图表示学习
文章目录
-
- 1.导言
-
- 1.1 为什么要研究图(graph)
- 1.2 针对图结构的机器学习任务
- 1.3 特征表示的难点
- 1.4 特征表示的解决思路
- 1.5 线性化思路
- 1.6 图神经网络
- 1.7 讨论:何谓Embedding
- 1.8 总结
- 2.图结构表示学习
-
- 2.1 deepwalk(深度游走算法)
- 2.2 node2vec
- 3. 图特征表示学习
-
-
- 3.1 GCN 图卷积网络
-
1.导言
1.1 为什么要研究图(graph)
很多数据都是图结构,例如社交网络、经济网络、生物医学网络、信息网络(互联网网站、学术引用)、互联网、神经网络。而网络是它们的通用语言,因此具备极大的研究价值。
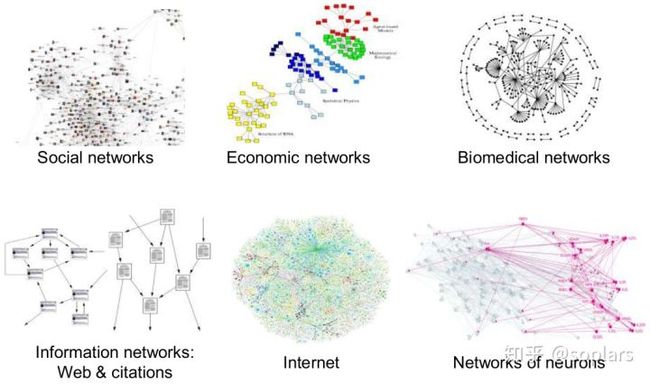
图1.图结构的举例 (source)
1.2 针对图结构的机器学习任务
一旦我们拥有了图结构的数据,就可以做一下潜在的机器学习任务,例如:
- 节点分类 ——预测一个给定节点的类型
- 链接预测 ——预测两个节点是否连接
- 社群检测 ——识别密集连接的节点群
- 网络相似度 ——两个子网络有多相似
等等。
然而,正如我们所熟知的,机器学习任务的基本流程如下所示:
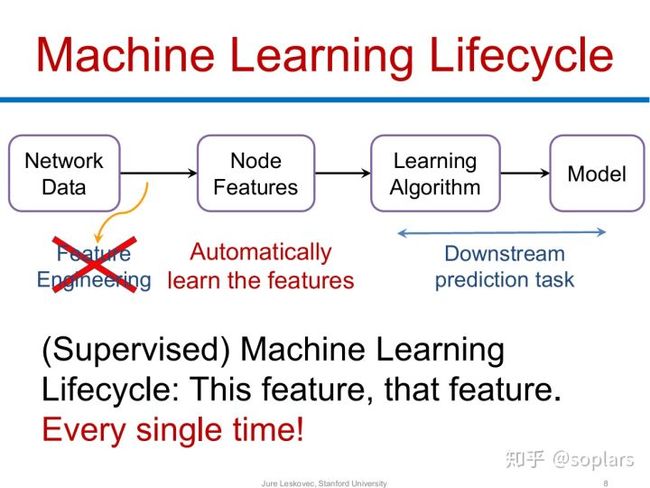
图2.机器学习任务的基本流程 (source)
可见,第一步的特征工程即需要把每条样本表示为向量,即特征向量。不论输入是非数值类型(图片、语音、文字、逻辑表示等),或者本身就是数值类型,我们都需要将输入数字化为特征向量。
而且,因为特征工程决定着算法上限。所以我们不仅要转为特征向量,而且希望转成的特征向量也足够好。因此,基于自动编码器(Auto-encoder)和词嵌入(Word-Embedding)的启发,我们期望转换后的特征向量(或者叫Embedding),能够自带节点信息(例如在特征空间上,相似的节点会离得特别近),这将非常有利于机器学习的任务。
那么,如何把网络中的节点转化为特征向量?
