基于草图的图像检索-Awesome-Sketch-Based-Applications 论文笔记
Awesome-Sketch-Based-Applications 论文笔记
项目地址:https://github.com/MarkMoHR/Awesome-Sketch-Based-Applications
文章目录
- Awesome-Sketch-Based-Applications 论文笔记
- Sketch Based 3D Shape Retrieval
-
- 2015CVPR-Sketch-based 3D Shape Retrieval using Convolutional Neural Networks
-
- 采用联合 CNN 网络进行度量学习
- 损失函数 -- 度量距离函数
- 2016AAAI-Learning Cross-Domain Neural Networks for Sketch-Based 3D Shape Retrieval
-
- 特定类别的神经网络 Category-Specific Neural Networks
- 跨域神经网络设计 Cross-Domain Neural Networks
- 金字塔跨域神经网络设计 Pyramid Cross-Domain Neural Networks
- 2017AAAI-Deep Correlated Metric Learning for Sketch-based 3D Shape Retrieval
-
- 深度相关性度量学习 DCML (Deep Correlated Metric Learning)
- 特征提取
- 学习两种深度非线性变换
- 2017CVPR-Learning Barycentric Representations of 3D Shapes for Sketch-based 3D ShapeRetrieval
-
- Wasserstein 距离 & Wasserstein 重心
- 使用多视图投影的 Wasserstein 重心来描述3D图形的特征
- 利用 Wasserstein 重心进行跨域匹配
- 2018ECCV-Deep Cross-modality Adaptation via Semantics Preserving Adversarial Learning for Sketch-based 3D Shape Retrieval
-
- 基于保留语义对抗学习的深层跨模态适应模型
- 重要性感知特征学习 Importance-Aware Feature Learning
- 基于对抗学习的跨模态转换 Cross-modality Transformation based on Adversarial Learning
- 最优化方法 Optimization
- 2018ACMMM-Unsupervised Learning of 3D Model Reconstruction from Hand-Drawn Sketches
-
- 基于手绘草图三维模型重建的无监督学习 Unsupervised Learning of 3D Model Reconstruction from Hand-Drawn Sketches
- 在合成图像域内嵌入手绘草图
- 从共享的隐藏向量空间中检索渲染的图像
- 用于具有池化层的对象重建的 3D-GANS
- 2020ICME-Cross-Modal Guidance Network For Sketch-Based 3d Shape Retrieval
-
- 跨模态引导网络 Cross-modal Guidance Network (CGN)
- 引导损失函数
- 2020CVIU-Open Cross-Domain Visual Search
-
- 开放跨域视觉搜索 Open Cross-Domain Visual Search
- 2018ECCV-Generative Domain-Migration Hashing for Sketch-to-Image Retrieval
-
- 生成域迁移的哈希算法 Generative Domain-Migration Hashing
- 生成域迁移的哈希算法 Generative Domain-Migration Hashing
Sketch Based 3D Shape Retrieval
2015CVPR-Sketch-based 3D Shape Retrieval using Convolutional Neural Networks
@inproceedings{2015Sketch,
title={Sketch-based 3D Shape Retrieval using Convolutional Neural Networks},
author={ Wang, F. and Kang, L. and Li, Y. },
booktitle={2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2015},
}
采用联合 CNN 网络进行度量学习
-
传统方法
两阶段法:找到3D模型的最佳视角,用这些最佳视角对应的2D投影来跟手绘草图做匹配,即将由2D到3D的检索转化为由2D到2D的检索
-
本文方法
对整个数据集使用预定义的视点,并采用两个 Siamese CNN 网络(分别用于视图和草图)进行度量学习(相似度学习,Metric Learning)
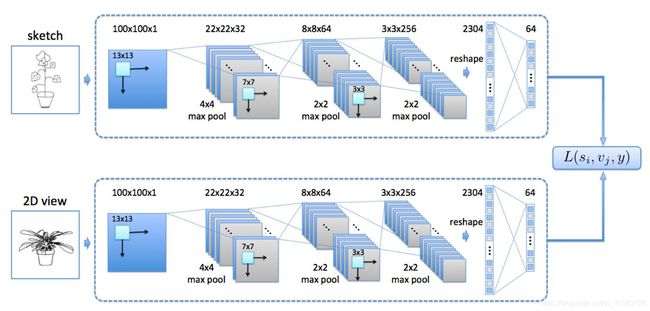
损失函数 – 度量距离函数
L ( s 1 , s 2 , v 1 , v 2 , y ) = L ( s 1 , s 2 , y ) + L ( v 1 , v 2 , y ) + L ( s 1 , v 1 , y ) (1) \mathcal{L}(s_{1},s_{2},v_{1},v_{2},y)=L(s_{1},s_{2},y)+L(v_{1},v_{2},y)+L(s_{1},v_{1},y)\tag{1} L(s1,s2,v1,v2,y)=L(s1,s2,y)+L(v1,v2,y)+L(s1,v1,y)(1)
式(1)中, L ( ⋅ , ⋅ , ⋅ ) L(·,·,·) L(⋅,⋅,⋅) 定义为
L ( s 1 , s 2 , y ) = ( 1 − y ) α D w 2 + y β e γ D w (2) L(s_{1},s_{2},y)=(1-y) \alpha D^2_{w} + y \beta e^{ \gamma D_{w}}\tag{2} L(s1,s2,y)=(1−y)αDw2+yβeγDw(2)
式(2)中, y y y 代表标签; D w = ∣ ∣ f ( s 1 ; w 1 ) − f ( s 2 ; w 2 ) D_{w}=||f(s_{1};w_{1})-f(s_{2};w_{2}) Dw=∣∣f(s1;w1)−f(s2;w2) 代表距离;设置 α = 1 C p \alpha=\frac{1}{C_{p}} α=Cp1, β = C n \beta=C_{n} β=Cn, γ = − 2.77 C n \gamma=\frac{-2.77}{C_{n}} γ=Cn−2.77,其中 C p = 0.2 C_{p}=0.2 Cp=0.2, C n = 10 C_{n}=10 Cn=10 是常数
损失函数由三个部分组成:草图相似度(the similarity of s k e t c h e s sketches sketches)、视图相似度(the similarity of views)和跨域相似度(the cross domain similarity)
2016AAAI-Learning Cross-Domain Neural Networks for Sketch-Based 3D Shape Retrieval
@inproceedings{2016Learning,
title={Learning Cross-Domain Neural Networks for Sketch-Based 3D Shape Retrieval.},
author={ Fan, Z. and Jin, X. and F Yi},
booktitle={Aaai},
year={2016},
}
特定类别的神经网络 Category-Specific Neural Networks
为来自同一类的实例设置相同的目标向量,对目标层实施区分性约束
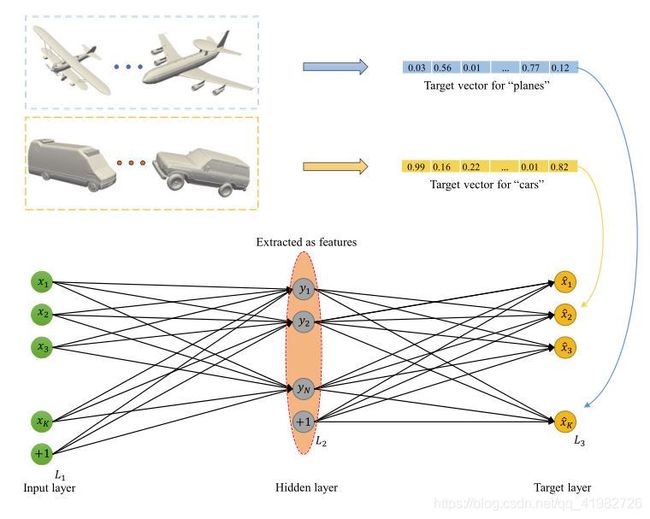
跨域神经网络设计 Cross-Domain Neural Networks
-
特征表示:2D-ScSPM,3D-LD-SIFT
-
对于草图和3D图,联合学习 CDNN 的目标函数为:
