图像分割典型编解码结构:U-net和SegNet网络及Pytorch代码实现
在FCN分割网络之后,后面出现了一系列的编解码结构网络。所谓的编解码结构其实就是指整个网络中存在一个主要的编码器块和解码器块。编码器块主要用来从输入中提取特征图谱,而解码器块主要是将经过编码器处理的输入所得到的特征进行进一步的特征优化和任务处理。比如分割任务,逐步实现对每个像素的标注。编码器常基于现有的Backbone网络,如vgg,resnet等等。利用在大型数据集上训练好的特征提取网络参数,往往能够得到比较好的特征编码器。而解码器则往往需要根据任务需求进行设计。
下面我们一起来对U-net和SegNet两个经典的encode-decode结构的图像分割网络进行学习吧!
U-net
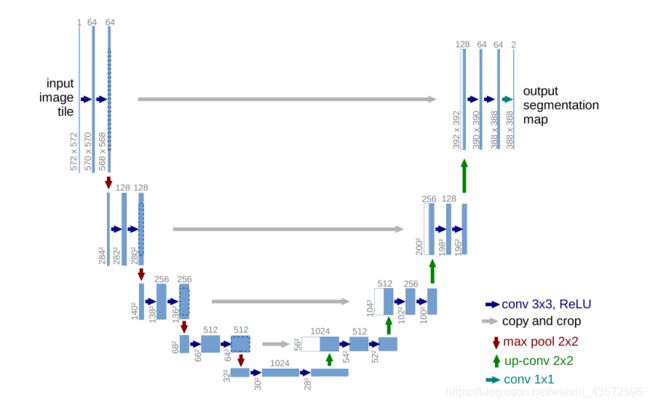
U-net是专门为医学图像所提出的分割网络。Unet对FCN进行了进一步延伸,将图像->高语义feature map的过程看成编码器,高语义->像素级别的分类score map的过程看作解码器)进行了加卷积加深处理,FCN只是单纯的进行了上采样。同时采用的Skip connection可以联合高层语义和低层的细粒度表层信息。在FCN中,Skip connection的联合是通过对应像素的求和,而U-Net则是对其的channel的concat过程。其网络结构如下:
SegNet
SegNet也是采用了编解码器结构。但不同于Unet,SegNet采用了完全对称的编解码结构策略。即编码器与解码器的结构完全对称。从结构图看我们可以清楚:

另外一点不同之处在于,为了更好的保留边界特征信息,SegNet采用了索引的方式进行上采样。即在进行池化操作时,记录池化所取值的位置,在上采样时直接用当时记录的位置进行UpPool(反池化)。从代码来看可能更直观:
import torch
import torchvision
import torch.nn as nn
import torch.nn.functional as F
class SEGNet(nn.Module):
def __init__(self,num_classes=21):
super(SEGNet,self).__init__()
self.encode_Conv1 = nn.Sequential(
nn.Conv2d(3,64,3,padding=1),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.Conv2d(64,64,3,padding=1),
nn.BatchNorm2d(64),
nn.ReLU(),
)
self.encode_Conv2 = nn.Sequential(
nn.Conv2d(64,128,3,padding=1),
nn.BatchNorm2d(128),
nn.ReLU(),
nn.Conv2d(128,128,3,padding=1),
nn.BatchNorm2d(128),
nn.ReLU()
)
self.encode_Conv3 = nn.Sequential(
nn.Conv2d(128,256,3,padding=1),
nn.BatchNorm2d(256),
nn.ReLU(),
nn.Conv2d(256, 256, 3, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(),
nn.Conv2d(256, 256, 3, padding=1),
nn.BatchNorm2d(256),
nn.ReLU()
)
self.encode_Conv4 = nn.Sequential(
nn.Conv2d(256,512,3,padding=1),
nn.BatchNorm2d(512),
nn.ReLU(),
nn.Conv2d(512,512,3,padding=1),
nn.BatchNorm2d(512),
nn.ReLU(),
nn.Conv2d(512,512,3,padding=1),
nn.BatchNorm2d(512),
nn.ReLU()
)
self.encode_Conv5 = nn.Sequential(
nn.Conv2d(512,512,3,padding=1),
nn.BatchNorm2d(512),
nn.ReLU(),
nn.Conv2d(512,512,3,padding=1),
nn.BatchNorm2d(512),
nn.ReLU(),
nn.Conv2d(512,512,3,padding=1),
nn.BatchNorm2d(512),
nn.ReLU())
self.decode_Conv1 = nn.Sequential(
nn.Conv2d(512,512,3,padding=1),
nn.BatchNorm2d(512),
nn.ReLU(),
nn.Conv2d(512,512,3,padding=1),
nn.BatchNorm2d(512),
nn.ReLU(),
nn.Conv2d(512,512,3,padding=1),
nn.BatchNorm2d(512),
nn.ReLU()
)
self.decode_Conv2 = nn.Sequential(
nn.Conv2d(512,512,3,padding=1),
nn.BatchNorm2d(512),
nn.ReLU(),
nn.Conv2d(512,512,3,padding=1),
nn.BatchNorm2d(512),
nn.ReLU(),
nn.Conv2d(512,256,3,padding=1),
nn.BatchNorm2d(256),
nn.ReLU()
)
self.decode_Conv3 = nn.Sequential(
nn.Conv2d(256,256,3,padding=1),
nn.BatchNorm2d(256),
nn.ReLU(),
