排序键作为判断数据唯一性的依据。
-- 插入新增数据,sign=1 表示正常数据
INSERT INTO emp_collapsingmergetree VALUES (1,'tom','上海',25,'技术部',20000,1);
-- 首先插入一条与原来相同的数据(ORDER BY 字段一致),并将 sign 置为-1
INSERT INTO emp_collapsingmergetree VALUES (1,'tom','上海',25,'技术部',20000,-1);
-- 再插入更新之后的数据
INSERT INTO emp_collapsingmergetree VALUES (1,'tom','上海',25,'技术部',30000,1);
-- 查询数据
select * from emp_collapsingmergetree;
-- 执行分区合并操作
optimize table emp_collapsingmergetree;
-- 再次查询
select * from emp_collaspingmergetree; 
数据折叠不是实时的,需要后台进行 Compaction 操作,用户也可以使用手 动合并命令,但是效率会很低,一般不推荐在生产环境中使用。
当进行汇总数据操作时,可以通过改变查询方式,来过滤掉被删除的数据。
SELECT
emp_id,
name,
sum(salary * sign)
FROM emp_collapsingmergetree
GROUP BY emp_id,
name HAVING sum(sign) > 0;
只有相同分区内的数据才有可能被折叠。其实,当我们修改或删除数据时,这些被修改的数据通常是在一个分区内的,所以不会产生影响。
数据写入顺序,值得注意的是: CollapsingMergeTree对于写入数据的顺序有
着严格要求,否则导致无法正常折叠。
如果数据的写入程序是单线程执行的,则能够较好地控制写入顺序;如果需要处理的数据量很大,数据的写入程序通常是多线程执行的,那么此时就不能保障数据的写入顺序了。在这种情况下,CollapsingMergeTree 的工作机制就会出现问题。但是可以通VersionedCollapsingMergeTree的表引擎得到解决。
3.4.6 VersionedCollapsingMergeTree
上面提到CollapsingMergeTree表引擎对于数据写入乱序的情况下,不能够实现数据折叠的效果。VersionedCollapsingMergeTree 表引擎的作用与CollapsingMergeTree完全相同,它们的不同之处在于,VersionedCollapsingMergeTree对数据的写入顺序没有要求,在同一个分区内,任意顺序的数据都能够完成折叠操作。
VersionedCollapsingMergeTree使用version列来实现乱序情况下的数据折叠。
该引擎除了需要指定一个sign标识之外,还需要指定--个UInt8类型的 version 版本号。
示例:
CREATE TABLE emp_versioned (
emp_id UInt16 COMMENT '员工 id',
name String COMMENT '员工姓名',
work_place String COMMENT '工作地点',
age UInt8 COMMENT '员工年龄',
depart String COMMENT '部门',
salary Decimal32(2) COMMENT '工资',
sign Int8,
version Int8
)ENGINE=VersionedCollapsingMergeTree(sign, version)
PARTITION BY work_place
ORDER BY (emp_id,name)
;
-- 先插入需要被删除的数据,即 sign=-1 的数据
INSERT INTO emp_versioned VALUES (1,'tom','上海',25,'技术部',20000,-1,1);
-- 再插入 sign=1 的数据
INSERT INTO emp_versioned VALUES (1,'tom','上海',25,'技术部',20000,1,1);
-- 在插入一个新版本数据
INSERT INTO emp_versioned VALUES (1,'tom','上海',25,'技术部',30000,1,2);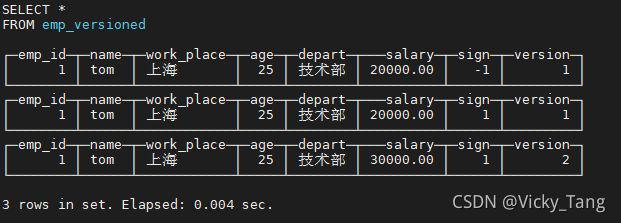
-- 获取正确查询结果
SELECT
emp_id,
name,
sum(salary * sign)
FROM emp_versioned
GROUP BY emp_id, name
HAVING sum(sign) > 0; 
-- 手动合并
optimize table emp_versioned;
-- 再次查询
select * from emp_versioned;
虽然在插入数据乱序的情况下,依然能够实现折叠的效果。之所以能够达到这种效果,是因为在定义version字段之后,VersionedCollapsingMergeTree 会自动将version作为排序条件并增加到ORDERBY的末端,就上述的例子而言,最终的排序字段为ORDER BY emp_ id,name, version desc。
3.5 外部集成表引擎
ClickHouse提供了许多与外部系统集成的方法,包括一些表引擎。这些表引擎与其他类型的表引擎类似,可以用于将外部数据导入到ClickHouse中,或者在ClickHouse中直接操作外部数据源。
