ResNeSt 模型分析和代码详解 (拆组和通道注意力ResNet)
ResNeSt: Split-Attention Networks模型的拆分注意力网络,最近特别火,主要是作为深度学习的backbone模型,ResNeSt在不同的图像任务中都有效提高了模型的预测精度。
因此今天分享下,最近两天学习的心得体会,参考资料如下:
ResNeSt: Split-Attention Networks
github官网
B站作者讲解
张航主页
文章目录
-
- 安装使用
- ResNeSt创新点
-
- split(multi-brach)分组再拆分!!!
- Channel attention 小组求权重再融合!!!
- 代码详解
-
- resnest.py
- resnet.py
-
- resnet50 layer1
- resnest50 layer1
- split-attention block
- 批注后的代码
- 模型完整结构
- dilated参数
安装使用
由于作者的主要想法就是搭建一个方便大家使用的Deep learning的backbone。所以使用起来还是相当方便。安装直接使用pip就可以安装ResNeSt模块
pip install git+https://github.com/zhanghang1989/ResNeSt
使用就更简单啦,直接import
# using ResNeSt-50 as an example
from resnest.torch import resnest50
net = resnest50(pretrained=True)
简单测试一下代码的运行效果,对博客中的猫星人进行预测
import resnest
from resnest.torch import resnest50
import torch
import numpy as np
from torchvision import transforms
from PIL import Image
def image_trans(img_file):
tf = transforms.Compose([
lambda x:Image.open(x).convert('RGB'), # string path= > image data
transforms.Resize(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
img = tf(img_file).unsqueeze(0) # add batch dim
return img
img = image_trans('./Cat.jpg')
net = resnest50(pretrained=True)
net.eval()
# input_tensor = torch.randn(2, 3, 224, 224)
output_tensor = net(img)
# [-1, 1] =>[0, 1] per softmax and transform to the numpy array
predictions = torch.nn.functional.softmax(output_tensor, 1).detach().numpy()
# ImageNet Decode
from tensorflow.keras.applications.mobilenet_v2 import decode_predictions
# print(output_tensor.shape)
print('Predicted:', decode_predictions(predictions, top=3)[0])
Predicted: [(‘n02124075’, ‘Egyptian_cat’, 0.3746694), (‘n02123045’, ‘tabby’, 0.30778167), (‘n02123159’, ‘tiger_cat’, 0.04715328)]
对比MobileNet V2的预测结果,发现前两种的预测概率有所提升
Predicted: [(‘n02124075’, ‘Egyptian_cat’, 0.329623), (‘n02123045’, ‘tabby’, 0.2984233), (‘n02123159’, ‘tiger_cat’, 0.08494468)]
ResNeSt创新点
看论文的个人感受觉:读完对split attention的模型特点也不是很清楚,图看起来也不是太好理解,个人觉得可能是因为文中涉及的cardinality和radix两个超参的说明有点抽象,示意图也不是特别形象,导致很难一下就明白作者想表达的操作流程。
我是在看了源代码和作者讲解视频后才真正理解了模型的精髓点。其实。作者一直强调的两个点,即split(multi-brach)和channel-attention。如果理解了这两点,就算基本掌握ResNeSt。
split(multi-brach)分组再拆分!!!
