Playwright(python)微软浏览器自动化教程(二)
写在前面,欢迎去我的博客参观:Scout he
1、Browser
这是一个浏览器实例,脚本运行需要首先打开浏览器实例
# playwright.brwoser_type.action(**kwargs)可以理解为指定浏览器内核
browser = playwright.chromium.launch(channel="chrome",headless=False)
# launch是最常用的一个函数,他有大量的参数,这里介绍常用的的
headless 是否显示GUI,默认是TRUE不显示
channel 指定浏览器版本,"chrome", "chrome-beta", "chrome-dev", "chrome-canary",
proxy 浏览器代理设置
timeout 等待超时时间,默认30000ms(30s)
slow_mo 减慢操作速度,浮点型,一边可以看清楚操作
顺便说一下,playwright的所有操作都有自动等待的功能,时间都是30s
2、Browser contexts
这个是独立的浏览器,隐身对话,意思是每一个Beowser contexts都是独立的,互相之间没有关系,等于说全都是新装的浏览器。
# 根据浏览器内核创建浏览器
context = browser.new_context(accept_downloads=False)
# 创建新页面
page = context.new_page()
2.1、browser.new_context
# browser.new_context的参数包括所有跟浏览器设置相关的
# 可以理解为根据浏览器创建一个新的浏览器
accept_downloads 是否下载所有附件,默认False不下载
geolocation 设定经纬度
user_agent 设定user agent
viewport 设定页面大小,规格,例如1280*720
offline 离线模式加载
2.2、context
# context就是浏览器层面的操作
context.new_page() 返回一个新页面
context.pages 返回所有打开的页面[list]
context.add_cookies([cookie_object1, cookie_object2]) 添加cookie
context.cookies() 返回cookie
context.wait_for_event(event, **kwargs) 等待event完成
3、Pages and frames
一个 Browser contexts 有多个pages,一个 page 是一个单独的tab,或者弹出窗口。用于导航到url ,或者与页面交互,比如点击,输入文字等。
一个 page 有多个 Frame (框架),框架内的操作无法通过page.**操作,只能通过page.Frame.func()操作,但是通常在录制模式下,他会自动识别是否是框架内的操作,如果不懂怎么定位框架,那么可以使用录制模式来找。
3.1、Pages
大部分操作都是在page层面的,所以page有最多的函数
from playwright.sync_api import sync_playwright
# 这是一个创建页面,定位到指定链接,并截屏保存的例子
def run(playwright):
webkit = playwright.webkit
browser = webkit.launch()
context = browser.new_context()
page = context.new_page()
page.goto("https://example.com")
page.screenshot(path="screenshot.png")
browser.close()
with sync_playwright() as playwright:
run(playwright)
常用的函数有,一般看名字就知道是干嘛的
page.click(selector, **kwargs)
page.content() # 获取页面的html
page.screenshot(**kwargs)
page.goto(url, **kwargs)
page.pdf(**kwargs)
page.reload(**kwargs)
page.wait_for_timeout(timeout)
page.get_attribute(selector, name, **kwargs)
# page的expect_**函数需要注意
# 这个类型的函数一般都伴随这with使用
# 下面这个例子就是点击按钮后,改变了页面框架
with page.expect_event("framenavigated") as event_info:
page.click("button")
frame = event_info.value
#这样的还有很多,比如,大都用在交互的对象改变的情况下
page.expect_file_chooser(**kwargs)
page.expect_navigation(**kwargs)
page.expect_popup(**kwargs)
# 个人推荐注意这几个is的方法,在等待页面的时候很有用
page.is_disabled/(selector, **kwargs)
is_editable,is_enabled,is_hidden,is_visible
# 还有一个特殊的方法
page.locator(selector) # 定位页面元素,返回的是locator对象
3.2、Frame
frame的操作大部分跟page一样,只不过frame是page下一级的,可以理解为在page里嵌套的一个小页面。但是还是有一点不一样。
page里分为主框架和子框架,这里有一个框架树的例子,大家可以运行下试试。
from playwright.sync_api import sync_playwright
def run(playwright):
firefox = playwright.firefox
browser = firefox.launch()
page = browser.new_page()
page.goto("https://www.theverge.com")
dump_frame_tree(page.main_frame, "")
browser.close()
def dump_frame_tree(frame, indent):
print(indent + frame.name + '@' + frame.url)
for child in frame.child_frames:
dump_frame_tree(child, indent + " ")
with sync_playwright() as playwright:
run(playwright)
其方法大部分都与page一样,不在赘述,注意的是
page.frame(**kwargs),这个可以用来选择Frame,并返回Frame对象,所以对Frame的操作有一下两种方法。
# 直接定位Frame操作
page.frame(name="frame-name").click('text=hello')
#返回Frame对象操作
frame = page.frame(name="frame-name")
frame.click('text=hello')
4、Selectors
Playwright可以通过css,XPath,HTML等选择元素,像id,data-test-id,或者像上面演示的,通过text内容。
这里有一些例子
# Using data-test-id= selector engine
page.click('data-test-id=foo')
# CSS and XPath selector engines are automatically detected
page.click('div')
page.click('//html/body/div')
# Find node by text substring
page.click('text=Hello w')