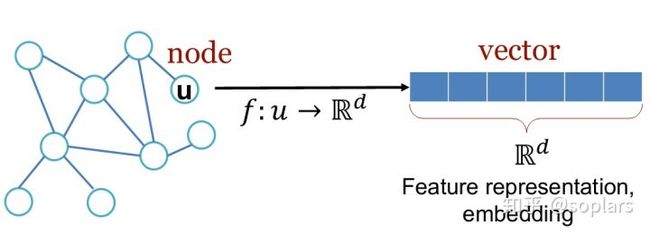
图3.节点需要映射为特征向量 (source)
1.3 特征表示的难点
不幸的是,这非常难。
我们可以考察一下常见的非数值类型的输入,是如何转换的。
- 图片(images)
有固定的2维结构,可以定义CNN。

图4.图片(image)拥有固定的2维结构 (source)
- 文本(text)、语音(speech)
都有固定的线性1维结构,可以定义滑动窗口。

图5.文本、语音拥有固定的1维结构 (source)
然而,图(graph)是非欧几里得结构。表现在:
- 图的结构可以任意变化
一个图可以具备各种形状,尽管它们的节点位置不一样,但是连接关系没变,所以图完全一样。
- 节点也可以以任意顺序标记
同样一个5个节点的图,节点可以标记为1、2、3、4、5,也可以标记为4、2、1、3、5,节点编号变了,尽管图完全没变。
1.4 特征表示的解决思路
怎么办?
他山之石,可以攻玉,基于上面我们对一维序列结构和二维图(image)结构的处理方法的总结,至少可以启发出以下两类套路:
1.5 线性化思路
通过图(graph)结构里的遍历,生成节点的序列,来创造“句子”语料,然后再使用Word2Vec的思想。如 Node2Vec。
常见的线性化方法如下所示。

图6.线性化常见做法 (source)
1.6 图神经网络
用周围节点来编码中心节点,相当于通过训练一个虚拟网络(Network),把每个节点周围的结构信息储存在了这个虚拟网络(Network)里,而输入周围节点后这个网络输出的向量,正是这个中心节点的embedding。
常见的图神经网络如下所示,后面章节将详细讨论,拨开它的神秘面纱。

图7.图神经网络常见做法 (source)
1.7 讨论:何谓Embedding
2013年Word2Vec(尽管Word2Vec的idea诞生多年,但直到2013年才因为训练技巧的加持而得以解除封印)显著效果兴起了一股风潮:即根据环境上下文的固有结构,用每个元素与上下文的元素之间构造“feature-target”这样的训练数据,自动化地训练浅层神经网络(一般只有一个隐层,一个输出层)。
狭义
某个元素狭义的Embedding即该元素传播到隐藏层计算出的向量。基于一个训练好的浅层网络,每个元素都可以由自己的one-hot表示传播到隐层后,抽出隐层向量作为自己的Embedding。
正是因为这个特征向量是**“嵌入”在网络中间的隐层**,所以叫嵌入(即Embedding)。
由于相似的元素的Embedding也相似,所以是非常理想的特征表示法。(作为对比,元素也可one-hot,但one-hot向量除了表征元素间的差异,完全没有其他信息,极大限制了机器学习模型的发挥)
广义
一个样本的特征向量,不管它是否来自一个训练的网络,或是来自其他方法的构造,我们都可称之为Embedding。因为我们的最终目标是迭代出最优的特征向量,蕴含相似度信息,所以我们把这种特征向量也称之为Embedding。这是本文所使用的Embedding意义。
