Python处理Excel比Vba快100倍,媳妇连连夸赞今晚不用再跪搓衣板----python实战
最近经历了一次把vb脚本改造成python脚本,并获得性能提升数倍的过程,当然,这个过程也不是一帆风顺,中间也经历了一些波折,但是,也收获了一波新的认知。正好最近有时间,姑且写下来记录一下。
什么是VB
话说现在的年轻人,听说过这个编程语言的应该不多了。VB是一种由微软公司开发的包含协助开发环境的事件驱动编程语言。从任何标准来说,VB都是世界上使用人数最多的语言,它源自于BASIC编程语言,也属于高级语言的一种了。只是现在各大应用场景以及被Java、Go、Python等编程语言瓜分一空,VB基本很少人知道了。
什么是VBA
而VBA和VB又有点差别,Visual Basic for Applications(VBA)是Visual Basic的一种宏语言,是微软开发出来在其桌面应用程序中执行通用的自动化(OLE)任务的编程语言。主要能用来扩展Windows的应用程式功能,特别是Microsoft Office软件,比如excel、powerpoint、word等。
故事的开端
而本次故事的场景,就是在excel中编写vba宏脚本,而这个场景的需求,则来源于笔者的媳妇。笔者的媳妇平时的工作大部分时间都是跟excel打交道,也就是很多人口中的“表姐”,因此excel的各种高级操作比如vlookup、数据透视等,也算是应用的炉火纯青了。
可偏偏事不如人愿,企业中的业务总是会越来越复杂,老板的要求也会越来越高,渐渐地,有一些需求我媳妇用她炉火纯青的技巧也搞不动了。于是她把希望寄托在了我这个廉价劳动力身上,毕竟传说中的搞IT的,可是什么都能干的。
于是大概从几年前,我开始陆陆续续用vba写宏,帮助媳妇处理类似复杂的数据计算问题,说到这里,我翻了翻我的朋友圈,竟然有据可查:2017年就开始了!有图为证:
也就是从那个时候开始,媳妇搞不定的复杂数据处理问题,就扔给我用vba来搞。要知道,对于一个写惯Java语言的人来说,对vba这种语言真的是一百种不习惯,尤其是那个土得掉渣的开发环境,话不多说,上图:
有没有一种年代复古风的感觉!这还是最新版本的,老版本的连调试功能都没有,任何问题都得默念加各种打日志排查,更不用说高级点IDE都具备的自动补全、提示、重构等功能了,所以,用这个玩意写代码的效率那真是一言难尽。
就这样被媳妇的需求折磨了几年,好在这几年的需求也没复杂到哪里去,一路也就忍过来了。可最近一次媳妇扔过来的需求,可着实把我可累了一把。
详细的需求就不说了,大概就是对一个excel的两个sheet进行计算,其中一个sheet将近1万行,两外一个sheet数据量倒不多300多行,但是格式比较复杂,各种合并和拆分单元格(见下图),而要计算的需求复杂度相比之前也上升了一个台阶。

拿到需求后,我还是按照惯例用vba来写,大概耗费了一个周末的时间搞定了,虽然交了差。但是面对未来可能越来越复杂的需求,我的心里打了鼓,vba的开发效率和复杂数据处理需求的矛盾越来越突出,而且这次写的脚本,性能上也问题很大,整个处理过程耗时10分钟之巨,如下图所示:

作为一个自认优秀且有良心的搞IT的,怎么能够忍受这种开发效率和运行效率,二话不说,我要优化它!
怎么优化呢?话说在大数据处理领域,Python可算是TIOBE排行榜上,数一数二的利器了,尤其是在AI大热的背景下,Python在TIOBE排行榜上的地位是逐渐蹿升,除了大数据领域,Python在web开发、Excel办公、科学计算和数据可视化等方面也表现优秀。好了,就用Python搞!
Python优化过程
大概的优化思路是这样的:用Python的xlwings库来处理excel数据的读写,但数据的计算就不用它直接搞了,效率会比较低,而是用Pandas库在内存中进行数据的复杂计算,然后将计算后的结果写回excel
思路其实很简单,但实操的过程却不是完全一帆风顺,接下来就是整个优化的过程
第一版优化
因为用Pandas把数据读到内存后,是一个DataFrame,我们可以很容易的拿到这个DataFrame的行数和列数,类似一个数组一样可以方便的遍历,因此第一版的实现,使用的是标准的遍历的方法来实现,核心代码如下:
读取excel
import pandas as pd
import xlwings as xw
#要处理的文件路径
fpath = "datas/joyce/DS_format_bak.xlsm"
#把CP和DS两个sheet的数据分别读入pandas的dataframe
cp_df = pd.read_excel(fpath,sheet_name="CP",header=[0])
ds_df = pd.read_excel(fpath,sheet_name="DS",header=[0,1])
......
标准遍历方法
for j in range(len(cp_df)):
cp_measure = cp_df.loc[j,'Measure']
cp_item_group = cp_df.loc[j,'Item Group']
if cp_measure == "Total Publish Demand":
for i in range(len(ds_df)):
#如果cp和ds的item_group值相同
if cp_item_group == ds_df.loc[i,('Total','Capabity')]:
......
写入excel
#保存结果到excel
app = xw.App(visible=False,add_book=False)
ds_format_workbook = app.books.open(fpath)
ds_format_workbook.sheets["DS"].range("A3").expand().options(index=False).value = ds_df
ds_format_workbook.save()
ds_format_workbook.close()
app.quit()
......
说到这里插一句,大家还记得我前面提到的那个各种拆分和合并单元格的复杂格式吗,这种格式在Pandas里又叫多层索引(MultiIndex),这种结构下数据的查询和操作,比普通的表格要复杂,大概处理代码类似下面:
#用元组的方式来定位某一列
ds_total_capabity1 = ds_df.loc[k,('Total','Capabity.1')]
#
#获取多层索引某一层数据的方法
ds_month = ds_df.columns.get_level_values(0)[k]
ds_datatime = ds_df.columns.get_level_values(1)[k]
......
因为这个话题跟本文章无关,这里就不展开了,有兴趣大家自己去学习了解。
这一版写完后,信心满满地执行脚本,但是立马被现实浇了一盆冷水,执行时间竟然要555秒,也就是9分多钟,并没有比vba快多少,如下图:

