PyTorch----从零实现乳腺癌预测
分类问题
- 使用线性回归解决的都是线性问题,而乳腺癌预测是分类问题。
那么PyTorch是怎么求解一个非线性问题?
乳腺癌预测
- 根据血常规的化验预测,查询出规律。
- 有30多个特征,输出0或1 是否患有乳腺癌。
一、获取数据
import pandas as pd
# 读取乳腺癌的数据
df = pd.read_csv('./breast_cancer.csv')
# 数据中的30个特征
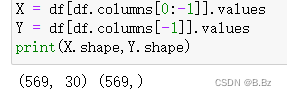
X = df[df.columns[0:-1]].values
# 数据的标签 0为患有乳腺癌,1为没有乳腺癌
Y = df[df.columns[-1]].values
print(X.shape,Y.shape)
通过数据的shape可以看到 569条数据 30个特征 1个标签
二、数据集的划分和标准化
划分:
- 为了能评估模型的好坏,需要按比例把数据分为训练集和测试集
- 训练集的数据用来训练模型,测试集的数据用来测试训练完的模型精度是否符合标准
使用sklearn.model_selection的train_test_split模块分割数据集:
- test_size 测试集比重
- random_state 随机种子,保证每次随机的都一样
from sklearn.model_selection import train_test_split
X_train,X_test,Y_train,Y_test = train_test_split(X,Y,test_size=0.2,random_state=3456)
标准化:
- 标准化可以加快模型的收敛速度
- 把所有的数据按照比例缩放到一定范围之内
使用sklearn.preprocessing的StandardScaler模块对数据集进行标准化处理:
- 创建StandardScaler()对象
- 对象的fit_transform()方法 参数为数据
因为Y标签数据本来就是0或1所以不用标准化来加快模型的收敛速度
from sklearn.preprocessing import StandardScaler
# 创建StandardScaler对象
sc = StandardScaler()
# 使用fit_transform()方法进行标准化
X_train = sc.fit_transform(X_train)
X_test = sc.fit_transform(X_test)
把numpy数组转为PyTorch中的张量Tensor:
import torch
import numpy as np
# 把numpy数组转为PyTorch内的张量Tensor
X_train = torch.from_numpy(X_train.astype(np.float32))
X_test = torch.from_numpy(X_test.astype(np.float32))
Y_train = torch.from_numpy(Y_train.astype(np.float32))
Y_test = torch.from_numpy(Y_test.astype(np.float32))
# 把标签转为2维
Y_train = Y_train.view(Y_train.shape[0],1)
Y_test = Y_test.view(Y_test.shape[0],1)
三、模型定义
- 线性函数是一条没有上界和下界的直线, 即线性函数预测出来的值可以很大, 也可以非常小. 而实验数据的标签只有0(患病)或1(不患病), 因此用线性函数来拟合乳腺癌的数据是不合理的。
- 找到输出始终为0-1之间的函数模型如果拥有这样的函数模型,那么将任意的x放入该模型中,都会输出0-1之间的值.这个值我们可以看做说患有乳腺癌的概率.如果这个概率值小于0.5则表示没有患乳腺癌.如果这个概率值大于0.5则表示患有乳腺癌.
- 这个始终输出0-1之间的函数模型就是激活函数
Sigmoid函数公式:
ρ = 1 1 + e − z \rho = \frac{1}{1+ e^{-z}} ρ=1+e−z1

- 线性问题的时候使用的MSE损失函数 当前是二分类问题
- 使用
BCE(Binary Cross Entropy)损失函数
class Model(torch.nn.Module):
"""自定义模型 继承于torch.nn.Module"""
def __init__(self,input_features,out_features):
"""
重写__init__方法
@param input_features: 输入维度
@param out_features: 输出维度
"""
# 执行父类方法
super(Model,self).__init__()
# 创建线性模型 把外部传进来的参数传进去 特征和输出
self.linear = torch.nn.Linear(input_features,out_features)
def forward(self,x):
"""重写正向传播的函数"""
# 执行一遍线性函数
out = self.linear(x)
# 丢入激活函数获取到预测值
y_pred = torch.sigmoid(out)
return y_pred
# 样本数 和 输入特征数 (30个)
n_samples,n_features = X_train.shape
# 创建模型对象 特征和输出丢进去
model = Model(n_features,Y_train.shape[1])
# 创建损失函数
loss = torch.nn.BCELoss()
# 定义训练次数和学习率
num_epochs = 100
learning_rate = 0.1
# 定义优化器
optimizer = torch.optim.SGD(model.parameters(),lr=learning_rate)
四、模型训练
- 正向传播获取到预测值
- 真实值和预测值扔进损失函数获取到损失值
- 进行反向传播
- 优化器修改参数权重
- 清空计算的梯度
# 循环训练
for epoch in range(num_epochs):
# 正向传播获取到预测值
y_pred = model(X_train)
# 真实值和预测值扔进损失函数获取到损失值
l = loss(y_pred,Y_train)
# 进行反向传播
l.backward()
# 优化器修改参数权重
optimizer.step()
# 清空计算的梯度
optimizer.zero_grad()
# 打印信息
if epoch % 10000 == 0:
print(f'epoch={epoch},loss={l.item():.4f}')
五、模型预测
# 在测试集内随机抽取一条数据
index = np.random.randint(0,len(X_test))
# 扔进训练完的模型正向传播
test_pred = model(X_test[index])
# 把结果四舍五入 因为超过0.5为没有患乳腺癌 低于0.5为患有乳腺癌
test_pred_label = test_pred.round()
# 把结果转为numpy查看
real = Y_test[index].detach().numpy()[0]
pred = test_pred_label.detach().numpy()[0]
print(f'测试集内第{index}条数据,真实值:{real},预测值:{pred}')
![]()
六、计算模型精准度
# 作用域内不计算梯度
with torch.no_grad():
# 正向传播 获取预测值
y_pred = model(X_test)
# 上面计算出来的结果是0-1之间的数, 我们将数据进行四舍五入,得到与原表相同的情况
y_pred_label = y_pred.round()
# 统计结果
acc = y_pred_label.eq(Y_test).sum().numpy()/float(Y_test.shape[0])
print(f"准确率:{acc.item()* 100 }%")
![]()