| 样本点 |
随机试验的每一种可能的结果,记作ω |
| 样本空间 |
全体样本点组成的集合,记作Ω,是必然事件 |
| 空集 |
不包含任何样本点的空集,记作∅,是不可能事件 |
| 随机事件 |
样本空间的子集,记作A,B,C⋯ |
| 基本事件 |
由一个样本点组成的样本空间的子集 |
| 事件的包含 |
一个事件的发生必然导致另一个事件发生,或者一个事件的样本点都属于另一个事件 |
| 相等事件 |
两个事件具有完全相同的样本点 |
| 相交事件 |
代表事件A和事件B同时发生的事件,记作AB或A∩B |
| 互斥事件 |
AB=∅的两个事件,也叫互不相容事件 |
| 互斥概率 |
两两互斥的事件有P(A1∪A2∪⋯∪An)=P(A1)+P(A2)+⋯+P(An) |
| 事件并集 |
代表事件A和事件B至少有一个发生的事件,记作A+B或A∪B |
| 对立事件 |
记作A’,A+A’=Ω,AA’=∅ |
| 完备事件组 |
一组两两互斥,但全部并起来可以组成样本空间的事件 |
| 事件的差 |
包含于A而不包含于B的事件称为A与B的差,记作A-B或AB’ |
| 事件的交换律 |
A+B=B+A,AB=BA |
| 事件的结合律 |
(A+B)+C=A+(B+C),(AB)C=A(BC) |
| 事件的分配律 |
A(B+C)=AB+AC,A+BC=(A+B)(A+C) |
| 事件的对偶律 |
(A+B)’=A’B’,(AB)’=A’+B’,(A-B)’=(AB’)’=A’+B |
| 条件概率 |
事件A发生时事件B发生的概率P(B|A)= P ( A B ) ‾ P ( A ) \begin{matrix}\underline{P(AB)}\\P(A)\end{matrix} P(AB)P(A) |
| 概率性质 |
P∅=0,P(Ω)=1,P(A)∈[0,1],P(A’)=1-P(A),A⊆B⇒P(A)≤P(B) |
| 古典概率 |
P(A)= A 中 样 本 点 的 数 量 ‾ Ω 中 样 本 点 的 总 数 = n ( A ) ‾ n ( Ω ) \begin{matrix}\underline{A中样本点的数量}\\Ω中样本点的总数\end{matrix}=\begin{matrix}\underline{n(A)}\\n(Ω)\end{matrix} A中样本点的数量Ω中样本点的总数=n(A)n(Ω) |
| 几何概率 |
P(A)= A 的 几 何 度 量 ‾ Ω 的 几 何 度 量 = L ( A ) ‾ L ( Ω ) \begin{matrix}\underline{A的几何度量}\\Ω的几何度量\end{matrix}=\begin{matrix}\underline{L(A)}\\L(Ω)\end{matrix} A的几何度量Ω的几何度量=L(A)L(Ω) |
| 概率加法 |
P(A+B)=P(A)+P(B)-P(AB) |
| 概率减法 |
P(A-B)=P(A)-P(AB) |
| 概率乘法 |
P(AB)=P(A)P(B│A)=P(B)P(A│B) |
| 全概率公式 |
P(A)=∑P(Bi)P(A│Bi),B为非零完备事件组 |
| 贝叶斯公式 |
P(Bk│A)= P ( A B k ) ‾ P ( A ) = P ( B k ) P ( A │ B k ) ‾ ∑ P ( B i ) P ( A │ B i ) \begin{matrix}\underline{P(AB_k)}\\P(A)\end{matrix}=\begin{matrix}\underline{P(B_k)P(A│B_k)}\\∑P(B_i)P(A│B_i)\end{matrix} P(ABk)P(A)=P(Bk)P(A│Bk)∑P(Bi)P(A│Bi),B为非零完备事件组 |
