decaNLP-一个可以同时处理机器翻译、问答、摘要、文本分类、情感分析等十项自然语言任务的通用模型
https://blog.csdn.net/wenyusuran/article/details/80810804
https://zhuanlan.zhihu.com/p/38359753
https://einstein.ai/static/images/pages/research/decaNLP/decaNLP.pdf
引言
深度学习已经显著地改善了自然语言处理任务中的最先进的性能,如机器翻译、摘要、问答和文本分类。每一个任务都有一个特定的衡量标准,它们的性能通常是由一组基准数据集测量的。这也促进了专门设计这些任务和衡量标准的体系的发展,但是它可能不会促使那些能够在各种自然语言处理(NLP)任务中表现良好的通用自然语言处理模型的涌现。为了探索这种通用模型的可能性以及在优化它们时产生的权衡关系,我们引入了自然语言十项全能(decaNLP)。
这个挑战涵盖了十个任务:问答、机器翻译、摘要、自然语言推理、情感分析、语义角色标注、关系抽取、任务驱动多轮对话、数据库查询生成器和代词消解。自然语言十项全能(decaNLP)的目标是开发出可以整合所有十个任务的模型,并研究这种模型与那些为单一任务训练而准备的模型有何不同。出于这个原因,十项全能的表现会被一个统一的指标所衡量,该指标集合了所有十项任务的度量标准。
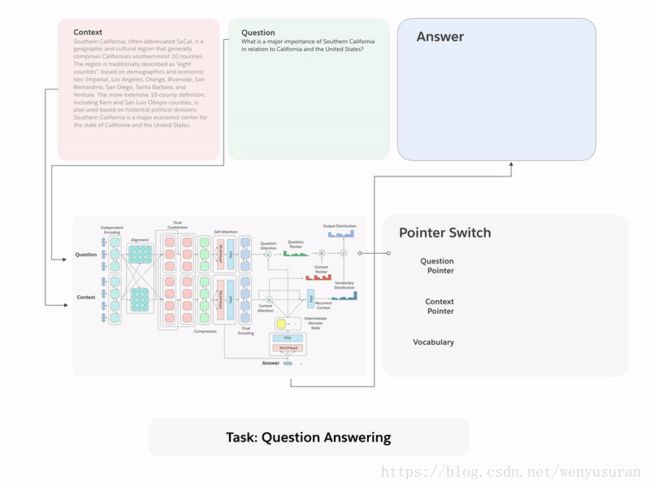
图1.通过将 decaNLP的所有十个任务整合成问答形式,我们可以训练一个通用的问答模型
我们把所有十个任务都统一转化为问答的方式,提出了一个新的多任务问答网络(MQAN),它是一个不需要特定任务的模块或参数而进行共同学习任务的网络。在机器翻译和实体识别命名中,MQAN显示出了迁移学习(Transfer learning)方面的改进。在情感分析和自然语言推理中,MQAN显示出了在领域适应方面的改进,同时对于文本分类方面也显示出了其zero-shot的能力。
在与基线的比较中,我们证明了MQAN的多指针编解码器(multi-pointer-generator decoder)是成功的关键,并且使用相反的训练策略(anti-curriculum training strategy)进一步改进了性能。 尽管该设计用于decaNLP和通用的问答,MQAN恰好也能在单任务设置中表现良好:它在WikiSQL语义解析任务上与单项模型最佳成绩旗鼓相当,任务驱动型对话任务中它排名第二,在SQuAD数据集不直接使用跨监督方法的模型中它得分最高,同时在其他任务中也表现良好。decaNLP的从获取和处理数据、训练和评估模型到复现实验的所有代码已经开源。
任务
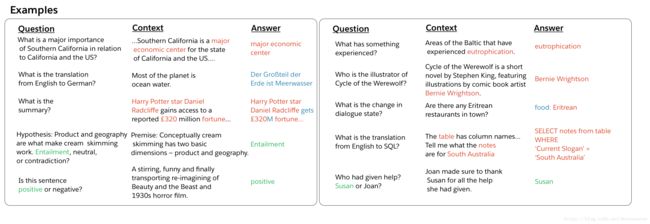
图2.(问题、上下文、答案)问答、机器翻译、摘要、自然语言推理、情感分析、词性标注、关系抽取、目标导向对话、语义解析和代词解析任务的例子
让我们首先开始讨论这些任务及其相关数据集。我们的论文包含更多的细节,包括对每个任务的历史背景和最近的工作进行更深入的讨论。每个任务的输入-输出对示例如上图所示。
问答。问答(QA)模型接收一个问题以及它所包含的必要的信息的上下文来输出理想的答案。我们使用斯坦福问答数据集的原始版本(SQuAD)来完成这项任务。该上下文是从英文维基百科中摘取的段落,答案是从文章中复制的单词序列。
机器翻译。机器翻译模型以源语言文本的形式为输入,输出为翻译好的目标语言。我们使用2016年为国际口语翻译研讨会(IWSLT)准备的英译德数据为训练数据集,使用2013年和2014年的测试集作为验证集和测试集。这些例子来自TED演讲,涵盖了会话语言的各种主题。这是一个相对较小的机器翻译数据集,但是它与其他任务的数据集大致相同。当然你还可以使用额外的训练资源,比如机器翻译大赛(WMT)中的数据集。
