Halcon 深度学习之语义分割 预处理 案例解析
语义分割 预处理
文章目录
- 语义分割 预处理
- 前言
- 一、预处理的目的是什么?
-
- 1、设置图像预处理的参数,此部分参数后续会写入到训练模型当中,具体参数信息如下图
- 2、得到语义分割的文件,用于后续的训练当中,语义分割可通过多种方式生成
- 二、案例分块解析
-
- 1.案例说明部分,可跳过
- 2.设置深度学习模型文件的路径,其为相对路径的方式
- 3.预处理参数的设置
- 4.导出语义分割文件与保存预处理文件
- 5.从训练集当中,随机抽取十张查看预处理效果
- 6.附个人注释的代码
- 个人总结
前言
声明:本篇是个人针对于语义分割预处理案例的理解,有理解不到位或者错误的地方,还望各位能够给予指正,在此表示感谢!
例子名称: segment_pill_defects_deep_learning_1_preprocess
一、预处理的目的是什么?
1、设置图像预处理的参数,此部分参数后续会写入到训练模型当中,具体参数信息如下图
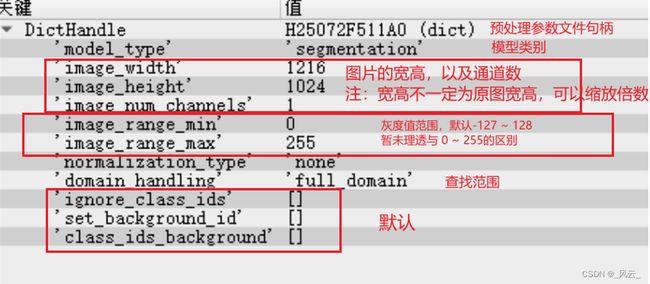
2、得到语义分割的文件,用于后续的训练当中,语义分割可通过多种方式生成
①:导入原图文件夹,标注文件夹,类别信息等
②:通过Deep Learning Tool 工具创建的语义分割文件【内部的信息也跟①的一样】
②:通过Deep Learning Tool工具创建的语义分割分拣,所导出的数据集文件.hdict【内部的信息也跟①方式生成的一样】
语义分割文件参数具体如下图
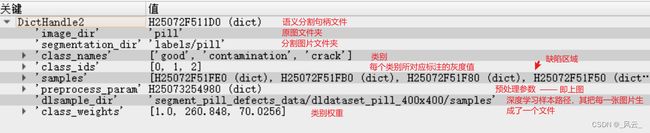
二、案例分块解析
1.案例说明部分,可跳过
* 一 :显示该例子介绍信息
ShowExampleScreens := false
dev_example_init (ShowExampleScreens, ExampleInternals)
*
if (ShowExampleScreens)
*
* Introduction text of example series.
dev_display_screen_introduction_part_1 (ExampleInternals)
stop ()
dev_display_screen_introduction_part_2 (ExampleInternals)
stop ()
*
* Explain semantic segmentation data.
dev_display_screen_segmentation_data (ExampleInternals)
stop ()
*
* Explain splitting the dataset.
dev_display_screen_split_dataset (ExampleInternals)
stop ()
*
* Explain preprocessing parameters.
dev_display_screen_preprocessing_params (ExampleInternals)
stop ()
dev_display_screen_weight_images (ExampleInternals)
stop ()
*
* Explain the next steps.