例如直接读取HDFS的文件或者MySQL数据库的表。这些表引擎只负责元数据管理和数据查询,而它们自身通常并不负责数据的写入,数据文件直接由外部系统提供。目前ClickHouse提供了下面的外部集成表引擎:
JDBC:通过指定jdbc连接读取数据源;
MySQL:将MySQL作为数据存储,直接查询其数据;
HDFS:直接读取HDFS.上的特定格式的数据文件;
Kafka:将Kafka数据导入ClickHouse。
3.5.1 HDFS
格式:
ENGINE = HDFS(URI, format)
URI: HDFS 文件路径
format:文件格式,比如CSV、JSON、TSV等。
示例:
CREATE TABLE hdfs_engine_table(
emp_id UInt16 COMMENT '员工 id',
name String COMMENT '员工姓名',
work_place String COMMENT '工作地点',
age UInt8 COMMENT '员工年龄',
depart String COMMENT '部门',
salary Decimal32(2) COMMENT '工资'
) ENGINE=HDFS('hdfs://master:9000/ch/hdfs_engine_table', 'CSV');
-- 写入数据
INSERT INTO hdfs_engine_table VALUES (1,'tom','上海',25,'技术部',20000),(2,'jack','上海',26,'人事部',10000);注意:
ch 目录要存在
如果提示没权限:hdfs dfs -chmod -R 777 /
可以看出,这种方式与使用Hive类似,我们直接可以将HDFS对应的文件映射成ClickHouse中的一张表,这样就可以使用SQL操作HDFS上的文件了。
值得注意的是:ClickHouse并不能够删除HDFS上的数据,当我们在ClickHouse客户端中删除了对应的表,只是删除了表结构,HDFS.上的文件并没有被删除,这一点跟Hive的外部表十分相似。

3.5.2 MySQL
格式:
CREATE TABLE mysql_engine_table(
id Int32,
name String
) ENGINE = MySQL( 'master:3306','test', 'student', 'root', '123456');
-- 查询数据
SELECT * FROM mysql_engine_table;
对于MySQL表引擎,不支持UPDATE和DELETE操作。
3.5.3 Kafka
格式:
示例:
CREATE TABLE kafka_table (
uid UInt64,
phone UInt64,
addr String
) ENGINE = Kafka()
SETTINGS
kafka_broker_list = 'master:9092',
kafka_topic_list = 'ck_topic',
kafka_group_name = 'group1',
kafka_format = 'JSONEachRow' ;生产者:
kafka-console-producer.sh --broker-list master:9092 --topic ck_topic数据:
{"uid":"1000166111","phone":"17703771999","addr":" 河南省 南阳"}{"uid":"1000432103","phone":"15388889881","addr":" 云南省 昆明"}{"uid":"1000473355","phone":"15388889557","addr":" 云南省 昆明"}{"uid":"1000555472","phone":"18083815777","addr":" 云南省 昆明"}{"uid":"1000585644","phone":"15377892222","addr":" 广东省 中山"}{"uid":"1000774061","phone":"18026666666","addr":" 广东省 惠州"}{"uid":"1001024965","phone":"18168526111","addr":" 江苏省 苏州"}{"uid":"1001283200","phone":"15310952123","addr":" 重庆 "}{"uid":"1001523180","phone":"15321168157","addr":" 北京 "}

当我们一旦查询完毕之后,ClickHouse 会删除表内的数据,其实Kafka表引擎只是一个数据管道,我们可以通过物化视图的方式访问Kafka中的数据。
首先创建--张Kafka表引擎的表,用于从Kafka中读取数据;
然后再创建--张普通表引擎的表,比如MergeTree,面向终端用户使用;
最后创建物化视图,用于将Kafka引擎表实时同步到终端用户所使用的表中。
示例:
-- 创建 Kafka 引擎表
CREATE TABLE kafka_table_consumer (
uid UInt64,
phone UInt64,
addr String
) ENGINE = Kafka()
SETTINGS
kafka_broker_list = 'master:9092',
kafka_topic_list = 'ck_topic',
kafka_group_name = 'group1',
kafka_format = 'JSONEachRow' ;
-- 创建一张终端用户使用的表
CREATE TABLE kafka_table_mergetree (
uid UInt64,
phone UInt64,
