笔记三|Fast R-CNN
溯源:Fast R-CNN基于R-CNN(笔记二)RCNN和SPP-Net的思想
论文地址
本文结构:
目录
1 Fast R-CNN结构
1.1特征提取与RoI
优点
1.2感兴趣区域池化层
1.3 全连接层
2 训练
2.1预训练
2.2 批量与样本选择
2.3 损失函数
2.3.1目标分类损失
2.3.2 边界框回归损失
2.3.3 网络总损失
2.4 感兴趣区域池化层的反向传播
2.5 SGD超参数
2.6 尺度不变的目标检测
3 模型的加速
3.1 全连接层加速( Truncated SVD)
4 实验解读
1 Fast R-CNN结构
1.1特征提取与RoI
网络组成的思路类似于RCNN,网络的输入为整幅的待检测图像,使用VGG16等图像分类网络中的卷积部分,对图像进行特征提取,得到最终的特征图。
RoI(Regions of Interest):感兴趣区域,是proposal(原图的红框区域)在特征图(Figure 1 中是Conv feature map)上的对应区域(灰色区域部分)
个人理解:用卷积网络在原图提取特征时,结果是整幅图像的特征图,网络其实有两个输入,一个是整张图,另一个则是用其他提取算法例如selective search等得到的proposals,卷积网络可以的输入端和输出端可以看成是一个线性的映射,RoI就是proposals经卷积后在特征图上的映射区域。
优点
【与RCNN相比】
RCNN在提取特征时,是使用卷积网络提取每一个proposals的特征;
在Fast R-CNN中,CNN只提取一次整幅图的特征,CNN的计算是共享的,节省了时间。
1.2感兴趣区域池化层
在RCNN中,卷积层的最后一层后面接了pool5池化层,Fast R-CNN吸收了SPP-Net的思想,使用了与SPP层类似的感兴趣区域池化层,将所有的RoI(在特征图上提取的灰色部分)都送到感兴趣区域池化层。

RoI池化层对每个RoI提取特定长度的特征向量,其使用最大池化的方式,具体操作为:
将RoI看成一个尺寸大小为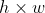 的窗口,将其划分为
的窗口,将其划分为 的子窗口(每个窗口大小为
的子窗口(每个窗口大小为![]() ),对RoI的每个子窗口进行池化,输出每个子窗口中的最大值。
),对RoI的每个子窗口进行池化,输出每个子窗口中的最大值。
- 该操作对于特征图的每个channel是独立进行的
- 最大池化这一步统一了输出的尺寸,即RoI因为是proposals的映射,其长宽比仍然是不变的,也就是RoIs的尺寸并不统一,通过最大池化的操作,无论原始数据如何,调节窗口的大小,池化后都是
1.3 全连接层
RoI最大池化层后接两个全连接层,作用是得到固定尺寸的RoI的特征向量
输出层由两个并接的全连接层组成,接收RoI的特征向量,输出两个任务的结果:softmax分类,边界框回归
【优点】将RCNN中分开训练的分类,边界框回归统一到了一个框架中,只用训练一次。
2 训练
2.1预训练
选取AlexNet、VGG_CNN_M_1024和VGG16这3个预训练网络作为基础网络。预训练网络是在ImageNet上通过图像分类任务训练得到的,每个网络有5个最大池化层和5~13个卷积层。
在用预训练网络初始化Fast R-CNN网络时,会经历三次变换:
第一次,最后的最大池化层被感兴趣区域池化层代替。
第二次,网络最后的全连接层和softmax函数被替换成两个同级层,分别用于目标分类任务和边界框回归任务。
第三次,网络的数据输入被改为两个,分别是图像的列表和这些图像中的建议框的列表
2.2 批量与样本选择
采用mini-batch的方法,每个mini-batch有N幅图片,再从N幅图片中选R个proposals;正样本为与某类真值边界框(ground-truth bounding box)的![]() 的proposals,负样本为与全部类别的真值边界框
的proposals,负样本为与全部类别的真值边界框![]() 的建议框,正负样本比例在1:3;
的建议框,正负样本比例在1:3;
在训练期间,会以50%的概率将图像水平翻转,作为唯一的数据增强的方式
2.3 损失函数
由最终输出层可知,网络是一个多任务模型:目标分类和边界框回归。因此存在两个损失函数,网络的总损失函数为两者的加权和:
![]()
2.3.1目标分类损失
softmax输出的是![]() ,代表的是一个RoI在K+1个类别上的离散概率分布(k=0是背景),每个RoI都有标定的真值类别
,代表的是一个RoI在K+1个类别上的离散概率分布(k=0是背景),每个RoI都有标定的真值类别 。
。
分类损失是一个对数损失:
![]()
2.3.2 边界框回归损失
第二个子连接层输出的是边界框回归的坐标,![]() 是对类别进行预测的边界框回归参数,
是对类别进行预测的边界框回归参数,![]() 是每个RoI的真值边界框的回归参数,
是每个RoI的真值边界框的回归参数,![]() ,
,![]() 都是维度为四的向量,
都是维度为四的向量,![]() ,前两个分量表示真值边界框G相对于建议框P计算得到的相对平移量,后两个分类代表缩放量。(类似于RCNN中边界框回归)。
,前两个分量表示真值边界框G相对于建议框P计算得到的相对平移量,后两个分类代表缩放量。(类似于RCNN中边界框回归)。
边界框损失为:
![]()
smooth是一个鲁棒的L1损失,与R-CNN和SPP-Net中使用的L2损失相比,更不容易受极值端的影响:

2.3.3 网络总损失
![]()
![]() 表示标定的真值类别
表示标定的真值类别 为1-K的类别的边界框才要计算边界框回归损失,
为1-K的类别的边界框才要计算边界框回归损失,![]() 表示被标记为背景类别的RoI可以忽略边界框损失
表示被标记为背景类别的RoI可以忽略边界框损失
本实验中,![]() ,表示两种损失的权重。
,表示两种损失的权重。
2.4 感兴趣区域池化层的反向传播
当普通最大池化层反向传播时,设 为该池化层中的第
为该池化层中的第 各输入节点,
各输入节点,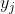 为该池化层的第
为该池化层的第 个输出节点,那么损失函数
个输出节点,那么损失函数 对输入节点的梯度为
对输入节点的梯度为

其中,判决函数![]() 表示输入节点是否被输出节点选为最大值输出,若选中则为true;损失函数对的偏导数等于损失函数对的偏导数乘以对的偏导数。(对的偏导数恒等于1)
表示输入节点是否被输出节点选为最大值输出,若选中则为true;损失函数对的偏导数等于损失函数对的偏导数乘以对的偏导数。(对的偏导数恒等于1)
由于RoI在特征图上可能会出现重叠的情况,所以一个输入节点可能与多个输出节点相关联。
所以,在进行反向传播时,损失函数对输入节点的梯度为损失函数对各个有可能的RoI的输出节点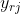 梯度的累加:
梯度的累加:
![]()
其中,
![[i = \delta(r,j)] = \begin{cases} 1 & i = \delta(r,j) \\ 0 & otherwise \end{cases}](http://img.e-com-net.com/image/info8/48e660be6119436bbbf984baa0510700.gif)
2.5 SGD超参数
初始化全连接层与边界框回归:零均值高斯分布,偏差分别为0.01,0.001;偏差为0
所有层对权重的学习率为1,偏差的学习率为2;全局的学习率为0.001
当在VOC07上或VOC12上训练时,每个小批量使用SGD方法,迭代30K,然后降低学习率为0.0001再另训练10K迭代次数。
大训练集再训练更多的次数
2.6 尺度不变的目标检测
brute force learning:每个image处理成预定大小进行训练和测试。所以网络必须直接从训练数据中学习尺度不变的目标检测
using image pyramids:相比之下,多尺度方法通过图像金字塔为网络提供了近似的尺度不变性。在测试时,每个图像金字塔被用来对每个object proposal近似尺度归一化。在多尺度训练过程,当一个图像被采样时,我们随机采样一个金字塔尺度,作为数据增强的一种方式。
3 模型的加速
检测:一旦一个Fast R-CNN网络被精修,
image或者image pyramid(编码成一个图像列表)和R个目标proposals组成的列表作为输入;在测试时,R一般在2000个左右,使用image pyramid时,每个RoI被缩放成一个尺度,使缩放后的RoI接近224×224
每个测试RoI r,前向传播输出一个类的后验概率p以及一个关于r的预测边界框偏差的集合(每个类别都有其修正的边界框预测
给每个r在每个目标类上一个检测可信度(detection confidence),计算方式为:
![]()
然后对每个类用非最大抑制的方法
3.1 全连接层加速( Truncated SVD)
感兴趣区域池化层后面接了两个全连接层,在Fast R-CNN中,全连接层的计算次数取决于RoI的个数,而RoI有2000个之多,因此全连接层的计算量是巨大的。几乎一半的前向传播时间用在全连接层上。
【Truncated SVD】Fast R-CNN给出了基于奇异值分解(SVD)的全连接层计算加速方法。
设全连接层的参数为![]() 大小的权重矩阵
大小的权重矩阵 ,可利用奇异值被近似分解为:
,可利用奇异值被近似分解为:
![]()
U大小为![]() ,由W的前t个左奇异向量组成,
,由W的前t个左奇异向量组成,![]() 是
是![]() 的对角矩阵,对角线上的值取W的前t个最高的奇异值,V是前t个右奇异向量组成。
的对角矩阵,对角线上的值取W的前t个最高的奇异值,V是前t个右奇异向量组成。
【参数量】Truncated SVD将参数量由uv降低到了t(u+v)。
【实现】这种方法相当于将单个全连接层拆分成两个全连接层,由权重为W的单全连接层替换成第一层权重矩阵为![]() ,第二层权重矩阵为U的全连接层
,第二层权重矩阵为U的全连接层
【效果】实验表明可以在使mAP在只降低0.3%的情况下提升30%的速度
4 实验解读
哪些层用来精修:
对于SPPnet网络,只精修全连接层可以取得很好的正确率;但是Fast R-CNN用的卷积层是VGG16,相比于SPPnet来说,卷积层更深。因此本文做了实验,看从哪些层开始进行精修能够提升网络的性能。