- Multi-brach能更够使模型具有
diverse representation,即在同一层中多个卷积核分支可以分别提取特征使得网络提取的特征更为多样。具体模型实现,作者在两个层级上体现了了mult-brach的思想。如下图中的cardinality 系数K和radix系数R,将输入特征分成了G组。
对于cardinality层级,作者使用了nn.Conv2d中的groups参数将输入特征分成Cardinality=K组。这个K组特征层和卷积核的操作使相对独立的操作。
对于radix层级,作者先使用了一个3x3的conv2d将通道数增加到channels*radix后,再用torch.split分成将特征层分成radix组输入。
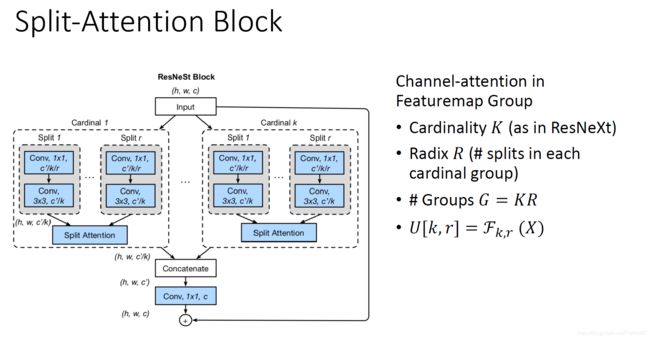
Channel attention 小组求权重再融合!!!
- Channel-attention能够提供捕捉
feature correlation的网络机制,即通过引入软注意机制实现特征通道间的权重分配。这里的权重系数获得可参考下图,首先将radix组的特征求和,再取global average pooling得到与单个radix组相同维度的矢量。
然后使用两组1x1的conv2d进行权重系数的分配,具体维度上第一组卷积的输出维度为max(in_channels*radix//reduction_factor, 32),这里的reduction_factor =4缩放系数用于减少参数量;第二组的卷积的输出维度channels*radix,保持了与radix的输入特征层维度的对应。
为保证radix组间的特征层的split的权重独立分布,使用r-softmax对各radix组的权重分别计算softmax得到attens,最后将各组对应的特征层与atten系数相乘再求和。
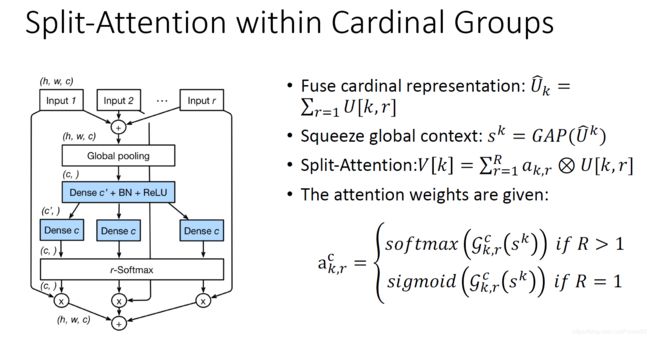
如果理解起来还是有点困难,没关系接下来我们对着源代码仔细剖析下ResNeSt的模型细节
代码详解
强烈建议对比TORCH官方的TORCHVISION.MODELS.RESNET50框架来来理解resnest的代码。
首先看看直接调用的resnest.torch.resnest.py文件中的内容。
resnest.py
定义了包括resnest50, 101, 200, 269在内的四个函数,函数内通过调用同目录下的resnet.py中的ResNet类建立model对象。
def resnest50(pretrained=False, root='~/.encoding/models', **kwargs):
model = ResNet(Bottleneck, [3, 4, 6, 3],
radix=2, groups=1, bottleneck_width=64,
deep_stem=True, stem_width=32, avg_down=True,
avd=True, avd_first=False, **kwargs)
if pretrained:
model.load_state_dict(torch.hub.load_state_dict_from_url(
resnest_model_urls['resnest50'], progress=True, check_hash=True))
return model
对于pretrained weight 文件的加载,程序通过查找文件名对应的url地址进行在线下载和权重加载过程
# 地址类似https://s3.us-west-1.wasabisys.com/resnest/torch/resnest50-528c19ca.pth
_url_format = 'https://s3.us-west-1.wasabisys.com/resnest/torch/{}-{}.pth'
# 建立一个{"resnest50":528c19ca,,,}的字典
_model_sha256 = {name: checksum for checksum, name in [
('528c19ca', 'resnest50'),
('22405ba7', 'resnest101'),
('75117900', 'resnest200'),
('0cc87c48', 'resnest269'),
]}
def short_hash(name):
if name not in _model_sha256:
raise ValueError('Pretrained model for {name} is not available.'.format(name=name))
return _model_sha256[name][:8]
# 建立字典{"resnest50":https://s3.us-west-1.wasabisys.com/resnest/torch/resnest50-528c19ca.pth,,,}
resnest_model_urls = {name: _url_format.format(name, short_hash(name)) for
name in _model_sha256.keys()
}
resnet.py
ResNeSt整体网络结构完全参考resnet,因此如下包括stem,layer1, layer2, layer3, layer4模块构成。

resnet50 layer1
为比较两者的局部结构的差异性,首先打印resnet50的layer1的结构
import torchvision.models as models
net = models.resnet50(pretrained=True)
print(net)
可见layer1中有三种Bottleneck,其中第一组bottleneck通道数由64变成256,由于改变了通道数需要增加downsample模块,另外两组保持通输入输出道数为256。
每组bottleneck由三组conv组成,卷积核分别为1x1、3x3 和 1x1。除第一组bottleneck外,每组的通道数存在bottleneck机制,用于减少网络的参数,即第二组conv的通道数为64
(layer1): Sequential(
(0): Bottleneck(
(conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
resnest50 layer1
继续查看resnset50的layer1的结构
# using ResNeSt-50 as an example
from resnest.torch import resnest50
net = resnest50(pretrained=True)
对比resnest的layer1的结构,可见主体结构与resnet是完全一直,不相同的地方是每一组bottleneck的conv2替换为了SplAtConv2d模块。
(layer1): Sequential(
(0): Bottleneck(
(conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): SplAtConv2d(
(conv): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=2, bias=False)
(bn0): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(fc1): Conv2d(64, 32, kernel_size=(1, 1), stride=(1, 1))
(bn1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(fc2): Conv2d(32, 128, kernel_size=(1, 1), stride=(1, 1))
(rsoftmax): rSoftMax()
)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): AvgPool2d(kernel_size=1, stride=1, padding=0)
(1): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): SplAtConv2d(