arg min W s , b s 1 P s ∑ i = 1 P s ∥ x ^ s i − h W s , b s ( x s i ) ∥ 2 2 + λ ∑ l = 1 L ∥ W s l ∥ F 2 \begin{aligned} \underset { \boldsymbol { W } _ { \boldsymbol { s } } , \boldsymbol { b } _ { \boldsymbol { s } } } { \arg \min } \frac { 1 } { P _ { s } } & \sum _ { i = 1 } ^ { P _ { s } } \left\| \hat { \boldsymbol { x } } _ { s } ^ { i } - h _ { \boldsymbol { W } _ { \boldsymbol { s } } , \boldsymbol { b } _ { \boldsymbol { s } } } \left( \boldsymbol { x } _ { \boldsymbol { s } } ^ { i } \right) \right\| _ { 2 } ^ { 2 } + \lambda \sum _ { l = 1 } ^ { L } \left\| \boldsymbol { W } _ { \boldsymbol { s } } ^ { l } \right\| _ { F } ^ { 2 } \end{aligned} Ws,bsargminPs1i=1∑Ps∥∥∥x^si−hWs,bs(xsi)∥∥∥22+λl=1∑L∥∥∥Wsl∥∥∥F2arg min W m , b m 1 P m ∑ j = 1 P m ∥ x ^ m j − h W m , b m ( x m j ) ∥ 2 2 + λ ∑ l = 1 L ∥ W m l ∥ F 2 s.t. x ^ m i = x ^ m j = x ^ s i = x ^ s j if q ( x m i ) = q ( x m j ) = q ( x s i ) = q ( x s j ) (3) \underset { \boldsymbol { W } _ { \boldsymbol { m } } , \boldsymbol { b } _ { m } } { \arg \min } \frac { 1 } { P _ { m } } \sum _ { j = 1 } ^ { P _ { m } } \left\| \hat { \boldsymbol { x } } _ { m } ^ { j } - h _ { \boldsymbol { W } _ { \boldsymbol { m } } , \boldsymbol { b } _ { \boldsymbol { m } } } \left( \boldsymbol { x } _ { \boldsymbol { m } } ^ { j } \right) \right\| _ { 2 } ^ { 2 } + \lambda \sum _ { l = 1 } ^ { L } \left\| \boldsymbol { W } _ { \boldsymbol { m } } ^ { l } \right\| _ { F } ^ { 2 } \\ \text { s.t. } \quad \hat { \boldsymbol { x } } _ { m } ^ { i } = \hat { \boldsymbol { x } } _ { m } ^ { j } = \hat { \boldsymbol { x } } _ { s } ^ { i } = \hat { \boldsymbol { x } } _ { s } ^ { j } \\ \text { if } \quad q \left( \boldsymbol { x } _ { m } ^ { i } \right) = q \left( \boldsymbol { x } _ { m } ^ { j } \right) = q \left( \boldsymbol { x } _ { s } ^ { i } \right) = q \left( \boldsymbol { x } _ { s } ^ { j } \right) \tag{3} Wm,bmargminPm1j=1∑Pm∥∥∥x^mj−hWm,bm(xmj)∥∥∥22+λl=1∑L∥∥∥Wml∥∥∥F2 s.t. x^mi=x^mj=x^si=x^sj if q(xmi)=q(xmj)=q(xsi)=q(xsj)(3)
可以将最优化式(3)的过程看作是分别优化2D和3D的两个网络的过程
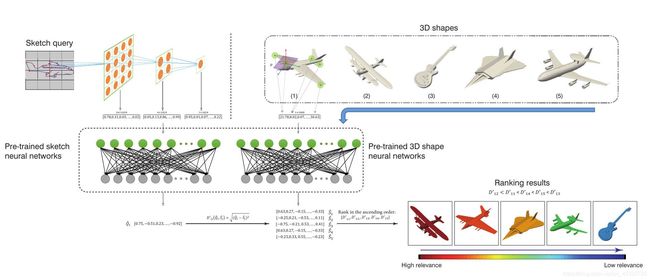
金字塔跨域神经网络设计 Pyramid Cross-Domain Neural Networks
-
目的:草图降噪,缓解草图不完整、不连续性带来的麻烦
-
遵循 ScSPM 框架来构建草图的层次表示。从草图图像的 16 × 16 的块中提取SIFT特征,并在约束投影系数稀疏性的同时投影到 1024 维的映射中。对 3 层稀疏编码使用最大池化,将草图图像分为 1 × 1、2 × 2 和 4 × 4 的 patches。替换了直接连接池化的结果与输入的全局 (1 × 1 + 2 × 2 + 4 × 4) × 1024 = 21504 维特征到神经网络中(即 CDNN 方法),采用了提取每个金字塔层的汇总结果,并特别训练了在该层描述草图特征和3D特征之间的联系的 CDNN 模型。当草图和3D图形特征通过 PCDNN 时,提取每个金字塔网络隐含层的值,分别作为草图和3D形状的最终表示(如红色虚线矩形所示)
-
对目标函数进行了一系列优化
-
检索:定义 Y ^ q \hat { \boldsymbol { Y } } _ { q } Y^q 为编码查询特征, Y ^ s \hat { \boldsymbol { Y } } _ { s } Y^s 为编码3D图形特征。为根据输入的草图查询对应的3D图形,使用式(4)计算两个特征之间的欧式距离。然后,对矩阵 D ’ D^{’} D’ 每一行进行升序排序, D i j ′ D^{'}_{ij} Dij′ 的值越低,则说明对应的 Y ^ s j \hat { \boldsymbol { Y } } ^ { j } _ { s } Y^sj 和 Y ^ q i \hat { \boldsymbol { Y } } ^ { i } _ { q } Y^qi 匹配度越高
D i j ′ ( Y ^ q , Y ^ s ) = ( Y ^ q i − Y ^ s j ) 2 (4) D _ { i j } ^ { \prime } \left( \hat { \boldsymbol { Y } } _ { q } , \hat { \boldsymbol { Y } } _ { s } \right) = \sqrt { \left( \hat { \boldsymbol { Y } } _ { q } ^ { i } - \hat { \boldsymbol { Y } } _ { s } ^ { j } \right) ^ { 2 } } \tag{4} Dij′(Y^q,Y^s)=(Y^qi−Y^sj)2(4)
2017AAAI-Deep Correlated Metric Learning for Sketch-based 3D Shape Retrieval
@article{2018Deep,
title={Deep Correlated Holistic Metric Learning for Sketch-Based 3D Shape Retrieval},
author={ Dai, G. and Jin, X. and Fan, Z. and Yi, F. },
journal={IEEE Transactions on Image Processing A Publication of the IEEE Signal Processing Society},
volume={27},
number={7},
pages={3374},
year={2018},
}
深度相关性度量学习 DCML (Deep Correlated Metric Learning)
DCML包括草图域(源域网络,SDN)和3D图形域(目标域网络,TDN),用同相同的 loss 联合训练两个不同的深度神经网络(每个域一个),学习两个深度非线性转换,将两个域的特征映射到一个非线性特征空间。所提出的 loss 包括对抗损失 discriminative loss 和相关性损失 correlation loss,目的是增加每个域内特征的判别性以及不同域之间的相关性。在转移空间中,对抗损失使深度转换特征的类内距离最小化,相关性损失使深度转换特征的类间距离最大化,每个域内至少有一个预定义的边缘,而相关损失则集中于使不同域之间的分布差异最小化
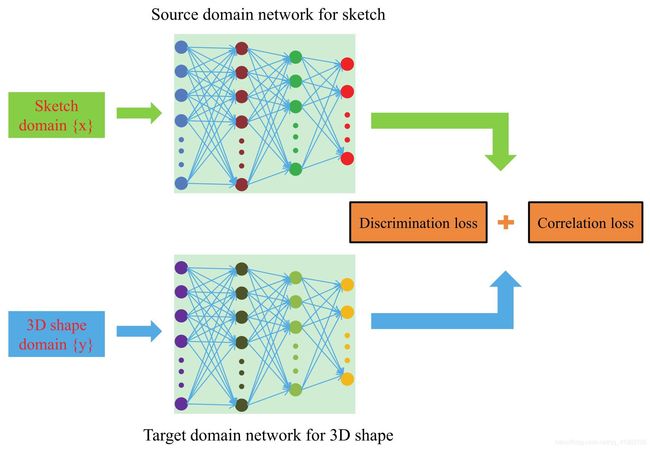
特征提取
- 2D草图:采用 CNN,在 Sketch 数据集上 AlexNet 微调,提取了“fc7”层的特征,维度为 4096
- 3D图形:先提取 3D-SIFT,然后用 LLC 编码,得到全局形状描述符
学习两种深度非线性变换
保证了每个领域内特征的辨别和不同领域间特征分布的一致性
1、激活函数
