【学习笔记】Machine Learning.吴恩达 (Week1)
假期到了,趁此良机给自己充充电,选择了Coursera网站上的Machine Learning课程学习,本系列文章为个人学习笔记,主要记录一些自己觉得比较新鲜知识及思考,没有申请加入课程,也没有买下课程,所以只有免费的视频笔记。欢迎大家讨论交流。
课程地址:Coursera | Online Courses & Credentials From Top Educators. Join for Free | CourseraLearn online and earn valuable credentials from top universities like Yale, Michigan, Stanford, and leading companies like Google and IBM. Join Coursera for free and transform your career with degrees, certificates, Specializations, & MOOCs in data science, computer science, business, and dozens of other topics. https://www.coursera.org/learn/machine-learning/home/week/1后来在B站上看到有搬运的视频,而且有大佬整理过Optional lab的资料,全部都在这个github仓库里,有了代码学习才会扎实。
https://www.coursera.org/learn/machine-learning/home/week/1后来在B站上看到有搬运的视频,而且有大佬整理过Optional lab的资料,全部都在这个github仓库里,有了代码学习才会扎实。
https://github.com/kaieye/2022-Machine-Learning-Specialization https://github.com/kaieye/2022-Machine-Learning-Specialization
https://github.com/kaieye/2022-Machine-Learning-Specialization
Week 1: lntroduction to Machine Learning
1.overview of Machine Learning
"Or recently at Landing AI have been doing a lot of work, putting computer vision into factories to help inspect if something coming off the assembly line has any defects. "
Landing AI是吴恩达从百度离职后,于2017年12月14日在美国帕罗奥图创立的企业,专注于将计算机视觉软件引入制造企业,为工业自动化和制造业的各种应用提供可靠的自动检测服务。
"In this class, you learn about the state of the art and also practice implementing machine learning algorithms yourself."
"the state of art"不是"艺术的状态",应为"技术的现状"、"前沿水平"、"最新技术"。
"the-state-of-art"则是形容词的"最先进的","最高水平的"、"顶级的"。
"When you've learned these skills, I hope that you too will find the great fun to dabble in exciting different applications and maybe even different industries. "
dabble v. 涉猎;涉足;浅尝;玩水 dabble in 涉猎
本小节讲了一下课程安排、发展历史、究竟什么是AI云云...不做记录了。
2.supervised vs.UnsupervisedMachine Learning
Field of study that gives computers the ability to learn without being explicitly programmed.
来自Arthur Samuel在1959年对机器学习给出的定义,即“一门使计算机无需明确编程就能获得学习能力的学科领域”。
So supervised learning algorithms learn to predict input, output or X to Y mapping.
有监督学习:
学习输入与输出,或者说X和Y之间的映射关系。
回归算法(regression algorithms)是有监督学习的一种类型,通过学习任何可能的数,预测输出数的算法。
分类算法(classfication algorithms)的输出是分类,或者说只存在少量可能的输出类型。
无监督学习:
But don't let the name uncivilized for you, unsupervised learning is I think just as super as supervised learning.
吴恩达老师非常有意思啊,无监督学习比有监督学习更super,哈哈哈。其实无监督学习就是使用不带有标签(label)的数据,去找到数据之间的规律。
cluster n. 簇,团,束 vi. 群聚,聚集;clustering 聚簇,聚类
聚类算法(clustring algorithm)是无监督学习的一种,简单来说就是通过输入没有标签的数据并自动将数据分为不同的类。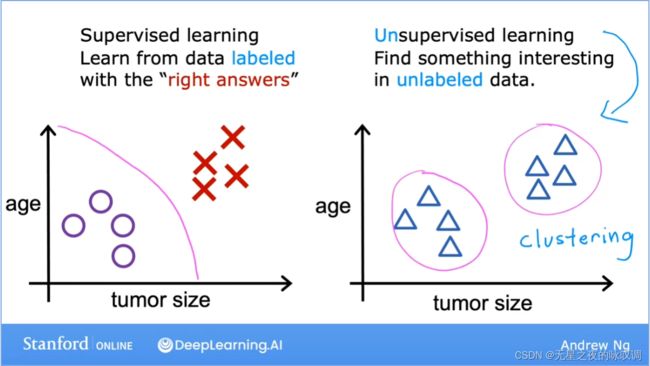
接下来又简单介绍了一下另外两种无监督学习算法:
异常检测(Anomaly detection),输入一堆数据,检测出其中的异常值。
数据降维(Dimensionality reduction),采用某种映射方法,将原高维空间中的数据点映射到低维度的空间中。
下面是测试,挺简单的,不做解析了。
3.Regression Model
...I'm going to use the notation x superscript in parenthesis i, y superscript in parentheses i. ...Just to note, this superscript i in parentheses is not exponentiation.
comma n.逗号
superscript adj.写在上边的 n.上标 (subscript下标)
parenthesis n.插入语; 插入成分; 圆括号; 间歇 (parenthese是parenthsis的复数)
exponentiation n.求幂 (exponent n.指数)
coefficients 系数; weights 权重; parameters 参数
在有监督学习算法中,训练集既包含了输入特征(input features),例如房子的面积,也包含了输出目标(output targets) ,例如房子的价格。(ps是应该这样翻译吗?)
训练集的表示方法如下图所示:
x表示输入的变量特征;y表示输出的目标变量;m表示训练集一共有多少个训练样例。
把features和targets都喂给learning algorithm,然后该learning algorithm会生成一些function即f(这个f以前也被成为hypothesis n.假设,假说; [逻]前提)
通过给这个function输入x,它便会得到ŷ(y-hat),ŷ表示预测值。这个f函数则被称为模型(model)。
那么如何才能得到这个函数f呢?定义f函数如下图。
单个变量的线性回归,有一个炫酷的名字:univariate linear regression。
平方损失函数(Squared error cost function)的定义如下图。这是一种常用的损失函数。