1.8 总结
- 用图结构数据进行机器学习具有巨大价值,然而抽取特征却是图结构数据的难点。
- 受图像(image)、文本(text)的特征抽取的启发,产生两大类思路。
2.图结构表示学习
表示学习的主要目标,正是将图数据转化成低维稠密的向量化表示方式,同时确保图数据的性质在向量空间中也能够得到对应。图数据的表示,可以是节点层面,或是全图层面,节点(图数据的基本元素)的表示学习一直是图表示学习的主要对象。图数据的表示如果能含有丰富的语义信息,就能得到好的输入特征,直接选用线性分类器对分类任务学习。
图表示学习的主要目标:将结点映射为向量表示,尽可能多地保留图的拓扑信息。
基于图结构的表示学习对结点的向量表示只来源于图的拓扑结构,缺乏对图结点特征消息的表示。
如下图;根据用户的行为构建图网络;通过 Random walk 随机采样的方式构建出结点序列(如:开始在 A 点,A->B,B 又跳到邻居点 E,最后到 F,得到"A->B->E->F"序列);序列问题就是 NLP 中的语言模型,句子就是单词构成的序列。之后是 Word2vec(词用向量表示)的问题,可采用 Skip-gram 模型得到最终的结点向量;这样就将图结构转化为序列问题。
注:结点走向其邻居结点的概率是均等的。在有向图和无向图中,游走方式不一样。
无向图中的游走方式是相连即可走;而有向图中则是只沿着“出边”的方向走。
2.1 deepwalk(深度游走算法)
随机游走算法(random walk)
英文:random walk
定义:随机游走,概念接近于布朗运动,是布朗运动的理想数学状态。
核心概念:任何无规则行走者所带的守恒量都各自对应着一个扩散运输定律。
随机游走算法的基本思想是:
从一个或一系列顶点开始遍历一张图。在任意一个顶点,遍历者将以概率1-a游走到这个顶点的邻居顶点,以概率a随机跳跃到图中的任何一个顶点,称a为跳转发生概率,每次游走后得出一个概率分布,该概率分布刻画了图中每一个顶点被访问到的概率。用这个概率分布作为下一次游走的输入并反复迭代这一过程。当满足一定前提条件时,这个概率分布会趋于收敛。收敛后,即可以得到一个平稳的概率分布。
随机游走过程
一维的随机游走可定义如下: 每过一个单位时间,游走者从数轴位置x出发以固定概率随机向左或向右移动一个单位.
不妨将n时刻游走者的位置记为Ln,则
有其中X1,X2,…,Xn为相互独立的随机变量,满足
随机游走算法的操作步骤:
word2vec算法
NLP (自然语言处理)。NLP 里面,最细粒度的是词语,词语组成句子,句子再组成段落、篇章、文档。所以处理 NLP 的问题,首先就要拿词语开刀。
咱们居住在各个国家的人们通过各自的语言进行交流,但机器无法直接理解人类的语言,所以需要先把人类的语言“计算机化”,那如何变成计算机可以理解的语言呢?
我们可以从另外一个角度上考虑。举个例子,对于计算机,它是如何判断一个词的词性,是动词还是名词的呢?