为什么会这样!Python不是号称数据处理利器吗。我们仔细看一下打印的日志输出,可以看到主要的瓶颈在循环计算这块,耗时469+42 = 517秒,基本所有时间都用在这里。当然,从日志也可以看到,读写excel的性能也一般,但并不是性能瓶颈。对于性能优化的一般准则是:数据驱动+二八原则,也即通过数据分析发现瓶颈,即占用80%耗时的地方,然后有针对性地优化该瓶颈。
内存中的循环计算为什么这么慢呢?遇事不决问度娘,通过一番搜索,终于让我找到一个官方解释,原来DataFrame(数据帧)是具有行和列的Pandas对象(objects),如果使用循环,则将遍历整个对象,Python无法利用任何内置函数,而且速度非常慢,建议用Pandas内置函数:iterrows(),iterrows()为每行返回一个Series,因此将DataFrame迭代为一对索引,将感兴趣的列作为Series进行迭代,这使其比标准循环更快。
既然官方这么说,那我们还怀疑什么,那就试试呗。
第二版优化
有了解决方案,那就好办了,无非就是把代码里所有用到标准循环的地方,改成用iterrows(),改动的地方代码如下:
#根据CP和DS表的Item_group值做lookup,计算DS表的Delta值
for index_i,cp_row in cp_df.iterrows():
#获取CP表的Item_group和siteid值
cp_item_group = cp_row['Item Group']
siteid = cp_row['SITEID']
key = cp_item_group + "-" + siteid
for index_j,ds_row in ds_df.iterrows():
#获取DS表的Item_group值
ds_item_group = ds_row[('Total','Capabity')]
if ds_item_group != "" and cp_item_group == ds_item_group :
iner_iter_df = ds_df.loc[index_j:index_j+5]
......
改完后执行,果然,效率提升了一些,见下图:
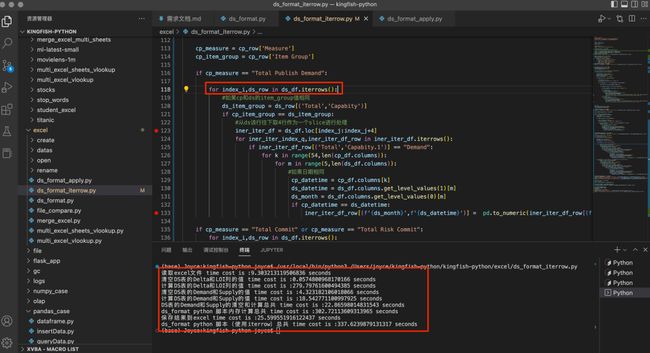
整体耗时337秒,也就是5分多钟,比前一版提升40%,看起来还不错。但是,作为一名优秀的IT人,不能满足于既有的成绩,要不断追求极致。于是,就有了第三版优化。
第三版优化
其实第三版优化的思路,还是追求更快地遍历效率,Pandas除了iterrows()之外,据说还有一个更快的apply()方法,能够对DataFrame的每一行逐行应用自定义函数,且遍历性能更好。于是,第三版的核心代码如下:
def Cal_Delta_Loi_Iter_In_Cp(data):
global cal_delta_loi_cp_row
cal_delta_loi_cp_row = data
#获取CP表的Item_group和siteid值
global cp_item_group
cp_item_group = cal_delta_loi_cp_row['Item Group']
siteid = cal_delta_loi_cp_row['SITEID']
global key
key = cp_item_group + "-" + siteid
ds_df.apply(Cal_Delta_Loi_Iter_In_Ds,axis=1)
#开始计算Delta和LOI值
cp_df.apply(Cal_Delta_Loi_Iter_In_Cp,axis=1)
......
按apply()改完代码再次执行,这次执行效率果然又上了一个台阶,如下图:

整体耗时147秒,也即2分多钟,相比上一版再次提升56%,Very Done!
小小总结一下
优化到这里,我们可以看到,使用Python的Pandas类库,并且使用较高性能的内置函数,能够很大程度提升数据处理的性能。但是,我们从前面打印出的日志也能看到,Python提供的xlwings库,在读写excel方面的性能缺很难说优秀,相比vba来说更是差了一大截。
VBA虽然数据结构少,数据计算速度慢,但访问自己Excel的Sheet,Range,Cell等对象却速度飞快,这就是一体化产品的优势。VBA读取Excel的Range,Cell等操作是通过底层的API直接读取数据的,而不是通过微软统一的外部开发接口。所以Python的各种开源和商用的Excel处理类库如果和VBA来比较读写Excel格子里面的数据,都是处于劣势的(至少是不占优势的)。
因此,Python处理Excel的时候,就要把Excel一次性地读取数据到Python的数据结构中,而不是大量调用Excel里的对象,不要说频繁地写入Excel,就是频繁地读取Excel里面的某些单元格也是效率较低的。