(conv): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=2, bias=False)
(bn0): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(fc1): Conv2d(64, 32, kernel_size=(1, 1), stride=(1, 1))
(bn1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(fc2): Conv2d(32, 128, kernel_size=(1, 1), stride=(1, 1))
(rsoftmax): rSoftMax()
)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): SplAtConv2d(
(conv): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=2, bias=False)
(bn0): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(fc1): Conv2d(64, 32, kernel_size=(1, 1), stride=(1, 1))
(bn1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(fc2): Conv2d(32, 128, kernel_size=(1, 1), stride=(1, 1))
(rsoftmax): rSoftMax()
)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
split-attention block
该模块定义在resnest.torch.splat.py中的SplAtConv2d类中

radix:基数,用于缩放的通道数的系数
SplAtConv2d模块中包括三组conv2d,卷积核分别为3x3, 1x1, 1x1,通道数都是64=>128, 64=>32, 32=>128。SplAtConv2d基本运算规则:
- 通过conv将通道数乘以radix系数;
- 通过split操作将特征分成radix组数据splited特征,并将相加后进行avg_pooling操作得到中间gap特征;
- 然后通过fc1压缩通道数,通过fc2将通道数提升到in_channels*radix的atten特征
通过split操作将atten分成radix组的attens特征,将attens与splited对应通道相乘,再相加最终得到与输入特征维度相同的特征层
批注后的代码
"""Split-Attention"""
import torch
from torch import nn
import torch.nn.functional as F
from torch.nn import Conv2d, Module, Linear, BatchNorm2d, ReLU
from torch.nn.modules.utils import _pair
__all__ = ['SplAtConv2d']
class SplAtConv2d(Module):
"""Split-Attention Conv2d
基数cardinality =groups= 1 groups对应nn.conv2d的一个参数,即特征层内的cardinal组数
基数radix = 2 用于SplAtConv2d block中的特征通道数的放大倍数,即cardinal组内split组数
reduction_factor =4 缩放系数用于fc2和fc3之间减少参数量
"""
def __init__(self, in_channels, channels, kernel_size, stride=(1, 1), padding=(0, 0),
dilation=(1, 1), groups=1, bias=True,
radix=2, reduction_factor=4,
rectify=False, rectify_avg=False, norm_layer=None,
dropblock_prob=0.0, **kwargs):
super(SplAtConv2d, self).__init__()
# padding=1 => (1, 1)
padding = _pair(padding)
self.rectify = rectify and (padding[0] > 0 or padding[1] > 0)
self.rectify_avg = rectify_avg
# reduction_factor主要用于减少三组卷积的通道数,进而减少网络的参数量
# inter_channels 对应fc1层的输出通道数 (64*2//4, 32)=>32
inter_channels = max(in_channels*radix//reduction_factor, 32)
self.radix = radix
self.cardinality = groups
self.channels = channels
self.dropblock_prob = dropblock_prob
# 注意这里使用了深度可分离卷积 groups !=1,实现对不同radix组的特征层进行分离的卷积操作
if self.rectify:
from rfconv import RFConv2d
self.conv = RFConv2d(in_channels, channels*radix, kernel_size, stride, padding, dilation,
groups=groups*radix, bias=bias, average_mode=rectify_avg, **kwargs)
else:
self.conv = Conv2d(in_channels, channels*radix, kernel_size, stride, padding, dilation,
groups=groups*radix, bias=bias, **kwargs)
self.use_bn = norm_layer is not None
if self.use_bn:
self.bn0 = norm_layer(channels*radix)
self.relu = ReLU(inplace=True)
self.fc1 = Conv2d(channels, inter_channels, 1, groups=self.cardinality)
if self.use_bn:
self.bn1 = norm_layer(inter_channels)
self.fc2 = Conv2d(inter_channels, channels*radix, 1, groups=self.cardinality)
if dropblock_prob > 0.0:
self.dropblock = DropBlock2D(dropblock_prob, 3)
self.rsoftmax = rSoftMax(radix, groups)
def forward(self, x):
# [1,64,h,w] = [1,128,h,w]
x = self.conv(x)
if self.use_bn:
x = self.bn0(x)
if self.dropblock_prob > 0.0:
x = self.dropblock(x)
x = self.relu(x)
# rchannel通道数量
batch, rchannel = x.shape[:2]
if self.radix > 1:
# [1, 128, h, w] = [[1,64,h,w], [1,64,h,w]]
if torch.__version__ < '1.5':
splited = torch.split(x, int(rchannel//self.radix), dim=1)
else:
splited = torch.split(x, rchannel//self.radix, dim=1)
# [[1,64,h,w], [1,64,h,w]] => [1,64,h,w]
gap = sum(splited)
else:
gap = x
