【深度学习】(6) EfficientNetV2 代码复现,网络解析,附pytorch完整代码
大家好,今天和各位分享一下如何使用 Pytorch 构建 ShuffleNetV2 卷积神经网络模型。
ShuffleNetV2 的原理和 TensorFlow2 实现方法可以看我下面这篇博文,建议大家看一下
https://blog.csdn.net/dgvv4/article/details/123598847
1. 模型介绍
EfficientNetV2 网络主要采用神经结构搜索技术(Neural Architecture Search, NAS)结合复合模型扩张方法获得了一组最优的复合系数,自动将网络的深度、宽度和输入图像分辨率三个参数进行合理的配置,提升了网络的性能,在 ImageNet ILSVRC2012 的 Top-1 上达到 87.3%的准确率,且 EfficientNetV2 减少了模型的参数量并且进一步提升了模型的训练速度。
EfficientNetV1 存在三个问题:
(1)若训练图片的尺寸很大,训练时间非常长;
(2)即使深度卷积结构的参数相比于普通卷积更少,但是在网络浅层中使用深度卷积训练速度仍然很慢,通常不能充分利用现有的加速器;
(3)在 EfficientNetV1中,各阶段都同等放大宽度和深度,但是每一个阶段的参数数量和训练速度都是不同的,所以使用同等放大的方法不是最优的选择。
所以针对以上的问题,EfficientNetV2 网络不论在训练速度还是所用参数数量都优于之前的网络,并且验证了不同的图像尺寸应该使用不同的正则方法,并且设计了一种渐进学习方法,该方法自动调节不同的图像尺寸使用动态的正则方法,并且不仅提高了模型预测准确率,同时还提升了训练速度。
2. Stochastic Depth dropout
网络结构中的 Droupout 层是随机深度,即有可能只剩捷径分支,随机丢掉整个模块的主干,相当于这个模块消失了,减少了网络的深度。随机深度不是使用随机失活方式,而是将其设置与倒残差层数 相关的线性函数。假设总共有 L 个倒残差块,那么存活概率从 ![]() 线性逐渐递减到第 L 个倒残差网络
线性逐渐递减到第 L 个倒残差网络 ![]() 。公式如(4-30)所示:
。公式如(4-30)所示:
![]()
使用线性失活方式的主要是因为较浅的层会提取低级特征,而后期的深层特征都是和这些低级特征紧密相联的,所以较浅的层应该尽可能提取更多的低级特征、尽量减少丢弃概率,那么最终 产生的线性下图所示。

代码展示:
'''
-------------------------------------------
模块(1)
-------------------------------------------
'''
import torch
from torch import nn
from functools import partial # 传参
from torchstat import stat # 查看网络参数
# -------------------------------------- #
# Stochastic Depth dropout 方法,随机丢弃输出层
# -------------------------------------- #
def drop_path(x, drop_prob: float=0., training: bool=False): # drop_prob代表丢弃概率
# (1)测试时不做 drop path 方法
if drop_prob == 0. or training is False:
return x
# (2)训练时使用
keep_prob = 1 - drop_prob # 网络每个特征层的输出结果的保留概率
shape = (x.shape[0],) + (1,) * (x.ndim-1)
random_tensor = keep_prob + torch.rand(shape, dtype=x.dtype, device=x.device)
random_tensor.floor_()
output = x.div(keep_prob) * random_tensor
return output
class DropPath(nn.Module):
def __init__(self, drop_prob=None):
super(DropPath, self).__init__()
self.drop_prob = drop_prob
def forward(self, x):
out = drop_path(x, self.drop_prob, self.training)
return out3. SE通道注意力机制
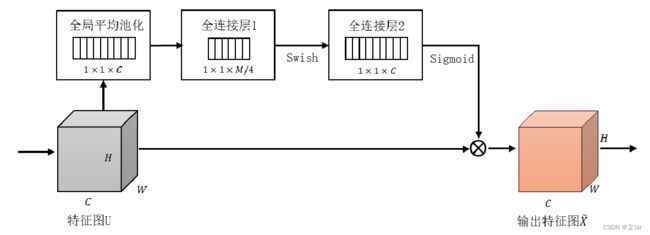
SE注意力机制基于不同的数据集和任务环境,调节捷径分支上每一个通道的权重值,提高或降低不同通道在训练过程中的重要程度。其原理如下图所示。

SE 模块包含压缩和激活两个操作:
(1)首先 SE 模块运用全局平均池化操作压缩通过卷积层卷积得到的特征图的尺寸,使得每个特征图的二维特征浓缩成一个实数,这个实数在某种程度上具备全局感受野,整个模型在保证拥有全局特征的情况下参数数量大幅减少;
(2)然后进入激发操作阶段,采用具有两个全连接层的瓶颈结构,降低网络模型的复杂结构以及提高模型的推广泛化能力。首先运用一个全连接层,将通道进行压缩,减少通道个数以进一步减轻计算量,然后使用 Relu 激活函数激活后,再经过第二个全连接层升维恢复到分支最开始的输入维度,接着使用 Sigmoid 激活函数激活得到最终权重系数;
(3)最终利用分支上输出的权值系数和模型的原始特征值相乘得到总的输出特征。
代码展示:
'''