a k + 1 i , s = σ ( W k s a k i , s + b k s ) = σ ( r k + 1 i , s ) a k + 1 j , t = σ ( W k t a k j , t + b k t ) = σ ( r k + 1 j , t ) (5) \begin{array} { l } a _ { k + 1 } ^ { i , s } = \sigma \left( W _ { k } ^ { s } a _ { k } ^ { i , s } + b _ { k } ^ { s } \right) = \sigma \left( r _ { k + 1 } ^ { i , s } \right) \\ a _ { k + 1 } ^ { j , t } = \sigma \left( W _ { k } ^ { t } a _ { k } ^ { j , t } + b _ { k } ^ { t } \right) = \sigma \left( r _ { k + 1 } ^ { j , t } \right) \end{array} \tag{5} ak+1i,s=σ(Wksaki,s+bks)=σ(rk+1i,s)ak+1j,t=σ(Wktakj,t+bkt)=σ(rk+1j,t)(5)
2、非线性变换函数
f s ( x i ) = a K s i , s f t ( y j ) = a K t j , t (6) f ^ { s } \left( x _ { i } \right) = a _ { K _ { s } } ^ { i , s } \quad f ^ { t } \left( y _ { j } \right) = a _ { K _ { t } } ^ { j , t } \tag{6} fs(xi)=aKsi,sft(yj)=aKtj,t(6)
3、损失函数
L = α L d + ( 1 − α ) L c + λ ( ∥ W s ∥ F 2 + ∥ W t ∥ F 2 ) (7) L = \alpha L ^ { d } + ( 1 - \alpha ) L ^ { c } + \lambda \left( \left\| W ^ { s } \right\| _ { F } ^ { 2 } + \left\| W ^ { t } \right\| _ { F } ^ { 2 } \right) \tag{7} L=αLd+(1−α)Lc+λ(∥Ws∥F2+∥∥Wt∥∥F2)(7)
其中, L d L^d Ld 为对抗损失,在每个域内预先设定边界 h h h,使深度变化特征类内距离最小、类间距离最大; L c L^c Lc 是相关性损失,用于优化跨域距离,以弱化域间数据表达方式不一致的影响
损失函数的每一项都是可微的,因此 DCML 网络可以通过随机梯度下降算法的反向传播来进行优化
-
对抗损失 Discrimination term
L d = L s d + L t d (8) L^{d}=L^{d}_{s}+L^{d}_{t} \tag{8} Ld=Lsd+Ltd(8)
其中, L s d L^{d}_{s} Lsd 和 L t d L^{d}_{t} Ltd 分别代表源域和目标域的对抗损失。对抗损失由同类内正例间两两的欧式距离之和以及同类负例间两两的 hinge loss 之和组成,hinge loss 的初始间隔为 h h h在源域:
L s d = ∑ ( x i , x j ) ∈ P s d + s ( x i , x j ) + ∑ ( x i , x j ) ∈ N s d − s ( x i , x j ) d + s ( x i , x j ) = ∥ f s ( x i ) − f s ( x j ) ∥ 2 2 d − s ( x i , x j ) = max { 0 , h − ∥ f s ( x i ) − f s ( x j ) ∥ 2 2 } (9) \begin{array} { l } L _ { s } ^ { d } = \sum _ { \left( x _ { i } , x _ { j } \right) \in P ^ { s } } d _ { + } ^ { s } \left( x _ { i } , x _ { j } \right) + \sum _ { \left( x _ { i } , x _ { j } \right) \in N ^ { s } } d _ { - } ^ { s } \left( x _ { i } , x _ { j } \right) \\ d _ { + } ^ { s } \left( x _ { i } , x _ { j } \right) = \left\| f ^ { s } \left( x _ { i } \right) - f ^ { s } \left( x _ { j } \right) \right\| _ { 2 } ^ { 2 } \\ d _ { - } ^ { s } \left( x _ { i } , x _ { j } \right) = \max \left\{ 0 , h - \left\| f ^ { s } \left( x _ { i } \right) - f ^ { s } \left( x _ { j } \right) \right\| _ { 2 } ^ { 2 } \right\} \end{array} \tag{9} Lsd=∑(xi,xj)∈Psd+s(xi,xj)+∑(xi,xj)∈Nsd−s(xi,xj)d+s(xi,xj)=∥fs(xi)−fs(xj)∥22d−s(xi,xj)=max{0,h−∥fs(xi)−fs(xj)∥22}(9)
在目标域:
L t d = ∑ ( y i , y j ) ∈ P t d + t ( y i , y j ) + ∑ ( y i , y j ) ∈ N t d − t ( y i , y j ) d + t ( y i , y j ) = ∥ f t ( y i ) − f t ( y j ) ∥ 2 2 d − t ( y i , y j ) = max { 0 , h − ∥ f t ( y i ) − f t ( y j ) ∥ 2 2 } (10) \begin{array} { l } L _ { t } ^ { d } = \sum _ { \left( y _ { i } , y _ { j } \right) \in P ^ { t } } d _ { + } ^ { t } \left( y _ { i } , y _ { j } \right) + \sum _ { \left( y _ { i } , y _ { j } \right) \in N ^ { t } } d _ { - } ^ { t } \left( y _ { i } , y _ { j } \right) \\ d _ { + } ^ { t } \left( y _ { i } , y _ { j } \right) = \left\| f ^ { t } \left( y _ { i } \right) - f ^ { t } \left( y _ { j } \right) \right\| _ { 2 } ^ { 2 } \\ d _ { - } ^ { t } \left( y _ { i } , y _ { j } \right) = \max \left\{ 0 , h - \left\| f ^ { t } \left( y _ { i } \right) - f ^ { t } \left( y _ { j } \right) \right\| _ { 2 } ^ { 2 } \right\} \end{array} \tag{10} Ltd=∑(yi,yj)∈Ptd+t(yi,yj)+∑(yi,yj)∈Ntd−t(yi,yj)d+t(yi,yj)=∥ft(yi)−ft(yj)∥22d−t(yi,yj)=max{0,h−∥ft(yi)−ft(yj)∥22}(10) -
相关性损失 Correlation term
L c = L 1 c + L 2 c L 1 c = ∑ ( x i , y j ) ∈ P c d + c ( x i , y j ) + ∑ ( x i , y j ) ∈ N c d − c ( x i , y j ) L 2 c = ∑ c s , c t ∀ x i , x j ∈ c s ∀ y i , y j ∈ c t R ( x i , x j , y i , y j ) − ∑ c s , d t c ≠ d ∑ ∀ x i , x j ∈ c s R ( x i , x j , y i , y j ) (11) L ^ { c } = L _ { 1 } ^ { c } + L _ { 2 } ^ { c } \\ L _ { 1 } ^ { c } = \sum _ { \left( x _ { i } , y _ { j } \right) \in P ^ { c } } d _ { + } ^ { c } \left( x _ { i } , y _ { j } \right) + \sum _ { \left( x _ { i } , y _ { j } \right) \in N ^ { c } } d _ { - } ^ { c } \left( x _ { i } , y _ { j } \right) \\ L _ { 2 } ^ { c } = \sum _ { c ^ { s } , c ^ { t } \forall x _ { i } , x _ { j } \in c ^ { s } \atop \forall y _ { i } , y _ { j } \in c ^ { t } } R \left( x _ { i } , x _ { j } , y _ { i } , y _ { j } \right) - \sum _ { c ^ { s } , d ^ { t } } ^ { c \neq d } \sum _ { \forall x _ { i } , x _ { j } \in c ^ { s } } R \left( x _ { i } , x _ { j } , y _ { i } , y _ { j } \right) \tag{11} Lc=L1c+L2cL1c=(xi,yj)∈Pc∑d+c(xi,yj)+(xi,yj)∈Nc∑d−c(xi,yj)L2c=∀yi,yj∈ctcs,ct∀xi,xj∈cs∑R(xi,xj,yi,yj)−cs,dt∑c=d∀xi,xj∈cs∑R(xi,xj,yi,yj)(11)
