【BERT蒸馏】DistilBERT、Distil-LSTM、TinyBERT、FastBERT(论文+代码)
文章目录
- 0. 引言
- 1. FastBERT: a Self-distilling BERT with Adaptive Inference Time
-
- 1.1 摘要
- 1.2 动机
- 1.3 贡献(适用于文本分类任务)
- 1.4 相关工作
- 1.5 模型
-
- 1.5.1 模型结构
- 1.5.2 训练步骤
- 1.6 实验结果
- 2. DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
-
- 2.1 摘要
- 2.2 动机
- 2.3 贡献
- 2.4 知识蒸馏
- 2.5 DistilBERT: a distilled version of BERT
- 2.6 实验结果
- 3. Distilling Task-Specific Knowledge from BERT into Simple Neural Networks
-
- 3.1 摘要
- 3.2 动机
- 3.3 贡献(主要针对句子分类和句子匹配)
- 3.4 方法论
-
- 3.4.1 Model Architecture
- 3.4.2 Distillation Objective
- 3.4.3 Data Augmentation for Distillation
- 3.5 实验结果
- 4. TinyBERT: Distilling BERT for Natural Language Understanding
-
- 4.1 摘要
- 4.2 动机
- 4.3 贡献
- 4.4 模型
- 4.5 实验
0. 引言
在BERT模型加速方面人们进行了许多尝试,如参数量化、权重修剪和知识蒸馏(KD)。蒸馏阶段输入数据为无监督数据,可依据需要引入更多数据提升鲁棒性。
接下来我们看看大家蒸馏都是怎么做的,以及分析是否适合我们当前的任务。具体来说比较受欢迎的有以下四个:FastBERT、DistilBERT、Distil-LSTM、TinyBERT。
DistilBERT:
原理:这个的做法就是用蒸馏12层的BERT得到6层的DistilBERT,首先预训练好BERT,然后用训练BERT的大规模预料来蒸馏12层的BERT得到。
效果:速度快60%,参数减少40%,同时效果保留了97%。
可行性:因为该任务是一个通用的蒸馏BERT,所以即插即用。并且已经有蒸馏好的中文模型。
论文地址:https://arxiv.org/abs/1910.01108
相关资料:https://medium.com/huggingface/distilbert-8cf3380435b5
代码地址:https://github.com/huggingface/transformers/tree/master/examples/distillation
Distil-LSTM
原理:这个做法是将BERT学习到的知识通过蒸馏迁移到LSTM中,针对特定分类任务设计的模型。首先对于特定任务(我们假设文本分类),Teacher选择预训练且微调好的BERT模型,然后用特定任务的数据集进行蒸馏到Student模型LSTM,为了保证数据集是足够大的,还加入了数据增广。
效果:在一些简单的分类任务上精度下降3%,速度提升近400倍。与上一个模型相比,DistilBERT 模型的效果相对更好,而 Distilled BiLSTM 压缩得更小。
可行性:速度提升最快,但是为简单的下游分类任务设计的,对我们关系抽取(可以当作序列标注)任务是否有帮助持疑问;此外,这是一个为特定任务设计的,没有可以直接拿来用的,需要要充分的特定任务预语料。
论文地址:https://arxiv.org/abs/1903.12136
代码地址:https://github.com/qiangsiwei/bert_distill
TinyBERT
原理:这个主要是专门为 Transformer 网络设计的知识蒸馏方法。并采用的是一个两阶段学习框架,第一个阶段,TinyBERT 在大量的 general 数据集上,利用预训练 BERT 蒸馏出一个通用TinyBERT;第二个阶段,TinyBERT 采用数据增强,用微调后的 BERT 训练一个 task specific 模型。
效果:相较于完整的 BERT,性能下降 3 个点,但是推理性能却得到了巨大提升,快了9倍多。
可行性:效果要比DistilBERT好,但是华为官方只公布了英文蒸馏好的模型。所以如果想适用于我们的中文关系抽取任务,有两个方法:1. 在大量的中文数据集上,训练一个中文通用tinybert,然后再针对我们任务,蒸馏微调Tinybert。但是这么做的话,需要大量的中文通用数据集,还需要充足的特定任务数据集。2. 省略第一步。a. 制作任务相关数据集; b. fine-tune teacher BERT; c. 固定 teacher BERT 参数,蒸馏得到 TinyBERT。这里也需要充足的特定任务数据集。
论文:https://arxiv.org/abs/1909.10351
相关资料:https://www.jiqizhixin.com/articles/2019-12-05-3