addr String
)ENGINE=MergeTree()
ORDER BY uid ;
-- 创建物化视图,同步数据
CREATE MATERIALIZED VIEW consumer TO kafka_table_mergetree AS
SELECT uid,phone,addr
FROM kafka_table_consumer ;
-- 查询,多次查询,已经被查询的数据依然会被输出
select * from kafka_table_mergetree;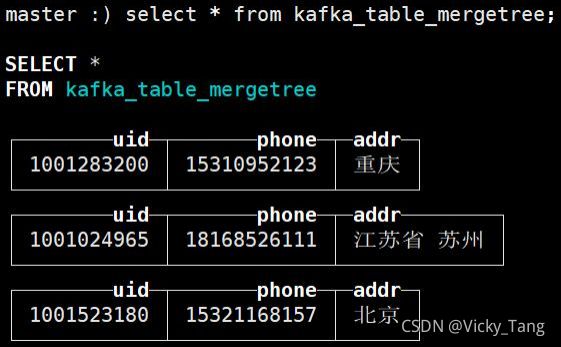
3.6 其他引擎
3.6.1 Memory
内存引擎,数据以未压缩的原始形式直接保存在内存当中,服务器重启数据就会消失。
读写操作不会相互阻塞,不支持索引。简单查询下有非常非常高的性能表现(超过10G/s )
一般用到它的地方不多,除了用来测试,就是在需要非常高的性能,同时数据量又不太大(上限大概1亿行)的场景。
使用方式和TinyLog一致。
3.6.2 Distributed
Distributed表引擎是分布式表的代名词,它自身不存储任何数据,数据都分散存储在某一个分片上,能够自动路由数据至集群中的各个节点,所以Distributed表引擎需要和其他数据表引擎一起协同工作。
所以,一张分布式表底层会对应多个本地分片数据表,由具体的分片表存储数据,分布式表与分片表是一对多的关系。
Distributed(cluster_ name, database_ name, table_ _name[, sharding_ key])
分布式引擎参数:服务器配置文件中的集群名,远程数据库名,远程表名,数据分片键(可选)。
1. 创建分布式表
默认情况下,CREATE、DROP、ALTER、RENAME操作仅仅在当前执行该命令的server.上生效。在集群环境下,可以使用ON CLUSTER语句,这样就可以在整个集群发挥作用。
创建一张分布式表:
CREATE TABLE IF NOT EXISTS user_cluster ON CLUSTER cluster_3shards_1replicas (
id Int32,
name String
)ENGINE = Distributed(cluster_3shards_1replicas, default, user_local,id);Distributed表引擎的定义形式如下所示:
Distributed(cluster_name, database_name, table_name[, sharding_key])各个参数的含义分别如下:cluster_name :集群名称,与集群配置中的自定义名称相对应。database_name :数据库名称table_name :表名称sharding_key :可选的,用于分片的 key 值,在数据写入的过程中,分布式表会依据分片 key 的规则,将数据分布到各个节点的本地表。
使用了ON CLUSTER分布式DDL,这意味着在集群的每个分片节点上,都会创建一张Distributed表,这样便可以从其中任意一- 端发起对所有分片的读、写请求。在每台机器上查看表,发现每台机器上都存在一张刚刚创建好的表。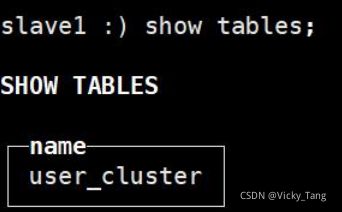
2. 创建本地表
在每台机器_上分别创建一张本地表:
CREATE TABLE IF NOT EXISTS user_local (
id Int32,
name String
)ENGINE = MergeTree()
PARTITION BY id
ORDER BY id
PRIMARY KEY id;
-- 查询本地表
select * from user_local;先在一台机器.上对user_ local 表进行插入数据,然后再查询user_ cluster 表。

再向user_ cluster 中插入一些数据,观察user_ local 表数据变化,可以发现数据被分散存储到了其他节点上了。
INSERT INTO user_cluster VALUES(3,'lilei'),(4,'lihua'); master
-- 在master节点上查询
select * from user_local; 
-- 在 slave1节点上查询
select * from user_local
四、Flink 整合ClickHouse
4.1初步整合实现
package cn.kgc.sink
import java.sql.PreparedStatement
import org.apache.flink.connector.jdbc._
import org.apache.flink.streaming.api.scala._
object CKSink {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.createLocalEnvironment();
val datastream = env.fromElements((7,"lele"),(8,"xixi"))
val sql = "insert into t2 values(?,?)"
datastream.addSink(JdbcSink
.sink[(Int,String)](
sql,
new CkSinkBuilder,
new JdbcExecutionOptions.Builder().withBatchSize(5).build(),