其中, L 1 c L^{c}_{1} L1c 以 h h h 为阈值,直接最小化跨域正例对的间距,同时最大化跨域负例对的间距,仅可能地使两个域的数据分布相似。 P c P^{c} Pc 和 N c N^{c} Nc 分别代表跨域的正例对和负例对的集合; d d d 的定义如下:
d + c ( x i , y j ) = ∥ f s ( x i ) − f t ( y j ) ∥ 2 2 d − c ( x i , y j ) = max { 0 , h − ∥ f s ( x i ) − f t ( y j ) ∥ 2 2 } (12) \begin{array} { l } d _ { + } ^ { c } \left( x _ { i } , y _ { j } \right) = \left\| f ^ { s } \left( x _ { i } \right) - f ^ { t } \left( y _ { j } \right) \right\| _ { 2 } ^ { 2 } \\ d _ { - } ^ { c } \left( x _ { i } , y _ { j } \right) = \max \left\{ 0 , h - \left\| f ^ { s } \left( x _ { i } \right) - f ^ { t } \left( y _ { j } \right) \right\| _ { 2 } ^ { 2 } \right\} \end{array} \tag{12} d+c(xi,yj)=∥fs(xi)−ft(yj)∥22d−c(xi,yj)=max{0,h−∥fs(xi)−ft(yj)∥22}(12)
L 2 c L^{c}_{2} L2c 进一步保证跨域数据的分布一致性。 c s c^{s} cs 和 c t c^{t} ct 分别代表来自源域和目标域的分类为 c c c 的样本集合;当两个样本来自同一个类时, R R R 应该取最小值,否则 R R R应取最大值。 R R R 的定义如下:
R ( x i , x j , y i , y j ) = ( ∥ f s ( x i ) − f s ( x j ) ∥ 2 2 − ∥ f t ( y i ) − f t ( y j ) ∥ 2 2 ) 2 (13) R \left( x _ { i } , x _ { j } , y _ { i } , y _ { j } \right) = \left( \sqrt { \left\| f ^ { s } \left( x _ { i } \right) - f ^ { s } \left( x _ { j } \right) \right\| _ { 2 } ^ { 2 } } - \right. \left. \sqrt { \left\| f ^ { t } \left( y _ { i } \right) - f ^ { t } \left( y _ { j } \right) \right\| _ { 2 } ^ { 2 } } \right) ^ { 2 } \tag{13} R(xi,xj,yi,yj)=(∥fs(xi)−fs(xj)∥22−∥ft(yi)−ft(yj)∥22)2(13)
2017CVPR-Learning Barycentric Representations of 3D Shapes for Sketch-based 3D ShapeRetrieval
@inproceedings{2017Learning,
title={Learning Barycentric Representations of 3D Shapes for Sketch-Based 3D Shape Retrieval},
author={ Jin, X. and Dai, G. and Fan, Z. and Yi, F. },
booktitle={2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2017},
}
Wasserstein 距离 & Wasserstein 重心
-
Wasserstein 距离
特点:Wasserstein 距离可以描述不同概率分布之间的几何特性,不仅告诉我们两个分布之间的距离,而且能够告诉我们它们具体如何不一样,即如何从一个分布转化为另一个分布
又称 Earth Mover’s Distance,具体定义可参考:
【数学】Wasserstein Distance
Wasserstein GAN and the Kantorovich-Rubinstein Duality
Notes on Optimal Transport
-
Wasserstein 重心
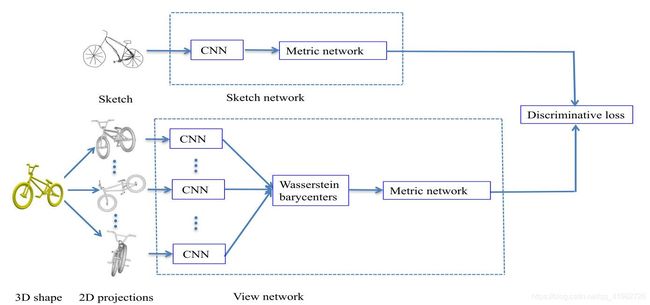
使用多视图投影的 Wasserstein 重心来描述3D图形的特征
使用 Wasserstein 重心从多个视图投影的特征空间来表征3D形状,作为一种非线性操作可以捕获结构的深层特征
均匀地缩放每个3D图形,并将形状的质心放置在球坐标系的原点。将 V V V 个虚拟摄像机均匀地放置在3D形状周围,就可以获得 V V V 个渲染视图。对于每个视图,将3D图形渲染为一个投影的灰度图像。一旦得到3D形状的二维投影,就可以提取二维投影的深度 CNN 特征。本文使用了 AlexNet 作为 CNN 的特征,它由五个卷积层和三个完全连接的层组成。对于每个投影,使用 ReLU 非线性激活函数后的最后一个全连通层作为深度特征,其特征大小为 4096
利用 Wasserstein 重心进行跨域匹配
提取了二维投影的深度 CNN 特征。计算深度 CNN 特征的 Wasserstein 重心来表示3D形状。利用全连通层的度量网络,设计了一个判别损失来学习草图和形状特征,用于跨域检索
损失函数:
( θ ^ 1 , θ ^ 2 ) = argmin θ 1 , θ 2 1 ∑ n j ∑ j = 1 n 2 ∑ i ∈ c ( j ) ∥ z j 2 − z i 1 ∥ 2 2 + 1 ∑ m j ∑ j = 1 n 2 ∑ i ∉ c ( j ) max ( 0 , α − ∥ z j 2 − z i 1 ∥ 2 2 ) + β 1 L 1 + β 2 L 2 (14) \left( \hat { \boldsymbol { \theta } } _ { 1 } , \hat { \boldsymbol { \theta } } _ { 2 } \right) = \operatorname { argmin } _ { \boldsymbol { \theta } _ { 1 } , \boldsymbol { \theta } _ { 2 } } \frac { 1 } { \sum n _ { j } } \sum _ { j = 1 } ^ { n _ { 2 } } \sum _ { i \in c ( j ) } \left\| \boldsymbol { z } _ { j } ^ { 2 } - \boldsymbol { z } _ { i } ^ { 1 } \right\| _ { 2 } ^ { 2 } + \\ \frac { 1 } { \sum m _ { j } } \sum _ { j = 1 } ^ { n _ { 2 } } \sum _ { i \notin c ( j ) } \max \left( 0 , \alpha - \left\| \boldsymbol { z } _ { j } ^ { 2 } - \boldsymbol { z } _ { i } ^ { 1 } \right\| _ { 2 } ^ { 2 } \right) + \beta _ { 1 } L _ { 1 } + \beta _ { 2 } L _ { 2 } \tag{14} (θ^1,θ^2)=argminθ1,θ2∑nj1j=1∑n2i∈c(j)∑∥∥zj2−zi1∥∥22+∑mj1j=1∑n2i∈/c(j)∑max(0,α−∥∥zj2−zi1∥∥22)+β1L1+β2L2(14)
其中, θ 1 = W 1 , b 1 \theta_{1}={W_{1},b_{1}} θ1=W1,b1 和 θ 2 = W 2 , b 2 \theta_{2}={W_{2},b_{2}} θ2=W2,b2 是视图和草图网络的权重和偏移量, z i 1 z^{1}_{i} zi1 和 z j 2 z^{2}_{j} zj2分别是视图网络和草图网络的输出, n j n_{j} nj 和 m j m_{j} mj 分别是草图的正负例样本数。 L 1 L_{1} L1 和 L 2 L_{2} L2 是正则项, β 1 \beta_{1} β1 和 β 2 \beta_{2} β2 是正则化参数。在式(14)中,前两项使跨域特征对之间的类内距离最小,类间距离最大。正则化项分别使3D形状特征和草图特征的类内散点最小和类间散点最大