dev_display_screen_next_steps (ExampleInternals)
stop ()
endif
2.设置深度学习模型文件的路径,其为相对路径的方式
* 原图像目录
ImageDir := 'pill'
* 分割图像存放文件夹,即标注的缺陷区域
SegmentationDir := 'labels/pill'
* 生成文件的根目录
ExampleDataDir := 'segment_pill_defects_data'
DataDirectoryBaseName := ExampleDataDir + '/dldataset_pill_'
* 模型预处理参数的文件名
PreprocessParamFileBaseName := '/dl_preprocess_param.hdict'
注:后续读取的算子
*读取分割模型数据集 (原图像目录,标注的缺陷目录, 标注类别),类别对应ID)
* DLDataset 实际上Deep Lerning Tool 创建的标注文件.hdict
read_dl_dataset_segmentation (ImageDir, SegmentationDir, ClassNames, ClassIDs, [], [], [], DLDataset)
3.预处理参数的设置
* 缺陷标签类别:好的,脏污,断裂
ClassNames := ['good','contamination','crack']
* 相应的标注序号,即灰度值索引
ClassIDs := [0,1,2]
* 拆分数据集的百分比 训练百分之70 确认百分之15【即每学习一段时间后,从此部分抽出一些进行识别验证,判断学习的准确程度】
TrainingPercent := 70
ValidationPercent := 15
*设置预处理图片的相应信息, 图片尺寸,图片彩色——
*①、此处可对图片进行压缩,
*②、但后续图像进行推理的时候,也需要对原图进行相应的压缩,不然推理的缺陷区域会与原图缺陷区域对应不上。
*③、图片越大相应的硬件要求也高一些
ImageWidth := 400
ImageHeight := 400
ImageNumChannels := 3
* 设置图片灰度值的范围,范围是-127到128,即为byte,有疑问
ImageRangeMin := -127
ImageRangeMax := 128
*设置进一步预处理的相应参数
*正常化参数,暂不明其意
NormalizationType := 'none'
*域处理参数,full_domain 即所操作的范围为全图
DomainHandling := 'full_domain'
IgnoreClassIDs := []
SetBackgroundID := []
ClassIDsBackground := []
注:后续设置的算子
*创建预处理模型参数(语义分割,图像宽,高,通道数,最低灰度值,最高灰度值,正常化参数,操作区域范围,图像背景信息[],[],[],[],out 预处理参数句柄)
create_dl_preprocess_param ('segmentation', ImageWidth, ImageHeight, ImageNumChannels, ImageRangeMin, ImageRangeMax, NormalizationType, DomainHandling, IgnoreClassIDs, SetBackgroundID, ClassIDsBackground, [], DLPreprocessParam)
*
4.导出语义分割文件与保存预处理文件
*创建一个空字典
create_dict (GenParam)
*是否覆盖文件
set_dict_tuple (GenParam, 'overwrite_files', true)
*预处理模型数据集 导出语义分割文件 即DLDatasetFilename
*将每张图片结合标注的信息,以及缺陷的权重,以hdict文件的格式记录,每张图片对应一个hdict【可不需要】,。。。。。。
preprocess_dl_dataset (DLDataset, DataDirectory, DLPreprocessParam, GenParam, DLDatasetFilename)
PreprocessParamFile := DataDirectory + PreprocessParamFileBaseName
*将当前的句柄保存下来,即保存当前预处理的相关参数
write_dict (DLPreprocessParam, PreprocessParamFile, [], [])
5.从训练集当中,随机抽取十张查看预处理效果
get_dict_tuple (DLDataset, 'samples', DatasetSamples)
*找出训练的数据集
find_dl_samples (DatasetSamples, 'split', 'train', 'match', SampleIndices)
*将数组打散随机,然后将打散后的数组取前十个
tuple_shuffle (SampleIndices, ShuffledIndices)
read_dl_samples (DLDataset, ShuffledIndices[0:9], DLSampleBatchDisplay)
*
create_dict (WindowHandleDict)
for Index := 0 to |DLSampleBatchDisplay| - 1 by 1
* Loop over samples in DLSampleBatchDisplay.
dev_display_dl_data (DLSampleBatchDisplay[Index], [], DLDataset, ['image','segmentation_image_ground_truth'], [], WindowHandleDict)
get_dict_tuple (WindowHandleDict, 'segmentation_image_ground_truth', WindowHandleImage)
dev_set_window (WindowHandleImage[1])
Text := 'Press Run (F5) to continue'
dev_disp_text (Text, 'window', 400, 40, 'black', [], [])
stop ()
endfor
6.附个人注释的代码
*
* This example is part of a series of examples, which summarizes
* the workflow for DL segmentation. It uses the MVTec pill dataset.