摘要。摘要模型接收一个文档并输出该文档的摘要。如今在摘要方面最重要的进展是将CNN/DailyMail (美国有线电视新闻网/每日邮报)语料库转换成一个摘要数据集。我们在decaNLP中包含这个数据集的非匿名版本。平均来讲,这些实例包含了该挑战赛中最长的文档,以及从上下文直接提取答案与语境外生成答案之间平衡的force Model。
自然语言推理。自然语言推理(NLI)模型接受两个输入句子:一个前提和一个假设。模型必须将前提和假设之间的推理关系归类为支持、中立或矛盾。我们使用的是多体裁自然语言推理语料库(MNLI),它提供来自多个领域的训练示例(转录语音、通俗小说、政府报告)和来自各个领域的测试对。
情感分析。情感分析模型被训练用来对输入文本表达的情感进行分类。斯坦福情感树库(SST)由一些带有相应的情绪(积极的,中立的,消极的)的影评所组成。我们使用未解析的二进制版本,以便明确对decaNLP模型的解析依赖。
语义角色标注。语义角色标注(SRL)模型给出一个句子和谓语(通常是一个动词),并且必须确定“谁对谁做了什么”、“什么时候”、“在哪里”。我们使用一个SRL数据集,该数据集将任务视为一种问答:QA-SRL。这个数据集涵盖了新闻和维基百科的领域,但是为了确保decaNLP的所有数据都可以自由下载,我们只使用了后者。
关系抽取。关系抽取系统包含文本文档和要从该文本中提取的关系类型。在这种情况下,模型需要先识别实体间的语义关系,再判断是不是属于目标种类。与SRL一样,我们使用一个数据集,该数据集将关系映射到一组问题,以便关系抽取可以被视为一种问答形式:QA-ZRE。对数据集的评估是为了在新的关系上测量零样本性能——数据集是分开的使得测试时看到的关系在训练时是无法看到的。这种零样本的关系抽取,以问答为框架,可以推广到新的关系之中。
任务驱动多轮对话。对话状态跟踪是任务驱动多轮对话系统的关键组成部分。根据用户的话语和系统动作,对话状态跟踪器会跟踪用户为对话系统设定了哪些事先设定目标,以及用户在系统和用户交互过程中发出了哪些请求。我们使用的是英文版的WOZ餐厅预订服务,它提供了事先设定的关于食物、日期、时间、地址和其他信息的本体,可以帮助代理商为客户进行预订。
语义解析。SQL查询生成与语义解析相关。基于WikiSQL数据集的模型将自然语言问题转换为结构化SQL查询,以便用户可以使用自然语言与数据库交互。
代词消解。我们的最后一个任务是基于要求代词解析的Winograd模式:“Joan一定要感谢Susan的帮助(给予/收到)。谁给予或者收到了帮助?Joan还是Susan?”。我们从Winograd模式挑战中的示例开始,并对它们进行了修改(导致了修订的Winograd模式挑战,即MWSC),以确保答案是上下文中的单个单词,并且分数不会因上下文、问题和答案之间的措辞或不一致而增加或者减少。
十项全能得分(decaScore)
在decaNLP上竞争的模型是被特定任务中度量标准的附加组合来评估的。所有的度量值都在0到100之间,因此十项全能得分在10个任务中的度量值在0到1000之间。使用附加组合可以避免我们在权衡不同指标时可能产生的随意性。所有指标都不区分大小写。我们将标准化的F1(nF1)用于问答、自然语言推理、情感分析、词性标注和MWSC;平均值ROUGE-1、ROUGE-2、ROUGE-L作为摘要的评分等级;语料BLEU水平得分用于对机器翻译进行评分;联合目标跟踪精确匹配分数和基于回合的请求精确匹配得分的平均值用于对目标导向进行评分;逻辑形式精确匹配得分用于WikiSQL上的语义解析;以及语料库级F1评分等级,用于QA-ZRE的关系提取。
为了代替标准的验证数据,我们选择了按要求的decaNLP模型提交到原始的小组平台进行测试。类似地,MNLI测试集不是公开的,decaNLP模型必须通过一个Kaggle系统来评估MNLI的测试性能。
多任务问答网络(MQAN)
为了有效地在所有decaNLP中进行多任务处理,我们引入了MQAN,一个多任务问题回答网络,它没有任何针对特定任务的参数和模块。
