Pytorch 中 Dataset 和 DataLoader,以及 torchvision 的 datasets 完全理解
目录
- 1、torch.utils.data.Dataset()
- 2、torch.utils.data.Sampler()
- 3、torch.utils.data.DataLoader()
- 4、torchvision.datasets.ImageFolder()
- 5、例子 torchvision.datasets.FashionMNIST()
1、torch.utils.data.Dataset()
首先最基础的,是 torch.utils.data.Dataset() (官方文档),它是 Pytorch 中表示数据集的抽象类,可以将其理解为如下:
class Dataset(object):
def __getitem__(self, index):
raise NotImplementedError
def __len__(self):
raise NotImplementedError
__getitem__()方法通过索引返回数据集中选定的样本__len__()方法返回数据集的总大小(实际上没定义在抽象类中,而是在 Sampler 中)
可见抽象类中的两个方法都是还没实现的,所以如果想实际使用 Dataset,就必须继承这个抽象类,创建一个子类,改写这两个方法,例如:
class CustomDataset(torch.utils.data.Dataset):
# Basic Instantiation
def __init__(self, ..., *args, **kwargs):
...
# Fetch an item from the Dataset
def __getitem__(self, index):
...
# Length of the Dataset
def __len__(self):
...
自定义数据集的具体例子可以看看这篇博客。
2、torch.utils.data.Sampler()
有了数据集之后,就需要从中采样数据,这就是 torch.utils.data.Sampler()(官方文档) 的作用,它是所有采样器的基类,可以将其理解如下:
class Sampler(object)
def __init__(self, data_source):
pass
def __iter__(self):
raise NotImplementedError
__iter__()方法用于迭代数据集元素索引
从官方实现的各种 Sampler 的子类源代码中可以看出,__iter__() 方法实际上就是用 Python 中的 iter()、next() 和 yield 等迭代器和生成器的方法(详见这篇博客),基于数据集产生一个迭代器,可以迭代得到数据集上的样本。
3、torch.utils.data.DataLoader()
最后就是 torch.utils.data.DataLoader()(官方文档),它的作用就是:
Combines a dataset and a sampler, and provides an iterable over the given dataset
结合一个 Dataset 和一个 Sampler,然后返回一个该数据集上的可迭代对象。当然它还可以指定 Batch_size,以及支持多进程等等。
4、torchvision.datasets.ImageFolder()
首先介绍下 torchvision 包,它和 torch 一样都归属于 Pytorch 深度学习框架,torchvision 是由常用数据集、模型架构和用于计算机视觉的常见图像转换所组成的。
torchvision.datasets 模块(官方文档)既有官方提供的数据集,也有自定义数据集的类,它们都是 torch.utils.data.Dataset 的子类,因此可以直接输入到 torch.utils.data.DataLoader 中。
官方提供的数据集如:torchvision.datasets.MNIST()、torchvision.datasets.FashionMNIST()、torchvision.datasets.ImageNet() 等等;
自定义的数据集类有三个,最常用的是 torchvision.datasets.ImageFolder(),它继承自 torchvision.datasets.DatasetFolder(),后者又继承自 torchvision.datasets.VisionDataset(),VisionDataset 则是 torch.utils.data.Dataset 的子类。传入 ImageFolder 的 root 路径参数,里面的子文件夹对应类别名,然后类别名文件夹里面就存放有该类别的图片,如下:
root
├── orange
│ ├── orange_image1.png
│ └── orange_image1.png
├── apple
│ └── apple_image1.png
│ └── apple_image2.png
│ └── apple_image3.png
5、例子 torchvision.datasets.FashionMNIST()
首先是导入库:
# imports 导入各种库
import matplotlib.pyplot as plt
import numpy as np
import torch
import torchvision
import torchvision.transforms as transforms
然后就可以直接使用官方提供的数据集了,其中有许多参数,如存放的路径、作为训练集还是测试集、如何数据增强等等:
train_set = torchvision.datasets.FashionMNIST(
root='./data'
,train=True
,download=True
,transform=transforms.Compose([
transforms.ToTensor()
])
)
得到数据集之后,就可以输入到 DataLoader 中,它也有很多参数,如批量大小、是否打乱、使用 CPU 的进程数等等:
train_loader = torch.utils.data.DataLoader(
train_set
,batch_size=4
,shuffle=True
)
此时,train_loader 就是一个可迭代对象,我们既可以先用 iter() 将其变成迭代器再用 next() 逐个批次进行迭代,例如:

next() 返回的一个批次大小为 4,包含图像数据和标签数据,对图像进行可视化如下:
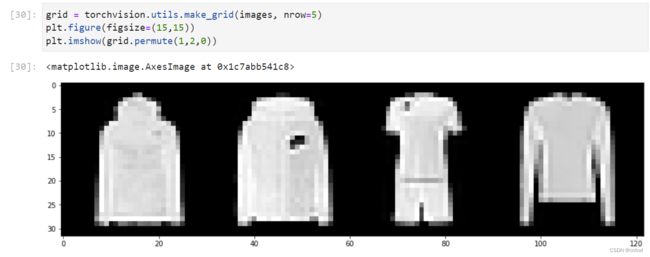
也可以直接 for 循环进行迭代,如:
for batch_idx, samples in enumerate(train_loader):
print(batch_idx, samples)
更具体的例子可以看看这篇博客。