通过对抗网络实现具有身份和姿态鲁棒性的表情识别
文章目录
- 摘要
- 一、整体介绍
- 二、算法原理
-
- 2.1 实现流程
- 2.2 分工实现
-
- 2.2.1 对抗特征学习
- 2.2.2 重构学习
- 2.2.3 总体学习
- 三、 实验
- 总结
摘要
文章是 2019 年 ACM 会议收录的一篇文章,发表于中国科学技术大学
文章中涉及的主要思想:利用对抗网络来同时实现表情识别对于身份和姿态二者的鲁棒性;实现过程分为五个部分进行:
(1)编码器(对于不同的人脸表情进行编码);
(2)表情分类器(对于不同的表情进行分类);
(3)身份鉴别器(鉴别图像中人物的身份信息);
(4)姿态鉴别器(鉴别图像中人物的不同姿态);
(5)生成器(生成面部表情);
在实际过程中,将图片中包含的身份、姿态信息加入到生成模块G,表情相关内容作为判别部分D,通过二者之间不断地对抗,最终来实现表情识别对二者的鲁棒性;
最终达成的理想化效果为:识别过程中,对于表情相关信息较为敏感,而对于身份,姿态等信息不敏感。
一、整体介绍
根据表情识别中引入方法的不同,对于图片中姿态或是人物身份特征带来干扰的处理,可以将现有的方法分为两大类:
- (1)对于姿态鲁棒性的表情识别;
- (2)对于身份鲁棒性的表情识别;
实现姿态鲁棒性的现有方法:
- 训练单一分类器和多姿态的表情分类器,用来适应不同姿态下的表情识别;
- 利用姿态归一化来实现表情识别的鲁棒性;缺点是无法利用不同姿态之间的关联性;
- 利用姿态不变特征来实现表情识别的鲁棒性;有效的利用了姿态之间的关联,但是无法应用于较大的姿态变化;
现有实现身份鲁棒性的方法:
- 学习身份不变特征,但是缺少现实样例;
- 学习基于特定个人的身份信息来减少差异,但是缺乏数据标注;
- 领域适应: 通过从源领域(即训练数据中的许多身份)中提取知识,提高目标领域(即未知的身份)的学习。然而,关于目标主体的有限数据使目标主体的分布难以适应源主体。
另一方面,关于用来实现姿态或是身份特征鲁棒性的方法有:
- JPEM (单一分类器方法)
- EPRL (姿态归一化方法)
- KPSNM (基于核的特征映射)
- LLCBL (基于姿态稳健的方法)
其中涉及到的概念有:
-
伪影:原本被扫描物体并不存在而在图像上却出现的各种形态的应像;拉伸伪影(stretching artifacts)指的是:因为对图像进行拉伸操作,造成的图像姿态发生改变;
-
SIFT:尺度不变特征变换描述符
-
流型:我们所能观察到的数据实际上是由一个低维流行映射到高维空间的。流型学习通常被用于进行降维操作,利用局部欧式距离扩展到全局,建立高维和低维的映射,来实现降维和可视化操作;
相比较而言,作者的方法同时实现了姿态和身份二者的鲁棒性,而不局限于其中的一种;前人的方法在训练中大多依赖 图像对,因此在数据较少时表现不佳,而作者的方法不依赖于图像对和条件假设,有着更好的性能。通过利用对抗学习和对所有网络的联合学习,该方法学习了一个保留表情内容但忽略身份和姿态变化的特征表示,从而提高了面部表情识别的准确率。
二、算法原理