| 独立与相关 |
独立⇔P(AB)=P(A)P(B)或f{X,Y}(x,y)=fX(x)fY(y)⇒不相关⇔E(XY)=E(X)E(Y) |
| 独立事件特性 |
多个事件相互独立⇒P(ABC)=P(A)P(B)P(C),它们中的部分事件相互独立 |
| 独立重复试验 |
重复若干次的随机试验,每次实验之间相互独立,且同一事件在每次实验中发生的概率相同,比如掷骰子 |
| 伯努利试验 |
每次实验只有A,A’两种结果的独立重复试验,比如抛硬币 |
| n重伯努利试验 |
重复n次的伯努利实验 |
| 排列与组合 |
A n m = n ! ( n − m ) ! ‾ , C n m = n ! m ! ( n − m ) ! ‾ A_n^m=\begin{matrix}n!\\\overline{(n-m)!}\end{matrix},C_n^m=\begin{matrix}n!\\\overline{m!(n-m)!}\end{matrix} Anm=n!(n−m)!,Cnm=n!m!(n−m)! |
| 分布函数 |
FX(x) = P(X ≤ x)= ∫ − ∞ x ∫_{-∞}^x ∫−∞xfX(x)dx;FX(-∞)=0,FX(+∞)=1;在间断点处 FX(x)=FX(x+) |
| 因变量分布函数 |
Y=g(X)⇒ FY(y)=P(Y ≤ y)=P(g(X) ≤ y) |
| 概率密度 |
fX(x)=F’X(x),P(a ∫ a b ∫_a^b ∫abfX(x)dx, ∫ − ∞ + ∞ ∫_{-∞}^{+∞} ∫−∞+∞fX(x)dx=1 |
| 离散型变量分布 |
P(X=xi)=pi或 X │ x 1 x 2 ⋯ x n P │ p 1 p 2 ⋯ p n \frac{\begin{matrix}X│x_1&x_2&⋯&x_n\end{matrix}}{\begin{matrix}P│p_1&p_2&⋯&p_n\end{matrix}} P│p1p2⋯pnX│x1x2⋯xn,∑pi=1 |
| 0-1分布 |
若P(X=0)=1-p,P(X=1)=p,0
|
| 二项概率 |
若每次试验中P(A)=p∈(0,1),则n重伯努利实验中A发生k次的概率=Cnkpk(1-p)n-k |
| 二项分布B |
若P(X=k)=Cnkpk(1-p)n-k,k∈N,p∈(0,1),则X~B(n,p),E(X)=np,D(X)=np(1-p) |
| 二项分布可加性 |
X~B(m,p),Y~B(n,p)⇒X+Y~B(m+n,p) |
| 几何分布 |
若P(X=k)=p(1-p)k-1,k∈N+,p∈(0,1),则X服从参数为p的几何分布,E(X)= 1 p \frac1p p1,D(X)= 1 p 2 − 1 p \frac1{p^2}-\frac1p p21−p1 |
| 超几何分布 |
若P(X=k)= C M k C N − M n − k C N n \frac{\begin{matrix}C_M^kC_{N-M}^{n-k}\end{matrix}}{\begin{matrix}C_N^n\end{matrix}} CNnCMkCN−Mn−k,k∈[max(0,n+M-N),min(n,M)],则X~H(n,M,N) |
| 超几何分布的意义 |
N件产品中有M件次品,从中抽取n件,样本中含k个次品 |
| 泊松分布P |
若P(X=k)= λ k e − λ k ! \frac{λ^ke^{-λ}}{k!} k!λke−λ,λ>0,k∈N,则X~P(λ),E(X)=D(X)=λ |
| 泊松分布可加性 |
X~P(λ1),Y~P(λ2)⇒X+Y~P(λ1+λ2) |
| 均匀分布U |