2018ECCV-Deep Cross-modality Adaptation via Semantics Preserving Adversarial Learning for Sketch-based 3D Shape Retrieval
@inproceedings{2018Deep,
title={Deep Cross-modality Adaptation via Semantics Preserving Adversarial Learning for Sketch-based 3D Shape Retrieval},
author={ Chen, J. and Fang, Y. },
booktitle={Springer, Cham},
year={2018},
}
基于保留语义对抗学习的深层跨模态适应模型
-
分别采用两个度量网络,在两个深度卷积神经网络(CNNs)的基础上,基于重要性感知度量学习方法学习特定模态的判别特征
-
明确引入了一种跨模态转换网络来补偿两种模态之间的差异,该网络可以将二维草图的特征转移到三维形状的特征空间
-
开发了一种基于对抗学习的方法来训练转换模型,通过同时增强两种模式数据分布之间的整体相关性,并通过最小化跨模态平均差异项来缓解局部语义差异
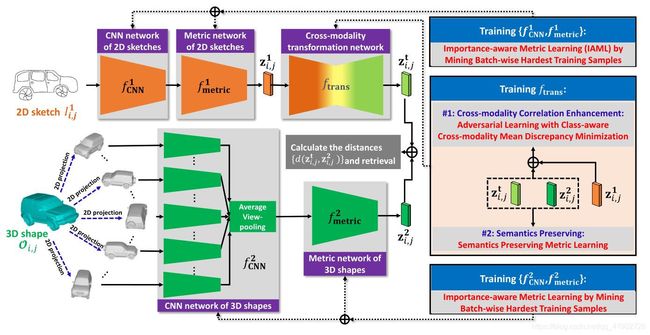
重要性感知特征学习 Importance-Aware Feature Learning
定义特征向量:
Z m = { z 1 , 1 m , ⋯ , z 1 , K m , ⋯ , z C , 1 m , ⋯ , z C , K m } (15) \mathbf { Z } ^ { m } = \left\{ \mathbf { z } _ { 1,1 } ^ { m } , \cdots , \mathbf { z } _ { 1 , K } ^ { m } , \cdots , \mathbf { z } _ { C , 1 } ^ { m } , \cdots , \mathbf { z } _ { C , K } ^ { m } \right\} \tag{15} Zm={z1,1m,⋯,z1,Km,⋯,zC,1m,⋯,zC,Km}(15)
其中, m ∈ { 1 , 2 } m \in { \{ 1,2 \} } m∈{1,2}, i = 1 , ⋅ ⋅ ⋅ , C i=1,···,C i=1,⋅⋅⋅,C, j = 1 , ⋅ ⋅ ⋅ , K j=1,···,K j=1,⋅⋅⋅,K, z i , j 1 = f metric 1 ( f CNN 1 ( I i , j 1 ) ) , z i , j 2 = f metric 2 ( f CNN 2 ( I i , j 2 ) ) \mathbf { z } _ { i , j } ^ { 1 } = f _ { \text {metric } } ^ { 1 } \left( f _ { \text {CNN } } ^ { 1 } \left( I _ { i , j } ^ { 1 } \right) \right) , \mathbf { z } _ { i , j } ^ { 2 } = f _ { \text {metric } } ^ { 2 } \left( f _ { \text {CNN } } ^ { 2 } \left( \mathbf { I } _ { i , j } ^ { 2 } \right) \right) zi,j1=fmetric 1(fCNN 1(Ii,j1)),zi,j2=fmetric 2(fCNN 2(Ii,j2))
损失函数:
L I A M L m ( { θ C N N m , θ m e t r i c m ; Z m ) = ∑ i C ∑ j = 1 K max ( 0 , η − [ ∥ z i , j m − z i ∗ , n ∗ m ∥ 2 − ∥ z i , j m − z i , p ∗ m ∥ 2 ] ) (16) L _ { I A M L } ^ { m } \left( \left\{ \boldsymbol { \theta } _ { \mathbf { C N N } } ^ { m } , \boldsymbol { \theta } _ { \mathbf { m e t r i c } } ^ { m } ; \mathbf { Z } ^ { m } \right) \right. = \sum _ { i } ^ { C } \sum _ { j = 1 } ^ { K } \max \left( 0 , \eta - \left[ \left\| \mathbf { z } _ { i , j } ^ { m } - \mathbf { z } _ { i ^ { * } , n ^ { * } } ^ { m } \right\| _ { 2 } - \left\| \mathbf { z } _ { i , j } ^ { m } - \mathbf { z } _ { i , p ^ { * } } ^ { m } \right\| _ { 2 } \right] \right) \tag{16} LIAMLm({θCNNm,θmetricm;Zm)=i∑Cj=1∑Kmax(0,η−[∥∥zi,jm−zi∗,n∗m∥∥2−∥∥zi,jm−zi,p∗m∥∥2])(16)
其中 η > 0 \eta>0 η>0为常数,而
Z i ∗ , n ∗ m = a r g m i n i ′ ∈ { 1 , ⋯ , C } , y i ′ ≠ y i , n ∈ { 1 , ⋯ , K } ∥ z i , j m − Z i ′ , n m ∥ 2 \begin{aligned} \mathbf { Z } _ { i ^ { * } , n ^ { * } } ^ { m } = \mathop{argmin}_{ i ^ { \prime } \in \{ 1 , \cdots , C \} , y _ { i } ^ { \prime } \neq y _ { i } , n \in \{ 1 , \cdots , K \} } \end{aligned} \left\| \mathbf { z } _ { i , j } ^ { m } - \mathbf { Z } _ { i ^ { \prime } , n } ^ { m } \right\| _ { 2 } Zi∗,n∗m=argmini′∈{1,⋯,C},yi′=yi,n∈{1,⋯,K}∥∥zi,jm−Zi′,nm∥∥2
z i , p ∗ m = argmax p ∈ { 1 , ⋯ , K } , p ≠ j ∥ z i , j m − z i , p m ∥ 2 (17) \mathbf { z } _ { i , p ^ { * } } ^ { m } = \underset { p \in \{ 1 , \cdots , K \} , p \neq j } { \operatorname { argmax } } \left\| \mathbf { z } _ { i , j } ^ { m } - \mathbf { z } _ { i , p } ^ { m } \right\| _ { 2 } \tag{17} zi,p∗m=p∈{1,⋯,K},p=jargmax∥∥zi,jm−zi,pm∥∥2(17)
Z i ∗ , p ∗ m { Z } _ { i ^ { * } , p ^ { * } } ^ { m } Zi∗,p∗m 和 Z i ∗ , n ∗ m { Z } _ { i ^ { * } , n ^ { * } } ^ { m } Zi∗,n∗m 是 z i , j m { z } _ { i , j } ^ { m } zi,jm 的最难区分的同类样本 hardest positive samples 和最难区分的异类样本 hardest negative samples,它们在训练时都应给予较高的重要性权重,同时强制他们与语义一致,这样可以更好地学习判别特征
最小化式(16)的损失函数,等价于让最小类间间距比最大类内间距大出一个阈值 η \eta η。这样就能训练 CNN 网络和度量网络来让为每个模态生成判别特征
基于对抗学习的跨模态转换 Cross-modality Transformation based on Adversarial Learning
设 Z t Z^{t} Zt是由 z 1 z^{1} z1转换得来的特征,其包括以下两个要求:
- 保留语义 semantics preserving,即保持小的类内距离和大的类间距离
- 拥有关于 { Z i , j 2 } \{ Z^{2}_{i,j} \} {Zi,j2}的相关数据分布 correlated data distribution with { Z i , j 2 } \{ Z^{2}_{i,j} \} {Zi,j2},即拥有学习到的3D图形的特征
