pytorch学习笔记十四:TensorBoard
一、TensorBoard的简介与安装
TensorBoard是Tensorflow中强大的可视化工具,支持标量、图像、文本、音频和 Embedding 等多种数据可视化。可以在模型的训练过程中绘制loss曲线,监控模型的训练效果,也可以对模型的参数分布,数据分布,图像、音频等各种数据的可视化。下面是TensorBoard的一个界面:

TensorBoard是如何显示这个界面的呢?下面来看一下TensorBoard的运行机制
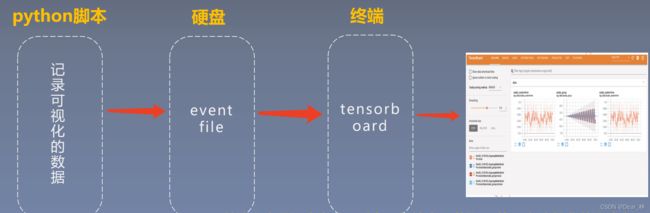
从上图中可看出先从python脚本中记录需要可视化的数据,然后生成eventfile文件存储到硬盘中,从终端运行TensorBoard打开web界面,读取存储在eventfile中的数据在web页面进行可视化。
下面通过代码来了解一下这个流程:
import numpy as np
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter(comment='test_tensorboard')
for x in range(100):
writer.add_scalar('y=2x', x * 2, x)
writer.add_scalar('y=pow(2, x)', 2 ** x, x)
writer.add_scalars('data/scalar_group', {"xsinx": x * np.sin(x),
"xcosx": x * np.cos(x),
"arctanx": np.arctan(x)}, x)
writer.close()
从torch.utils.tensorboard中导入SummaryWriter类,通过这个类创建一个writer,记录需要可视化的数据。直接运行上述代码,可能会报错,【ModuleNotFoundError: No module named ‘tensorboard’ 】和【ModuleNotFoundError: No module named ‘past’】需要安装tensorboard和past,安装命令是:
pip install tensorboard
pip install future
安装完成之后,运行代码会生成一个runs文件夹

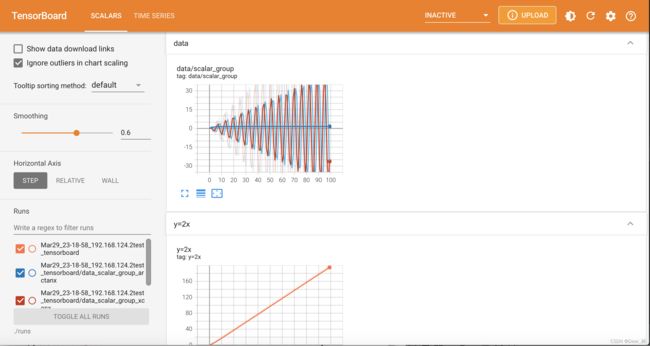
在终端输入tensorboard --logdir=./runs,点击生成的链接,即可看到如下的界面
二、TensorBoard的使用
Tensorbord的基本使用包括准确率和损失函数的可视化,参数的数据分布以及梯度的分布,图像数据的可视化等。
1、SummaryWriter
官网链接:链接
SummaryWriter 用于记录需要可视化的数据,包括标量、图像、文本、音频和 Embedding 等多种数据类型,然后用tensorboard在终端进行可视化。

功能:记录数据并自动生成 event file,供tensorboard进行可视化。该类是异步更新文件内容,也就是说允许训练程序调用方法以直接从训练循环中将数据添加到文件,而不会减慢训练速度。
主要参数:
log_dir::文件保存路径,默认为runs/CURRENT_DATETIME_HOSTNAME
comment:默认文件的后缀,若log_dir指定安装目录,则此参数无效
例如:
from torch.utils.tensorboard import SummaryWriter
# create a summary writer with automatically generated folder name.
writer = SummaryWriter()
# folder location: runs/May04_22-14-54_s-MacBook-Pro.local/
# create a summary writer using the specified folder name.
writer = SummaryWriter("my_experiment")
# folder location: my_experiment
# create a summary writer with comment appended.
writer = SummaryWriter(comment="LR_0.1_BATCH_16")
# folder location: runs/May04_22-14-54_s-MacBook-Pro.localLR_0.1_BATCH_16/
主要方法:
1、add_scalar:添加标量数据
add_scalar(tag, scalar_value, global_step=None, walltime=None)
tag:图像的标签
scalar_value:要标记的标量
global_step:x轴
2、add_scalars:添加多个标量数据
add_scalars(main_tag, tag_scalar_dict, global_step=None, walltime=None)
main_tag:图像的标签
tag_scalar_dict:字典,存储标量值和对应的标签,key是变量的tag,value是变量的值
3、add_histogram:添加直方图或多分位数折线图
add_histogram(tag, values, global_step=None, bins='tensorflow', walltime=None, max_bins=None)
tag:图像的标签
values:要统计的参数
global_step:y轴
4、add_image:添加图片数据
add_image(tag, img_tensor, global_step=None, walltime=None, dataformats='CHW')
tag:图像的标签名,图像的唯一标识符
img_tensor:图片值 0~255之间,默认(3, H, W),另外可以用torchvision.utils.make_grid()将一个batch的数据转化为3xHxW 的格式或者可以用add_images()方法。图片格式为 (1, H, W) , (H, W), (H, W, 3)同样适用,只要传入相应的格式即可。
global_step:x轴
dataformats:数据形式,CHW,HWC,HW
torchvision.utils.make_grid()

功能:制作网格图像;
tensor:图像数据,BCH*W形式;
nrow:行数(列数自动计算)
padding:图像间距(像素单位)
normalize:是否将像素值标准化
range:标准化范围
scale_each:是否单张图维度标准化
pad_value:padding的像素值
5、add_images:添加batch的图片数据
add_images(tag, img_tensor, global_step=None, walltime=None, dataformats='NCHW')
img_tensor:图像数据 ,格式默认为(N, 3, H, W)
6、add_figure:添加matplotlib图像
add_figure(tag, figure, global_step=None, close=True, walltime=None)
figure:图像或者图像列表
7、add_video:添加视频数据
add_video(tag, vid_tensor, global_step=None, fps=4, walltime=None)
8、add_graph:可视化模型计算图
add_graph(model, input_to_model=None, verbose=False, use_strict_trace=True)
model:需要可视化的模型,必须是nn.Module
input_to_model:模型输入的数据
verbose:是否打印计算图结构信息
9、其他
add_audio:添加音频数据;
add_text:添加文本数据;
add_embedding:添加embedding数据;
以上每个方法的具体使用可参考官网给的例子,下面从人民币的二分类来具体看一下summarywriter是如何记录模型训练过程中的参数值的:
监控模型训练过程中的loss、acc以及参数的分布和参数梯度的分布,在模型训练之前构建一个summarywriter,
# 构建 SummaryWriter
writer = SummaryWriter(comment='test_your_comment', filename_suffix="_test_your_filename_suffix")
对应生成的文件路径为:

如何在模型训练过程中添加要监控的指标变化值
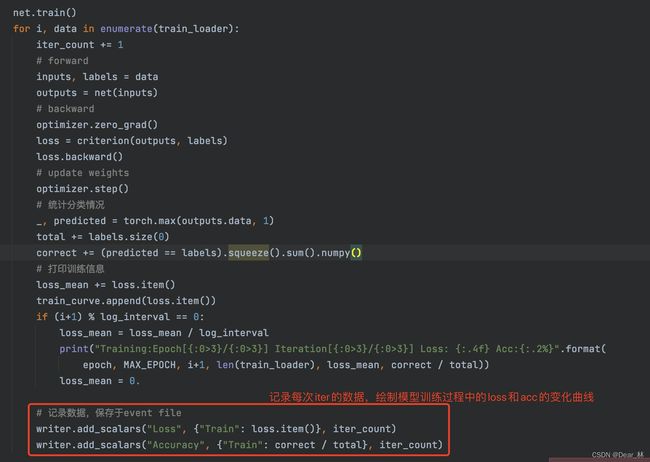

记录验证集上损失函数和准确率的变化曲线图
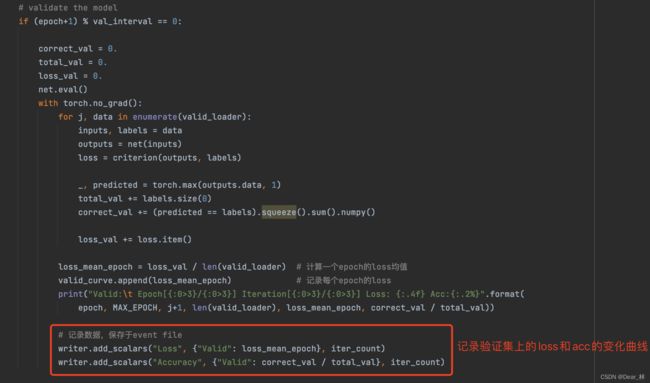
最终显示结果:
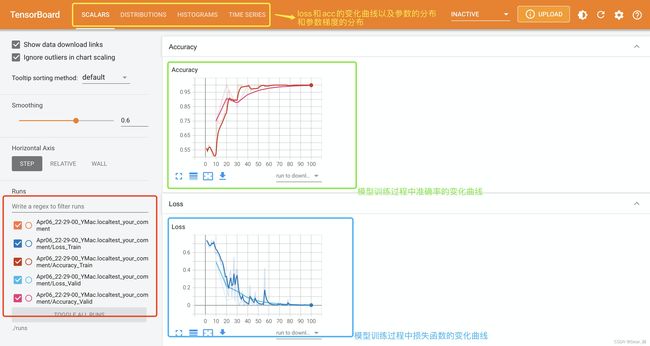
下面来看一下参数的分布和参数梯度的分布:
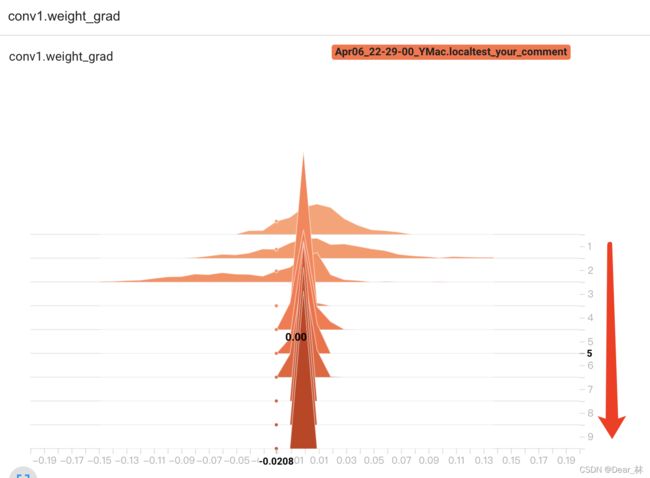
这是conv1的权重梯度分布,可以看出随着epoch的增加,逐渐趋于0,这有两个原因一是因为模型训练的不错,loss很小了二是梯度逐渐消失了,那这个该如何判断呢?

这是最后一层的参数梯度分布,可看出参数的梯度是随着epoch的增加逐渐趋于0的,这说明loss确实是减小了,模型训练的不错。
以上就是如何用summarywriter中的add_scalars 和add_histogram 方法如何监控模型训练过程中的参数变化,下面再来看一下summartwriter中其他几个常用的方法:
writer = SummaryWriter()
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))])
trainset = datasets.MNIST('mnist_train', train=True, download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=64, shuffle=True)
model = torchvision.models.resnet50(False)
# Have ResNet model take in grayscale rather than RGB
model.conv1 = torch.nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3, bias=False)
images, labels = next(iter(trainloader))
grid = torchvision.utils.make_grid(images)
writer.add_image('images', grid, 0)
writer.add_graph(model, images)
writer.close()
可视化mnist数据集一个batch的图片和模型结构示意图,可视化结果显示如下:

模型结构示意图:
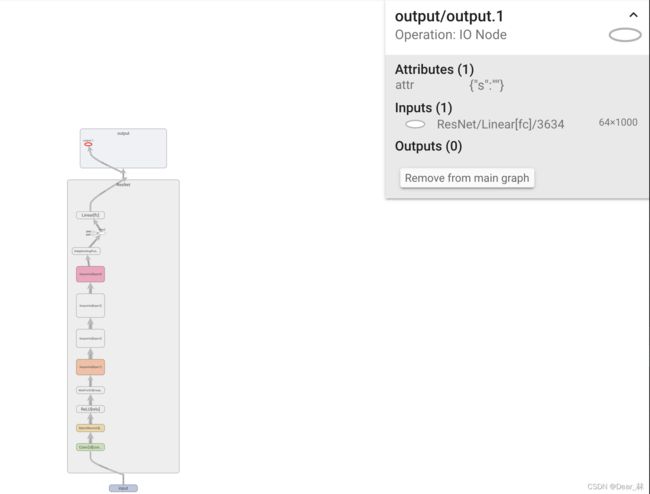
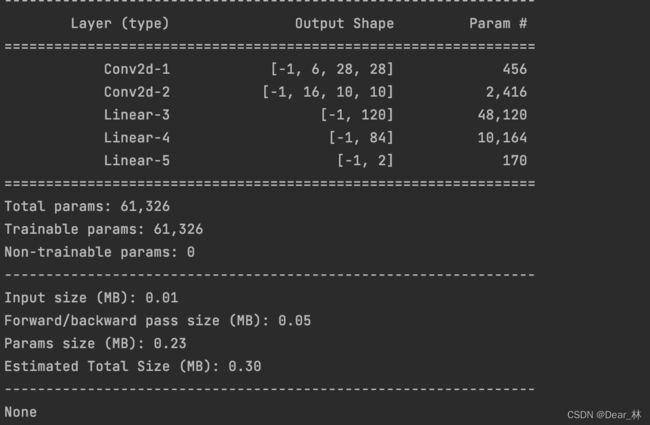
上面是可视化模型的计算图,有时还会关注数据经过模型的各个板块之后的shape变化,torchsummary函数用来实现此功能。

功能:查看模型信息,便于调试,打印模型的输入输出shape以及参数量
model:pytorch模型
input_size:模型输入的size
batch_size:batch size大小,一般设为默认
device:cuda 或者 cpu
举个栗子:
writer = SummaryWriter(comment='test_your_comment', filename_suffix="_test_your_filename_suffix")
# 模型
fake_img = torch.randn(1, 3, 32, 32)
lenet = LeNet(classes=2)
writer.add_graph(lenet, fake_img)
writer.close()
from torchsummary import summary
print(summary(lenet, (3, 32, 32), device="cpu"))
显示结果: