基于CNN遥感图象分类+前后端交互
基于CNN遥感图像分类+前后端交互
基于CNN遥感图像分类+前后端交互
一、项目介绍
1.1 项目简述
1.2 几个概念
二、遥感图片分类模型
2.1 训练数据的处理
三、效果展示
参考资料
项目完整代码:GitHub
一、项目介绍
1.1 项目简述
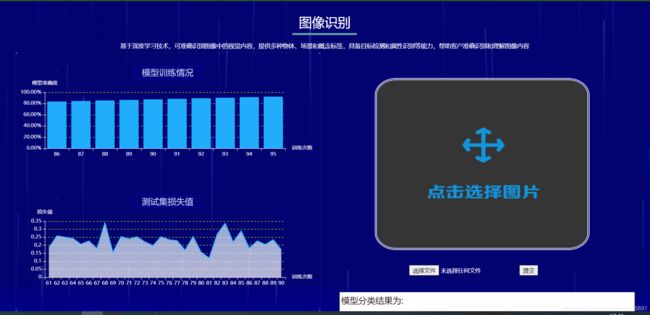
通过遥感影像判读识别地物,进行地物信息的识别,提取,分类,进行动态变化监测,以及专题地图制作,遥感图库的建立,设计初期各种格局指数的计算,以及安全格局的建立,都要以图像分类为基础。该项目采用CNN神经网络实现对遥感图片的分类,准确率在90%左右,网络架构中有三层卷积层,两层全连接层,最后采用Softmax激活函数计算每个目标类别在所有可能的目标类中的概率,即可对传入的图片进行分类。后端采用Flask框架实现用户在前端提交页面后,后台调用训练好的模型对传入图片进行分类,再将结果返回到前端页面。可视化方面提取模型训练过程中生成的训练信息中的模型准确率和损失值作为数据,利用E-Chars图表进行动态展示。
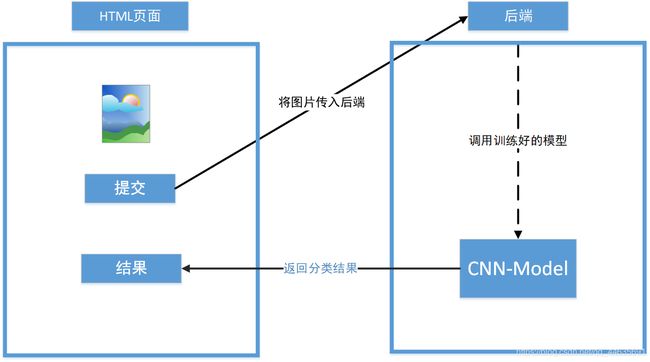
项目架构图
1.2 几个概念
有监督学习(Supervised learning)
图像分类是属于深度学习的有监督学习方式,有监督学习的任务是在给定大量组“输入数据-输出结果”的数据中,学习一个可以描述这中关系的“函数”的过程。与此相对的是无监督学习(Unsupervised learning),无监督学习是一种机器学习的另一种方式,它在没有预先存在的标签和最少的人工监督的情况下,在数据集中寻找先前未检测到的模式。
卷积神经网络(Convolutional Neural Networks)
CNN被广泛用来做图像识别、图像分类、目标检测等任务。CNN中每个输入图像都会通过一系列带滤波器(Filter )、池(Pooling)、完全连接层(Fully connected)的卷积层,以获得更强的表达能力,并应用Softmax函数对概率值介于0到1之间的对象进行分类。例如猫狗分类中,通过向网络中传入一张图片经过各层运算后得到是猫和狗概率值分别为0.45和0.98,所以判断传入图片属于狗。下图是CNN处理输入图像的完整流程。
 来源:https://medium.com/@RaghavPrabhu/understanding-of-convolutional-neural-network-cnn-deep-learning-99760835f148
来源:https://medium.com/@RaghavPrabhu/understanding-of-convolutional-neural-network-cnn-deep-learning-99760835f148
其中有几个关键操作:
- 卷积(Convolution)
卷积神经网络的名称表明该类神经网络采用一种称为卷积的数学运算。卷积是一种特殊的线性运算。卷积网络是一种简单的神经网络,它在至少一个层中使用卷积代替一般的矩阵乘法卷积是从输入图像中提取特征的第一层,通过使用滤波器(Filter)学习图像特征来保持像素之间的关系。用不同的滤波器对图像进行卷积可以进行边缘检测、模糊和锐化等操作。二维数据的卷积操作如下图所示。

来源:网络
- 池化(Pooling)
池化层也叫下采样层,与卷积层类似,池化层负责减小卷积特征的空间大小。
主要作用:(1) 降低信息冗余;(2) 提升模型的尺度不变性、旋转不变性;(3) 防止过拟合。
一般有:
平均池化(
average pooling):计算图像区域的平均值作为该区域池化后的值。最大池化(
max pooling):选图像区域的最大值作为该区域池化后的值。
- 全连接层(Fully Connected Layer)
添加全连接层是学习由卷积层的输出表示的高级特征的非线性组合的方法。全连接层在这个空间学习一个可能的非线性函数。我们将矩阵展平成向量,然后将其输入到一个完全连接的层中。

来源:https://medium.com/@RaghavPrabhu/understanding-of-convolutional-neural-network-cnn-deep-learning-99760835f148
二、遥感图片分类模型
2.1 训练数据的处理
该项目采用的是数据集是尺寸为256x256的遥感图片,每种图片700张,种类有沙漠、岛屿、公路、房屋,如下图所示。
2.1.1 图像数据预处理
import cv2
import os
import glob
from sklearn.utils import shuffle
import numpy as npload_train函数主要实现对多个文件中的图像,通过从cv2读入转化为矩阵,并对每张图片打标签,这里体现了监督式学习。
# 图像预处理
def load_train(train_path, image_size, classes):
# 保存所有读入图像的矩阵
images = []
# 总标签列表记录所有读入的,图像的标签
labels = []
img_names = []
cls = []
print('现在开始读取图像:')
# 遍历类比:先读island的图像,再读seaice的图像
for fields in classes:
k = 1
index = classes.index(fields)