------------------------------------------
模块(2)
------------------------------------------
'''
# -------------------------------------- #
# SE注意力机制
# -------------------------------------- #
class SequeezeExcite(nn.Module):
def __init__(self,
input_c, # 输入到MBConv模块的特征图的通道数
expand_c, # 输入到SE模块的特征图的通道数
se_ratio=0.25, # 第一个全连接下降的通道数的倍率
):
super(SequeezeExcite, self).__init__()
# 第一个全连接下降的通道数
sequeeze_c = int(input_c * se_ratio)
# 1*1卷积代替全连接下降通道数
self.conv_reduce = nn.Conv2d(expand_c, sequeeze_c, kernel_size=1, stride=1)
self.act1 = nn.SiLU()
# 1*1卷积上升通道数
self.conv_expand = nn.Conv2d(sequeeze_c, expand_c, kernel_size=1, stride=1)
self.act2 = nn.Sigmoid()
# 前向传播
def forward(self, x):
# 全局平均池化[b,c,h,w]==>[b,c,1,1]
scale = x.mean((2,3), keepdim=True)
scale = self.conv_reduce(scale)
scale = self.act1(scale)
scale = self.conv_expand(scale)
scale = self.act2(scale)
# 对输入特征图x的每个通道加权
return scale * x4. MBConv 结构
残差结构先降维再升维,中间的操作过程会造成信息的损失,而倒残差结构先升维后降维,形成了稀疏特征损失比较小 。
MBConv 结构其实是对 MobileNetV2 网络模型中的倒残差结构的微调。具体调整了两个部分:(1)使用的激活函数不同,EfficientNetV2 的 MBConv 将 Relu6 激活函数替换为 Swish 激活函数;(2)在每个 MBConv 中内置了通道注意力机制,在深度卷积层之后增加了 SE 结构,计算通道权重。MBConv 结构如下图所示。

MBConv 结构主要由一个包含了 BN 和 SiLU 激活函数的核为1 × 1、步距为 1的普通卷积,起到一个升维作用;再接入一个包含 BN 和 SiLU 激活函数的核为 × 、步距为 1 或者 2 的深度卷积,大大减少运算量和参数数量, 的值主要分 3或 5 两种;再接入一个 SE 模块,分配通道权重;再接入一个包含了 BN 的1 × 1的普通卷积,起到一个降低维度的作用;最后接入一个 Droupout 层组成。
代码展示:
'''
--------------------------------------------
模块(3)
--------------------------------------------
'''
# -------------------------------------- #
# 卷积 + BN + 激活
# -------------------------------------- #
class ConvBnAct(nn.Module):
def __init__(self,
in_planes, # 输入特征图通道数
out_planes, # 输出特征图通道数
kernel_size=3, # 卷积核大小
stride=1, # 滑动窗口步长
groups=1, # 卷积时通道数分组的个数
norm_layer=None, # 标准化方法
activation_layer=None, # 激活函数
):
super(ConvBnAct, self).__init__()
# 计算不同卷积核需要的0填充个数
padding = (kernel_size - 1) // 2
# 若不指定标准化和激活函数,就用默认的
if norm_layer is None:
norm_layer = nn.BatchNorm2d
if activation_layer is None:
activation_layer = nn.SiLU
# 卷积
self.conv = nn.Conv2d(in_channels=in_planes,
out_channels=out_planes,
kernel_size=kernel_size,
stride=stride,
padding=padding,
groups=groups,
bias=False,
)
# BN
self.bn = norm_layer(out_planes)
# silu
self.act = activation_layer(inplace=True)
# 前向传播
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
x = self.act(x)
return x
# -------------------------------------- #
# MBConv卷积块
# -------------------------------------- #
class MBConv(nn.Module):
def __init__(self,
input_c,
output_c,
kernel_size, # DW卷积的卷积核size