简单地说,MQAN采用一个问题和一个上下文背景文档,用BiLSTM编码,使用额外的共同关注对两个序列的条件进行表示,用另两个BiLSTM压缩所有这些信息,使其能够更高层进行计算,用自我关注的方式来收集这种长距离依赖关系,然后使用两个BiLSTM对问题和背景环境的进行最终的表示。多指针生成器解码器着重于问题、上下文以及先前输出象征来决定是否从问题中复制,还是从上下文复制,或者从有限的词汇表中生成。关于我们的模型的其他细节可以在我们的文章的第3节中找到。
基线和结果
除了MQAN,我们还尝试了几种基线方法并计算了它们的十项全能得分。第一个基线,S2S,是具有注意力和指针生成器的序列到序列的网络。我们的第二基线,S2S w/SAtt,是一个S2S网络,它在编码器侧的BiLTM层和解码器侧的LSTM层之间添加了自注意(Transformer)层。我们的第三个基线,+CAtt,将上下文和问题分成两个序列,并在编码器侧添加一个额外的共同关注层。MQAN是一个种带有附加问题指针的+CAtt模型,在我们的基线/消融研究中,它被称为+QPtr。针对每一个模型,我们都提出了两种实验。第一,我们报告出十个任务模型中的单任务性能。第二,我们提出多任务性能,即模型在所有任务中被联合训练所体现出的性能。
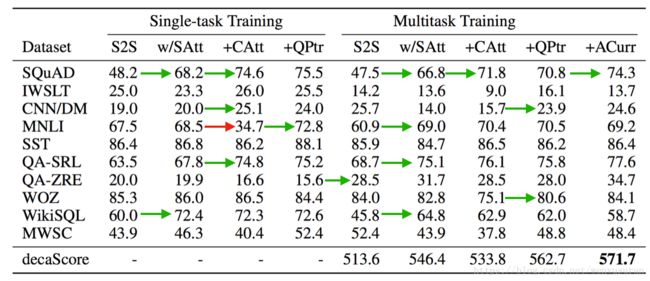
图4.单任务和多任务实验对不同模型和训练策略的验证结果
比较这些实验的结果突出了在序列到序列和通用NLP问答方法之间的多任务和单任务之间的权衡关系。从S2S到S2S w/ SAtt提供了一种模型,该模型在混合上下文和输入的系列问题中添加了附加关注层。这大大提高了 SQuAD和WiKISQL的性能,同时也提高了QA-SRL的性能。仅此一点就足以实现WiKISQL的最新技术性能。这也表明,如果不隐性地学习如何分离它们的表示方法,而显性地去分离上下文和问题会使模型建立更丰富的表示方法。
下一个基线使用上下文和问题作为单独的输入序列,相当于使用一个共同关注机制(+CAT)来增强S2S模型,该机制分别构建了两个序列表示。 使得每个SQuAD和QA-SRL的性能增加了 5 nF1。但遗憾的是,这种分离不能改善其他任务,并且极大地损害了MNLI和MWSC的性能。对于这两个任务,可以直接从问题中复制答案,而不是像大多数其他任务那样从上下文中复制答案。由于两个S2S基线都将问题连接到上下文,所以指针生成器机制能够直接从问题中复制。当上下文和问题被分成两个不同的输入时,模型就失去了这种能力。
为了补救这个问题,我们在前面的基线中添加了一个问题指针(+QPTR),一种在之前添加给MQAN的指针。这提高了MNLI和MWSC的性能,甚至能够比S2S基线达到更高的分数。它也改善了在SQuAD,IWSLT和 CNN/DM上的性能,该模型在WiKISQL上实现了最新的成果,是面向目标的对话数据集的第二高执行模型,并且是非显式地将问题建模为跨度提取的最高性能模型。因为当使用直接跨度监督时,我们会看到应用在通用问答中的一些局限性。
在多任务设置中,我们看到了类似的结果,但我们还注意到一些额外的显著特性。在QA-ZRE中,零样本关系提取,性能比最高的单任务模型提高11个点,这支持了多任务学习即使在零样本情况下也能得到更好的泛化的假设。在需要大量使用S2S基线的指针生成器解码器的生成器部分的任务上,性能下降了50%以上,直到问题指针再次添加到模型中。我们认为这在多任务设置中尤为重要。
原因有二:首先,问题指针除了在一个共同参与的上下文语境环境之外,还有一个共同参与的问题。这种分离允许有关问题的关键信息直接流入解码器,而不是通过共同参与的上下文。其次,通过更直接地访问这个问题,模型能够更有效地决定何时生成输出令牌比直接复制更合适。
使用这种反课程训练策略,最初只针对问答进行训练,在decaNLP上的性能也进一步有所提高。
零样本和迁移学习能力
