AdaptiveAvgPool2d理解(中网、外网整合)
目录
- 什么是Pooling
- AdaptivePooling(自适应池化)和General Pooling(一般池化)的区别
- AdaptivePooling的实现细节
- 实例
-
- 1d
- 2d
- 对自己的一些基于pool的实现的困惑的解答
-
- kernel必须得是正方形嘛?
什么是Pooling
Pooling,池化层,又称下采样层、汇聚层,是从样本中再选样本的过程。
池化层主要分为两类:最大值(Max)池化层,均值(Avg)池化层。前者用取最大值的方式抽取样本,后者用平均值的方式抽取样本。
参考资料:Pytorch 里 nn.AdaptiveAvgPool2d(output_size) 原理是什么?
AdaptivePooling(自适应池化)和General Pooling(一般池化)的区别
AdaptivePooling,自适应池化层。函数通过输入原始尺寸和目标尺寸,自适应地计算核的大小和每次移动的步长。如告诉函数原来的矩阵是7x7的尺寸,我要得到3x1的尺寸,函数就会自己计算出核多大、该怎么运动。
官网对torch.nn.AdaptiveAvgPool2d使用方法的定义及介绍。
AdaptiveAveragePooling的源码内容。
故,我认为,自适应池化层和非自适应池化层有三点主要区别:
- AdaptivePooling的核的大小和步长是函数自己计算的,不需要人为设定;而General Pooling需要指定核的大小和步长。
- AdaptivePooling的核是可变大小的,且步长也是动态的;而General Pooling是固定核的大小和步长的。
- AdaptivePooling的相邻池化窗口之间是可以出现重叠的;General Pooling作用于图像中不重叠的区域。(也存在OverlappingPooling(重叠池化层))
AdaptivePooling的实现细节
从AdaptivePooling和General Pooling的区别出发,我们可以分两种情况讨论AdaptivePooling:
- 第一种情况-输入尺寸是输出尺寸的整数倍
在这种情况下,自适应层的核的大小相同且不重叠,AdaptivePooling可以改写为General Pooling,核的大小和步长的计算规则如下:
#input_size: 输入尺寸 output_size: 输出尺寸
stride = intput_size // output_size #步长
kernel_size = input_size - ( output_size -1 ) * stride #核的尺寸
padding = 0
- 第二种情况-输入尺寸不是输出尺寸的整数倍
在这种情况下,自适应层的核是可变大小的,且可能互相重叠,此时固定步长和核的尺寸的General Pooling不能改写AdaptivePooling。目前网上找到两种在AdaptivePooling中计算核大小的方法:
- 方法一,用代码方式严谨地展示的每一步kernel尺寸的计算过程:
from typing import List
import math
def kernels(input_size,output_size) -> List:
"""Returns a List [(kernel_offset_start,kernel_length)] defining all the pooling kernels for a 1-D adaptive pooling layer that takes an input of dimension `ind` and yields an output of dimension `outd`"""
def start_index(a,b,c): #a:当前指向的位置 b:输出尺寸 c:输入尺寸
return math.floor((float(a) * float(c)) / b) # 向下取整
def end_index(a,b,c): #a:当前指向的位置 b:输出尺寸 c:输入尺寸
return math.ceil((float(a + 1) * float(c)) / b) # 向上取整
results = []
for current_o in range(output_size):
start = start_index(current_o ,output_size,input_size)
end = end_index(current_o ,output_size,input_size)
sz = end - start
results.append((start,sz))
return results
def kernel_indexes(input_size,output_size) -> List:
"""Returns a List [[*ind]] containing the indexes of the pooling kernels"""
startsLengths = kernels(ind,out)
return [list(range(start,start+length)) for (start,length) in startsLengths]
参考内容:How does adaptive pooling in pytorch work?
以我的理解,AdaptivePooling的核的大小是通过输入尺寸和输出尺寸计算出来的,大小固定,但在移动过程中,步长是动态的。
- 方法二,一种适合手动推算AdaptivePooling池化过程的计算过程:
- 首先计算核的大小:
kernel_size = (input_size + target_size -1) // target_size (结果四舍五入)
- 然后计算每个核的位置:
将 (0, input_size-kernel_size)划分为包含target_size个元素的等差数列。
eg:给定一个一维数列,input_size = 14, output_size = 4, 通过计算得到kernel_size = 4
故 (0, 10) 被拆分为包含四个元素的等差数列 (0, 3.3333, 6.6666, 10), 并对每一位做四舍五入得到(0, 3 ,7, 10)
故四个核为[0, 4], [3, 7], [7, 11], [10, 14]
故得到kernel的运行轨迹如下:

参考内容:What is AdaptiveAvgPool2d?
实例
1d
上面的方法二已经介绍了1x14转化为1x4在Adaptive下的计算过程。
2d
下面展示的是7x7转换为3x2在Adaptive下的计算过程。
使用上述方法二模拟转换过程:
-
首先计算核的大小:
kernel_size = (input_size + target_size -1) // target_size (结果四舍五入)
横向:(7+3-1)//3=3
纵向:(7+2-1)//2=4 -
然后计算每个核的位置:
横向:将 (0, 7-3)划分为包含3个元素的等差数列即(0,2,4),故横向三个核的位置为[0,3],[2,5],[4,7]
纵向:将 (0, 7-4)划分为包含2个元素的等差数列即(0,3),故纵向两个核的位置为[0,4],[3,8]
故2d中共六个核的移动状态如下图:
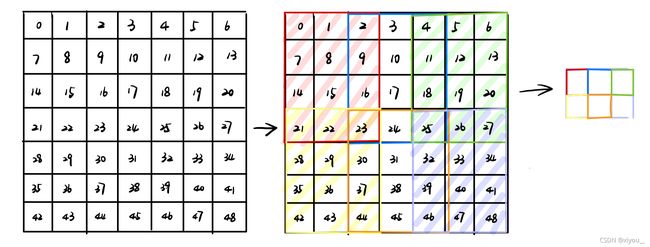
(由于网上对于2d下的核的移动计算的示例几乎找不到,所以以上计算包含了自己的理解,如果有不对的地方,欢迎指正,多谢。)
对自己的一些基于pool的实现的困惑的解答
kernel必须得是正方形嘛?
不是!
以pytorch中MaxPool2d的例子为例:
Examples::
>>> # pool of square window of size=3, stride=2
>>> m = nn.MaxPool2d(3, stride=2)
>>> # pool of non-square window
>>> m = nn.MaxPool2d((3, 2), stride=(2, 1))
>>> input = torch.randn(20, 16, 50, 32)
>>> output = m(input)
这里明确说明了kernel是正方形和不是正方形两种情况下的函数定义。