我们有一系列样本(x,y),对于计算机技术机器学习而言,这里的 x 是词语,y 是它们的词性,我们要构建 f(x)->y 的映射:
-
首先,这个数学模型 f(比如神经网络、SVM)只接受数值型输入;
-
而 NLP 里的词语,是人类语言的抽象总结,是符号形式的(比如中文、英文、拉丁文等等)
-
如此一来,咱们便需要把NLP里的词语转换成数值形式,或者嵌入到一个数学空间里;
-
我们可以把文本分散嵌入到另一个离散空间,称作分布式表示,又称为词嵌入(word embedding)或词向量。
-
一种简单的词向量是one-hot encoder,所谓 one-hot编码,其思想跟特征工程里处理类别变量的 one-hot 一样,本质上是用一个只含一个 1、其他都是 0 的向量来唯一表示词语。
Word2Vec
当然,传统的one-hot 编码仅仅只是将词符号化,不包含任何语义信息。而且词的独热表示(one-hot representation)是高维的,且在高维向量中只有一个维度描述了词的语义。多高?词典有多大就有多少维,一般至少上万的维度。所以我们需要解决两个问题:1 需要赋予词语义信息,2 降低维度。
word2vec是Google研究团队里的Tomas Mikolov等人于2013年的《Distributed Representations ofWords and Phrases and their Compositionality》以及后续的《Efficient Estimation of Word Representations in Vector Space》两篇文章中提出的一种高效训练词向量的模型,基本出发点是上下文相似的两个词,它们的词向量也应该相似,比如香蕉和梨在句子中可能经常出现在相同的上下文中,因此这两个词的表示向量应该就比较相似。
实际上,大部分的有监督机器学习模型,都可以归结为:f(x)->y。
在有些NLP问题中,把 x 看做一个句子里的一个词语,y 是这个词语的上下文词语,那么这里的 f 便是上文中所谓的『语言模型』(language model),这个语言模型的目的就是判断 (x,y) 这个样本是否符合自然语言的法则,更通俗点说就是:有了语言模型之后,我们便可以判断出:词语x和词语y放在一起,是不是人话。
当然,前面也说了,这个语言模型还得到了一个副产品:词向量矩阵。
而对于Word2vec 而言,词向量矩阵的意义就不一样了,因为Word2Vec的最终目的不是为了得到一个语言模型,也不是要把 f 训练得多么完美,而是只关心模型训练完后的副产物:词向量矩阵。
我们来看个例子,如何用 Word2vec 寻找相似词:
对于一句话:她们 夸 吴彦祖 帅 到 没朋友,如果输入 x 是吴彦祖,那么 y 可以是:“她们、夸、帅、没朋友”这些词
现有另一句话:她们 夸 我 帅 到 没朋友,如果输入 x 是:我,那么不难发现,这里的上下文 y 跟上面一句话一样从而 f(吴彦祖) = f(我) = y,所以大数据告诉我们:我 = 吴彦祖(完美的结论)
所以说,word2vec模型中比较重要的概念是词汇的上下文,说白了就是一个词周围的词,比如wt的范围为1的上下文就是wt−1和wt+1。
word2vec模式下的两个模型:CBOW和SkipGram
在word2vec中提出了两个模型(假设上下文窗口为3,图来自2013年Mikolov的原始论文,注意这里没有隐藏层,只有输入层、投影层、输出层,且输入层到投影层不带权重,投影层到输出层带权重):