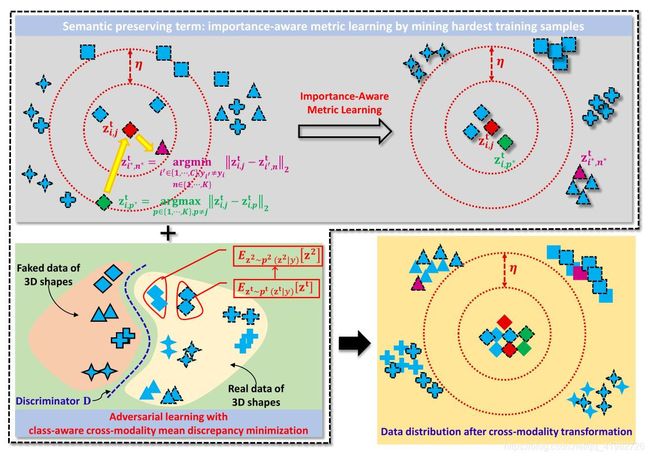
如图所示,模型使用了两个模块来保证上述的两个要求:
-
语义保留模块 Semantics Preserving Term
使用式(16)和式(17)所示的损失函数来保证小的类内距离和大的类间距离
-
跨模态相关项增强模块 Cross-modality Correlation Enhancement Term
使用GANs,训练生成器 G G G 从噪声向量 v v v 的数据分布 p x ( x ) p_{x}(x) px(x) 中采样,训练判别器 D D D 来区分 G G G 生成的数据和来自 p x ( x ) p_{x}(x) px(x) 的真实数据。
在该模型中,GANs 的目标函数即为:
min f trans max D E z 2 ∼ p 2 ( z 2 ) [ log ( D ( z 2 ) ) ] + E z 1 ∼ p 1 ( z 1 ) [ log ( 1 − D ( f trans ( z 1 ) ) ) ] (18) \min _ { f _ { \text {trans } } } \max _ { D } E _ { \mathbf { z } ^ { 2 } \sim p ^ { 2 } \left( \mathbf { z } ^ { 2 } \right) } \left[ \log \left( D \left( \mathbf { z } ^ { \mathbf { 2 } } \right) \right) \right] + E _ { \mathbf { z } ^ { 1 } \sim p ^ { 1 } \left( \mathbf { z } ^ { 1 } \right) } \left[ \log \left( 1 - D \left( f _ { \text {trans } } \left( \mathbf { z } ^ { \mathbf { 1 } } \right) \right) \right) \right] \tag{18} ftrans minDmaxEz2∼p2(z2)[log(D(z2))]+Ez1∼p1(z1)[log(1−D(ftrans (z1)))](18)
其中, p 1 ( z 1 ) , p 2 ( z 2 ) p^{1}(z^{1}),p^{2}(z^{2}) p1(z1),p2(z2) 和 p t ( z t ) p^{t}(z^{t}) pt(zt) 分别是学习到的草图特征的分布、3D图形的特征分布和转换数据后的特征分布。当式(8)达到全局平衡时,有 p t ( z t ) = p t ( f trans ( z 1 ) ) = p 2 ( z 2 ) p ^ { \mathbf { t } } \left( \mathbf { z } ^ { \mathbf { t } } \right) = p ^ { \mathbf { t } } \left( f _ { \text {trans } } \left( \mathbf { z } ^ { \mathbf { 1 } } \right) \right) = p ^ { \mathbf { 2 } } \left( \mathbf { z } ^ { \mathbf { 2 } } \right) pt(zt)=pt(ftrans (z1))=p2(z2),即转换数据 z t z^{t} zt 和3D图形 z 2 z^{2} z2 拥有相同的数据分布。因此,将减少跨模态数据的差异损失函数为:
L G = E z 1 ∼ p 1 ( z 1 ) [ log ( 1 − D ( z t ) ) ) ] (19) \left. L _ { G } = E _ { \mathbf { z } ^ { 1 } \sim p ^ { 1 } \left( \mathbf { z } ^ { 1 } \right) } \left[ \log \left( 1 - D \left( \mathbf { z } ^ { \mathbf { t } } \right) \right) \right) \right] \tag{19} LG=Ez1∼p1(z1)[log(1−D(zt)))](19)L D = − E z 2 ∼ p 2 ( z 2 ) [ log ( D ( z 2 ) ) ] − E z 1 ∼ p 1 ( z 1 ) [ log ( 1 − D ( z t ) ) ] (20) L _ { D } = - E _ { \mathbf { z } ^ { 2 } \sim p ^ { 2 } \left( \mathbf { z } ^ { 2 } \right) } \left[ \log \left( D \left( \mathbf { z } ^ { 2 } \right) \right) \right] - E _ { \mathbf { z } ^ { 1 } \sim p ^ { 1 } \left( \mathbf { z } ^ { 1 } \right) } \left[ \log \left( 1 - D \left( \mathbf { z } ^ { \mathbf { t } } \right) \right) \right] \tag{20} LD=−Ez2∼p2(z2)[log(D(z2))]−Ez1∼p1(z1)[log(1−D(zt))](20)
L C M D = ∑ y ∥ E z t ∼ p t ( z t ∣ y ) [ z t ] − E z 2 ∼ p 2 ( z 2 ∣ y ) [ z 2 ] ∥ 2 (21) L _ { C M D } = \sum _ { y } \left\| E _ { \mathbf { z } ^ { \mathbf { t } } \sim p ^ { \mathbf { t } } \left( \mathbf { z } ^ { \mathbf { t } } \mid y \right) } \left[ \mathbf { z } ^ { \mathbf { t } } \right] - E _ { \mathbf { z } ^ { 2 } \sim p ^ { 2 } \left( \mathbf { z } ^ { 2 } \mid y \right) } \left[ \mathbf { z } ^ { \mathbf { 2 } } \right] \right\| _ { 2 } \tag{21} LCMD=y∑∥∥Ezt∼pt(zt∣y)[zt]−Ez2∼p2(z2∣y)[z2]∥∥2(21)
L G L_{G} LG 和 L D L_{D} LD 可以令 GANs 减少草图的变换特征和3D模型特征的分布之间的差异, L C M D L_{CMD} LCMD 补充考虑了跨模态的语义结构,可以使得从草图得到的 y y y 类平均特征向量接近于从3D形状得到的同类平均特征向量
汇总上述所有损失函数,最终的转换模块 f t r a n s f_{trans} ftrans 的损失函数为:
L T ( θ trans ) = L S e P + ( L G + L C M D ) (22) L _ { T } \left( \boldsymbol { \theta } _ { \text {trans } } \right) = L _ { S e P } + \left( L _ { G } + L _ { C M D } \right) \tag{22} LT(θtrans )=LSeP+(LG+LCMD)(22)
最优化方法 Optimization
- 使用 Adam 随机梯度下降法作为全程的优化器
- 使用式(16)中的 L I A M L m L^{m}_{IAML} LIAMLm 预训练草图和3D图形的 CNN 度量网络
- 通过最小化式(19)和式(20)的 L T L_{T} LT 和 L D L_{D} LD 预训练跨模态转换网络
- 通过最小化 L I A M L 1 L^{1}_{IAML} LIAML1、 L I A M L 2 L^{2}_{IAML} LIAML2、 L T L_{T} LT 和 L D L_{D} LD 分别更新 { θ C N N 1 , θ m e t r i c 1 } \{ \theta^{1}_{CNN},\theta^{1}_{metric} \} {θCNN1,θmetric1}、 { θ C N N 2 , θ m e t r i c 2 } \{ \theta^{2}_{CNN},\theta^{2}_{metric} \} {θCNN2,θmetric2}、 θ t r a n s \theta_{trans} θtrans 和对抗判别器 D D D
2018ACMMM-Unsupervised Learning of 3D Model Reconstruction from Hand-Drawn Sketches
@inproceedings{wang2018unsupervised,
title={Unsupervised learning of 3d model reconstruction from hand-drawn sketches},