代码地址:https://github.com/huawei-noah/Pretrained-Language-Model/tree/master/TinyBERT
FastBERT
原理:主要思想是自适应调整每个样本的计算量,容易的样本通过一两层就可以预测出来,较难的样本则需要走完全程。步骤:使用预训练好的bert,跟普通训练一样finetune模型。然后freeze主干网络和最后层的teacher分类器,每层的子模型拟合teacher分类器(KL散度为loss);inference阶段,根据样本输入,子分类器置信度高则提前返回。
效果:度可以提升1-10倍,且精度下降全部在0.11个点之内,甚至部分任务上还有细微提升。优于DistillBERT,无论是性能还是速度。
可行性:为文本分类任务设计,我们如果改造也不容易,首先需要将简单的单层分类器改为多个双向LSTM进行分类,然后我们的置信度也不好表示,并且我们也需要大量的特定任务数据。
论文地址(ACL2020): https://arxiv.org/pdf/2004.02178.pdf
代码地址(Pytorch): https://github.com/BitVoyage/FastBERT
小的预训练模型
此外还有一些预训练好的小语言模型可以即插即用,如albert_chinese_tiny,也在很多榜单上刷榜,且模型小,速度快。
一些其他资料:
https://huggingface.co/voidful/albert_chinese_tiny
https://github.com/brightmart/albert_zh
https://github.com/huggingface/transformers/tree/master/examples/distillation
https://zhuanlan.zhihu.com/p/245634608
https://zhuanlan.zhihu.com/p/94359189?utm_source=wechat_timeline
https://blog.csdn.net/weixin_43378396/article/details/106753376
1. FastBERT: a Self-distilling BERT with Adaptive Inference Time
1.1 摘要
像BERT这样的预先训练过的语言模型已经被证明是非常高效的。然而,在许多实际的场景中,它们通常是计算昂贵的,因为这样的大型模型很难在有限的资源下轻易地实现。为了在保证模型性能的前提下提高效率,我们提出了一种具有自适应推理时间的速度可调快速BERT算法。推理速度可根据不同需求灵活调整,避免了样本的冗余计算。此外,该模型在微调方面采用了独特的自精馏机制,进一步提高了计算效率,使性能损失最小。我们的模型在12个中英文数据集中取得了很好的结果。如果给定不同的加速阈值以进行速度性能折中,那么它能够比BERT加速1到12倍。
1.2 动机
- 尽管BERT类模型在准确性上有所提高,但它们的计算成本较高,推理速度较慢,这严重影响了它们的实用性。实际设置,特别是在行业时间和资源有限的情况下,很难让这类机型投入运行。例如,在句子匹配和文本分类等任务中,通常需要每秒处理数十亿个请求。更重要的是,请求的数量随时间而变化。
- 通过检查许多NLP数据集,我们发现样本具有不同的难度水平。较重的模型可能会对简单的输入计算过高,而较轻的模型在复杂的样本中容易出现故障。
1.3 贡献(适用于文本分类任务)
我们提出了FastBERT,一个预先训练的模型,具有样本明智的自适应机制。它可以动态调整执行层的数量,以减少计算步骤。该模型也有一个独特的自我蒸馏过程,需要最小的变化的结构,实现更快,但在一个单一的框架内准确的结果。我们的模型不仅达到了与BERT模型相当的加速(2到11倍),而且与更重的预训练模型相比,也获得了竞争的准确性。
- 我们提出了FastBERT,一个预先训练的模型,具有样本明智的自适应机制。它可以动态调整执行层的数量,以减少计算步骤。该模型也有一个独特的自我蒸馏过程,需要最小的变化的结构,实现更快,但在一个单一的框架内准确的结果。我们的模型不仅达到了与BERT模型相当的加速(2到11倍),而且与更重的预训练模型相比,也获得了竞争的准确性
- 将样本自适应机制和自精馏机制相结合,提高了神经规划模型的推理时间。在12个NLP数据集上验证了有效性;
1.4 相关工作
知识蒸馏(KD):人们做了许多尝试来将重模型(教师)提炼成轻模型(学生)。PKD-BERT (Sun et al., 2019a)采用了一种增量提取过程,从教师模型的中间层学习归纳。TinyBERT (Jiao et al., 2019)进行了两阶段学习,包括一般领域的预培训和特定任务的微调。DistilBERT (Sanh et al., 2019)通过引入三元组损失,进一步利用了大模型中的归纳偏差。如图1所示,学生模型往往需要一个分离的结构,但其效果主要取决于教师的收获。他们像他们的老师一样不加区分地对待个别情况,只会以降低成绩为代价而变得更快。
1.5 模型
我们的方法将适应和精馏融合为一种新的加速方法,如图2所示,在准确性和效率方面都取得了竞争的结果。如图所示,FastBERT由主干和分支组成。主干是建立在12层的变压器编码器和一个额外的教师分类器,而分支包括学生分类器,附加到每个变压器输出,以实现早期输出