CBOW(Continuous Bag-of-Word):以上下文词汇预测当前词,即用wt-2,wt-1,wt+1,wt+2去预测wt
SkipGram:以当前词预测其上下文词汇,即用wt去预测wt-2,wt-1,wt+1,wt+2
输入输出都只有一个词的简单版本(2014年Rong, X版)
假定整个词汇表的大小为V(2013年Mikolov用的N表示词表大小,此处用V,不影响本质),即假设全世界所有的词语总共有 V 个,这 V 个词语有自己的先后顺序,x 是one-hot编码形式的输入,y 是在这整个词汇表里 V 个词上输出的概率,我们希望跟真实的 y 的 one-hot encoder 一样。
假设『吴彦祖』这个词是第1个词,『我』这个单词是第2个词,那么『吴彦祖』就可以表示为一个 V 维全零向量、把第1个位置的0变成1,而『我』同样表示为 V 维全零向量、把第2个位置的0变成1。这样,每个词语都可以找到属于自己的唯一表示。
我们先来看个最简单的例子,输入输出都只有一个词。上面说到, y 是 x 的上下文,所以 y 只取上下文里一个词语的时候,语言模型就变成:
用当前词 x 预测它的下一个词 y。
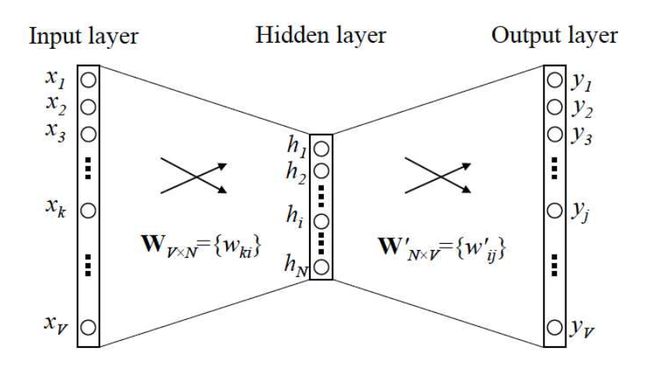
其中,V: 词汇表长度; N: 隐层神经元个数,同时也是词向量维度
W ∈RV×N输入层到隐层的权重矩阵,其实就是词向量矩阵,其中每一行代表一个词的词向量
W’ ∈RN×V隐层到输出层的权重矩阵,其中每一列也可以看作额外的一种词向量
看到这,你可能开始纳闷了,怎么前一个图是输入层、投影层、输出层,且输入层到投影层不带权重,投影层到输出层带权重,而这个图是输入层、隐藏层、输出层,且输入层到隐藏层以及隐藏层到输出层都带权重呢?
仔细深究,你会发现第一个图来自2013年Mikolov的原始论文,第二个图来自一些网友推崇的2014年Rong, X的文章,虽然都是讲的Word2Vec,但这两者之间有不少微妙的差别,但再深入一想,好像又没有本质差别:
- 2013年,Mikolov发表Word2Vec的原始论文,Word2Vec的网络结构里没有隐藏层,只有输入层、投影层、输出层,且输入层到投影层不带权重,因为只是对输入层做累加求和,学习迭代的是原始输入,而投影层到输出层虽然一开始带了权重,但在实际训练的时候,因为投影层到输出层的计算量巨大,所以改了投影层到输出层的网络结构,去掉了权重,且训练用的方法是HS或负采样。
- 2014年Rong, X在以为“Word2Vec是一个深度学习模型”这个概念的影响下,Word2Vec的网络结构里涉及神经网络中经典的输入层、隐藏层、输出层,通过从输入层到隐藏层或隐藏层到输出层的权重矩阵去向量化表示词的输入,学习迭代的是两个权重矩阵(分别用W、W′表示),当然,从输入层到隐藏层的权重矩阵W的计算量还好(因为隐层的激活函数其实是线性的,相当于没做任何处理,我们要训练这个神经网络,可以用反向传播算法,本质上是链式求导 梯度下降那一套。关于如何理解反向传播,请点击此文),但从隐藏层到输出层的权重矩阵W′的计算量巨大,所以和2013年Mikolov的工作一样,也是去掉了权重W′,且训练用的方法也是HS或负采样。
对于2014年Rong, X的工作,有两点值得注意:
第一点,“通过从输入层到隐藏层或隐藏层到输出层的权重矩阵去向量化表示词的输入” 这句说的是啥意思呢?