# 通过 >> 链接相同或不同的选择器
# Click an element with text 'Sign Up' inside of a #free-month-promo.
page.click('#free-month-promo >> text=Sign Up')
我推荐使用浏览器的开发者模式来寻找选择器:
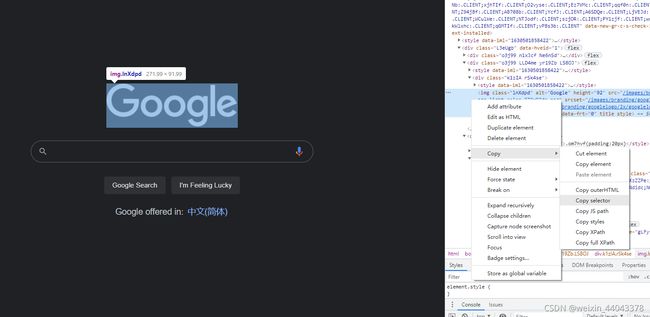
5、Auto-waiting
所有的操作都会等待元素可见,或者可操作之后才会进行,也就是自带等待时间,但是如果要自己加等待的话不推荐使用time.sleep(5),而是用page.wait_for_timeout(5000)。
这里也可以使用page的wait操作:
page.wait_for_event(event, **kwargs)
page.wait_for_function(expression, **kwargs)
page.wait_for_load_state(**kwargs)
page.wait_for_selector(selector, **kwargs)
page.wait_for_timeout(timeout)
page.wait_for_url(url, **kwargs)
6、Evaluation Argument
像 page.evaluate(expression, **kwargs) 这样的剧作家评估方法采用单个可选参数。 此参数可以是 Serializable 值和 JSHandle 或 ElementHandle 实例的混合。 句柄会自动转换为它们所代表的值。
# A primitive value.
page.evaluate('num => num', 42)
# An array.
page.evaluate('array => array.length', [1, 2, 3])
# An object.
page.evaluate('object => object.foo', { 'foo': 'bar' })
# A single handle.
button = page.query_selector('button')
page.evaluate('button => button.textContent', button)
# Alternative notation using elementHandle.evaluate.
button.evaluate('(button, from) => button.textContent.substring(from)', 5)
# Object with multiple handles.
button1 = page.query_selector('.button1')
button2 = page.query_selector('.button2')
page.evaluate("""o => o.button1.textContent + o.button2.textContent""",
{ 'button1': button1, 'button2': button2 })
# Object destructuring works. Note that property names must match
# between the destructured object and the argument.
# Also note the required parenthesis.
page.evaluate("""
({ button1, button2 }) => button1.textContent + button2.textContent""",
{ 'button1': button1, 'button2': button2 })
# Array works as well. Arbitrary names can be used for destructuring.
# Note the required parenthesis.
page.evaluate("""
([b1, b2]) => b1.textContent + b2.textContent""",
[button1, button2])
# Any non-cyclic mix of serializables and handles works.
page.evaluate("""
x => x.button1.textContent + x.list[0].textContent + String(x.foo)""",
{ 'button1': button1, 'list': [button2], 'foo': None })
参考文章:
参考链接