【机器学习】欠拟合及过拟合与学习曲线、误差来源
模型训练导航:
【机器学习】模型训练:scikitLearn线性模型的公式法与三种梯度下降法求解
【机器学习】scikitLearn正则化l1,l2,提前停止
【机器学习】逻辑回归logit与softmax
学习曲线
在固定模型的情况下,通过逐步增加训练集的数据数目,绘制训练集和数据集上的均方误曲线,为学习曲线,其代码如下:
这里的数据是由二次多项式加噪声生成的,所选模型为简单的线性模型:
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split
def plot_learning_curves(model, X, y):
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, random_state=10)
train_errors, val_errors = [], []
for m in range(1, len(X_train) + 1):
model.fit(X_train[:m], y_train[:m])
y_train_predict = model.predict(X_train[:m])
y_val_predict = model.predict(X_val)
train_errors.append(mean_squared_error(y_train[:m], y_train_predict))
val_errors.append(mean_squared_error(y_val, y_val_predict))
plt.plot(np.sqrt(train_errors), "r-+", linewidth=2, label="train")
plt.plot(np.sqrt(val_errors), "b-", linewidth=3, label="val")
plt.legend(loc="upper right", fontsize=14) # not shown in the book
plt.xlabel("Training set size", fontsize=14) # not shown
plt.ylabel("RMSE", fontsize=14) # not shown
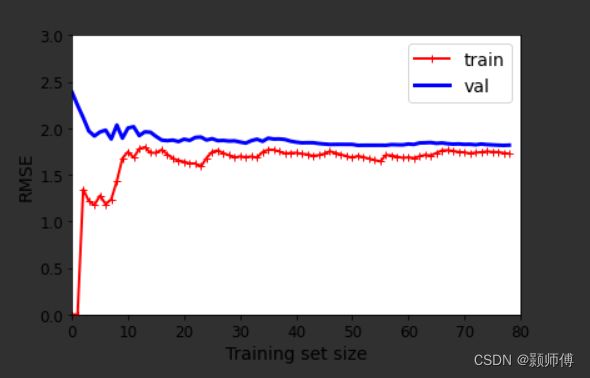
如图所示,当参与训练的数据量很小的时候,模型可以轻易拟合训练集,但是对于测试集,呈现欠拟合装。随着数据量增大,由曲线可知,训练集误差上升后稳定,测试集误差下降后稳定。
显而易见,继续增大训练集的尺寸,无法进一步缩小验证集上的误差。这是由于模型自身局限性引起的。
进一步,训练集及验证集误差接近,均不为0,体现了一种由模型自身局限性引起的欠拟合状态。
下面使用10阶多项式模型,继续绘制上述曲线,代码如下:
from sklearn.pipeline import Pipeline
polynomial_regression = Pipeline([
("poly_features", PolynomialFeatures(degree=10, include_bias=False)),
("lin_reg", LinearRegression()),
])
plot_learning_curves(polynomial_regression, X, y)
plt.axis([0, 80, 0, 3]) # not shown
save_fig("learning_curves_plot") # not shown
plt.show()
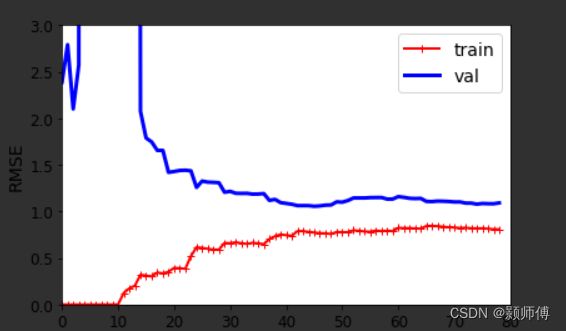
首先,相对于线性模型,训练集上模型目前的误差更小了;平稳时最小误差的大小,是由模型的选型决定的。
但是应注意到,验证集和训练集曲线间还有相当的距离,而两者的模型是一致的,这反映出过拟合的特性,因为数据量的差异,使得相同模型在训练集和验证集上的误差有较大差异,当继续增加数据集数量时,两条曲线会继续接近,直到接近重合。
即,对于过拟合的模型,增加数据集数量,可以进一步减少模型误差。
误差来源
误差来源分为3个部分:
1.偏差,就是模型选型带来的误差,最易造成欠拟合的情况。
2.方差,模型对数据的细微变化过于敏感,一般特征越多的模型,其可能的方差越大,倾向于过拟合数据。
3.不可避免的误差:数据自带的噪声,可通过清理数据,做异常值检测消除。