new JdbcConnectionOptions.JdbcConnectionOptionsBuilder() .withUrl("jdbc:clickhouse://master:8123").withDriverName("ru.yandex.clickhouse.ClickHouseDriver") .withUsername("default") .build()
))
env.execute()
}
}
class CkSinkBuilder extends JdbcStatementBuilder[(Int, String)] {
override def accept(t: PreparedStatement, u: (Int, String)): Unit = {
t.setInt(1, u._1)
t.setString(2, u._2)
}
}4.2 项目数据写入 ClickHouse
package cn.kgc.stock
import java.sql.PreparedStatement
import java.text.SimpleDateFormat
import java.util.{Date, Properties}
import com.alibaba.fastjson.{JSON, JSONArray}
import org.apache.flink.api.common.functions.RichFlatMapFunction
import org.apache.flink.api.common.restartstrategy.RestartStrategies
import org.apache.flink.api.common.serialization.SimpleStringSchema
import org.apache.flink.api.common.time.Time import org.apache.flink.connector.jdbc.{JdbcConnectionOptions, JdbcExecutionOptions, JdbcSink, JdbcStatementBuilder}
import org.apache.flink.runtime.state.hashmap.HashMapStateBackend
import org.apache.flink.streaming.api.CheckpointingMode
import org.apache.flink.streaming.api.environment.CheckpointConfig.ExternalizedCheckpoin tCleanup
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer
import org.apache.flink.util.Collector
import org.apache.kafka.clients.consumer.ConsumerConfig
object Kafka2Flink2ClickHouse {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val hashMapStateBackend = new HashMapStateBackend()
env.setStateBackend(new HashMapStateBackend())
try {
//env.getCheckpointConfig.setCheckpointStorage("file:///D://abc//ckp")
env.getCheckpointConfig
.setCheckpointStorage("hdfs://master:9000/flink/checkpoin t")
} catch {
case e => e.printStackTrace()
}
env.enableCheckpointing(1000,CheckpointingMode.EXACTLY_ONCE)
env.getCheckpointConfig.setMinPauseBetweenCheckpoints(500)
env.getCheckpointConfig.setCheckpointTimeout(60000)
env.getCheckpointConfig.setTolerableCheckpointFailureNumber(1)
env.getCheckpointConfig.enableExternalizedCheckpoints(ExternalizedCheckpointClea nup.RETAIN_ON_CANCELLATION)
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(3,Time.milliseconds(600)))
val props = new Properties()
props.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "master:9092")
props.setProperty(ConsumerConfig.GROUP_ID_CONFIG, "group-2")
props.setProperty(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "2000")
props.setProperty(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "true")
props.setProperty(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "latest")