# [1,64,h,w] => [1, 64, 1, 1]
gap = F.adaptive_avg_pool2d(gap, 1)
# [1, 64, 1, 1] => [1, 32, 1, 1]
gap = self.fc1(gap)
if self.use_bn:
gap = self.bn1(gap)
gap = self.relu(gap)
# [1, 32, 1, 1] => [1, 128, 1, 1]
atten = self.fc2(gap)
atten = self.rsoftmax(atten).view(batch, -1, 1, 1)
# attens [[1,64,1,1], [1,64,1,1]]
if self.radix > 1:
if torch.__version__ < '1.5':
attens = torch.split(atten, int(rchannel//self.radix), dim=1)
else:
attens = torch.split(atten, rchannel//self.radix, dim=1)
# [1,64,1,1]*[1,64,h,w] => [1,64,h,w]
out = sum([att*split for (att, split) in zip(attens, splited)])
else:
out = atten * x
# contiguous()这个函数,把tensor变成在内存中连续分布的形式
return out.contiguous()
class rSoftMax(nn.Module):
def __init__(self, radix, cardinality):
super().__init__()
self.radix = radix
self.cardinality = cardinality
def forward(self, x):
batch = x.size(0)
if self.radix > 1:
# [1, 128, 1, 1] => [1, 2, 1, 64]
# 分组进行softmax操作
x = x.view(batch, self.cardinality, self.radix, -1).transpose(1, 2)
# 对radix维度进行softmax操作
x = F.softmax(x, dim=1)
# [1, 2, 1, 64] => [1, 128]
x = x.reshape(batch, -1)
else:
x = torch.sigmoid(x)
return x
模型完整结构
ResNet(
(conv1): Sequential(
(0): Conv2d(3, 32, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(4): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
(6): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1): Sequential(
(0): Bottleneck(
(conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): SplAtConv2d(
(conv): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=2, bias=False)
(bn0): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(fc1): Conv2d(64, 32, kernel_size=(1, 1), stride=(1, 1))
(bn1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(fc2): Conv2d(32, 128, kernel_size=(1, 1), stride=(1, 1))
(rsoftmax): rSoftMax()
)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): AvgPool2d(kernel_size=1, stride=1, padding=0)
(1): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): SplAtConv2d(
(conv): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=2, bias=False)
(bn0): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(fc1): Conv2d(64, 32, kernel_size=(1, 1), stride=(1, 1))
(bn1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(fc2): Conv2d(32, 128, kernel_size=(1, 1), stride=(1, 1))
(rsoftmax): rSoftMax()
)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): SplAtConv2d(
(conv): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=2, bias=False)
(bn0): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(fc1): Conv2d(64, 32, kernel_size=(1, 1), stride=(1, 1))
(bn1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(fc2): Conv2d(32, 128, kernel_size=(1, 1), stride=(1, 1))
(rsoftmax): rSoftMax()
)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(layer2): Sequential(
(0): Bottleneck(
(conv1): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(avd_layer): AvgPool2d(kernel_size=3, stride=2, padding=1)
(conv2): SplAtConv2d(
(conv): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=2, bias=False)
(bn0): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(fc1): Conv2d(128, 64, kernel_size=(1, 1), stride=(1, 1))
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(fc2): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1))
(rsoftmax): rSoftMax()
)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): AvgPool2d(kernel_size=2, stride=2, padding=0)
(1): Conv2d(256, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): SplAtConv2d(
(conv): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=2, bias=False)
(bn0): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(fc1): Conv2d(128, 64, kernel_size=(1, 1), stride=(1, 1))