如图所示,结构框架包括:编码器E,表情分类器De,姿态鉴别器Dp,身份鉴别器Ds,生成器G;各符号所代表的的含义如下:
![]()
- D为整体训练集
- xi表示表情图像
- yi表示表情标签是否真实
- vi表示姿态标签
- si表示身份标签;
算法的想要实现的目标如下:
- 利用编码器 E 提取具有身份和姿态鲁棒性的特征, 同时利用表情分类器预测提取出的特征的表情标签。即 Xt 为无标签的测试图片集,对于 Xt 中任意给出的未标记的图片 xt,可以用 R= E~De 来预测其表情类别;
2.1 实现流程
- 编码器 E 将训练的样本 x映射成其潜在的特征表示;
- 之后利用表情分类器De来预测其表情标签;
- 用姿态分类器Dp来预测其姿态标签;
- 用身份分类器Ds来预测其身份标签;
- 将潜在特征 E(x) 和嵌入类 z( z 由身份信息和姿态信息构成)作为生成器G的输入,将整合后的人脸图像 xf 作为输出;
xf 被期望拥有和输入 x 相同的表情标签;即 De(E(xf))的预测结果应和输入 x 的标签相同;与此同时,除了接受姿态,身份和表情信息作为输入外,编码器 E 同样可以将生成的相似类 xf 作为输入;最终的目标是在编码器中仅保留表情信息,而去除身份,姿态等的影响;编码器 E 提取的特征应易被表情分类器识别而不易被身份和姿态分类器识别,这样就达到了对身份和姿态的抑制效果; 最终得到一个整合后的分类器:
![]()
2.2 分工实现
2.2.1 对抗特征学习
将 De 应用到E(x)中有利于编码器保存表情相关的信息;E 和De 的联合工作可以使得 K 类表情预测的损失函数最小,损失函数由真实表情与预测表情之间的交叉熵损失造成;公式表示如下:

编码后的特征表示 E(x)也被用来作为姿态分类器和身份分类器的输入;E 和 Dp 相互对抗,E 中最小化姿势差异,从而使得 Dp 无法正确识别;E 和 Ds 同理;
目标如下:

由训练样本x 和姿态标签 v 带来的 M 类姿态预测损失可以被定义为:预测类Dp( E(x) ) 和真实标签 v 之间的交叉熵:

其中,可以将多类对抗性损失准换为 真/假 标签;例如:将正面姿态放在Z+中,其余姿态放在Z-中;E 和 Dp 之间对抗损失可以定义为:

由训练样本x 和身份标签 s 带来的 W 类身份预测损失可以被定义为:预测类Ds( E(x) ) 和真实标签 s 之间的交叉熵;
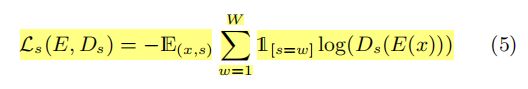
说了这么多,其实目的就一个,最大化 E 与 Dp, E 与 Ds 之间的损失,最小化 E 与 De 之间的损失,这样在最后识别的过程中,就会有效的抑制住身份和姿态信息带来的干扰;用公式可以表示为:
2.2.2 重构学习
通过优化表情分类损失和对抗损失,学习后的特征 E(x) 能够重新训练表情信息并移除身份和姿态变化的影响;生成器的分支产生表情图片 xf ,拥有和 具有任意姿态和身份特征的输入图像的表情相同;实现方法如下:
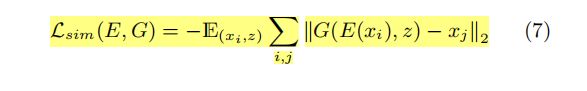
当生成的 xf 的身份信息和姿态信息与输入 xi 相同时,生成器尝试重构输入xi 的图像,即:

对生成图像进行正则化处理,目的是为了平滑生成图像的色彩空间;H 代表了图像的高度,W代表了图像的宽度;最终得到一个分类器 R ,用来预测生成的 xf 的表情标签;
xf 的表情分类预测损失可以表示为:

其中,yi 是图像 xi 的表情标签;由生成的图像 xf 可以得到的扩充数据集: Df

因此,训练中真正的训练集是 D 与 Df 的统合。
2.2.3 总体学习
对于前面提到的各类损失项,可以用一个函数来整体表达,即含损失项的联合目标函数:
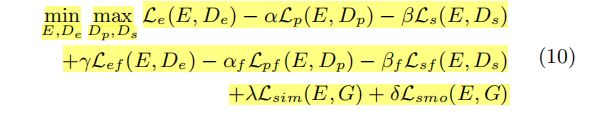
, , , , …都是加权系数; 整体学习可以分为两部分进行:
- 第一步:固定身份特征 Ds 和姿态特征 Dp,更新 E,De,和生成器 G;
- 第二步:固定 E,De,G,更新 Ds 和 Dp;重复执行,直至融合;
算法伪代码如下:

划线部分解释:当达到阈值 S 后,开始加入生成器 G 生成的图像;设置 epoch 为 T;
三、 实验
实验部分在五个公开数据集上实行,分别是:Multi-PIE , BU-3DFE , SFEW , AffectNet ,FER2013 。根据前人的设计实验探究,将数据集中的图片划分为:
- 在数据集 Multi-PIE , BU-3DFE 中, Multi-PIE 的图片划分为(0,90)度的偏转角度和(-30,30)度的平移角度;BU-3DFE 的图片划分为(0,90)度的偏转角度和(-45,45)度的平移角度;
在实验中,作者设计了自己方法的自比较:
- (1) IPFR:训练 E 和 De 模块,不加入Dp,Ds 和 G 模块;
- (2)IPFR+:训练 E 和 De ,Dp模块,不加入Ds 和 G 模块;
- (3)IPFR+:训练 E 和 De ,Ds模块,不加入Dp 和 G 模块;
- (4)IPFR++:训练 E 和 De ,Ds,Dp模块,不加入G 模块;
- (5)IPFR:加入所有模块;
自比较在数据集中各自的准确率如下,评判标准采取五次试验结果的均值,利用ACC打分:

图中的实验结果证明了以下观点:
- 加入De和Dp比不加入好,加入两个比单独加入一个好;
- 准确率的提升表明加入De模块和Dp模块是有效的,能够一定程度上抑制姿态和身份变化带来的干扰;
- 协作学习可以取得更好的性能;
- 将生成器G的生成结果加入到对抗网络中,取得了更好的性能;
可视化:
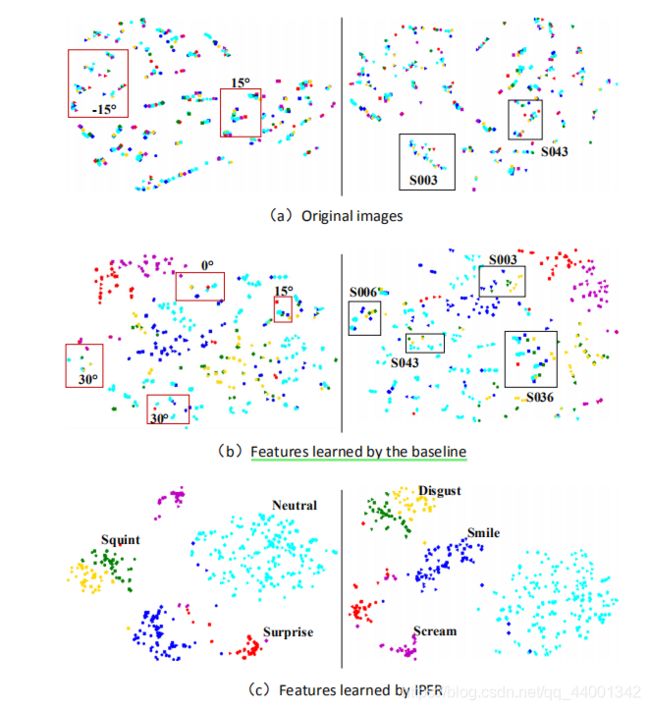
-
不同的颜色代表不同的表情。在左栏中,不同的形状代表不同的姿态,而在右栏中,不同的形状代表不同的身份
-
整体上,相同的表情聚簇,但是仍有个别表情不同但身份相同的聚集在一起,这表明表情识别确实受到了身份特征的影响;使用作者的 IPFR算法后,有效的抑制了身份信息的干扰,表情识别以正确的簇聚集在一起。
生成图片 Xf 的可视化:

- 由输出可见,生成器G可以生成与输入有相同表情的不同姿态图片。
在Multi-PIE 和 BU-3DFE 数据集与其他先进方法的比较:

ACC评分:

在各类数据集中与其他的方法比较:

总结
提出了一种抑制身份和姿态信息干扰的表情识别方法。