若f(x)= { 1 b − a ‾ , a < x < b 0 , 其 它 \left\{\begin{matrix}\begin{matrix}1\\\overline{b-a}\end{matrix},a⎩⎨⎧1b−a,a<x<b0,其它,则X~U(a,b),E(X)= a + b ‾ 2 \begin{matrix}\underline{a+b}\\2\end{matrix} a+b2,D(X)= ( a − b ) 2 ‾ 12 \begin{matrix}\underline{(a-b)^2}\\12\end{matrix} (a−b)212 |
| 指数分布E |
若f(x)= { λ e − λ x , x > 0 0 , 其 它 \left\{\begin{matrix}λe^{-λx},x>0\\0,其它\end{matrix}\right. {λe−λx,x>00,其它,λ>0,则X~E(λ),E(X)=λ-1,D(X)=λ-2 |
| 正态分布N |
若f(x)= 1 2 π σ ‾ e − ( x − μ ) 2 2 σ 2 \begin{matrix}1\\\overline{\sqrt{2π}σ}\end{matrix}e^{-\frac{(x-μ)^2}{2σ^2}} 12π σe−2σ2(x−μ)2,σ>0,则X~N(μ,σ2),E(X)=μ,D(X)=σ2 |
| 标准正态分布 |
X~N(0,1),Φ(x)= 1 2 π ‾ ∫ − ∞ x e − x 2 2 d x \begin{matrix}1\\\overline{\sqrt{2π}}\end{matrix}∫_{-∞}^xe^{-\frac{x^2}2}\mathrm dx 12π ∫−∞xe−2x2dx,Φ’(x)=φ(x)= 1 2 π ‾ e − x 2 2 \begin{matrix}1\\\overline{\sqrt{2π}}\end{matrix}e^{-\frac{x^2}2} 12π e−2x2 |
| 正态分布特性1 |
X~N(μ,σ2) ⇒ aX+b~N(aμ+b,(aσ)2), X − μ σ \frac{X-μ}{σ} σX−μ~N(0,1) |
| 正态分布特性2 |
X~N(μ,σ^2) ⇒ F(X)=Φ( X − μ ‾ σ \begin{matrix}\underline{X-μ}\\σ\end{matrix} X−μσ),P(a b − μ ‾ σ \begin{matrix}\underline{b-μ}\\σ\end{matrix} b−μσ)-Φ( a − μ ‾ σ ) \begin{matrix}\underline{a-μ}\\σ\end{matrix}) a−μσ) |
| 二维随机变量 |
若X,Y是样本空间上的两个随机变量,则(X,Y)为二维随机变量 |
| 二维离散随机变量 |
可能取有限个或可数无穷个值的二维随机变量 |
| 二维离散变量分布 |
P(X=xi,Y=yj)=pij,∑pij=1 |
| 二维连续变量分布 |
F(x,y)=P(X≤x,Y≤y)= ∫ − ∞ x ∫ − ∞ y ∫_{-∞}^x∫_{-∞}^y ∫−∞x∫−∞yf(x,y)dydx |
| 二维分布的性质1 |
F(x,-∞)=F(-∞,y)=0,F(+∞,+∞)=1,在单个维度上单调不减且“右连续” |
| 二维分布的性质2 |
P(aDf(x,y)dydx |
| 边缘分布 |
fX(x)= ∫ − ∞ + ∞ ∫_{-∞}^{+∞} ∫−∞+∞f(x,y)dy,FX(x)= ∫ − ∞ x ∫ − ∞ + ∞ ∫_{-∞}^x∫_{-∞}^{+∞} ∫−∞x∫−∞+∞f(x,y)dydx, ∫ − ∞ + ∞ ∫ − ∞ + ∞ ∫_{-∞}^{+∞}∫_{-∞}^{+∞} ∫−∞+∞∫−∞+∞f(x,y)dydx=1 |
