Springboot实现多数据源整合的两种方式,java堆与栈的区别面试
-
如果文章对你有帮助,可以帮忙一键三连和专栏订阅哦!技术圈子经过这段时间的筹划,已经初步成型!有兴趣、志同道合的小伙伴可以查看左边导航栏的技术圈子介绍,期待你们的加入! -
本篇文章重点介绍SpringBoot集合MyBatis和MyBatis-Plus整合多数据源方面的知识!
二、专栏推荐
=========
良心推荐: 下面的相关技术专栏还在免费分享哦,大家可以帮忙点点订阅哦!
JAVA进阶知识大全
算法日记修行
三、整合多数据源需要了解的知识
==================
1、何时会使用到多数据源
一个技术的出现、应用必然是为了解决存在的某些问题,多数据源出现常见的场景如下:
(1)、与第三方对接时,有些合作方并不会为了你的某些需求而给你开发一个功能,他们可以提供给你一个可以访问数据源的只读账号,你需要获取什么数据由你自己进行逻辑处理,这时候就避免不了需要进行多数据源整合了。
(2)、业务数据达到了一个量级,使用单一数据库存储达到了一个瓶颈,需要进行分库分表等操作进行数据管理,在操作数据时,不可避免的涉及到多数据源问题。
2、多数据源整合有哪些方式
参考了网上的许多材料,发现整合方式无外乎以下几种:
(1)、使用分包方式,不同的数据源配置不同的MapperScan和mapper文件
(2)、使用APO切片方式,实现动态数据源切换(如果对Aop不是很熟悉,欢迎查看我之前的一篇文章,这知识保熟哦!【什么是面向切面编程?】)
(3)、使用数据库代理中间件,如Mycat等
3、不同方式之间的区别
(1)、分包方式可以集合JTA(JAVA Transactional API)实现分布式事务,但是整个流程的实现相对来说比较复杂。
(2)、AOP动态配置数据源方式缺点在于无法实现全局分布式事务,所以如果只是对接第三方数据源,不涉及到需要保证分布式事务的话,是可以作为一种选择。
(3)、使用数据库代理中间件方式是现在比较流行的一种方式,很多大厂也是使用这种方式,开发者不需要关注太多与业务无关的问题,把它们都交给数据库代理中间件去处理,大量的通用的数据聚合,事务,数据源切换都由中间件来处理,中间件的性能与处理能力将直接决定应用的读写性能,比较常见的有Mycat、TDDL等。现在阿里出了100%自研的分布式数据库OceanBase,从最底层支持分布式,性能也非常强大,大家感兴趣的可以去了解下!
4、本文实战选择的方式
鉴于本次遇到需求的整合多数据源的场景是需要 对接第三方的数据,暂不涉及到分布式事务问题 ,所以本文实战整合多数据源使用的方式是【分包方式】实现简单的多数据源整合,至于其他方式和分布式事务的坑,后面再慢慢填吧(o(╥﹏╥)o)!
四、SpringBoot+MyBatis整合多数据源
=============================
4.1 说明
本次案例涉及到的代码比较多,因此文章只贴出部分,全部案例代码已经上传到Gitee,需要者可直接访问:【SpringBoot结合MyBatis整合多数据源】,项目结构如下:
4.2 涉及依赖包
- spring-boot-starter-web – web相关支持
- mybatis-spring-boot-starter – springboot整合mybatis依赖
- mysql-connector-java – mysql数据驱动
- lombok – 自动生成实体类常用方法依赖包
- hutool-all – 常用方法封装依赖包
org.springframework.boot
spring-boot-starter-web
org.mybatis.spring.boot
mybatis-spring-boot-starter
2.2.0
mysql
mysql-connector-java
8.0.13
org.projectlombok
lombok
true
cn.hutool
hutool-all
5.4.5
4.3 项目配置
项目启动端口
server:
port: 9090
项目 名称
spring:
application:
name: multi-datasource-instance
datasource:
主数据库
master:
注意,整合多数据源时如果使用springboot默认的数据库连接池Hikari,指定连接数据使用的是jdbc-url而不是url属性
jdbc-url: jdbc:mysql://localhost:3306/test1?serverTimezone=UTC&useUnicode=true&characterEncoding=utf8&useSSL=false
username: root
password: 123456
driver-class-name: com.mysql.cj.jdbc.Driver
副数据库
slave:
注意,整合多数据源时如果使用springboot默认的数据库连接池Hikari,指定连接数据使用的是jdbc-url而不是url属性
jdbc-url: jdbc:mysql://localhost:3306/test2?serverTimezone=UTC&useUnicode=true&characterEncoding=utf8&useSSL=false
username: root
password: 123456
driver-class-name: com.mysql.cj.jdbc.Driver
4.4 编写主副数据库数据源配置
1、主数据源相关配置:主要是指定主数据源、扫描的mapper地址、事务管理器等信息。
@Configuration
// 指定主数据库扫描对应的Mapper文件,生成代理对象
@MapperScan(basePackages =“com.diary.it.multi.datasource.mapper” ,sqlSessionFactoryRef = “masterSqlSessionFactory”)
public class MasterDataSourceConfig {
// mapper.xml所在地址
private static final String MAPPER_LOCATION = “classpath*:mapper/*.xml”;
/**
-
主数据源,Primary注解必须增加,它表示该数据源为默认数据源
-
项目中还可能存在其他的数据源,如获取时不指定名称,则默认获取这个数据源,如果不添加,则启动时候回报错
*/
@Primary
@Bean(name = “masterDataSource”)
// 读取spring.datasource.master前缀的配置文件映射成对应的配置对象
@ConfigurationProperties(prefix = “spring.datasource.master”)
public DataSource dataSource() {
DataSource build = DataSourceBuilder.create().build();
return build;
}
/**
- 事务管理器,Primary注解作用同上
*/