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(fc2): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1))
(rsoftmax): rSoftMax()
)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): SplAtConv2d(
(conv): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=2, bias=False)
(bn0): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(fc1): Conv2d(128, 64, kernel_size=(1, 1), stride=(1, 1))
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(fc2): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1))
(rsoftmax): rSoftMax()
)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(3): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): SplAtConv2d(
(conv): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=2, bias=False)
(bn0): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(fc1): Conv2d(128, 64, kernel_size=(1, 1), stride=(1, 1))
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(fc2): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1))
(rsoftmax): rSoftMax()
)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(layer3): Sequential(
(0): Bottleneck(
(conv1): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(avd_layer): AvgPool2d(kernel_size=3, stride=2, padding=1)
(conv2): SplAtConv2d(
(conv): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=2, bias=False)
(bn0): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(fc1): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1))
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(fc2): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1))
(rsoftmax): rSoftMax()
)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): AvgPool2d(kernel_size=2, stride=2, padding=0)
(1): Conv2d(512, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(2): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): SplAtConv2d(
(conv): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=2, bias=False)
(bn0): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(fc1): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1))
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(fc2): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1))
(rsoftmax): rSoftMax()
)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): SplAtConv2d(
(conv): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=2, bias=False)
(bn0): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(fc1): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1))
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(fc2): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1))
(rsoftmax): rSoftMax()
)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(3): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): SplAtConv2d(
(conv): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=2, bias=False)
(bn0): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(fc1): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1))
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(fc2): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1))
(rsoftmax): rSoftMax()
)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(4): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): SplAtConv2d(
(conv): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=2, bias=False)
(bn0): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(fc1): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1))
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(fc2): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1))
(rsoftmax): rSoftMax()
)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(5): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): SplAtConv2d(
(conv): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=2, bias=False)