author={Wang, Lingjing and Qian, Cheng and Wang, Jifei and Fang, Yi},
booktitle={Proceedings of the 26th ACM international conference on Multimedia},
pages={1820--1828},
year={2018}
}
基于手绘草图三维模型重建的无监督学习 Unsupervised Learning of 3D Model Reconstruction from Hand-Drawn Sketches
- 通过带有对抗损失的自动编码器训练一个适应网络,将未配对的2D渲染图像域与手绘草图域嵌入到共享的隐藏向量空间
- 从嵌入的隐藏空间中,对于每个测试草图图像,从训练的3D数据集中检索几个(例如5个)最近的邻居,作为3D生成对抗网络的先验知识
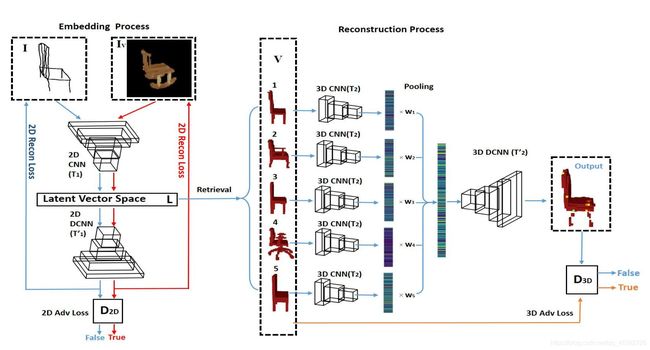
在合成图像域内嵌入手绘草图
生成器 G 2 D G_{2D} G2D 的损失函数:
L G 2 D ( x , v ′ ∣ θ G 2 D ) = ( 1 − ϕ 2 D ) [ L R E C 2 D ( x ) + L R E C 2 D ( v ′ ) ] + ϕ 2 D L A D V 2 D ( T 1 ′ T 1 ( x ) ) ) \begin{aligned} L _ { G _ { 2 D } } \left( x , v ^ { \prime } \mid \theta _ { G _ { 2 D } } \right) & = \left( 1 - \phi _ { 2 D } \right) \left[ L _ { R E C _ { 2 D } } ( x ) + L _ { R E C _ { 2 D } } \left( v ^ { \prime } \right) \right] \left. + \phi _ { 2 D } L _ { A D V _ { 2 D } } \left( T _ { 1 } ^ { \prime } T _ { 1 } ( x ) \right) \right) \end{aligned} LG2D(x,v′∣θG2D)=(1−ϕ2D)[LREC2D(x)+LREC2D(v′)]+ϕ2DLADV2D(T1′T1(x)))
其中, ϕ 2 D \phi _ { 2 D } ϕ2D 是用于平衡2D重构损失和2D对抗损失的超参数, T 1 T_{1} T1 和 T 1 ′ T^{\prime}_{1} T1′ 分别为编码器和解码器
2D重构损失为:
L R E C 2 D ( v ∣ θ G 2 D ) = ∥ T 1 ′ T 1 ( v ) − v ∥ 1 , ∀ v ∈ I ∪ I V (23) L _ { R E C _ { 2 D } } \left( v \mid \theta _ { G _ { 2 D } } \right) = \left\| T _ { 1 } ^ { \prime } T _ { 1 } ( v ) - v \right\| _ { 1 } , \forall v \in I \cup I _ { V } \tag{23} LREC2D(v∣θG2D)=∥T1′T1(v)−v∥1,∀v∈I∪IV(23)
2D对抗损失为:
L A D V 2 D ( v ∣ θ D 2 D ) = ∥ v − D 2 D ( v ) ∥ 1 , ∀ v ∈ T 1 ′ T 1 ( I ) ∪ T 1 ′ T 1 ( I V ) (24) L _ { A D V _ { 2 D } } \left( v \mid \theta _ { D _ { 2 D } } \right) = \left\| v - D _ { 2 D } ( v ) \right\| _ { 1 } , \forall v \in T _ { 1 } ^ { \prime } T _ { 1 } ( I ) \cup T _ { 1 } ^ { \prime } T _ { 1 } \left( I _ { V } \right) \tag{24} LADV2D(v∣θD2D)=∥v−D2D(v)∥1,∀v∈T1′T1(I)∪T1′T1(IV)(24)
从共享的隐藏向量空间中检索渲染的图像
-
从训练集中的所有特征向量 z v j , k ′ z_{v^{ \prime }_{j,k}} zvj,k′中找到特征向量 z x i z_{x_{i}} zxi的几个邻居,即在嵌入后从渲染的图像中找到草图图像的邻居,距离使用欧氏距离
-
检索 K K K 个最近邻居(本文中为 5 个) z v j , k ′ z_{v^{ \prime }_{j,k}} zvj,k′,分别对应在空间 I V I_{V} IV 中的渲染图像 v j , k ′ v^{ \prime }_{j,k} vj,k′,然后定位他们在空间 V V V 中对应的3D对象 v j v_{j} vj
用于具有池化层的对象重建的 3D-GANS
-
生成器 G 3 D G_{3D} G3D
自编码器 T 2 T_{2} T2:拥有 200 维的瓶颈层,将 32 × 32 × 32 32 \times 32 \times 32 32×32×32 维的3D对象编码转换为 200 维的特征向量
池化层:生成器 G 3 D G_{3D} G3D 将 K K K 个选取的3D对象考虑为一个整体来看待,将每个对象乘以权重得到特征向量 w = ∑ i = 1 K w i z v i w={\sum}^{K}_{i=1}w_{i}z_{v_{i}} w=∑i=1Kwizvi(例如 K = 5 K=5 K=5 时,权重分别为 0.5 , 0.4 , 0.3 , 0.2 , 0.1 0.5,0.4,0.3,0.2,0.1 0.5,0.4,0.3,0.2,0.1,保证了最近邻可以得到更高的关注同时又不会丢失其他邻居的信息)
解码器 T 2 ′ T^{ \prime }_{2} T2′ :将 200 维的特征向量还原回 32 × 32 × 32 32 \times 32 \times 32 32×32×32 维的3D对象。将池化后的特征向量 w w w 输入解码器 T 2 ′ T^{ \prime }_{2} T2′ 将得到重建的3D对象 v O U T v_{OUT} vOUT
-
判别器 D 3 D D_{3D} D3D
区分3D输出对象是否跟真实的3D空间 V V V 内的对象高度相似,若是则将其判定为"true",否则认为其是由池化后的特征向量 w w w 生成的,将其判定为"false"
生成器和判别器的损失函数为:
L G 3 D ( v O U T , v ∣ θ G 3 D ) = ( 1 − ϕ 3 D ) [ L R E C 3 D ( v O U T ) + L R E C 3 D ( v ) ] + ϕ 3 D L A D V 3 D ( v O U T ) (25) L _ { G _ { 3 D } } \left( v _ { O U T } , v \mid \theta _ { G _ { 3 D } } \right) = \left( 1 - \phi _ { 3 D } \right) \left[ L _ { R E C _ { 3 D } } \left( v _ { O U T } \right) + L _ { R E C _ { 3 D } } ( v ) \right] + \phi _ { 3 D } L _ { A D V _ { 3 D } } \left( v _ { O U T } \right) \tag{25} LG3D(vOUT,v∣θG3D)=(1−ϕ3D)[LREC3D(vOUT)+LREC3D(v)]+ϕ3DLADV3D(vOUT)(25)
L D 3 D ( v O U T , v ∣ θ D 3 D ) = L A D V 3 D ( v ) − k 3 D t L A D V 3 D ( T 2 ′ T 2 ( v O U T ) ) (26) L _ { D _ { 3 D } } \left( v _ { O U T } , v \mid \theta _ { D _ { 3 D } } \right) = L _ { A D V _ { 3 D } } ( v ) - k _ { 3 D _ { t } } L _ { A D V _ { 3 D } } \left( T _ { 2 } ^ { \prime } T _ { 2 } \left( v _ { O U T } \right) \right) \tag{26} LD3D(vOUT,v∣θD3D)=LADV3D(v)−k3DtLADV3D(T2′T2(vOUT))(26)
3D重构损失为:
L R E C 3 D ( v ∣ θ G 3 D ) = ∥ T 2 ′ ( T 2 ( v ) ) − v ∥ 1 (27) L _ { R E C _ { 3 D } } \left( v \mid \theta _ { G _ { 3 D } } \right) = \left\| T _ { 2 } ^ { \prime } \left( T _ { 2 } ( v ) \right) - v \right\| _ { 1 } \tag{27} LREC3D(v∣θG3D)=∥T2′(T2(v))−v∥1(27)