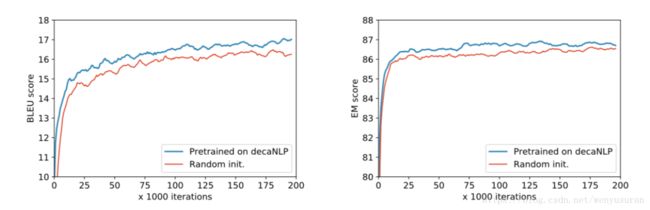
图5.在适应新域和学习新任务时,MQAN对decaNLP的预训练优于随机初始化。左:一个新的语言对的训练-英文到捷克语,右:训练一个新的任务-实体识别命名(NER)
考虑到我们的模型是在丰富和多样的数据上进行训练的,它构建了强大的中间表示方法,从而实现了迁移学习。相对于一个随机初始化的模型,我们的模型在decaNLP上进行了预先训练,使得在几个新任务上更快的收敛并且也提高了分数。我们在上图中给出了两个这样的任务:命名实体识别和英文到捷克语的翻译。 我们的模型也具有领域适应的零样本能力。
我们的模型在decaNLP上接受过训练,在没有看过训练数据的情况下,我们将SNLI数据集调整到62%的精确匹配分数。因为decaNLP包含SST,它也可以在其他二进制情感分析任务中执行得很好。在亚马逊和Yelp的评论中,MQAN在decaNLP上进行了预先培训,分别获得了82.1%和80.8%的精确匹配分数。此外,用高兴/愤怒或支持/不支持来替换训练标签的符号来重新表示问题,只会导致性能的轻微下降,因为模型主要依赖于SST的问题指针。这表明,这些多任务模型对于问题和任务中的微小变化更加可靠,并且可以推广到新的和不可见的类。
附加细节和引文
为了方便起见,我们为感兴趣的读者提供了我们的论文及其附录,为主要任务、历史背景、模型、训练策略、课程学习启发、模型激活分析和相关工作提供更多细节。该论文链接如下:
https://einstein.ai/static/images/pages/research/decaNLP/decaNLP.pdf
原文链接:https://einstein.ai/research/the-natural-language-decathlon
开源代码:https://github.com/salesforce/decaNLP
未来智能实验室是人工智能学家与科学院相关机构联合成立的人工智能,互联网和脑科学交叉研究机构。
未来智能实验室的主要工作包括:建立AI智能系统智商评测体系,开展世界人工智能智商评测;开展互联网(城市)云脑研究计划,构建互联网(城市)云脑技术和企业图谱,为提升企业,行业与城市的智能水平服务。
The Natural Language Decathlon is a multitask challenge that spans ten tasks: question answering (SQuAD), machine translation (IWSLT), summarization (CNN/DM), natural language inference (MNLI), sentiment analysis (SST), semantic role labeling(QA‑SRL), zero-shot relation extraction (QA‑ZRE), goal-oriented dialogue (WOZ, semantic parsing (WikiSQL), and commonsense reasoning (MWSC). Each task is cast as question answering, which makes it possible to use our new Multitask Question Answering Network (MQAN). This model jointly learns all tasks in decaNLP without any task-specific modules or parameters in the multitask setting. For a more thorough introduction to decaNLP and the tasks, see the main website, our blog post, or the paper.
While the research direction associated with this repository focused on multitask learning, the framework itself is designed in a way that should make single-task training, transfer learning, and zero-shot evaluation simple. Similarly, the paper focused on multitask learning as a form of question answering, but this framework can be easily adapted for different approaches to single-task or multitask learning.
Leaderboard
| Model | decaNLP | SQuAD | IWSLT | CNN/DM | MNLI | SST | QA‑SRL | QA‑ZRE | WOZ | WikiSQL | MWSC |
|---|---|---|---|---|---|---|---|---|---|---|---|
| MQAN(Sampling+CoVe) | 609.0 | 77.0 | 21.4 | 24.4 | 74.0 | 86.5 | 80.9 | 40.9 | 84.8 | 70.2 | 48.8 |
| MQAN(QA‑first+CoVe) | 599.9 | 75.5 | 18.9 | 24.4 | 73.6 | 86.4 | 80.8 | 37.4 | 85.8 | 68.5 | 48.8 |
| MQAN(QA‑first) | 590.5 | 74.4 | 18.6 | 24.3 | 71.5 | 87.4 | 78.4 | 37.6 | 84.8 | 64.8 | 48.7 |
| S2S | 513.6 | 47.5 | 14.2 | 25.7 | 60.9 | 85.9 | 68.7 | 28.5 | 84.0 | 45.8 | 52.4 |
Getting Started
GPU vs. CPU
The devices argument can be used to specify the devices for training. For CPU training, specify --devices -1; for GPU training, specify --devices DEVICEID. Note that Multi-GPU training is currently a WIP, so --device is sufficient for commands below. The default will be to train on GPU 0 as training on CPU will be quite time-consuming to train on all ten tasks in decaNLP.
If you want to use CPU, then remove the nvidia- and the cuda9_ prefixes from the default commands listed in sections below. This will allow you to use Docker without CUDA.
For example, if you have CUDA and all the necessary drivers and GPUs, you you can run a command inside the CUDA Docker image using:
nvidia-docker run -it --rm -v `pwd`:/decaNLP/ -u $(id -u):$(id -g) bmccann/decanlp:cuda9_torch041 bash -c "COMMAND --device 0"
If you want to run the same command without CUDA:
docker run -it --rm -v `pwd`:/decaNLP/ -u $(id -u):$(id -g) bmccann/decanlp:torch041 bash -c "COMMAND --device -1"
For those in the Docker know, you can look at the Dockerfiles used to build these two images in dockerfiles/.
PyTorch Version
The research associated with the original paper was done using Pytorch 0.3, but we have since migrated to 0.4. If you want to replicate results from the paper, then to be safe, you should use the code at a commit on or before 3c4f94b88768f4c3efc2fd4f015fed2f5453ebce. You should also replace toch041 with torch03 in the commands below to access a Docker image with the older version of PyTorch.