*
* The four parts are:
* 1. Dataset preprocessing. 预处理:数据集预处理
* 2. Training of the model. 训练:模型的训练
* 3. Evaluation of the trained model. 评估:对训练模型的评估
* 4. Inference on new images. 推理:对新图像的推断
*
* 第一部分:数据预处理
*
dev_update_off ()
* 一 :显示该例子介绍信息
ShowExampleScreens := false
dev_example_init (ShowExampleScreens, ExampleInternals)
*
if (ShowExampleScreens)
*
* Introduction text of example series.
dev_display_screen_introduction_part_1 (ExampleInternals)
stop ()
dev_display_screen_introduction_part_2 (ExampleInternals)
stop ()
*
* Explain semantic segmentation data.
dev_display_screen_segmentation_data (ExampleInternals)
stop ()
*
* Explain splitting the dataset.
dev_display_screen_split_dataset (ExampleInternals)
stop ()
*
* Explain preprocessing parameters.
dev_display_screen_preprocessing_params (ExampleInternals)
stop ()
dev_display_screen_weight_images (ExampleInternals)
stop ()
*
* Explain the next steps.
dev_display_screen_next_steps (ExampleInternals)
stop ()
endif
*二:设置深度学习模型文件的路径,其为相对路径的方式
* 原图像目录
ImageDir := 'pill'
* 分割图像存放文件夹,即标注的缺陷区域
SegmentationDir := 'labels/pill'
* 生成文件的根目录
ExampleDataDir := 'segment_pill_defects_data'
DataDirectoryBaseName := ExampleDataDir + '/dldataset_pill_'
* 模型预处理参数的文件名
PreprocessParamFileBaseName := '/dl_preprocess_param.hdict'
* 三:设置训练的相应参数
* 缺陷标签类别:好的,脏污,断裂
ClassNames := ['good','contamination','crack']
* 相应的标注序号,即灰度值索引
ClassIDs := [0,1,2]
* 拆分数据集的百分比 训练百分之70 确认百分之15【即每学习一段时间后,从此部分抽出一些进行识别验证,判断学习的准确程度】
TrainingPercent := 70
ValidationPercent := 15
*设置预处理图片的相应信息, 图片尺寸,图片彩色——
*①、此处可对图片进行压缩,
*②、但后续图像进行推理的时候,也需要对原图进行相应的压缩,不然推理的缺陷区域会与原图缺陷区域对应不上。
*③、图片越大相应的硬件要求也高一些
ImageWidth := 400
ImageHeight := 400
ImageNumChannels := 3
* 设置图片灰度值的范围,范围是-127到128,即为byte,有疑问
ImageRangeMin := -127
ImageRangeMax := 128
*设置进一步预处理的相应参数
*正常化参数,暂不明其意
NormalizationType := 'none'
*域处理参数,full_domain 即所操作的范围为全图
DomainHandling := 'full_domain'
IgnoreClassIDs := []
SetBackgroundID := []
ClassIDsBackground := []
*
*设置一个随机种子,不设置的话会已当前时间段生成一个随机种子,具体干嘛的暂无感触
SeedRand := 42
set_system ('seed_rand', SeedRand)
*四:读取分割数据集,并设置相应好坏种类的比例
* Read the dataset.