expand_ratio, # 第一个1*1卷积上升通道数的倍率
stride, # DW卷积的步长
se_ratio, # SE模块的第一个全连接层下降通道数的倍率
drop_rate, # 随机丢弃输出层的概率
norm_layer,
):
super(MBConv, self).__init__()
# 下采样模块不存在残差边;基本模块stride=1时且输入==输出特征图通道数,才用到残差边
self.has_shortcut = (stride==1 and input_c==output_c)
# 激活函数
activation_layer = nn.SiLU
# 第一个1*1卷积上升的输出通道数
expanded_c = input_c * expand_ratio
# 1*1升维卷积
self.expand_conv = ConvBnAct(in_planes=input_c, # 输入通道数
out_planes=expanded_c, # 上升的通道数
kernel_size=1,
stride=1,
groups=1,
norm_layer=norm_layer,
activation_layer=activation_layer,
)
# DW卷积
self.dwconv = ConvBnAct(in_planes=expanded_c,
out_planes=expanded_c, # DW卷积输入和输出通道数相同
kernel_size=kernel_size,
stride=stride,
groups=expanded_c, # 对特征图的每个通道做卷积
norm_layer=norm_layer,
activation_layer=activation_layer,
)
# SE注意力
# 如果se_ratio>0就使用SE模块,否则线性连接、
if se_ratio > 0:
self.se = SequeezeExcite(input_c=input_c, # MBConv模块的输入通道数
expand_c=expanded_c, # SE模块的输出通道数
se_ratio=se_ratio, # 第一个全连接的通道数下降倍率
)
else:
self.se = nn.Identity()
# 1*1逐点卷积降维
self.project_conv = ConvBnAct(in_planes=expanded_c,
out_planes=output_c,
kernel_size=1,
stride=1,
groups=1,
norm_layer=norm_layer,
activation_layer=nn.Identity, # 不使用激活函数,恒等映射
)
# droppath方法
self.drop_rate = drop_rate
# 只在基本模块使用droppath丢弃输出层
if self.has_shortcut and drop_rate>0:
self.dropout = DropPath(drop_prob=drop_rate)
# 前向传播
def forward(self, x):
out = self.expand_conv(x) # 升维
out = self.dwconv(out) # DW
out = self.se(out) # 通道注意力
out = self.project_conv(out) # 降维
# 残差边
if self.has_shortcut:
if self.drop_rate > 0:
out = self.dropout(out) # drop_path方法
out += x # 输入和输出短接
return out5. Fused-MBConv 模块
Tan 等人在 EfficientNet 中发现 DW 深度卷积虽然在理论上能减少模型的训练参数,但是在浅层网络中实际使用速度很慢,并没有达到理想状态,无法完全利用现有的加速器,所以在 EfficientNetV2 网络中引用了 Fused-MBConv 结构。
Fused-MBConv 结构是在 MBConv 结构的基础上进行了修改,将一个包含了 BN 和 SiLU激活函数的核为1 × 1的普通卷积,和一个包含 BN 和 SiLU 激活函数的核为 × 的深度卷积变为了一个3 × 3的普通卷积,并且舍弃了 SE 结构。
Fused-MBConv 模块有两种形式,当膨胀比为 1 时,不使用有升维作用的卷积,只运用在网络的第一阶段,如图 1 所示;

当膨胀比不为 1 时,使用核为3 × 3的卷积进行升维作用,运用在第二、三阶段,如图 2 所示。

代码展示:
'''
----------------------------------------
模块(4)
----------------------------------------
'''
# -------------------------------------- #
# FusedMBConv卷积块
# -------------------------------------- #
class FusedMBConv(nn.Module):
def __init__(self,
input_c,
output_c,
kernel_size, # DW卷积核的size
expand_ratio, # 第一个1*1卷积上升的通道数
stride, # DW卷积的步长
se_ratio, # SE模块第一个全连接下降通道数的倍率
drop_rate, # drop—path丢弃输出层的概率
norm_layer,
):
super(FusedMBConv, self).__init__()
# 残差边只用于基本模块
self.has_shortcut = (stride==1 and input_c==output_c)