3D对抗损失为:
L A D V 3 D ( v ∣ θ D 3 D ) = ∥ v − D 3 D ( v ) ∥ 1 (28) L _ { A D V _ { 3 D } } \left( v \mid \theta _ { D _ { 3 D } } \right) = \left\| v - D _ { 3 D } ( v ) \right\| _ { 1 } \tag{28} LADV3D(v∣θD3D)=∥v−D3D(v)∥1(28)
2020ICME-Cross-Modal Guidance Network For Sketch-Based 3d Shape Retrieval
@inproceedings{dai2020cross,
title={Cross-Modal Guidance Network For Sketch-Based 3d Shape Retrieval},
author={Dai, Weidong and Liang, Shuang},
booktitle={2020 IEEE International Conference on Multimedia and Expo (ICME)},
pages={1--6},
year={2020},
organization={IEEE}
}
跨模态引导网络 Cross-modal Guidance Network (CGN)
- 训练教师网络学习3D图形特征,在预学习的特征空间的引导下,学生网络学习得到将草图特征转换到3D特征的映射
- 第一步:采用多视点方法提取特征,将3D图形渲染为 V V V 视图,然后通过 CNN-2,各个CNN-2共享相同的参数,然后用平均池化融合 CNN-2 输出的特征,用 AM-softmax作为网络的损失函数。AM-softmax 可以增大类间余弦距离,减小类内余弦距离。训练完成后,3D训练数据经过 FCN-2后提取特征,得到预学习的3D形状特征空间,最后通过计算同一类特征的平均值得到类中心
- 第二步:在3D图形预学习类中心的引导下,学生网络(即转换网络),在引导损失函数的监督下,将草图特征转换到预学习的特征空间
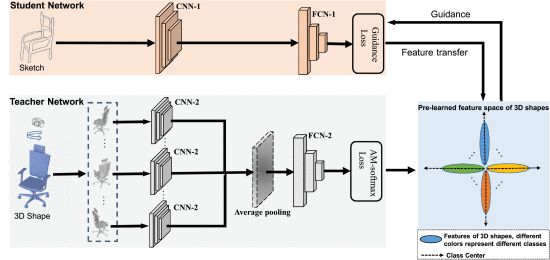
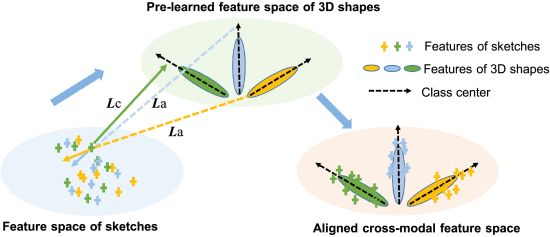
引导损失函数
将草图的特征转换到预学习的3D图形特征空间,同时需要确保草图特征与具有相同语义信息的类中心对齐
损失函数:
L G = L c − λ L a (29) {L}_{G}={L}_{c}-\lambda \mathrm{L}_{a} \tag{29} LG=Lc−λLa(29)
L c L_{c} Lc 是同一类中草图特征与预学习的3D图形类中心的余弦距离,即
L c = 1 M ∑ i = 1 M f i ⋅ c y i ∥ f i ∣ ∣ 2 ∥ c y i ∥ 2 (30) {L}_{\mathrm{c}}=\frac{1}{M}\sum_{i=1}^{M}\frac{\mathrm{f}_{i}\cdot \mathrm{c}_{y^{i}}}{\Vert \mathrm{f}_{i}||_{2}\Vert \mathrm{c}_{y^{i}}\Vert_{2}} \tag{30} Lc=M1i=1∑M∥fi∣∣2∥cyi∥2fi⋅cyi(30)
L a L_{a} La 是草图特征与其他3D图形类中心的余弦距离之和,即
L a = 1 M ∑ i = 1 M ∑ j = 1 , j ≠ y i N f i ⋅ c j ∥ f i ∣ ∣ 2 ∥ c j ∥ 2 (31) {L}_{\mathrm{a}}=\frac{1}{M}\sum_{i=1}^{M}\sum_{j=1,j\neq y^{i}}^{N}\frac{\mathrm{f}_{i}\cdot \mathrm{c}_{j}}{\Vert \mathrm{f}_{i}||_{2}\Vert \mathrm{c}_{j}\Vert_{2}}\tag{31} La=M1i=1∑Mj=1,j=yi∑N∥fi∣∣2∥cj∥2fi⋅cj(31)
λ \lambda λ 是平衡 L c L_{c} Lc 和 L a L_{a} La 的超参数, M M M 是 mini-batch 的大小, N N N 是类别数量, f i f_{i} fi 表示草图特征向量, y i y_{i} yi 表示第 i i i 个样本的标签, { c 1 , c 2 , c N } \{ c_{1},c_{2},c_{N} \} {c1,c2,cN} 是预学习的3D图形的类中心向量
如下图,引导损失函数旨在将草图的特征向同类3D图形的类中心聚类,同时使特征远离不同类的中心,实现了跨模态的语义对齐,减少了2D草图和3D图形之间的跨模态差异
2020CVIU-Open Cross-Domain Visual Search
@article{2020Open,
title={Open cross-domain visual search},
author={ Thong, W. and Mettes, P. and Snoek, Cgm },
journal={Computer Vision and Image Understanding},
pages={103045},
year={2020},
}
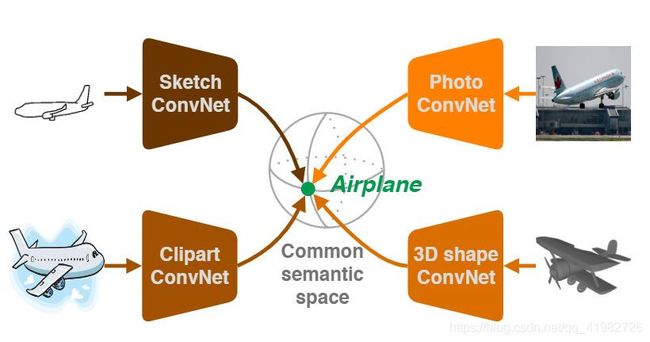
开放跨域视觉搜索 Open Cross-Domain Visual Search
可以输入任意域的数据,同时查询任意域的数据
为每个模态设计一个转换函数,将草图 sketch、自然图像 image 和3D图形的特征全部转移到一个共享的语义空间,在语义空间内执行原型学习 Prototype learning (有点像聚类)
对于一些 unseen 的类别,也可以有高于 baseline 的测试结果,即零次学习 zero-shot learning 任务也可以有不错的结果
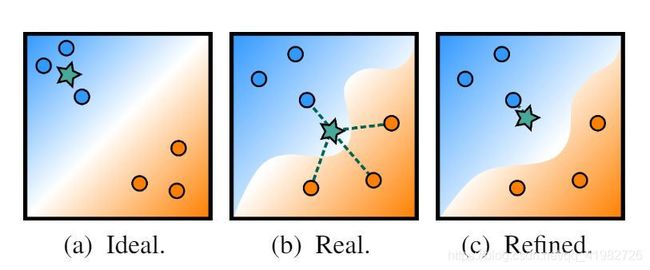
如下图,绿色星星代表输入的查询:
-
a) 理想情况下,查询的邻居仅与同一类别的实例接近
-
b) 在现实中,变异性 variability 在语义空间中引起了噪声。因此,查询也可能会丢失到其他类别的样本中
-
c) 通过改进查询表示来解决这种变异性:拉近查询与其最近邻的距离来修正结果
2018ECCV-Generative Domain-Migration Hashing for Sketch-to-Image Retrieval
@article{2018Generative,
title={Generative Domain-Migration Hashing for Sketch-to-Image Retrieval},
author={ Zhang, J. and Shen, F. and Liu, L. and Zhu, F. and Yu, M. and Shao, L. and Shen, H. T. and Gool, L. V. },
journal={Springer, Cham},
year={2018},
}
生成域迁移的哈希算法 Generative Domain-Migration Hashing
从由草图迁移过来的自然图像中生成哈希代码
- 生成器 G I G_{I} GI 和 G S G_{S} GS :两个并行的生成 CNNs 网络,分别完成从草图到自然图像和从自然图像到草图的生成工作
- 判别器 D S D_{S} DS 和 D I D_{I} DI:分别判定生成的自然图像和草图与真实样本的差异
- 哈希网络 H H H:将由判别器生成的草图和图像转换为二进制的哈希编码,并且可以基于带掩码的真实图像 ( I ⊙ m a s k ) (I\odot mask) (I⊙mask) 和生成的图像 G I ( S ) G_{I}(S) GI(S) 进行训练
- 损失函数:基于三元组损失
@article{2018Generative,
title={Generative Domain-Migration Hashing for Sketch-to-Image Retrieval},
author={ Zhang, J. and Shen, F. and Liu, L. and Zhu, F. and Yu, M. and Shao, L. and Shen, H. T. and Gool, L. V. },
journal={Springer, Cham},
year={2018},
}
生成域迁移的哈希算法 Generative Domain-Migration Hashing
从由草图迁移过来的自然图像中生成哈希代码
- 生成器 G I G_{I} GI 和 G S G_{S} GS :两个并行的生成 CNNs 网络,分别完成从草图到自然图像和从自然图像到草图的生成工作
- 判别器 D S D_{S} DS 和 D I D_{I} DI:分别判定生成的自然图像和草图与真实样本的差异
- 哈希网络 H H H:将由判别器生成的草图和图像转换为二进制的哈希编码,并且可以基于带掩码的真实图像 ( I ⊙ m a s k ) (I\odot mask) (I⊙mask) 和生成的图像 G I ( S ) G_{I}(S) GI(S) 进行训练
- 损失函数:基于三元组损失