print('现在读取 {} 文件夹下图片 (索引号: {})'.format(fields, index))
path = os.path.join(train_path, fields, '*g') # 把文件夹下的所有图片的路径拿到
files = glob.glob(path) # 遍历每个图片
# 高速路类、房屋的变量
for fl in files:
image = cv2.imread(fl)
# 将图像大小转成64x64
image = cv2.resize(image, (image_size, image_size), 0, 0, cv2.INTER_LINEAR)
k = k + 1
image = image.astype(np.float32)
# 归一化:矩阵数值都转成0到1之间
image = np.multiply(image, 1.0 / 255.0)
# 加到总图像列表中
images.append(image)
# 每类图片有自己的label
label = np.zeros(len(classes))
# 例如:高速路时:label=[0,1,0,0] 房屋时:label=[0,0,1,0]
label[index] = 1.0
labels.append(label)
flbase = os.path.basename(fl)
img_names.append(flbase)
cls.append(fields)
# 把所有列表转换为一维数组/矩阵
images = np.array(images)
labels = np.array(labels)
img_names = np.array(img_names)
# 所有图片所属标签
cls = np.array(cls)
# 图片已拿到并预处理:把读入并加过标签的数据返回为辅助函数3
return images, labels, img_names, cls2.1.2 划分训练集和测试集
因为图片的读入是按照已经划分好类别进行读入的,所以每类图片都是集中在一起的,划分前需要对数据集进行打乱再按照比例进行打乱。
# 打乱数据集并分为测试集和训练集
def read_train_sets(train_path, image_size, classes, validation_size):
class DataSets(object):
pass
data_sets = DataSets()
# 调用图像预处理函数
images, labels, img_names, cls = load_train(train_path, image_size, classes)
# 打乱数据集
images, labels, img_names, cls = shuffle(images, labels, img_names, cls)
# 设定测试集的样本数:(判断数据类型isinstance)
if isinstance(validation_size, float):
# 测试集个数 = 20% * 1400
validation_size = int(validation_size * images.shape[0])
# 测试集
validation_images = images[:validation_size]
validation_labels = labels[:validation_size]
validation_img_names = img_names[:validation_size]
validation_cls = cls[:validation_size]
# 训练集
train_images = images[validation_size:]
train_labels = labels[validation_size:]
train_img_names = img_names[validation_size:]
train_cls = cls[validation_size:]
# 调用函数2:
data_sets.train = DataSet(train_images, train_labels, train_img_names, train_cls)
data_sets.valid = DataSet(validation_images, validation_labels, validation_img_names, validation_cls)
# 返回一个包含训练集和测试集相关信息的类
return data_sets2.2 构建CNN神经网络
为创建卷积层、全连接层编写函数方便调用
# 权重参数设置
def create_weights(shape):
return tf.Variable(tf.truncated_normal(shape, stddev=0.05))
def create_biases(size):
return tf.Variable(tf.constant(0.05, shape=[size]))# 创建卷积层的函数:卷积池化各层参数的设置与工作
def create_convolutional_layer(input,
num_input_channels,
conv_filter_size,
num_filters):