val kafkaConsumer = new FlinkKafkaConsumer[String]("indexTimeLine",new SimpleStringSchema(),props)
kafkaConsumer.setCommitOffsetsOnCheckpoints(true)
val inputStream = env.addSource(kafkaConsumer)
val resultStream: DataStream[StockIndexMinuteResult2] = inputStream.flatMap(new MyFlatMapAnalysisJson2)
resultStream.print()
val sql = "insert into t5 values(?,?,?)"
resultStream.addSink(JdbcSink
.sink[StockIndexMinuteResult2]( sql, new CkSinkBuilder, new JdbcExecutionOptions.Builder().withBatchSize(5).build(),
new JdbcConnectionOptions
.JdbcConnectionOptionsBuilder()
.withUrl("jdbc:clickhouse://master:8123")
.withDriverName("ru.yandex.clickhouse.ClickHouseDriver")
.withUsername("default")
.build()
)
)
env.execute()
}
}
class CkSinkBuilder extends JdbcStatementBuilder[StockIndexMinuteResult2] {
override def accept(t: PreparedStatement, u: StockIndexMinuteResult2): Unit = {
t.setString(1,u.name)
t.setString(2,u.dt)
t.setDouble(3,u.nowPrice)
}
}
class MyFlatMapAnalysisJson2 extends RichFlatMapFunction[String,StockIndexMinuteResult2]{
override def flatMap(line: String, out: Collector[StockIndexMinuteResult2]): Unit = {
val jSONObject = JSON.parseObject(line)
val jSONArray = jSONObject.getJSONObject("showapi_res_body").getJSONArray("dataList")
val jSONObject2 = JSON.parseObject(jSONArray.getString(0))
val dt = jSONObject2.get("date").toString
val array: JSONArray = jSONObject2.getJSONArray("minuteList")
val code = jSONObject.getJSONObject("showapi_res_body").getString("code")
val name = jSONObject.getJSONObject("showapi_res_body").getString("name")
val market = jSONObject.getJSONObject("showapi_res_body").getString("market")
var i:Int = 0
while (i < array.size()){
val time = array.getJSONObject(i).getString("time")
val avgPrice = array.getJSONObject(i).getString("avgPrice").toDouble
val nowPrice = array.getJSONObject(i).getString("nowPrice").toDouble
out.collect( StockIndexMinuteResult2(code,name,market,tranTimeToString(tranTimeToLong(dt+ti me)),avgPrice,nowPrice))
i += 1
}
}
def tranTimeToLong(tm:String) :Long={
val fm = new SimpleDateFormat("yyyyMMddHHmm")
val dt = fm.parse(tm)
val aa = fm.format(dt)
val tim: Long = (dt.getTime()+"").toLong tim
}
def tranTimeToString(tm:Long) :String={
val fm = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss")
val time = fm.format(new Date(tm)) time
}
}
case class StockIndexMinuteResult2(codeId:String,name:String,market:String,dt:String,avgPrice :Double,nowPrice:Double)