1.5.1 模型结构
主干由三部分组成:嵌入层、包含成堆变压器块的编码器和教师分类器。嵌入层和编码器的结构与BERT的结构一致,在最终编码输出之后是一个教师分类器,它提取域内特征用于下游推断。
![]()
![]()
为给FastBERT提供更多的适应性,多分支,即学生分类器与教师相同的架构被添加到每个变压器块的输出以使早期输出成为可能,特别是在那些简单的情况下。学生分类器可以描述为:
![]()
1.5.2 训练步骤
要求各自的训练步骤骨干和学生分类。在训练另一个模块时,一个模块中的参数总是冻结的。通过三个步骤对模型进行训练,为后续推理做准备:
Pre-training
同BERT系模型是一样的,网上那么多开源的模型也可以随意拿来。
Fine-tuning for backbone
主干精调,也就是给BERT最后一层加上分类器,用任务数据训练,这里也用不到分支分类器,可以尽情地优化
Self-distillation for branch
分支自蒸馏,用无标签任务数据就可以,将主干分类器预测的概率分布蒸馏给分支分类器。这里使用KL散度衡量分布距离,loss是所有分支分类器与主干分类器的KL散度之和

Adaptive inference
自适应推理,及根据分支分类器的结果对样本进行层层过滤,简单的直接给结果,困难的继续预测。这里作者定义了新的不确定性指标,用预测结果的熵来衡量。

1.6 实验结果
对于每层分类结果,作者用“Speed”代表不确定性的阈值,和推理速度是正比关系。因为阈值越小 => 不确定性越小 => 过滤的样本越少 => 推理速度越慢。