可以看到训练经过RoI池化层的效果提升了很多。
那么所有的卷积层都需要精修吗》在小的网络上,conv1通常是通用的,与任务无关,允许conv1是否学习在mAP上没有很大的影响。在VGG16上,只发现更新从conv3_1至9?这样的优点是:
:
从conv2_1开始精修,相较于con3_1会增加1.3倍训练时间,mAP只增加了0.3个点;从conv1_1开始训练,GPU内存不够。
Fast R-CNN都使用从conv3_1及以上的层精修,模型S和M精修conv2及以上
多任务训练是否提高了目标检测的准确率

有三个量级的模型S,M,L
第一列是VOC07 mAP的基准线,基准值是没有边界框回归的。
S,M,L的第二列是用文章中提到的损失函数训练的(Fast R-CNN虽然是多任务,但参数是共享的),但在测试时禁用了边界框回归。可以看到每组多任务训练都要优于只分类训练的准确率。
第三列是在基准模型(只用分类损失训练)上添加了边界框回归层,然后用回归损失训练回归层参数(其他层参数保持不变),这种方法就是stage-wise训练策略,结果mAP相较于基准值也提高了,但还是低于多任务训练(第四列)。
尺度不变目标检测
有两种方法:
暴力学习
多尺度:
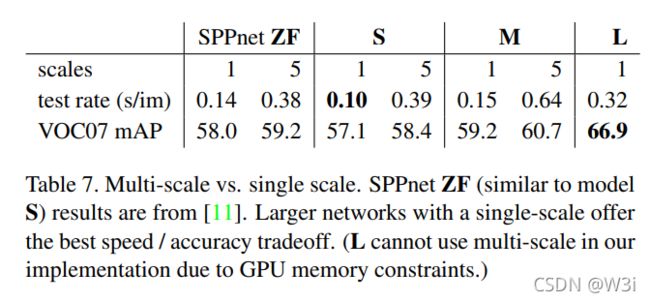
【结论】多尺度和暴力法的mAP差距很小,且暴力法的速度要优于多尺度,实现速度与准确率上很好的tradeoff,因此文中的其他部分都用single-scale的方式
增加训练数据
在原有的VOC07 trainval数据集上添加VOC12 trainval,图像数量增加了三倍(16.5k),mini-batch迭代次数从40k增加到了60k,在VOC10和2012实验上同理扩增数据集,使用VOC07 trainval,test 和VOC12 trainval的集合(21.5k),训练时使用100k SGD迭代,每过40k迭代次数,将学习率降低0.1倍。也提升了VOC10和2012的mAP
SVM和softmax的比较
文中提到R-CNN和SPPnet都是对SVM进行post-hoc(训练相较于卷积网络是滞后的),所以为了统一性,在Fast R-CNN也进行post-hoc训练(这里不太清楚细节是怎么实现的)
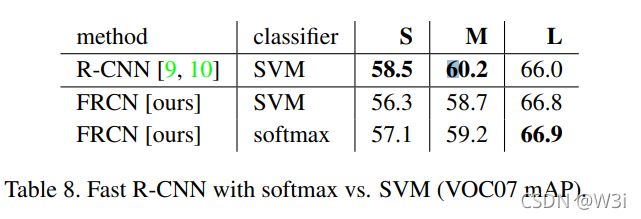
可以看到在FRCN同一框架下,softmax的mAP分数更高,作者提到softmax在给RoI打分时,类间是有竞争的,与SVM的one-vs-rest的给分方式不同。
proposals是否越多越好:
概括的说目标检测有两种,分别使用object proposals的稀疏集(如选择性算法得到的)和密集集(用如DPM方法得到的)。分类具有稀疏性的proposals是一种cascade(首先用proposal机制拒绝大量的候选proposals,留给分类器一个小集合去评估。这种cascade应用到DPM上也能提高检测的准确性,这种方法也能提高Fast R-CNN的性能
整体疏导
Fast R-CNN网络的输入
将数据集图像image(比如来自VOC数据集的)首先处理成同一尺寸大小的blob。
【原因】
- 网络的结构是固定的,即网络的输入尺寸是固定的,所以进行处理

上图为源码中处理image的对应语块。
对于不同尺寸的image,处理思路是 :先用