使用PyEcharts简单分析csv文件数据
使用pyecharts之前我们要获取首先我们获取网站数据,并且将获取的数据在csv文件中进行必要的转码,如utf-8,gbk23等编码,并且将一些空白的项剔除,删除干扰值
#-*-coding:utf8-*-
#1.发送请求,用python代码模拟浏览器发送请求
#2.获取数据,获取服务器返回的response响应数据
#3.解析数据,提取我们想要的数据内容
#4.保存数据,保存到csv表格中
#5.多页爬取
#记得把下面的注释回去,不然我发布不了博客
#import requests
#import parsel
#import csv
#import pandas as pd
f=open("票房.csv",mode="a",encoding="utf-8",newline="")
csv_writer=csv.DictWriter(f,fieldnames=[
"排名",
"电影名",
"年份",
"类型"
])
#写入表头
csv_writer.writeheader()
#发送请求
url="http://www.piaofang.biz/"
#请求头 伪装python代码
headers={
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36 Edg/107.0.1418.42"
}
response=requests.get(url=url,headers=headers)
#因为爬取页面编码格式为GB2312所以需要将得来的请求转换成gb2312
response.encoding="gb2312"
#获取的响应体对象
#获取响应体的文本数据
#2.获取数据,获取服务器返回的response响应数据
#3.解析数据re正则表达式 css选择器 xpath解析方法
#直接对字符串数据进行提取的话,只能用re正则表达式
#需要把获取下来的html字符串数据内容转换一下
selector=parsel.Selector(response.text)
#css选择器 根据标签属性内容 提取数据
#分成两次提取数据 第一次提取 提取所有标签 第二次在提取我们想要的数据
#tr为根节点
lis=selector.css("tr")
for td in lis:
num=td.css("td.num::text ").get()
title = td.css("td.title a::text").get()
year=td.css("td.year::text").get()
type=td.css("td.type::text").get()
dit={
"排名":num,
"电影名":title,
"年份":year,
"类型":type
}
csv_writer.writerow(dit)
if title!=None:
print(num," ",title," ",year," ",type)
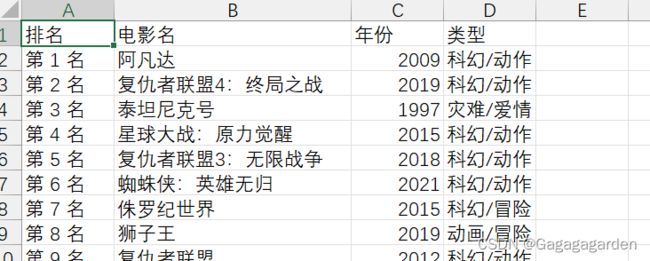
csv文件如下,务必记得进行转码否则csv文件中看到的是乱码
接着再开始使用这个得到的csv文件用pyEcharts库进行简易的数据分析
from pyecharts.charts import Bar
from pyecharts.charts import Pie
from pyecharts import options as opts
from pyecharts.globals import ThemeType
import pandas as pd
import numpy as np
bar=Bar(init_opts=opts.InitOpts(theme=ThemeType.DARK))
#读入文件
file=pd.read_csv("票房.csv",encoding="utf-8")
#取出表头为年份的数据
year = file["年份"].values
#取出表头为类型的数据
types=file["类型"].values
# print(year)
# print(types)
#新建列表存放年份
new_year=[]
#把nan去除
for elem in year:
if not np.isnan(elem):
new_year.append(elem)
#把列表里面的浮点数年份转换成整型年份
new_year=list(map(int,new_year))
#取出所有的表头
title=file.columns.values
#得到不同年份
key=set(new_year)
# print(list(key))
#根据key中每一个年份进行遍历
num=[]
for year in key:
num.append(new_year.count(int(year)))
#得到不同的类型
types=list(types)
type=set(types)
dict={}
for i in types:
if types.count(i)>1:
dict[i]=types.count(i)
#删除字典中的nan
dict={k: v for k,v in dict.items() if k==k}
print(dict)
#键值对分别组成列表
keys=dict.keys()
values=dict.values()
keys=list(keys)
values=list(values)
print(keys)
print(values)
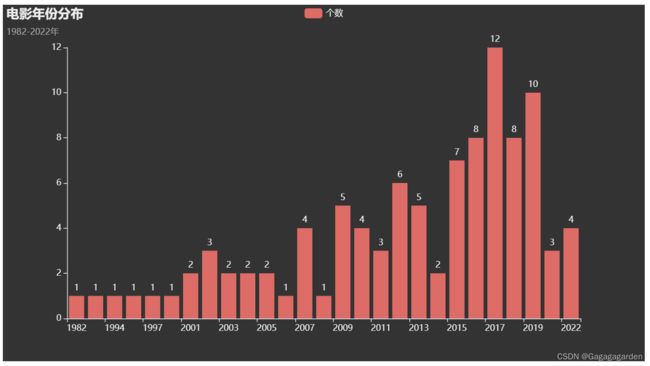
bar.add_xaxis(key)
bar.add_yaxis("个数",num)
bar.set_global_opts(title_opts=opts.TitleOpts(title="电影年份分布",subtitle="1982-2022年"))
bar.render()
#
pie=Pie()
pie.add("",[list(z) for z in zip(keys,values)])
pie.set_global_opts(title_opts=opts.TitleOpts(title="类型"))
pie.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}:{c}"))
pie.render(path="pie.html")打开生成的html文件