Training
For example, to train a Multitask Question Answering Network (MQAN) on the Stanford Question Answering Dataset (SQuAD) on GPU 0:
nvidia-docker run -it --rm -v `pwd`:/decaNLP/ -u $(id -u):$(id -g) bmccann/decanlp:cuda9_torch041 bash -c "python /decaNLP/train.py --train_tasks squad --device 0"
To multitask with the fully joint, round-robin training described in the paper, you can add multiple tasks:
nvidia-docker run -it --rm -v `pwd`:/decaNLP/ -u $(id -u):$(id -g) bmccann/decanlp:cuda9_torch041 bash -c "python /decaNLP/train.py --train_tasks squad iwslt.en.de --train_iterations 1 --device 0"
To train on the entire Natural Language Decathlon:
nvidia-docker run -it --rm -v `pwd`:/decaNLP/ -u $(id -u):$(id -g) bmccann/decanlp:cuda9_torch041 bash -c "python /decaNLP/train.py --train_tasks squad iwslt.en.de cnn_dailymail multinli.in.out sst srl zre woz.en wikisql schema --train_iterations 1 --device 0"
To pretrain on n_jump_start=1 tasks for jump_start=75000 iterations before switching to round-robin sampling of all tasks in the Natural Language Decathlon:
nvidia-docker run -it --rm -v `pwd`:/decaNLP/ -u $(id -u):$(id -g) bmccann/decanlp:cuda9_torch041 bash -c "python /decaNLP/train.py --n_jump_start 1 --jump_start 75000 --train_tasks squad iwslt.en.de cnn_dailymail multinli.in.out sst srl zre woz.en wikisql schema --train_iterations 1 --device 0"
This jump starting (or pretraining) on a subset of tasks can be done for any set of tasks, not only the entirety of decaNLP.
Tensorboard
If you would like to make use of tensorboard, you can add the --tensorboard flag to your training runs. This will log things in the format that Tensorboard expects.
To read those files and run the Tensorboard server, run (typically in a tmux pane or equivalent so that the process is not killed when you shut your laptop) the following command:
docker run -it --rm -p 0.0.0.0:6006:6006 -v `pwd`:/decaNLP/ -u $(id -u):$(id -g) bmccann/decanlp:cuda9_torch041 bash -c "tensorboard --logdir /decaNLP/results"
If you are running the server on a remote machine, you can run the following on your local machine to forward to http://localhost:6006/:
ssh -4 -N -f -L 6006:127.0.0.1:6006 YOUR_REMOTE_IP
If you are having trouble with the specified port on either machine, run lsof -if:6006 and kill the process if it is unnecessary. Otherwise, try changing the port numbers in the commands above. The first port number is the port the local machine tries to bind to, and and the second port is the one exposed by the remote machine (or docker container).
Notes on Training
- On a single NVIDIA Volta GPU, the code should take about 3 days to complete 500k iterations. These should be sufficient to approximately reproduce the experiments in the paper. Training for about 7 days should be enough to fully replicate those scores, which should be only a few points higher than what is achieved by 500k iterations.
- The model can be resumed using stored checkpoints using
--loadand--resume. By default, models are stored every--save_everyiterations in theresults/folder tree. - During training, validation can be slow! Especially when computing ROUGE scores. Use the
--val_everyflag to change the frequency of validation. - If you run out of GPU memory, reduce
--train_batch_tokensand--val_batch_size. - If you run out of CPU memory, make sure that you are running the most recent version of the code that interns strings; if you are still running out of CPU memory, post an issue with the command you ran and your peak memory usage.
- The first time you run, the code will download and cache all considered datasets. Please be advised that this might take a while, especially for some of the larger datasets.
Notes on Cached Data
- In order to make data loading much quicker for repeated experiments, datasets are cached using code in
text/torchtext/datasets/generic.py. - If there is an update to this repository that touches any files in
text/, then it might have changed the way a dataset is cached. If this is the case, then you'll need to delete all relevant cached files or you will not see the changes. - Paths to cached files should be printed out when a dataset is loaded, either in training or in prediction. Search the text logged to stdout for
Loading cached data fromorCaching data toin order to locate the relevant path names for data caches.
Evaluation
You can evaluate a model for a specific task with EVALUATION_TYPE as validation or test:
nvidia-docker run -it --rm -v `pwd`:/decaNLP/ -u $(id -u):$(id -g) bmccann/decanlp:cuda9_torch041 bash -c "python /decaNLP/predict.py --evaluate EVALUATION_TYPE --path PATH_TO_CHECKPOINT_DIRECTORY --device 0 --tasks squad"
or evaluate on the entire decathlon by removing any task specification:
nvidia-docker run -it --rm -v `pwd`:/decaNLP/ -u $(id -u):$(id -g) bmccann/decanlp:cuda9_torch041 bash -c "python /decaNLP/predict.py --evaluate EVALUATION_TYPE --path PATH_TO_CHECKPOINT_DIRECTORY --device 0"
For test performance, please use the original SQuAD, MultiNLI, and WikiSQL evaluation systems. For WikiSQL, there is a detailed walk-through of how to get test numbers in the section of this document concerning pretrained models.