*读取分割模型数据集 (原图像目录,标注的缺陷目录, 标注类别),类别对应ID), DLDataset 分割数据集的句柄,记录着传进来的各种参数信息
* DLDataset 实际上Deep Lerning Tool 创建的标注文件.hdict
read_dl_dataset_segmentation (ImageDir, SegmentationDir, ClassNames, ClassIDs, [], [], [], DLDataset)
*生成拆分数据集, 训练的70 确认的15,要额外设置
split_dl_dataset (DLDataset, TrainingPercent, ValidationPercent, [])
*判断一下相应路径是否存在,如果不存在的话,则新建路径
file_exists (ExampleDataDir, FileExists)
if (not FileExists)
*后续会在此目录下生成每张图片的hdict文件,里面记录着图片的尺寸信息,分割区域,推断区域等,详情见图
make_dir (ExampleDataDir)
endif
*创建预处理模型参数(语义分割,图像宽,高,通道数,最低灰度值,最高灰度值,正常化参数,操作区域范围,图像背景信息[],[],[],[],out 预处理参数句柄)
create_dl_preprocess_param ('segmentation', ImageWidth, ImageHeight, ImageNumChannels, ImageRangeMin, ImageRangeMax, NormalizationType, DomainHandling, IgnoreClassIDs, SetBackgroundID, ClassIDsBackground, [], DLPreprocessParam)
*
* Dataset directory for any outputs written by preprocess_dl_dataset.
DataDirectory := DataDirectoryBaseName + ImageWidth + 'x' + ImageHeight
*
*创建一个空字典
create_dict (GenParam)
*是否覆盖文件
set_dict_tuple (GenParam, 'overwrite_files', true)
*预处理模型数据集 生成语义分割文件 即DLDatasetFilename
*将每张图片结合标注的信息,以及缺陷的权重,以hdict文件的格式记录,每张图片对应一个hdict【可不需要】,。。。。。。
preprocess_dl_dataset (DLDataset, DataDirectory, DLPreprocessParam, GenParam, DLDatasetFilename)
*
* Store preprocess params separately in order to use it e.g. during inference.
PreprocessParamFile := DataDirectory + PreprocessParamFileBaseName
*将当前的句柄保存下来,即保存当前预处理的相关参数
write_dict (DLPreprocessParam, PreprocessParamFile, [], [])
*五: 验证,实时反馈
get_dict_tuple (DLDataset, 'samples', DatasetSamples)
*找出训练的数据集
find_dl_samples (DatasetSamples, 'split', 'train', 'match', SampleIndices)
*将数组打散随机,然后将打散后的数组取前十个
tuple_shuffle (SampleIndices, ShuffledIndices)
read_dl_samples (DLDataset, ShuffledIndices[0:9], DLSampleBatchDisplay)
*
create_dict (WindowHandleDict)
for Index := 0 to |DLSampleBatchDisplay| - 1 by 1
* Loop over samples in DLSampleBatchDisplay.
dev_display_dl_data (DLSampleBatchDisplay[Index], [], DLDataset, ['image','segmentation_image_ground_truth'], [], WindowHandleDict)
get_dict_tuple (WindowHandleDict, 'segmentation_image_ground_truth', WindowHandleImage)
dev_set_window (WindowHandleImage[1])
Text := 'Press Run (F5) to continue'
dev_disp_text (Text, 'window', 400, 40, 'black', [], [])
stop ()
endfor
*
* Close windows that have been used for visualization.
dev_close_window_dict (WindowHandleDict)
*
if (ShowExampleScreens)
* Hint to the DL segmentation training process example.
dev_display_screen_next_example (ExampleInternals)
stop ()
* Close example windows.
dev_close_example_windows (ExampleInternals)
endif
个人总结
预处理这块的代码量虽然很多,但大多数是用于介绍等,实际上,当有标注好的文件,在设置上图像的一些信息
如:图像宽度,高度,通道,训练的模式【CPU || GPU】 训练集与验证集的比例,缺陷放大的权重参数,即可完成图像预处理
个人也是刚刚接触的深度学习这块,总结不到位或者理解错误的地方,希望各位能够给予指正,再次感谢大家!