# 随机丢弃输出层的概率
self.drop_rate = drop_rate
# 第一个卷积是否上升通道数
self.has_expansion = (expand_ratio != 1)
# 激活函数
activation_layer = nn.SiLU
# 卷积上升的通道数
expanded_c = input_c * expand_ratio
# 只有expand_ratio>1时才使用升维卷积
if self.has_expansion:
self.expand_conv = ConvBnAct(in_planes=input_c,
out_planes=expanded_c, # 升维的输出通道数
kernel_size=kernel_size,
stride=stride,
norm_layer=norm_layer,
activation_layer=activation_layer,
)
# 1*1降维卷积
self.project_conv = ConvBnAct(in_planes=expanded_c,
out_planes=output_c,
kernel_size=1,
stride=1,
norm_layer=norm_layer,
activation_layer=nn.Identity,
)
# 如果expand_ratio=1,即第一个卷积不上升通道
else:
self.project_conv = ConvBnAct(in_planes=input_c,
out_planes=output_c,
kernel_size=kernel_size,
stride=stride,
norm_layer=norm_layer,
activation_layer=activation_layer,
)
# 只有在基本模块中才使用shortcut,只有存在shortcut时才能用drop_path
self.drop_rate = drop_rate
if self.has_shortcut and drop_rate>0:
self.dropout = DropPath(drop_rate)
# 前向传播
def forward(self, x):
# 第一个卷积块上升通道数倍率>1
if self.has_expansion:
out = self.expand_conv(x)
out = self.project_conv(out)
# 不上升通道数
else:
out = self.project_conv(x)
# 基本模块中使用残差边
if self.has_shortcut:
if self.drop_rate > 0:
out = self.dropout(out)
out += x
return out6. 构造主干网络
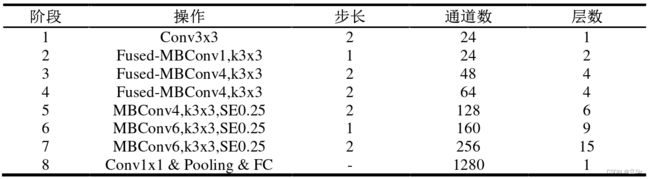
从下表看出 EfficientNetV2-S 网络总共分成了 8 个阶段,
(1)第 1 个阶段就是一个包含 BN 层和激活函数 Swish 的卷积核大小为3 × 3步距为 2 的普通卷积层;
(2)阶段 2~阶段 4 都是在反复叠加 Fused-MBConv 结构,表中的层数表示该阶段 Fused-MBConv 结构反复次数;
(3)阶段 5~阶段 7 都是在反复叠加 MBConv 结构,表中的层数表示该阶段 MBConv 结构反复次数,Fused-MBConv 和 MBConv 模块是网络特征提取的主要手段,通过这两个模块使得网络参数和计算量大大降低,并且MBConv 模块使用了 SE 模块增强了关键信息的提取能力;
(4)最后一个阶段由1 × 1的普通卷积层、池化层和全连接层构成。
代码展示:
'''
----------------------------------------
模块(5)
----------------------------------------
'''
# -------------------------------------- #
# 主干网络
# -------------------------------------- #
class EfficientNetV2(nn.Module):
def __init__(self,
model_cnf:list, # 配置文件
num_classes=1000, # 分类数
num_features=1280, # 输出层的输入通道数
drop_path_rate=0.2, # 用于卷积块中的drop_path层
drop_rate=0.2): # 输出层的dropout层
super(EfficientNetV2, self).__init__()
# 为BN层传递默认参数
norm_layer = partial(nn.BatchNorm2d, eps=1e-3, momentum=0.1)
# 第一个卷积层的输出通道数
stem_filter_num = model_cnf[0][4] # 24
# 第一个卷积层[b,3,h,w]==>[b,24,h//2,w//2]
self.stem = ConvBnAct(in_planes=3,
out_planes=stem_filter_num,
kernel_size=3,
stride=2,
norm_layer=norm_layer,
)
# 统计一共堆叠了多少个卷积块
total_blocks = sum([i[0] for i in model_cnf])
block_id = 0
blocks = [] # 保存所有的卷积块
# 遍历每个stage的参数
for cnf in model_cnf:
# 当前stage重复次数
repeats = cnf[0]