根据损失函数(下图右)可知,J(w)是关于参数的函数。在本例子中,当w=1时,损失函数最小。
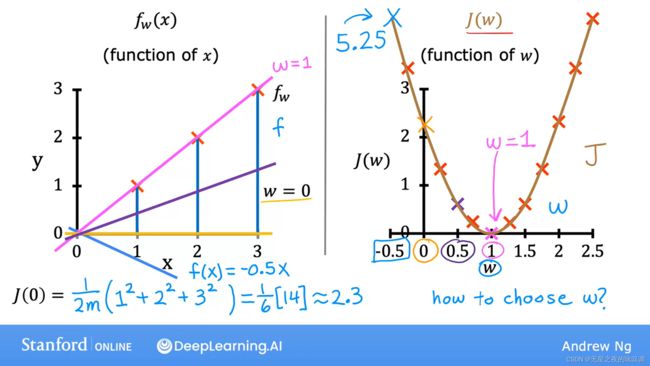
通过绘制等高线,从二维的角度来看,w和b是如何影响J的值的。

4.Train the model with gradient descent
partial derivative 偏导数;calculus 微积分
tangent n.切线;正切 adj.切线的;正切的;接触的;离题的;tangent line切线
convergence n.汇聚;融合;收敛 repeat until convergence 重复直到收敛
converge v.收敛; diverge v.发散;divergence n.发散
convex function 凸函数(碗形状的那个); concave function 凹函数
batch n.一批;(食物、药物等)一批生产的量;批
首先来对梯度下降(gradient descent)有一个直观的感受。如下图所示,有一片起伏的小丘,在给定一个初始的位置下,通过选择当前位置下坡最陡峭的一个方向移动一小步,在到达新的位置后继续选择当前位置下坡最陡峭的一个方向移动一小步,如此往复,最终到达一个小凹地。这个小凹地就是局部最小值(local minima)。选择不同的起点,可能会到达不同的局部最小值点。
梯度下降算法如下图所示,即计算当前点的梯度,然后乘学习率(learning rate alpha,α),作为参数的一个增量。吴恩达在这里稍微讲解了一下代码和数学的表示区别,咱们表示完全理解哈哈。他强调要注意w和b要同时更新,如图左下部分,错误的步骤如图右下部分。
假设仅有1个参数w时,绘制损失函数J(w)的函数曲线如下,通过选择不同的初始点,并计算当前点倒数,可以看出经过一次迭代,w的值是向着J(w)的局部最小值移动的。
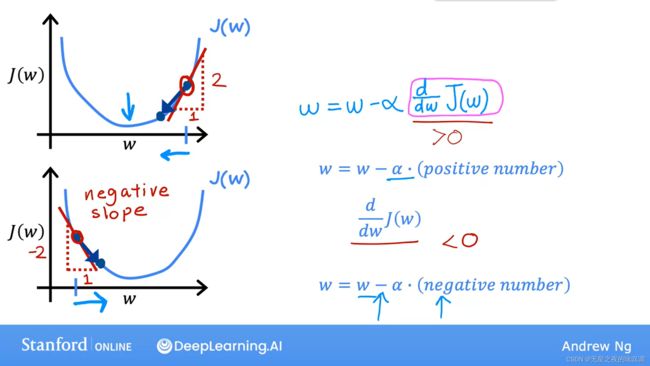
关于学习率α的选择,过小会导致梯度下降进行得十分缓慢,过大会导致超调不能达到局部最小值,不能收敛甚至发散。

当你使用的是平方损失函数作为你线下回归模型的损失函数,那么此时将只会有1个全局的极小值点。因为平方损失函数是凸函数。
批梯度下降法(batch gradient descent)在计算时使用了整个数据集,优点是获得全局最优解且易于并行实现,而缺点是当样本数目很多时训练过程会很慢。

一周的学习结束了...实际上花了1个多月,中途出去旅游了,又去了所里干活。现在稍微闲下来,继续学习。