当模型训练完后,最后得到的其实是神经网络的权重,比如现在输入一个 x 的 one-hot encoder: [1,0,0,…,0],对应刚说的那个词语『吴彦祖』,则在输入层到隐含层的权重里,只有对应 1 这个位置的权重被激活,当前词和隐藏层的结点一一进行带权重的相乘,相乘后的结果组成一个向量 vx 来表示x,而因为每个词语的 one-hot encoder 里面 1 的位置是不同的,所以,这个向量 vx 就可以用来唯一表示 x。
类似的,输出 y 也是用 V 个结点表示的,对应V个词语,所以其实,我们把输出结点置成 [1,0,0,…,0],它也能表示『吴彦祖』这个单词,但是激活的是隐藏层到输出层的权重,当前词和输出层的结点一一进行带权重的相乘,相乘后的结果组成一个向量 vy,跟上面提到的 vx 维度一样,并且可以看做是词语『吴彦祖』的另一种词向量。而这两种词向量 vx 和 vy,正是 Mikolov 在论文里所提到的『输入向量』和『输出向量』,一般我们用『输入向量』。
原文链接:https://blog.csdn.net/v_JULY_v/article/details/102708459
深度游走算法一种将随机游走(random walk)和word2vec两种算法相结合的图结构数据挖掘算法。该算法能够学习网络的隐藏信息,能够将图中的节点表示为一个包含潜在信息的向量,如图所示
该算法主要分为随机游走和生成表示向量两个部分。首先利用随机游走算法(Random walk)从图中提取一些顶点序列;然后借助自然语言处理的思路,将生成的定点序列看作由单词组成的句子,所有的序列可以看作一个大的语料库(corpus),最有利用自然语言处理工具word2vec将每一个顶点表示为一个维度为d的向量。
符号定义:一个图可以表示为: G = ( V , E )
其中,V表示顶点的集合;E表示边的集合, 且E⊆V×V。
算法如下:
2.2 node2vec
node2vec是一种综合考虑DFS邻域和BFS邻域的graph embedding方法。简单来说,可以看作是eepwalk的一种扩展,可以看作是结合了DFS和BFS随机游走的deepwalk。
nodo2vec 算法原理
优化目标
设f(u)是将顶点u映射为embedding向量的映射函数,对于图中每个顶点u,定义NS(u)为通过采样策略S采样出的顶点u的近邻顶点集合。
node2vec优化的目标是给定每个顶点条件下,令其近邻顶点出现的概率最大。
m a x f ∑ u ∈ V l o g P r ( N s ( U ) ∣ f ( u ) ) max_f\sum_{u∈V} logPr(N_s(U)∣f(u)) maxfu∈V∑logPr(Ns(U)∣f(u))
为了将上述最优化问题可解,文章提出两个假设:
- 条件独立性假设
假设给定源顶点下,其近邻顶点出现的概率与近邻集合中其余顶点无关。
P r ( N s ( u ) ∣ f ( u ) ) = ∏ n i ∈ N s ( u ) P r ( n i ∣ f ( u ) ) Pr(N_s(u)|f(u))=\prod_{n_i\in N_s(u)} Pr(n_i|f(u)) Pr(Ns(u)∣f(u))=ni∈Ns(u)∏Pr(ni∣f(u))
- 特征空间对称性假设
这里是说一个顶点作为源顶点和作为近邻顶点的时候共享同一套embedding向量。(对比LINE中的2阶相似度,一个顶点作为源点和近邻点的时候是拥有不同的embedding向量的)
在这个假设下,上述条件概率公式可表示为
P r ( n i ∣ f ( u ) ) = exp f ( n i ) ⋅ f ( u ) ∑ v ∈ V exp f ( v ) ⋅ f ( u ) Pr(n_i|f(u))=\frac{\exp{f(n_i)\cdot f(u)}}{\sum_{v\in V}{\exp{f(v)\cdot f(u)}}} Pr(ni∣f(u))=∑v∈Vexpf(v)⋅f(u)expf(ni)⋅f(u)
根据以上两个假设条件,最终的目标函数表示为