# 使用何种卷积块,0标记则用FusedMBConv
op = FusedMBConv if cnf[-2]==0 else MBConv
# 堆叠每个stage
for i in range(repeats):
blocks.append(op(
input_c=cnf[4] if i==0 else cnf[5], # 只有第一个下采样卷积块的输入通道数需要调整,其余都一样
output_c=cnf[5], # 输出通道数保持一致
kernel_size=cnf[1], # 卷积核size
expand_ratio=cnf[3], # 第一个卷积升维倍率
stride=cnf[2] if i==0 else 1, # 第一个卷积块可能是下采样stride=2,剩下的都是基本模块
se_ratio=cnf[-1], # SE模块第一个全连接降维倍率
drop_rate=drop_path_rate * block_id / total_blocks, # drop_path丢弃率满足线性关系
norm_layer=norm_layer,
))
# 没堆叠完一个就计数
block_id += 1
# 以非关键字参数形式返回堆叠后的stage
self.blocks = nn.Sequential(*blocks)
# 输出层的输入通道数 256
head_input_c = model_cnf[-1][-3]
# 输出层
self.head = nn.Sequential(
# 1*1卷积 [b,256,h,w]==>[b,1024,h,w]
ConvBnAct(head_input_c, num_features, kernel_size=1, stride=1, norm_layer=norm_layer),
# 全剧平均池化[b,1024,h,w]==>[b,1024,1,1]
nn.AdaptiveAvgPool2d(1),
nn.Flatten(), # [b,1024]
nn.Dropout(p=drop_rate, inplace=True),
nn.Linear(num_features, num_classes) # [b,1000]
)
# ----------------------------------------- #
# 权重初始化
# ----------------------------------------- #
for m in self.modules():
# 卷积层初始化
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
nn.init.zeros_(m.bias)
# BN层初始化
elif isinstance(m, nn.BatchNorm2d):
nn.init.ones_(m.weight)
nn.init.zeros_(m.bias)
# 全连接层
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.zeros_(m.bias)
# 前向传播
def forward(self, x):
x = self.stem(x)
x = self.blocks(x)
x = self.head(x)
return x7. 查看网络结构
通过 stat 库查看网络的结构以及参数量
'''
-------------------------------------------
模块(6)
-------------------------------------------
'''
# ----------------------------------------- #
# 网络结构参数
# ----------------------------------------- #
def efficientnetv2(num_classes=1000):
# 配置文件
# repeat, kernel, stride, expansion, in_c, out_c, operate, squeeze_rate
model_config = [[2, 3, 1, 1, 24, 24, 0, 0],
[4, 3, 2, 4, 24, 48, 0, 0],
[4, 3, 2, 4, 48, 64, 0, 0],
[6, 3, 2, 4, 64, 128, 1, 0.25],
[9, 3, 1, 6, 128, 160, 1, 0.25],
[15, 3, 2, 6, 160, 256, 1, 0.25],
]
# 构建模型
model = EfficientNetV2(model_cnf=model_config,
num_classes=num_classes)
return model
# ----------------------------------------- #
# 查看网络参数量
# ----------------------------------------- #
if __name__ == '__main__':
model = efficientnetv2()
# 构造输入层shape==[4,3,224,224]
inputs = torch.rand(4,3,224,224)
# 前向传播查看输出结果
outputs = model(inputs)
print(outputs.shape) # [4,1000]
# 查看模型参数,不需要指定batch维度
stat(model, input_size=[3,224,224])
'''
Total params: 21,458,488
Total memory: 144.98MB
Total MAdd: 5.74GMAdd
Total Flops: 2.87GFlops
Total MemR+W: 267.99MB
'''