@Bean(name = “masterTransactionManager”)
@Primary
public PlatformTransactionManager dataSourceTransactionManager(@Qualifier(“masterDataSource”) DataSource dataSource) {
return new DataSourceTransactionManager(dataSource);
}
/**
- session工厂,Primary注解作用同上
*/
@Bean(name = “masterSqlSessionFactory”)
@Primary
public SqlSessionFactory sqlSessionFactory(@Qualifier(“masterDataSource”) DataSource dataSource) throws Exception {
final SqlSessionFactoryBean sessionFactoryBean = new SqlSessionFactoryBean();
sessionFactoryBean.setDataSource(dataSource);
sessionFactoryBean.setMapperLocations(new PathMatchingResourcePatternResolver().getResources(MasterDataSourceConfig.MAPPER_LOCATION));
return sessionFactoryBean.getObject();
}
}
2、副数据源相关配置:主要是指定数据源、扫描的mapper地址、事务管理器等信息。
@Configuration
// 指定从数据库扫描对应的Mapper文件,生成代理对象
@MapperScan(basePackages = “com.diary.it.multi.datasource.mapper2”, sqlSessionFactoryRef = “slaveSqlSessionFactory”)
public class SlaveDataSourceConfig {
// mapper.xml所在地址
private static final String MAPPER_LOCATION = “classpath*:mapper2/*.xml”;
/**
- 数据源
*/
@Bean(name = “slaveDataSource”)
// 读取spring.datasource.slave前缀的配置文件映射成对应的配置对象
@ConfigurationProperties(prefix = “spring.datasource.slave”)
public DataSource dataSource() {
DataSource build = DataSourceBuilder.create().build();
return build;
}
/**
- 事务管理器
*/
@Bean(name = “slaveTransactionManager”)
public PlatformTransactionManager dataSourceTransactionManager(@Qualifier(“slaveDataSource”) DataSource dataSource) {
return new DataSourceTransactionManager(dataSource);
}
/**
- session工厂
*/
@Bean(name = “slaveSqlSessionFactory”)
public SqlSessionFactory sqlSessionFactory(@Qualifier(“slaveDataSource”) DataSource dataSource) throws Exception {
final SqlSessionFactoryBean sessionFactoryBean = new SqlSessionFactoryBean();
sessionFactoryBean.setDataSource(dataSource);
sessionFactoryBean.setMapperLocations(new PathMatchingResourcePatternResolver().getResources(SlaveDataSourceConfig.MAPPER_LOCATION));
return sessionFactoryBean.getObject();
}
}
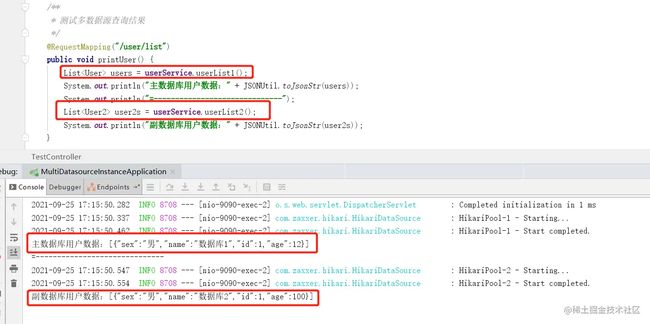
4.5 执行结果
完成上面的步骤后,就跟我们平常写业务逻辑的方式一样,在service中写业务逻辑,在mapper中写sql语句等,下面看看执行结果!
4.6 整合中遇到的问题
看完上面的教程,是不是发现其实整合多数据源其实也挺简单的!但是,完全按照教学流程整合还是遇到各种问题的现象真的太常见了,下面博主就总结下整合中遇到的各种问题,如果你在整合过程中也遇到了,可以直接按照博主的解决方案来哦(贴心吧!)。
问题1、出现 jdbcUrl is required with driverClassName异常
原因: SpringBoot2.x后默认的数据库连接池就是HikariCP(号称史上最快,性能最高),HikariCP连接池中命名规则和其他的连接池不太一样,指定连接数据库的地址时,它使用的是jdbc-url而不是url,所以如果我们不指定数据库连接池如druid而使用springboot默认的连接池的话,需要将配置中连接数据库的url改成jdbc-url属性。
问题2、 出现 Invalid bound statement (not found)异常
原因:
(1)、在定义数据源配置信息时没有指定SqlSessionFactoryBean扫描的mapper.xml文件的位置即 sessionFactoryBean.setMapperLocations(xxx)。
(2)、mapper.xml文件中namespace属性对应的路径不准确或者对应方法的id名称、parameterType属性不对
(3)、xxxMapper.java的方法返回值是List,而select元素没有正确配置ResultMap,或者只配置
《一线大厂Java面试题解析+后端开发学习笔记+最新架构讲解视频+实战项目源码讲义》
【docs.qq.com/doc/DSmxTbFJ1cmN1R2dB】 完整内容开源分享
ResultType
问题3、 出现 required a single bean, but 2 were found异常
原因: 因为我们在指定主副数据源配置时已经使用MapperScan注解进行扫描对应的mapper.java,此时被扫描到的mapper.java已经生成代理类到Spring容器,如果此时在启动类中再使用MapperScan扫描则会成出现上面的问题(奇怪的是:这个问题我换一台电脑就不报错了,所以出现这个问题先按照这个方案解决吧)
问题4、 主数据源配置类中为什么添加Primary注解