Pretrained Models
This model is the best MQAN trained on decaNLP so far. It was trained first on SQuAD and then on all of decaNLP. It uses CoVe as well. You can obtain this model and run it on the validation sets with the following.
wget https://s3.amazonaws.com/research.metamind.io/decaNLP/pretrained/mqan_decanlp_better_sampling_cove_cpu.tgz tar -xvzf mqan_decanlp_better_sampling_cove_cpu.tgz nvidia-docker run -it --rm -v `pwd`:/decaNLP/ -u $(id -u):$(id -g) bmccann/decanlp:cuda9_torch041 bash -c "python /decaNLP/predict.py --evaluate validation --path /decaNLP/mqan_decanlp_better_sampling_cove_cpu/ --checkpoint_name iteration_560000.pth --device 0 --silent"
This model is the best MQAN trained on WikiSQL alone, which established a new state-of-the-art performance by several points on that task: 73.2 / 75.4 / 81.4 (ordered test logical form accuracy, unordered test logical form accuracy, test execution accuracy).
wget https://s3.amazonaws.com/research.metamind.io/decaNLP/pretrained/mqan_wikisql_cpu.tar.gz tar -xvzf mqan_wikisql_cpu.tar.gz nvidia-docker run -it --rm -v `pwd`:/decaNLP/ bmccann/decanlp:cuda9_torch041 -c "python /decaNLP/predict.py --evaluate validation --path /decaNLP/mqan_wikisql_cpu --checkpoint_name iteration_57000.pth --device 0 --tasks wikisql" nvidia-docker run -it --rm -v `pwd`:/decaNLP/ -u $(id -u):$(id -g) bmccann/decanlp:cuda9_torch041 bash -c "python /decaNLP/predict.py --evaluate test --path /decaNLP/mqan_wikisql_cpu --checkpoint_name iteration_57000.pth --device 0 --tasks wikisql" docker run -it --rm -v `pwd`:/decaNLP/ -u $(id -u):$(id -g) bmccann/decanlp:cuda9_torch041 bash -c "python /decaNLP/convert_to_logical_forms.py /decaNLP/.data/ /decaNLP/mqan_wikisql_cpu/iteration_57000/validation/wikisql.txt /decaNLP/mqan_wikisql_cpu/iteration_57000/validation/wikisql.ids.txt /decaNLP/mqan_wikisql_cpu/iteration_57000/validation/wikisql_logical_forms.jsonl valid" docker run -it --rm -v `pwd`:/decaNLP/ -u $(id -u):$(id -g) bmccann/decanlp:cuda9_torch041 bash -c "python /decaNLP/convert_to_logical_forms.py /decaNLP/.data/ /decaNLP/mqan_wikisql_cpu/iteration_57000/test/wikisql.txt /decaNLP/mqan_wikisql_cpu/iteration_57000/test/wikisql.ids.txt /decaNLP/mqan_wikisql_cpu/iteration_57000/test/wikisql_logical_forms.jsonl test" git clone https://github.com/salesforce/WikiSQL.git #[email protected]:salesforce/WikiSQL.git for ssh docker run -it --rm -v `pwd`:/decaNLP/ -u $(id -u):$(id -g) bmccann/decanlp:cuda9_torch041 bash -c "python /decaNLP/WikiSQL/evaluate.py /decaNLP/.data/wikisql/data/dev.jsonl /decaNLP/.data/wikisql/data/dev.db /decaNLP/mqan_wikisql_cpu/iteration_57000/validation/wikisql_logical_forms.jsonl" # assumes that you have data stored in .data docker run -it --rm -v `pwd`:/decaNLP/ -u $(id -u):$(id -g) bmccann/decanlp:cuda9_torch041 bash -c "python /decaNLP/WikiSQL/evaluate.py /decaNLP/.data/wikisql/data/test.jsonl /decaNLP/.data/wikisql/data/test.db /decaNLP/mqan_wikisql_cpu/iteration_57000/test/wikisql_logical_forms.jsonl" # assumes that you have data stored in .data
You can similarly follow the instructions above for downloading, decompressing, and loading in pretrained models for other indivual tasks (single-task models):
wget https://s3.amazonaws.com/research.metamind.io/decaNLP/pretrained/squad_mqan_cove_cpu.tgz wget https://s3.amazonaws.com/research.metamind.io/decaNLP/pretrained/cnn_dailymail_mqan_cove_cpu.tgz wget https://s3.amazonaws.com/research.metamind.io/decaNLP/pretrained/iwslt.en.de_mqan_cove_cpu.tgz wget https://s3.amazonaws.com/research.metamind.io/decaNLP/pretrained/sst_mqan_cove_cpu.tgz wget https://s3.amazonaws.com/research.metamind.io/decaNLP/pretrained/multinli.in.out_mqan_cove_cpu.tgz wget https://s3.amazonaws.com/research.metamind.io/decaNLP/pretrained/woz.en_mqan_cove_cpu.tgz wget https://s3.amazonaws.com/research.metamind.io/decaNLP/pretrained/srl_mqan_cove_cpu.tgz wget https://s3.amazonaws.com/research.metamind.io/decaNLP/pretrained/zre_mqan_cove_cpu.tgz wget https://s3.amazonaws.com/research.metamind.io/decaNLP/pretrained/schema_mqan_cove_cpu.tgz
