Lift-Splat-Shoot算法理解及代码中文注释
论文:Lift, Splat, Shoot: Encoding Images from Arbitrary Camera Rigs by Implicitly Unprojecting to 3D
完整代码中文注释:https://github.com/ZhouZijie-BIT/lift-splat-shoot-annotated
NVIDIA提出了一种多视角相机图像到3D空间BEV下的编码方法。Lift是指将多视角的相机图像从扁平的透视空间,“提升”到3维空间当中。Splat是指通过sum pooling操作将3维空间的特征“拍扁”成BEV特征。Shoot与运动规划有关,本文不做探究。

Lift
单目相机融合的难点在于像素的深度未知,LSS的做法是为每一个像素通过网络预测一个深度。具体做法是给每个像素在一系列可能的离散深度值上预测一个概率向量 α = [ α 0 , α 1 , α 2 , . . . , α D − 1 ] T \alpha=[\alpha_0,\alpha_1,\alpha_2,...,\alpha_{D-1}]^T α=[α0,α1,α2,...,αD−1]T。假设通过backbone在每个像素上提取到的特征维度为 C C C,那么每个像素点的特征向量为 c = [ c 0 , c 1 , c 2 , . . . , c c − 1 ] T c=[c_0,c_1,c_2,...,c_{c-1}]^T c=[c0,c1,c2,...,cc−1]T,则最终该像素在深度值 d d d 的特征 c d = α d c c_d=\alpha_dc cd=αdc,即相当于让概率向量与特征向量做外积 c α T c\alpha^T cαT。
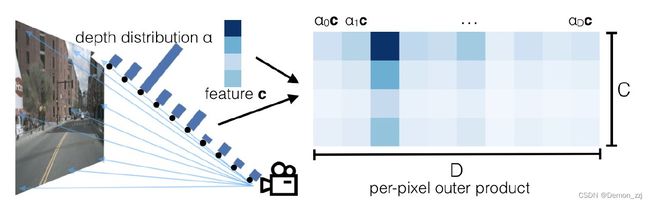
经过这一步操作就相当于在每个像素的每个离散深度值上都创造了一个点,之后再将这每个点通过相机内参和外参投影到自车坐标系下,则就完成了Lift操作。
class CamEncode(nn.Module): # 提取图像特征进行图像编码
def __init__(self, D, C, downsample):
super(CamEncode, self).__init__()
self.D = D # 41
self.C = C # 64
self.trunk = EfficientNet.from_pretrained("efficientnet-b0") # 使用 efficientnet 提取特征
self.up1 = Up(320+112, 512) # 上采样模块,输入输出通道分别为320+112和512
self.depthnet = nn.Conv2d(512, self.D + self.C, kernel_size=1, padding=0) # 1x1卷积,变换维度
def get_depth_dist(self, x, eps=1e-20): # 对深度维进行softmax,得到每个像素不同深度的概率
return x.softmax(dim=1)
def get_depth_feat(self, x):
x = self.get_eff_depth(x) # 使用efficientnet提取特征 x: 24 x 512 x 8 x 22
# Depth
x = self.depthnet(x) # 1x1卷积变换维度 x: 24 x 105(C+D) x 8 x 22
depth = self.get_depth_dist(x[:, :self.D]) # 第二个维度的前D个作为深度维,进行softmax depth: 24 x 41 x 8 x 22
new_x = depth.unsqueeze(1) * x[:, self.D:(self.D + self.C)].unsqueeze(2) # 将特征通道维和通道维利用广播机制相乘 new_x: 24 x 64 x 41 x 8 x 22
return depth, new_x
def get_eff_depth(self, x): # 使用efficientnet提取特征
# adapted from https://github.com/lukemelas/EfficientNet-PyTorch/blob/master/efficientnet_pytorch/model.py#L231
endpoints = dict()
# Stem
x = self.trunk._swish(self.trunk._bn0(self.trunk._conv_stem(x))) # x: 24 x 32 x 64 x 176
prev_x = x
# Blocks
for idx, block in enumerate(self.trunk._blocks):
drop_connect_rate = self.trunk._global_params.drop_connect_rate
if drop_connect_rate:
drop_connect_rate *= float(idx) / len(self.trunk._blocks) # scale drop connect_rate
x = block(x, drop_connect_rate=drop_connect_rate)
if prev_x.size(2) > x.size(2):
endpoints['reduction_{}'.format(len(endpoints)+1)] = prev_x
prev_x = x
# Head
endpoints['reduction_{}'.format(len(endpoints)+1)] = x # x: 24 x 320 x 4 x 11
x = self.up1(endpoints['reduction_5'], endpoints['reduction_4']) # 先对endpoints[4]进行上采样,然后将 endpoints[5]和endpoints[4] concat 在一起
return x # x: 24 x 512 x 8 x 22
def forward(self, x):
depth, x = self.get_depth_feat(x) # depth: B*N x D x fH x fW(24 x 41 x 8 x 22) x: B*N x C x D x fH x fW(24 x 64 x 41 x 8 x 22)
return x
Splat
上一步在Lift操作中,得到了一系列点及其特征。在车辆周围划分网格,将Lift操作中得到的每个点分配到每个网格当中,然后进行sum pooling操作(对每个网格中的点特征求和),再通过resnet网络降维,拍扁,最终得到多个视角图像融合的BEV特征。
class BevEncode(nn.Module):
def __init__(self, inC, outC): # inC: 64 outC: 1
super(BevEncode, self).__init__()
# 使用resnet的前3个stage作为backbone
trunk = resnet18(pretrained=False, zero_init_residual=True)
self.conv1 = nn.Conv2d(inC, 64, kernel_size=7, stride=2, padding=3,
bias=False)
self.bn1 = trunk.bn1
self.relu = trunk.relu
self.layer1 = trunk.layer1
self.layer2 = trunk.layer2
self.layer3 = trunk.layer3
self.up1 = Up(64+256, 256, scale_factor=4)
self.up2 = nn.Sequential( # 2倍上采样->3x3卷积->1x1卷积
nn.Upsample(scale_factor=2, mode='bilinear',
align_corners=True),
nn.Conv2d(256, 128, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(128),
nn.ReLU(inplace=True),
nn.Conv2d(128, outC, kernel_size=1, padding=0),
)
def forward(self, x): # x: 4 x 64 x 200 x 200
x = self.conv1(x) # x: 4 x 64 x 100 x 100
x = self.bn1(x)
x = self.relu(x)
x1 = self.layer1(x) # x1: 4 x 64 x 100 x 100
x = self.layer2(x1) # x: 4 x 128 x 50 x 50
x = self.layer3(x) # x: 4 x 256 x 25 x 25
x = self.up1(x, x1) # 给x进行4倍上采样然后和x1 concat 在一起 x: 4 x 256 x 100 x 100
x = self.up2(x) # 2倍上采样->3x3卷积->1x1卷积 x: 4 x 1 x 200 x 200
return x