# 权重参数初始化:3 3 3 32
# 前两个参数是滑动窗尺寸3x3 第三个参数为3通量 第4个参数是这一层观察多少个特征
weights = create_weights(shape=[conv_filter_size, conv_filter_size, num_input_channels, num_filters])
biases = create_biases(num_filters)
# 执行一次卷积操作
layer = tf.nn.conv2d(input=input,
filter=weights,
strides=[1, 1, 1, 1],
padding='SAME')
layer += biases
# relu激活函数:激活后的数值传给下一步
layer = tf.nn.relu(layer)
# 池化操作:上一卷积层的输出就是这里的输入;池化窗尺寸为2x2
layer = tf.nn.max_pool(value=layer,
ksize=[1, 2, 2, 1],
strides=[1, 2, 2, 1],
padding='SAME')
return layer
# 全连接层参数的设置
def create_flatten_layer(layer):
# 把到最后一个卷积池化层的尺寸:[7,8,8,64]
# 既然是全连接层,就要把它拉伸;即对这个全连接层的"输入"应有8x8x64=4096个
layer_shape = layer.get_shape()
# 计算得到那个4096的数值
num_features = layer_shape[1:4].num_elements()
# 转换成数组/矩阵
layer = tf.reshape(layer, [-1, num_features])
return layer
# 全连接层创建与工作
def create_fc_layer(input,
num_inputs,
num_outputs,
use_relu=True):
# 全连接层的权重参数等的设置
weights = create_weights(shape=[num_inputs, num_outputs])
biases = create_biases(num_outputs)
# 计算:
layer = tf.matmul(input, weights) + biases
# dropout解决过拟合,随机剔除30%个节点
layer = tf.nn.dropout(layer, keep_prob=0.7)
# relu激活函数
if use_relu:
layer = tf.nn.relu(layer)
return layer模型训练函数
def train(num_iteration):
global total_iterations
for i in range(total_iterations,
total_iterations + num_iteration):
x_batch, y_true_batch, _, cls_batch = data.train.next_batch(batch_size)
x_valid_batch, y_valid_batch, _, valid_cls_batch = data.valid.next_batch(batch_size)
# 做好每一个epoch
feed_dict_tr = {x: x_batch, y_true: y_true_batch}
feed_dict_val = {x: x_valid_batch, y_true: y_valid_batch}
# 开始运行训练
# 保存权重信息,在tensorboard可视化显示
summary, _ = session.run([merged, optimizer], feed_dict=feed_dict_tr)
writer.add_summary(summary, i)
if i % int(data.train.num_examples / batch_size) == 0:
# 损失值
val_loss = session.run(cost, feed_dict=feed_dict_val)
epoch = int(i / int(data.train.num_examples / batch_size))
show_progress(epoch, feed_dict_tr, feed_dict_val, val_loss, i)
# 保存文件夹的地方
saver.save(session, './model1/savemodel.ckpt', global_step=i)
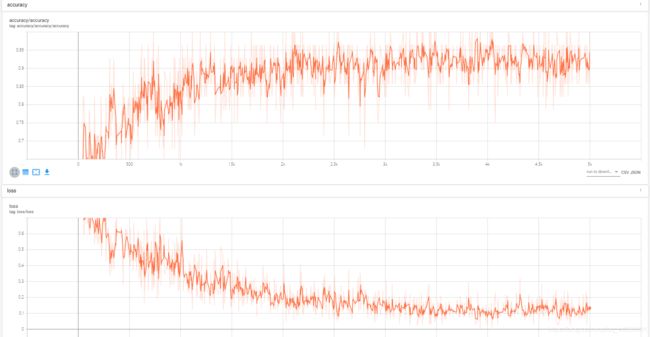
total_iterations += num_iteration模型训练记录
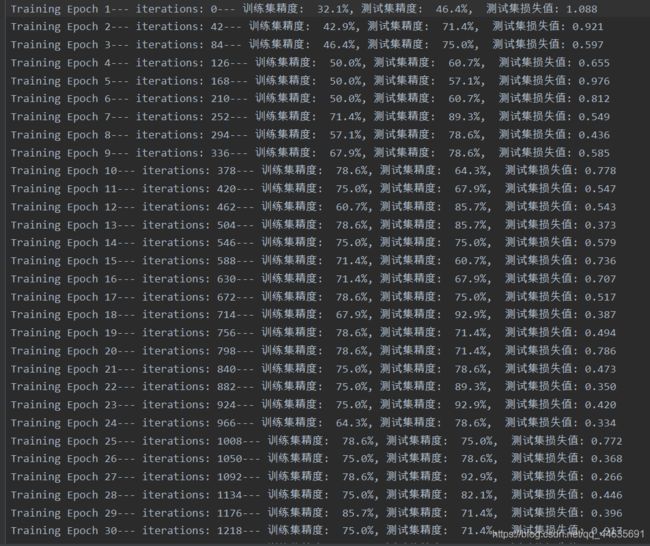
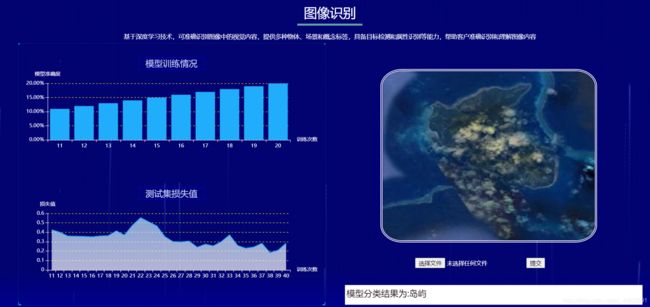
三、效果展示
传入一张岛屿图片,下方显示模型分类结果
模型相关信息在tensorboard查看
- 模型结构
- 模型训练过程的信息
- 权重信息



参考资料
【1】Stuart J. Russell, Peter Norvig (2010) Artificial Intelligence: A Modern Approach, Third Edition, Prentice Hall ISBN 9780136042594.
【2】http://cadesign.cn/bbs/thread-548-1-1.html