sklearn 之决策树与回归树
造树部分
代码
from sklearn import tree #导入需要的模块
clf = tree.DecisionTreeClassifier() #实例化
clf = clf.fit(X_train,y_train) #用训练集数据训练模型
result = clf.score(X_test,y_test) #导入测试集,从接口中调用需要的信息
#### 决策树参数
基本参数
random_state用来设置分枝中的随机模式的参数,默认None,在高维度时随机性会表现更明显,低维度的数据(比如鸢尾花数据集),随机性几乎不会显现。输入任意整数,会一直长出同一棵树,让模型稳定下来。
splitter也是用来控制决策树中的随机选项的,有两种输入值,输入”best",决策树在分枝时虽然随机,但是还是会优先选择更重要的特征进行分枝(重要性可以通过属性feature_importances_查看),输入“random",决策树在分枝时会更加随机,树会因为含有更多的不必要信息而更深更大,并因这些不必要信息而降低对训练集的拟合。这也是防止过拟合的一种方式。当你预测到你的模型会过拟合,用这两个参数来帮助你降低树建成之后过拟合的可能性。当然,树一旦建成,我们依然是使用剪枝参数来防止过拟合。
重要参数
Criterion : entropy(信息熵) gini 基尼系数
random_state:随机种子,默认为none
splitter: ”best",决策树在分枝时虽然随机,但是还是会优先选择更重要的特征进行分枝.
输入“random",决策树在分枝时会更加随机,树会因为含有更多的不必要信息而更深更大,并因这些不必要信息而降低对训练集的拟合。这也是防止过拟合的一种方式。
max_depth:最大深度,建议从3开始
min_samples_leaf 一个节点在分枝后的每个子节点都必须包含至少min_samples_leaf个训练样本,否则分枝就不会发生(对于类别不多的分类问题,取1;一般问题取5)
min_samples_split 一个节点必须要包含至少min_samples_split个训练样本
重要属性
feature_importances_ 能够查看各个特征对模型的重要性。
重要接口
fit 拟合参数
score 查看模型的准确度
apply 中输入测试集返回每个测试样本所在的叶子节点的索引。
predict 输入测试集返回每个测试样本的标签。
画树部分
tree.export_graphviz 可视化函数
feature_names #特征名称
class_names= #分类名
filled #颜色填充
rounded #边框为园
graph=graphviz.Source() 画树
例子:
import graphviz
dot_data = tree.export_graphviz(clf
,feature_names = feature_name
,class_names=["琴酒","雪莉","贝尔摩德"]
,filled=True
,rounded=True
)
graph = graphviz.Source(dot_data)
进阶部分
网格搜索
用于选取最好的参数。
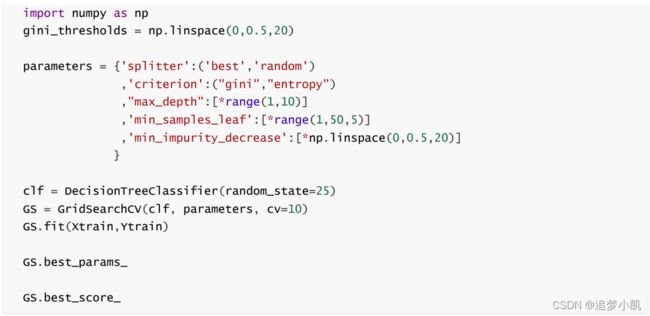
交叉验证
可以防止模型受数据集选取的影响过大

注意事项
所有接口中要求输入X_train和X_test的部分,输入的特征矩阵必须至少是一个二维矩阵。sklearn不接受任何一维矩阵作为特征矩阵被输入。(可以使用reshape(1,-1) 进行升维)
数据的使用
建议使用官方的红酒数据库
from sklearn.datasets import load_wine
wine=load_wine()
data=wine.data
target=wine.target