(bn0): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(fc1): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1))
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(fc2): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1))
(rsoftmax): rSoftMax()
)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(layer4): Sequential(
(0): Bottleneck(
(conv1): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(avd_layer): AvgPool2d(kernel_size=3, stride=2, padding=1)
(conv2): SplAtConv2d(
(conv): Conv2d(512, 1024, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=2, bias=False)
(bn0): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(fc1): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1))
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(fc2): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1))
(rsoftmax): rSoftMax()
)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): AvgPool2d(kernel_size=2, stride=2, padding=0)
(1): Conv2d(1024, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(2): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): SplAtConv2d(
(conv): Conv2d(512, 1024, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=2, bias=False)
(bn0): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(fc1): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1))
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(fc2): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1))
(rsoftmax): rSoftMax()
)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): SplAtConv2d(
(conv): Conv2d(512, 1024, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=2, bias=False)
(bn0): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(fc1): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1))
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(fc2): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1))
(rsoftmax): rSoftMax()
)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(avgpool): GlobalAvgPool2d()
(fc): Linear(in_features=2048, out_features=1000, bias=True)
)
dilated参数
关于class ResNet(nn.Module)中的dilated参数使用,源代码给出了如下注释
dilated : bool, default False
Applying dilation strategy to pretrained ResNet yielding a stride-8 model,
typically used in Semantic Segmentation.
当修改为True时,layers3的膨胀系数dilation=2,layer4的膨胀系数dilation=4。
if dilated or dilation == 4:
self.layer3 = self._make_layer(block, 256, layers[2], stride=1,
dilation=2, norm_layer=norm_layer,
dropblock_prob=dropblock_prob)
self.layer4 = self._make_layer(block, 512, layers[3], stride=1,
dilation=4, norm_layer=norm_layer,
dropblock_prob=dropblock_prob)
对比特征层的尺寸也发生了相应的改变,dilated=True时的layers3和4的尺寸保持了不变
def forward(self, x):
# [1, 3, 224, 336]
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
# [1, 64, 56, 84] => [1, 256, 56, 84]
x = self.layer1(x)
# [1, 256, 56, 84] => [1, 512, 28, 42]
x = self.layer2(x)
# dilated=True [1, 512, 28, 42] => [1, 1024, 28, 42]
# dilated=False [1, 512, 28, 42] => [1, 1024, 14, 21]
x = self.layer3(x)
# dilated=True [1, 1024, 28, 42] => [1, 2048, 28, 42]
# dilated=False [1, 1024, 14, 21] => [1, 2048, 7, 11]
x = self.layer4(x)
#
x = self.avgpool(x)
#x = x.view(x.size(0), -1)
x = torch.flatten(x, 1)
if self.drop:
x = self.drop(x)
x = self.fc(x)
return x
对比输入下面这幅图的分类后的预测结果

dilated=False时
Predicted: [(‘n04285008’, ‘sports_car’, 0.6432321), (‘n02974003’, ‘car_wheel’, 0.108564466), (‘n02814533’, ‘beach_wagon’, 0.027976403)]
dilated=True时
Predicted: [(‘n04285008’, ‘sports_car’, 0.5430163), (‘n02974003’, ‘car_wheel’, 0.30195466), (‘n02814533’, ‘beach_wagon’, 0.054642778)]
对比在dilated=True的情况下sport_car的预测概率降低,car_wheel的概率明显增加。可见增加膨胀系数后网络能够更好的捕捉图像中的小特征