m a x f ∑ u ∈ V [ − log Z u + ∑ n i ∈ N s ( u ) f ( n i ) ⋅ f ( u ) ] max_f{\sum_{u\in V}[-\log{Z_u}+\sum_{n_i\in N_s(u)}{f(n_i)\cdot f(u)}]} maxfu∈V∑[−logZu+ni∈Ns(u)∑f(ni)⋅f(u)]
由于归一化因子
Z u = ∑ n i ∈ N s ( u ) exp ( f ( n i ) ⋅ f ( u ) ) Z_u=\sum_{n_i\in N_s(u)}{\exp(f(n_i)\cdot f(u))} Zu=ni∈Ns(u)∑exp(f(ni)⋅f(u))
的计算代价高,所以采用负采样技术优化。
采样策略
node2vec依然采用随机游走的方式获取顶点的近邻序列,不同的是node2vec采用的是一种有偏的随机游走。给定当前顶点v,访问下一个顶点x的概率为
P ( c i = x ∣ c i − 1 = v ) = { π v x , i f ( v , x ) ∈ E 0 , o t h e r w i s e P(c_i=x|c_{i-1}=v)= \begin{cases} \pi_{vx},\quad if(v,x) \in E\\ 0, \quad otherwise \end{cases} P(ci=x∣ci−1=v)={πvx,if(v,x)∈E0,otherwise
是顶点v和顶点x之间的未归一化转移概率,Z是归一化常数。
node2vec引入两个超参数p和q来控制随机游走的策略,假设当前随机游走经过边(t,v)到达顶点v
设
π v x = α p q ( t , x ) ⋅ w v x \pi_{vx}=\alpha_{pq}(t,x)\cdot w_{vx} πvx=αpq(t,x)⋅wvx
是顶点v和x之间的边权,
α p q ( t , x ) = { 1 p , i f d t x = 0 1 , i f d t x = 1 1 q , i f d t x = 2 \alpha_{pq}(t,x)= \begin{cases} \frac{1}{p},\quad if\quad d_{tx}=0\\ 1, \quad if\quad d_{tx}=1\\ \frac{1}{q},\quad if\quad d_{tx}=2\\ \end{cases} αpq(t,x)=⎩⎪⎨⎪⎧p1,ifdtx=01,ifdtx=1q1,ifdtx=2
dtx为顶点t和顶点x之间的最短路径距离。
下面讨论超参数p pp和q qq对游走策略的影响
-
Return parameter,p
参数p控制重复访问刚刚访问过的顶点的概率。
注意到p仅作用于 dtx=0的情况,而dtx=0表示顶点x就是访问当前顶点v之前刚刚访问过的顶点。
那么若p较高,则访问刚刚访问过的顶点的概率会变低,反之变高。当p比较小时,结点间跳转类似于BFS -
In-out papameter,q
q控制着游走是向外还是向内,若q>1,随机游走倾向于访问和t接近的顶点(偏向BFS)。若q<1,倾向于访问远离t的顶点(偏向DFS)。
下面的图描述的是当从t访问到v时,决定下一个访问顶点时每个顶点对应的α
学习算法
采样完顶点序列后,剩下的步骤就和deepwalk一样了,用word2vec去学习顶点的embedding向量。
值得注意的是node2vecWalk中不再是随机抽取邻接点,而是按概率抽取,node2vec采用了Alias算法进行顶点采样。
Alias Method:时间复杂度O(1)的离散采样方法
3. 图特征表示学习
3.1 GCN 图卷积网络
基于图特征的表示学习加入了结点的特征矩阵 *X* (姓名、年龄、身高等特征),为区别于基于图结构的表示学习,将这类的模型叫做“图神经网络”。
GCN:Graph Convolutional Networks(图卷积网络),新特征是对上一层邻居结点特征的聚合。
H l = σ ( D 1 2 ( A + I ) D 1 2 H ( l − 1 ) W l ) H^{l}=\sigma(D^{\frac{1}{2}}(A+I)D^{\frac{1}{2}}H^{(l-1)}W^l) Hl=σ(D21(A+I)D21H(l−1)Wl)