nn.Conv2d(256, 256, 3, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(),
nn.Conv2d(256, 128, 3, padding=1),
nn.BatchNorm2d(128),
nn.ReLU()
)
self.decode_Conv4 = nn.Sequential(
nn.Conv2d(128,128,3,padding=1),
nn.BatchNorm2d(128),
nn.ReLU(),
nn.Conv2d(128,64,3,padding=1),
nn.BatchNorm2d(64),
nn.ReLU()
)
self.decode_Conv5 = nn.Sequential(
nn.Conv2d(64,64,3,padding=1),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.Conv2d(64,num_classes,3,padding=1),
#nn.BatchNorm2d(num_classes),
#nn.ReLU(),
)
self.weights_new = self.state_dict()
def forward(self, x):
#print('inputsize',x.shape)
x = self.encode_Conv1(x)
x1size = x.size()
x,id1 = F.max_pool2d(x,kernel_size=2,stride=2,return_indices=True)
#print(x.shape,id1.shape)
x = self.encode_Conv2(x)
x2size = x.size()
x,id2 = F.max_pool2d(x,kernel_size=2,stride=2,return_indices=True)
#print(x.shape,id2.shape)
x = self.encode_Conv3(x)
x3size = x.size()
x,id3 = F.max_pool2d(x,kernel_size=2,stride=2,return_indices=True)
#print(x.shape,id3.shape)
x = self.encode_Conv4(x)
x4size = x.size()
x,id4 = F.max_pool2d(x,kernel_size=2,stride=2,return_indices=True)
#print(x.shape,id4.shape)
x = self.encode_Conv5(x)
x5size = x.size()
x,id5 = F.max_pool2d(x,kernel_size=2,stride=2,return_indices=True)
#print(x.shape,id5.shape)
x = F.max_unpool2d(x,indices=id5,kernel_size=2, stride=2,output_size=x5size)
x = self.decode_Conv1(x)
#print(x.shape,id4.shape)
x = F.max_unpool2d(x,indices=id4,kernel_size=2, stride=2,output_size=x4size)
x = self.decode_Conv2(x)
x = F.max_unpool2d(x,indices=id3,kernel_size=2, stride=2,output_size=x3size)
x = self.decode_Conv3(x)
x = F.max_unpool2d(x,indices=id2,kernel_size=2,stride=2,output_size=x2size)
x = self.decode_Conv4(x)
x = F.max_unpool2d(x,indices=id1,kernel_size=2,stride=2,output_size=x1size)
x = self.decode_Conv5(x)
return x
def copy_params_from_vgg16(self, model,weights):
del weights["classifier.0.weight"]
del weights["classifier.0.bias"]
del weights["classifier.3.weight"]
del weights["classifier.3.bias"]
del weights["classifier.6.weight"]
del weights["classifier.6.bias"]
names = []
for key, value in model.state_dict().items():
# if "num_batches_tracked" in key:
# continue
names.append(key)
for dict, name in zip(weights.items(),names):
self.weights_new[name] = dict[1]
model.load_state_dict(self.weights_new)
值得注意的一点是,由于进行池化过程中,可能会使得特征size丢失一部分,比如150×150的大小,经过k=2,stride=2的池化操作后,size变为75×75,但是再进行一次这样的池化操作后你会发现size变成了37×37,但是这时记录的indices是按size75×75记录的。立马进行uppool,同样采用k=2,stride=2,就会报错了,会告诉你shape不匹配。37×37进行k=2,stride=2的uppool只会变成74×74。但是在进行池化操作前你记录了图的size大小的话,就可以很开心的做这样的事情了!比如上面forward过程中的那样!
总结
编解码结构是很经典的分割网络设计,在以后也要记得尝试使用!