Inference on a Custom Dataset
Using a pretrained model or a model you have trained yourself, you can run on new, custom datasets easily by following the instructions below. In this example, we use the checkpoint for the best MQAN trained on the entirety of decaNLP (see the section on Pretrained Models to see how to get this checkpoint) to run on my_custom_dataset.
mkdir -p .data/my_custom_dataset/
touch .data/my_custom_dataset/val.jsonl
echo '{"context": "The answer is answer.", "question": "What is the answer?", "answer": "answer"}' >> .data/my_custom_dataset/val.jsonl
# TODO add your own examples line by line to val.jsonl in the form of a JSON dictionary, as demonstrated above.
# Make sure to delete the first line if you don't want the demonstrated example.
nvidia-docker run -it --rm -v `pwd`:/decaNLP/ -u $(id -u):$(id -g) bmccann/decanlp:cuda9_torch041 bash -c "python /decaNLP/predict.py --evaluate valid --path /decaNLP/mqan_decanlp_qa_first_cpu --checkpoint_name iteration_1140000.pth --tasks my_custom_dataset"
You should get output that ends with something like this:
** /decaNLP/mqan_decanlp_qa_first_cpu/iteration_1140000/valid/my_custom_dataset.txt already exists -- this is where predictions are stored **
** /decaNLP/mqan_decanlp_qa_first_cpu/modeltion_1140000/valid/my_custom_dataset.gold.txt already exists -- this is where ground truth answers are stored **
** /decaNLP/mqan_decanlp_qa_first_cpu/modeltion_1140000/valid/my_custom_dataset.results.txt already exists -- this is where metrics are stored **
{"em":0.0,"nf1":100.0,"nem":100.0}
{'em': 0.0, 'nf1': 100.0, 'nem': 100.0}
Prediction: the answer
Answer: answer
From this output, you can see where predictions are stored along with ground truth outputs and metrics. If you want to rerun using this model checkpoint on this particular dataset, you'll need to pass the --overwrite_predictions argument to predict.py. If you do not want predictions and answers printed to stdout, then pass the --silent argument to predict.py.
The metrics dictionary should have printed something like {'em': 0.0, 'nf1': 100.0, 'nem': 100.0}. Here em stands for exact match. This is the percentage of predictions that had every token match the ground truth answer exactly. The normalized version, nem, lowercases and strips punctuation -- all of our models are trained on lowercased data, so nem is a more accurate representation of performance than em for our models. For tasks that are typically treated as classification problems, these exact match scores should correspond to accuracy. nf1 is a normalized (lowercased; punctuation stripped) F1 score over the predicted and ground truth sequences. If you would like to add additional metrics that are already implemented you can try adding --bleu (the typical metric for machine translation) and --rouge (the typical metric for summarization). Other metrics can be implemented following the patterns in metrics.py.
Citation
If you use this in your work, please cite The Natural Language Decathlon: Multitask Learning as Question Answering.
@article{McCann2018decaNLP,
title={The Natural Language Decathlon: Multitask Learning as Question Answering},
author={Bryan McCann and Nitish Shirish Keskar and Caiming Xiong and Richard Socher},
journal={arXiv preprint arXiv:1806.08730},
year={2018}
}
Contact
Contact: [email protected] and [email protected]