A 为邻接矩阵,D 是定点的度矩阵(对角矩阵),I 是单位矩阵,W 是神经网络间的系数矩阵;
H 代表层节点特征矩阵,第一层的特征矩阵为H0,就是原始节点特征举证 X(如上)。
h v l = σ ( W l ∑ u ∈ N i ∪ v h u l − 1 ∣ N u ∣ ⋅ ∣ N V ∣ ) h^l_v=\sigma(W^l\sum_{u\in N_i\cup v}\frac{h^{l-1}_u}{\sqrt{\lvert N_u\rvert\cdot\lvert N_V\rvert }}) hvl=σ(Wlu∈Ni∪v∑∣Nu∣⋅∣NV∣hul−1)
h v l h^l_v hvl代表第 l 层中节点 v 的向量, h u l − 1 h^{l-1}_u hul−1代表的是 l 层上一层中节点u的向量,
Ni为节点i 的邻居节点集合;GCN 的聚合方式是将一个结点的所有邻居节点聚合。若每层结点的平均邻居结点个数为 d ˉ \bar{d} dˉ,K 层聚合后的结点聚合代价为 ∑ i = 0 k d i ˉ \sum^k_{i=0}\bar{d^i} ∑i=0kdiˉ,这样的计算量会很大。
GraphSAGE 在一个 epoch 中不适用某个结点所有邻居结点聚合,而是设置一个定值 S k S_k Sk,在第 k 层选择邻居的时候只从中选最多选择 S k S_k Sk 个邻居结点进行聚合,计算的复杂度大致在 ο ( ∏ k = 1 K S k ) \omicron(\prod^K_{k=1}S_k) ο(∏k=1KSk)
结点聚合应该满足:
对聚合结点的数量自适应:向量的维度不应随邻居结点和总结点个数改变。
聚合操作对聚合结点具有排列不变性。
显然,在优化过程中,模型的计算要是可导的。
集中聚合方式:
GCN原理
先附上GCN的核心计算公式:
接下来,我将带领大家分步骤理解该公式。
Step1: 求图模型的邻接矩阵和度矩阵
对于传统的GNN,一个图网络需要节点特征矩阵和邻接矩阵的输入,这样才能进行节点的聚合操作。但是GCN中还需要引入一个度矩阵,这个矩阵用来表示一个节点和多少个节点相关联,对于后面的步骤有巨大的作用,如图所示:

Step2:进行特征计算
求得矩阵A,D,X后,进行特征的计算,来聚合邻居节点的信息。GCN中的聚合方式和传统GNN中的方式有较大差异,这里分解为几个细节点:
① 邻接矩阵的改变
邻接矩阵 A 没有考虑自身的加权,所以GCN中的邻接矩阵实际上等于 A +单位对角矩阵I。
② 度矩阵的改变
首先对度矩阵的行和列进行了归一化(具体格式看下图),为什么这么做呢?行归一化系数代表着节点自身的一个变化程度,关联的节点越少,系数越大,越容易随波主流,更易受别人影响。而列归一化系数,代表关联节点对当前节点的影响程度,关系网越复杂的节点,它对其他节点的作用就越小,比如我认识一个亿万富翁,但富翁认识很多人,我们也就是一面之缘,那么能说因为我和他认识,我就是个百万富翁了嘛,显然有点草率了。通过行和列归一化系数,相互制衡,秒不可言。
同时,归一化的系数还开了根号,就是因为考虑到归一化后的行和列系数都加权给了节点特征,均衡一点。
③ Attention机制
在部分GCN中,还会引入注意力机制,根据关联节点的重要性来分配权重,最后乘到邻接矩阵上。传统计算权重的方法有两种,第一种方法,两节点特征向量直接相乘,关联节点都算完后,经过softmax算出权重值。还有第二种方法,就是将本节点和关联节点拼接成一个特征向量后,传入FC中,最后经过softmax算出权重值。如图所示:
Step3:训练参数 w 的加权
进行完聚合操作后,新的节点特征向量再乘上 w,往往会改变一下特征的维度,具体见下图:
Step 4:层数的迭代
接下来重复step1~3,每重复一次算一层,GCN正常只需要3–5层即可,这里就和CNN、RNN很不一样。因为节点每更新一次,感受野就变大一些,如果网络太深,那么每个节点就会受无关节点的影响,效果反而下降。
正如六度分割空间理论——“只需6个人,你就可以认识全世界”,见下图所示: