激光感知(十二):PointRCNN
目录
- 一:思路概括
- 二:网络结构
-
-
- 1. 第一阶段:自底向上的预选框生成
- 2. 第二阶段:再筛选和优化bounding box
-
一:思路概括
PointRCNN目标检测算法分两个阶段:
1)第一阶段:首先对点云进行语义分割,对每个点得到一个预测label,比如对所有判断是“车”的点(也叫做前景点),赋予label=1,其他点(也叫做背景点),赋予label=0。然后,用所有前景点生成bounding box,一个前景点对应一个bounding box,然后用了去除冗余的方法,继续减少bounding box的数目,这一阶段结束的时候只留下300个bounding box。
2)第二阶段:继续优化上一阶段生成的bounding box。首先,对前一阶段生成的bounding box做旋转平移,把这些bounding box转换到自己的正规划坐标系下(canonical coordinates)。然后,通过点云池化等操作的到每个bounding box的特征,再结合第一阶段的到的特征,进行bounding box的修正和置信度的打分,从而的到最终的bounding box。
二:网络结构

1. 第一阶段:自底向上的预选框生成
这个阶段有两个功能:分割前景点,生成预选框。
先用pointnet提取点云的特征。输入是(bs, n, 3)的点云,输出是(bs, n, 128)的特征。然后接了一个前景点分割网络和一个box生成网络。
前景点分割网络,是由两个卷积层组成。输入是那个(bs, n, 128)的特征,输出是(bs, n, 1)的mask。1表示这个点属于前景点的概率,值越大,则它属于前景点的概率越高。加一个sigmoid限制到(0,1),然后用focal loss计算损失。focal loss本身是为了减少容易分类的样本的权重,将权重尽量集中于难分类样本上。公式如下:

box生成网络,也是由两个卷积层组成。输入是那个(bs, n, 128)的特征,输出是(bs, n, 76)。对于3d目标检测里的bounding box,需要7个量来表示:box中心点(x,y,z), box的长,宽,高(w,h,l),俯视图的旋转角ry。这里用基于bin的预测方法使76个维度特征来代表这7个量,如下图所示。

bin就相当于直尺上的刻度,在上图中用绿色大括号表示,这里设置物理空间中0.5m是一个bin。通过预测每个点对于bounding box中心点偏移了几个bin,加上已知这个点本身的坐标,就可以得到中心点的坐标,所以只用知道一大堆前景点里面预测最准确的点就可以得出bounding box。衡量坐标的时候是物理尺度上划分了几个bin,旋转角也用这种基于bin的方法预测,是把2π话分成若干个bin。
由于bin是一个整数,还是无法精确定位,所以还需要中心点坐标在一个bin中的偏移量,把这个偏移量叫做res。
下图表示通过76维度特征预测bounding box的过程。
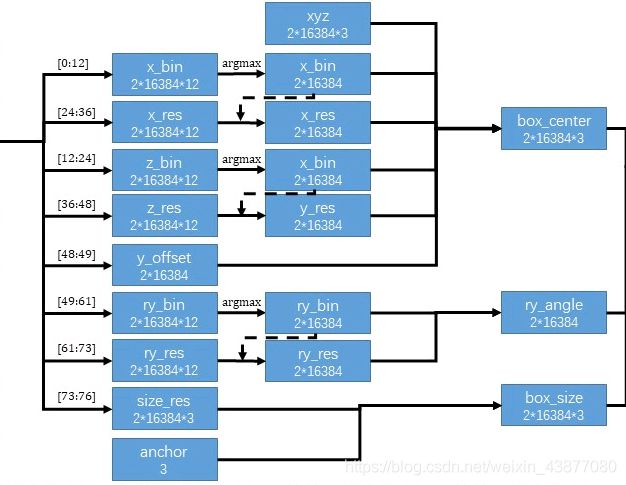
这一步网络的输出是(bs, n, 76),也就是说对场景中的每一个点,预测一个bounding box。可以知道这样预测是非常冗余的,所以结合之前分割得到的mask,只考虑前景点的预测结果。再使用了NMS算法来进一步减少bounding box。
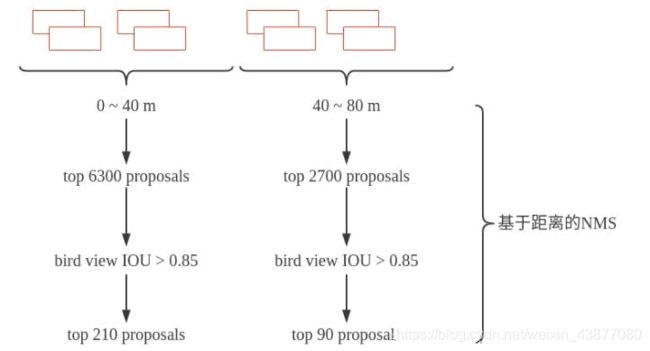
在相机 0~40m距离内的bounding box,先取得分类得分最高的6300个,然后计算bird view IOU,把IOU大于0.85的都删掉,到这里bounding box 又少了一点。然后再取得分最高的210个。在距离相机40~80m的范围内用同样的方法取90个。这样第一阶段结束的时候只剩下300个bounding box了。再进行第二阶段置信度打分和bounding box优化。
2. 第二阶段:再筛选和优化bounding box
这一阶段的输入是300个proposal bounding box,大小表示为(bs,300,7)。然后用sample和设置阈值的方法把bbox减少到128个。把在每个bounding box proposal 内部的点聚集起来,就的到大小为(bs,m,512,c)的数据。其中 bs表示batch size, m表示每个batch中有多少个bounding box(比如上面提到的128), 512表示每个bounding box里面有多少个point。然后进行数据增强操作。
接下来把每个bounding box内的points转换到局部坐标系(canonical 转换)下。如下图。

具体就是,新坐标系的坐标原点是bbox的中心点。并且让新的x轴和这个bbox头部平行。第二阶段会结合第一阶段预测的到的大小为(bs,n,128)的feature。
把大小为(bs,n,1)的mask,每个点距离相机的距离,每个点的反射强度(从雷达相机直接可以得到的值),每个点的坐标(x,y,z)。把这些特征concat在一起作为一个新的local特征。上采样到128维度,和第一阶段预测得到的128维的global feature结合的到新的特征。新特征为256维。
用pointnet++的SA module(pointnet++是一个采样,分组,特征提取模块)继续对这个特征进行卷积操作,得到一个(m,1,512)的特征,表示一个场景中有m个bounding box, 一个512维的point来代表这个bbox。
最后分别接一个reg_layer和一个cls_layer(conv1d)改变特征通道。得到(m,46)的bbox相关的预测结果和(m,1)的置信度结果。
这个46特征也是基于bin的预测,只是现在0-6表示x_bin,从而得到128个bounding box。结合预测得到的confidence筛选出最后的bounding box。PointRCNN检测结果如下图所示。