在Speed=0.2时速度可以提升1-10倍,且精度下降全部在0.11个点之内,甚至部分任务上还有细微提升。相比之下HuggingFace的DistillBERT的波动就比较剧烈了,6层模型速度只提升2倍,但精度下降最高会达到7个点。
2. DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
2.1 摘要
随着大规模预训练模型的迁移学习在自然语言处理(NLP)中越来越普遍,在边缘和/或计算训练或推理预算受限的情况下操作这些大型模型仍然具有挑战性。在这项工作中,我们提出了一种预先训练一种更小的通用语言表示模型的方法,称为蒸馏伯特DistilBERT,然后可以对其进行微调,使其在更大范围的任务中表现良好。虽然大多数之前的工作研究了使用蒸馏来构建特定任务模型,但我们在培训前阶段利用了知识蒸馏,表明它可以将一个BERT模型的规模减少40%,同时保留97%的语言理解能力,并提高60%的速度。为了利用大模型在训练前的归纳偏差,我们引入了结合语言建模、蒸馏和余弦距离损失的三重损失。
2.2 动机
几个担忧。首先是Schwartz等人和Strubell等人提到的这些模型的计算需求的指数尺度的环境成本。其次,虽然在设备上实时运行这些模型有可能使新颖有趣的语言处理应用程序成为可能,但这些模型不断增长的计算和内存需求可能会阻碍广泛采用。
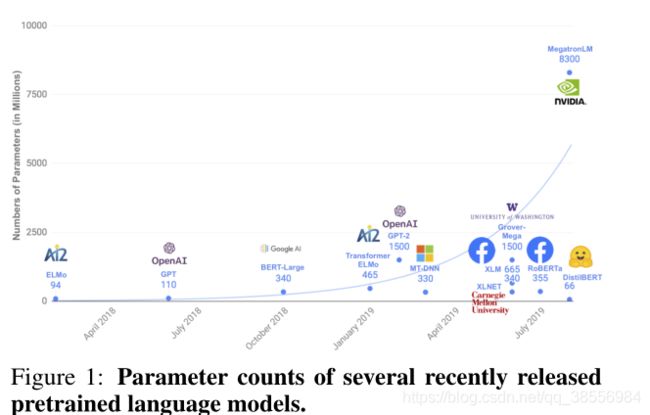
2.3 贡献
在这篇论文中,我们证明了使用预先经过知识蒸馏训练的小得多的语言模型可以在许多下游任务上达到相似的性能,从而使得模型在推理时更轻更快,同时也需要更小的计算训练预算。我们的通用预训练模型可以在几个下游任务上进行良好的性能调整,保持较大模型的灵活性。我们还展示了我们的压缩模型小到足以运行在移动设备。
通过三重损失,我们证明了通过蒸馏预训练的较小40%的Transformer,通过更大的Transformer语言模型的监督,可以在各种下游任务上实现类似的性能,同时在推理时间上提高60%。进一步的消融研究表明,三重损失的所有组成部分对最佳性能是重要的。
2.4 知识蒸馏
用teacher soft 目标概率的蒸馏损失训练student:
![]()
通过充分利用Teacher的分布,这一目标函数产生了丰富的训练信号。
最终的训练目标是蒸馏损失 L c e L_{ce} Lce与监督训练损失的线性组合,在我们的案例中是MASK语言建模损失 L m l m L_{mlm} Lmlm。我们发现增加一个余弦嵌入损失( L c o s L_{cos} Lcos)是有益的,它将倾向于对齐student和teacher隐藏状态向量的方向。
2.5 DistilBERT: a distilled version of BERT
Student architecture
在目前的工作中,学生-蒸馏BERT-有相同的一般BERT结构。标记式嵌入和池被删除,而层的数量减少了1 / 2。变压器中使用的大多数操作体系结构(线性层和层正常化)在现代高度优化的线性代数框架和我们的调查显示,张量的变化在最后维度(隐藏的尺寸大小)对计算效率的影响较小(一个固定参数的预算)比变化等其他因素层的数量。因此我们专注于减少层的数量。
Student initialization
利用教师网络和学生网络的共同维度,我们从教师中提取一层来初始化学生。
Distillation
我们使用Liu等人最近提出的最佳实践来训练BERT模型
Data and compute power
我们在与原始BERT模型相同的语料库上训练(丰富的数据)
2.6 实验结果

3. Distilling Task-Specific Knowledge from BERT into Simple Neural Networks
3.1 摘要
在本文中,我们证明了基本的、轻量级的神经网络仍然可以在不改变架构、外部训练数据或额外输入特性的情况下具有竞争力。我们提议将知识从最先进的语言表示模型BERT提取到单层BiLSTM中,以及用于句子对任务的siamese对等体中。在释义、自然语言推理和情感分类等多个数据集上,我们使用ELMo获得了可比较的结果,同时使用的参数少了大约100倍,推理时间少了15倍。
3.2 动机
然而,这样大的神经网络在实践中是有问题的。例如,由于参数太多,BERT和GPT-2在资源受限的系统(如移动设备)中是不可部署的。由于推理时间效率低,它们也可能不适用于实时系统。
3.3 贡献(主要针对句子分类和句子匹配)
在本文中,我们提出了一个简单而有效的方法,将特定任务的知识从BERT传输到一个浅层的神经结构,特别是一个双向长短期记忆网络(BiLSTM)。我们质疑一个简单的架构是否真的缺乏文本建模的表示能力,我们希望研究将知识从BERT传输到BiLSTM的有效方法。具体来说,我们利用知识蒸馏方法,其中较大的模型充当教师,较小的模型学着将教师模仿为学生。使得在BERT和不同的神经结构(比如我们的例子中的单层BiLSTM)之间进行知识转移成为可能。
我们进一步提出了一种新的基于规则的文本数据扩充方法来构建知识转移集。虽然我们的扩充样本不是流畅的自然语言句子,但实验结果表明,我们的方法在知识精馏方面的效果令人惊讶。
通过我们的方法,一个基于浅层bilstm的模型可以获得与来自语言模型(ELMo), 但是使用的参数少了大约100倍,执行推断的速度快了15倍。因此,我们的模型成为一种先进的“小”模型的神经NLP。
3.4 方法论
首先,我们选择期望的教师和学生模型进行知识蒸馏方法。然后,我们描述我们的蒸馏过程,它包括两个主要组成部分:第一,增加一个逻辑回归目标,第二,构建一个迁移数据集,它扩充了训练集从而更有效的知识转移。
3.4.1 Model Architecture
对于教师网络,我们使用预训练、微调好的的BERT 模型,这是一种深度、双向转换器编码器,在各种语言理解任务上达到最先进的状态。从一个输入句子(pair), BERT计算一个特征向量,在此基础上我们为任务构建一个分类器。对于单句分类,在训练过程中,我们利用交叉熵损失,最大限度地利用正标的概率,共同调整BERT和分类器的参数。
相比之下,我们的学生模型是一个带有非线性分类器的单层BiLSTM。将输入的单词嵌入输入BiLSTM后,将每个方向上最后一步的隐藏状态串联并馈送到具有整直线性单元的全连接层(ReLUs),其输出再传递到softmax层进行分类。
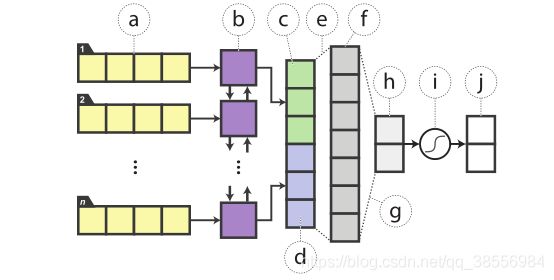
对于句子对任务,我们在siamese架构中在两个句子编码器之间共享BiLSTM编码器的权重,产生句子向量 h s 1 h_{s1} hs1和 h s 2 h_{s2} hs2,两个句子向量拼接后进入输出层去判断。

3.4.2 Distillation Objective
将 BERT 蒸馏到 BiLSTM 模型,使用的损失函数包含两个部分:
一部分是 hard target,直接使用 one-hot 类别与 BiLSTM 输出的概率值计算交叉熵。
一部分是 soft target,使用 teacher 模型 (BERT) 输出的概率值与 BiLSTM 输出的概率值计算均方误差 MSE(那看来只是适用于分类任务了?)。

3.4.3 Data Augmentation for Distillation
在训练过程中,太小的数据集不足以让 student 模型学习到 teacher 模型的所有知识,所以作者提出了三种数据增强的方法扩充数据:
- Masking,使用 [mask] 标签随机替换一个单词,例如 “I have a cat”,替换成 “I [mask] a cat”。
- POS-guided word replacement,将一个单词替换成另一个具有相同 POS 的单词,例如将 “I have a cat” 替换成 “I have a dog”。
- n-gram,在 1-5 中随机采样得到 n,然后采用 n-gram,去掉其他单词。
3.5 实验结果

上面是 Distilled BiLSTM 模型的结果,可以看到比单纯使用 BiLSTM 模型的效果好很多,在 SST 和 QQP 数据集上的效果甚至比 ELMo 好,说明模型能够学习到一部分 BERT 的泛化能力。但是 Distilled BiLSTM 的效果还是比 BERT 差了很多,说明还是有很多知识不能迁移到 BiLSTM 中。
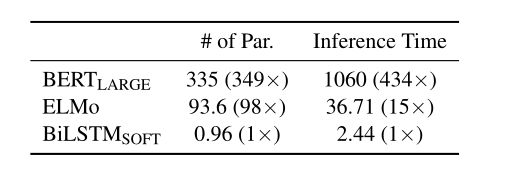
上面是 Distilled BiLSTM 的参数和推断时间,BiLSTM 的参数要远远少于 BERT-large,比 BERT-large 少了 335倍,推断时间比 BERT-large 快了 434 倍。压缩效果还是明显的。
4. TinyBERT: Distilling BERT for Natural Language Understanding
4.1 摘要
语言模型预处理,如BERT,显著提高了许多自然语言处理任务的性能。然而,预先训练过的语言模型通常在计算上很昂贵,因此很难在资源受限的设备上有效地执行它们。为了在保持精度的同时加速推理和缩小模型规模,我们首先提出了一种新的变压器精馏方法,该方法专门为基于Transformer的模型的知识精馏(KD)而设计。通过利用这种新的KD方法,大量的知识编码在一个大的“教师”伯特可以有效地转移到一个小的“学生”TinyBERT。然后,我们为TinyBERT引入了一个新的两阶段学习框架,该框架在预训练和特定任务的学习阶段进行变压器蒸馏。该框架保证了BERT中既包含了通用领域的知识,也包含了任务相关的知识。
4.2 动机
然而,PLMs通常有大量的参数,需要很长的推理时间,这很难部署在边缘设备上,如移动电话。近期研究证明PLMs中存在冗余。因此,在保持PLMs性能的同时减少计算开销和模型存储是至关重要和可行的。
4.3 贡献
为了构建一个具有竞争力的TinyBERT,我们首先提出了一种新的基于Transformer蒸馏方法来提取嵌入在教师BERT中的知识。具体来说,我们设计了三种损失函数来适应不同的BERT层表示:1)嵌入层的输出;2)Transformer层导出的隐状态和注意矩阵;3)预测层的logits输出。BERT学习到的注意权重可以捕获大量的语言知识,从而促进了语言知识可以很好地从BERT老师转移到TinyBERT学生身上。然后,我们提出了一个新的两阶段学习框架,包括一般的提炼和特定任务的提炼,如图1所示。在一般的蒸馏阶段,原BERT没有进行微调,成为教师模型。学生TinyBERT通过在通用域语料库上提出的Transformer蒸馏来模拟教师的行为。在此基础上,我们得到了一个通用的TinyBERT,作为进一步精馏学生模型的初始化。在任务特定的精馏阶段,首先进行数据扩充,然后使用经过微调的BERT作为教师模型对扩充后的数据集进行精馏。需要指出的是,这两个阶段对于提高TinyBERT的性能和泛化能力都是必不可少。

我们在实验中显示,我们的TinyBERT可以实现教师BERTBASEon黏着任务的96.8%的性能,同时拥有更少的参数(约13.3%)和更少的推断时间(约10.6%),并且显著优于其他最先进的BERT蒸馏4层基线; 我们还表明,6层Tinybert可以与教师BERTBASEon胶水媲美。
4.4 模型
假设 TinyBERT 有 M 个 Transformer 层,而 BERT 有 N 个 Transformer 层。TinyBERT 蒸馏主要涉及的层有 embedding 层 (编号为0)、Transformer 层 (编号为1到M) 和输出层 (编号 M+1)。我们需要将 TinyBERT 每一层和 BERT 中要学习的层对应起来,然后再蒸馏。对应的函数为 g(m) = n,m 是 TinyBERT 层的编号,n 是 BERT 层的编号。
对于 embedding 层,TinyBERT 蒸馏的时候 embedding 层 (0) 对应了 BERT 的 embedding 层 (0),即 g(0) = 0;对于输出层,TinyBERT 的输出层 (M+1) 对应了 BERT 的输出层 (N+1),即 g(M+1) = N+1;对于中间的 Transformer 层,TinyBERT 采用 k 层蒸馏的方法,即 g(m) = m × N / M。

Embedding-layer Distillation
![]()
Transformer-layer Distillation
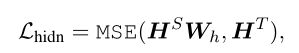
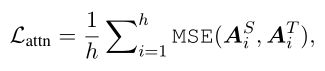
Prediction-Layer Distillation
![]()
总体来看:

4.5 实验
BERT 有两个训练阶段,第一个训练阶段是训练一个预训练模型 (预训练 BERT),第二个训练阶段是针对具体下游任务微调 (微调后的 BERT)。TinyBERT 的蒸馏过程也分为两个阶段:
第一个阶段,TinyBERT 在大规模的 general 数据集上,利用预训练 BERT 蒸馏出一个 General TinyBERT;
第二个阶段,TinyBERT 采用数据增强,利用微调后的 BERT 训练一个 task specific 模型。
论文中的控制变量实验显示 general 的蒸馏对各项下游任务的影响较小,我们此次选择直接用 fine-tune 过的 teacher BERT,蒸馏得到 student BERT。
所以我们蒸馏 TinyBERT 的流程是:
制作任务相关数据集;
fine-tune teacher BERT;
固定 teacher BERT 参数,蒸馏得到 TinyBERT
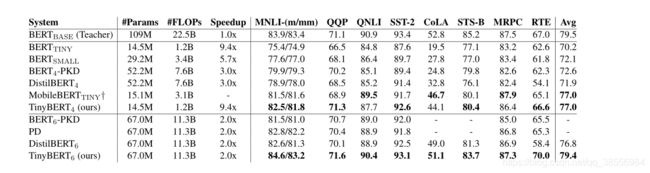
可以看到 TinyBERT 表现优异。在 GLUE 上,相较于完整的 BERT,性能下降 3 个点,但是推理性能却得到了巨大提升,快了 9 倍多