| 条件分布 |
F{X|Y}(x|y)=P(X≤x|Y=y) |
| 条件密度 |
f{X|Y}(x|y)= f ( x , y ) ‾ f Y ( y ) \begin{matrix}\underline{f(x,y)}\\f_Y(y)\end{matrix} f(x,y)fY(y) |
| 二维正态分布 |
(X,Y) ~ N(μ1,μ2,σ12,σ22,ρxy),f= 1 2 π σ 1 σ 2 1 − ρ 2 ‾ exp [ − ( x − μ 1 σ 1 ) 2 − 2 ρ ( x − μ 1 σ 1 ) ( y − μ 2 σ 2 ) + ( y − μ 2 σ 2 ) 2 ‾ 2 ( 1 − ρ 2 ) ] \begin{matrix}1\\\overline{2πσ_1σ_2\sqrt{1-ρ^2}}\end{matrix}\exp[-\begin{matrix}\underline{(\frac{x-μ_1}{σ_1})^2-2ρ(\frac{x-μ_1}{σ_1})(\frac{y-μ_2}{σ_2})+(\frac{y-μ_2}{σ_2})^2}\\2(1-ρ^2)\end{matrix}] 12πσ1σ21−ρ2 exp[−(σ1x−μ1)2−2ρ(σ1x−μ1)(σ2y−μ2)+(σ2y−μ2)22(1−ρ2)] |
| 多维正态分布特性1 |
(X1,X2,⋯,Xn)服从多维正态分布⇔Xi服从正态分布,X1,X2,⋯,Xn的线性组合服从正态分布 |
| 多维正态分布特性2 |
(X1,X2,⋯,Xn)服从多维正态分布⇒X1,X2,⋯,Xn相互独立且两两不相关 |
| 二元函数的分布 |
Z=f(X,Y)⇒FZ(z)=P(Z≤z)=P(f(X,Y)≤z) |
| 数学期望/样本均值 |
E(g(X))=∑pig(xi)= ∫ − ∞ + ∞ ∫_{-∞}^{+∞} ∫−∞+∞g(x)fX(x)dx,E(C)=C,E(aX+bY)=aE(X)+bE(Y), X ˉ = 1 n ∑ X i \bar X=\frac 1n∑X_i Xˉ=n1∑Xi |
| 二元数学期望 |
E(Z)=E[g(X,Y)]=∑pijg(xi,yj)= ∫ − ∞ + ∞ ∫ − ∞ + ∞ ∫_{-∞}^{+∞}∫_{-∞}^{+∞} ∫−∞+∞∫−∞+∞f(x,y)g(x,y)dydx |
| 方差/标准差 |
D(X)=σ2(X)=E([X-E(X)]2)=E(X2)-E2(X), S 2 = ∑ ( X i − X ˉ ) 2 ‾ n − 1 S^2=\begin{matrix}\underline{∑(X_i-\bar X)^2}\\n-1\end{matrix} S2=∑(Xi−Xˉ)2n−1,σ或S为标准差 |
| 方差特性 |
D(aX+b)=a2D(X),D(X±Y)=D(X)+D(Y)±2Cov(X,Y) |
| 样本的矩 |
k阶原点矩 = 1 n ∑ X i k =\frac 1n∑X_i^k =n1∑Xik,k阶中心矩 = 1 n ∑ ( X i − X ˉ ) k =\frac 1n∑(X_i-\bar X)^k =n1∑(Xi−Xˉ)k |
| 二级中心矩展开 |
1 n ∑ ( X i − X ˉ ) 2 = X 2 ‾ − X ˉ 2 \frac 1n∑(X_i-\bar X)^2=\overline{X^2}-\bar X^2 n1∑(Xi−Xˉ)2=X2−Xˉ2 |
| 混合矩 |
(k+l)阶混合矩=E(XkYl),(k+l)阶混合中心矩=E([X-E(X)]k[Y-E(Y)]l) |
| 协方差 |
Cov(X,Y)=E([X-E(X)][Y-E(Y)])=E(XY)-E(X)E(Y) |
| 协方差的性质 |
Cov(X,Y)=Cov(Y,X),Cov(aX,bY)=abCov(X,Y),Cov(X1+X2,Y)=Cov(X1,Y)+Cov(X2,Y) |
| 协方差矩阵 |
在协方差矩阵C中,cij=Cov(Xi,Xj) |
| 相关系数 |
ρxy= C o v ( X , Y ) D ( X ) ⋅ D ( Y ) ‾ \begin{matrix}Cov(X,Y)\\\overline{\sqrt{D(X)·D(Y)}}\end{matrix} Cov(X,Y)D(X)⋅D(Y) ∈[-1,1],为1(-1)时线性正(负)相关,为0时不相关 |
| 均值之均值 |
E( X ˉ \bar X Xˉ)=E(X)=μ |
| 均值之方差 |
D( X ˉ \bar X Xˉ)= 1 n \frac 1n n1D(X)= σ 2 ‾ n \begin{matrix}\underline{σ^2}\\n\end{matrix} σ2n |
| 方差之均值 |
E(S2)=D(X)=σ2 |
| 方差之方差1 |
Xi~N(μ,σ2) ⇒ ∑ ( X i − μ ‾ σ ) 2 (\begin{matrix}\underline{X_i-μ}\\σ\end{matrix})^2 (Xi−μσ)2~χ²(n) ⇒ D[ ( X i − μ ‾ σ ) 2 (\begin{matrix}\underline{X_i-μ}\\σ\end{matrix})^2 (Xi−μσ)2]=2n ⇒ D[∑(Xi-μ)2]=2nσ4 |
| 方差之方差2 |
Xi~N(μ,σ2) ⇒ n − 1 ‾ σ 2 \begin{matrix}\underline{n-1}\\σ^2\end{matrix} n−1σ2S2∼χ²(n-1) ⇒ D[ n − 1 ‾ σ 2 \begin{matrix}\underline{n-1}\\σ^2\end{matrix} n−1σ2S2]=2(n-1) ⇒ D(S2)= 2 σ 4 n − 1 ‾ \begin{matrix}2σ^4\\\overline{n-1}\end{matrix} 2σ4n−1 |
| 依概率收敛 |
∃随机变量X1,X2,⋯,Xn,∀ε>0, lim n → ∞ \lim\limits_{n→∞} n→∞limP(|Xn-C|<ε)=1⇒Xi依概率收敛于常数C,记作Xn → P \overset P→ →PC |
| 依概率收敛的特性 |
X n → P a , Y n → P b ⇒ X n ± Y n → P a ± b , X n Y n → P a b , X n ‾ Y n → P a ‾ b , g ( X n ) → P g ( a ) X_n\overset P→a,Y_n\overset P→b⇒X_n±Y_n\overset P→a±b,X_nY_n\overset P→ab,\begin{matrix}\underline{X_n}\\Y_n\end{matrix}\overset P→\begin{matrix}\underline{a}\\b\end{matrix},g(X_n)\overset P→g(a) Xn→Pa,Yn→Pb⇒Xn±Yn→Pa±b,XnYn→Pab,XnYn→Pab,g(Xn)→Pg(a) |
| 大数定律 |
∃随机变量X1,X2,⋯,Xn, X ˉ = 1 n ∑ X i , X ˉ → P E ( X ˉ ) \bar X=\frac 1n∑X_i,\bar X\overset P→E(\bar X) Xˉ=n1∑Xi,Xˉ→PE(Xˉ)⇒随机变量序列{Xn}服从大数定律,棣-拉中的Xn可换成∑Xi |
| 常用大数定律 |
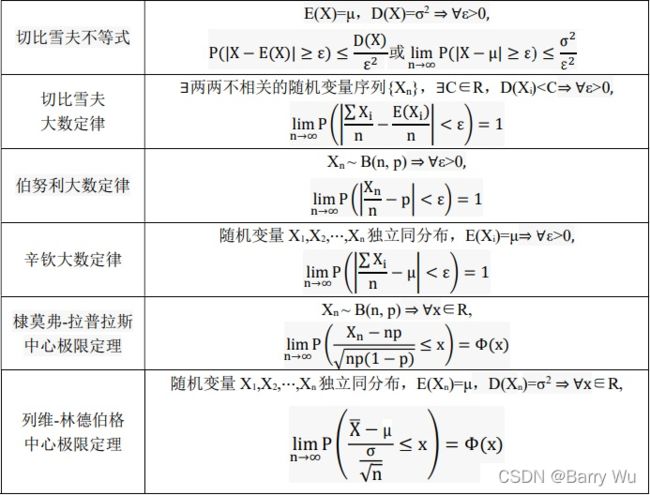 |
