2021_WWW_Self-Supervised Multi-Channel Hypergraph Convolutional Network for Social Recommendation
[论文阅读笔记]2021_WWW_Self-Supervised Multi-Channel Hypergraph Convolutional Network for Social Recommendation
论文下载地址: https://doi.org/10.1145/3442381.3449844
发表期刊:IW3C2 (International World Wide Web Conference Committee)
Publish time: 2021
作者及单位:
- Junliang Yu The University of Queensland [email protected]
- Hongzhi Yin∗ The University of Queensland [email protected]
- Jundong Li University of Virginia [email protected]
- Qinyong Wang The University of Queensland [email protected]
- Nguyen Quoc Viet Hung Griffith University [email protected]
- Xiangliang Zhang King Abdullah University of Science and Technology [email protected]
数据集:
- LastFM http://files.grouplens.org/datasets/hetrec2011/
- DouBan https://pan.baidu.com/s/1hrJP6rq
- Yelp
代码:
- https://github.com/Coder-Yu/RecQ
其他人写的文章
- Self-Supervised Multi-Channel Hypergraph Convolutional Network for Social Recommendation(这篇几乎翻译了全文)
简要概括创新点:(有很多实现的细节,值得去读)
- (1) 本文一直在强调high-order
- (2) motif不太好翻译
- (3) 从超图的角度
- 设计了很多细节,使得能够把框架缝合成功
- (4) 自监督学习
- (5)极有可能是根据 DHCF(DHCF是一种最新的基于超图卷积网络的方法,对用户和项目之间的高阶相关性进行建模,用于一般推荐。)改的,把DHCF搬到social Recommendation这个领域,再加上自己的创新。
- DHCF–>MHCN
- 都是超图卷积
- 都是关注high-order correlations
- Shuyi Ji, Yifan Feng, Rongrong Ji, Xibin Zhao, Wanwan Tang, and Yue Gao. 2020. Dual Channel Hypergraph Collaborative Filtering. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2020–2029.
Abstract
- (1) Most existing social recommendation models exploit pairwise relations to mine potential user preferences. However, real-life interactions among users are very complicated and user relations can be high-order. (大多数现有的社交推荐模型都利用成对关系来挖掘潜在的用户偏好。然而,现实生活中用户之间的交互非常复杂,用户关系可能是高阶的。)
- (2) Hypergraph provides a natural way to model complex high-order relations, while its potentials for improving social recommendation are under-explored.(超图为复杂的高阶关系建模提供了一种自然的方法,但它在提高社会推荐方面的潜力尚未得到充分开发)
- (3) In this paper, we fill this gap and propose a multi-channel hypergraph convolutional network to enhance social recommendation by leveraging high-order user relations(在本文中,我们填补了这一空白,并提出了一个多通道超图卷积网络来利用高阶用户关系来增强社交推荐)
- (4) Technically, each channel in the network encodes a hypergraph that depicts a common high-order user relation pattern via hypergraph convolution.(在技术上,网络中的每个通道通过超图卷积编码一个描述普通高阶用户关系模式的超图。)
- (5) By aggregating the embeddings learned through multiple channels, we obtain comprehensive user representations to generate recommendation results.(通过聚合通过多个渠道学习到的嵌入,我们获得全面的用户表示,从而产生推荐结果)
- (6) However, the aggregation operation might also obscure the inherent characteristics of different types of high-order connectivity information(然而,聚合操作也可能会掩盖不同类型的高阶连通性信息的固有特征)( 操作层面的难点)
- (7) To compensate for the aggregating loss, we innovatively integrate self-supervised learning into the training of the hypergraph convolutional network to regain the connectivity information with hierarchical mutual information maximization.(为了弥补聚合损失,我们创新性地将自我监督学习融入超图卷积网络的训练中,以层次互信息最大化的方式重新获得连通信息。)
CCS Concepts
Information systems→ Recommender systems; Social recommendation.
Keywords
- Social Recommendation,
- Self-supervised Learning,
- Hypergraph Learning,
- Graph Convolutional Network,
- Recommender System
1 Introduction
-
(1) It has been revealed that people may alter their attitudes and behaviors in response to what they perceive their friends might do or think, which is known as the social influence.
-
(2) Meanwhile, there are also studies [25] showing that people tend to build connections with others who have similar preferences with them, which is called the homophily.
-
(3) However, a key limitation of these GNNs-based social recommendation models is that they only exploit the simple pairwise user relations and ignore the ubiquitous high-order relations among users.(然而,这些基于gnns的社交推荐模型的一个关键缺陷是,它们只利用了简单的两两用户关系,而忽略了用户之间普遍存在的高阶关系。)
-
(4) Although the long-range dependencies of relations (i.e. transitivity of friendship), which are also considered
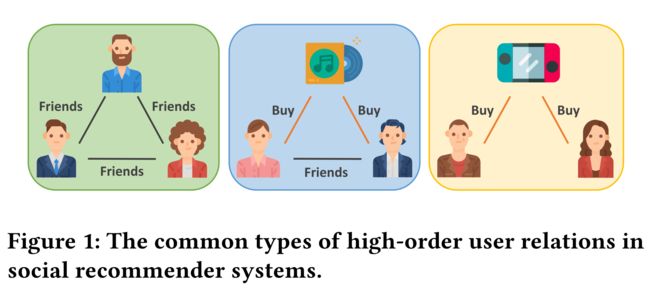
high-order, can be captured by using k k k graph neural layers to incorporate features from k k k-hop social neighbors, these GNNs-based models are unable to formulate and capture the complex high-order user relation patterns (as shown in Fig. 1) beyond pairwise relations.(虽然长期依赖关系(即友谊的传递性)也被认为是高阶的,通过使用 k k k个图神经层结合 k k k-hop社会邻居的特征来捕获,这些基于GNNs的模型无法表达和捕获成对关系之外的复杂的高阶用户关系模式(如图1所示))
-
(5) For example, it is natural to think that two users who are socially connected and also purchased the same item have a stronger relationship than those who are only socially connected, whereas the common purchase information in the former is often neglected in previous social recommendation models.(例如,人们很自然地会认为,两个具有社交联系的用户同时购买了同一件商品,他们之间的关系比那些只具有社交联系的用户更强,而前者的共同购买信息在之前的社交推荐模型中往往被忽视。 对前人不足之处做出解释,这种情形下就是不足的)
-
(6) Hypergraph [4], which generalizes the concept of edge to make it connect more than two nodes, provides a natural way to model complex high-order relations among users (超图[4]对边的概念进行了概括,使其能够连接两个以上的节点,为用户间复杂的高阶关系建模提供了一种自然的方法) (超图的合适之处)
-
(7) In this paper, we fill this gap by investigating the potentials of fusing hypergraph modeling and graph convolutional networks, and propose a Multi-channel Hypergraph Convolutional Network (MHCN) to enhance social recommendation by exploiting high-order user relations(在本文中,我们通过研究融合超图建模和图卷积网络的潜力来填补这一空白,并提出了一个多通道超图卷积网络(MHCN),通过利用高阶用户关系来增强社会推荐)
-
(8) Technically, we construct hypergraphs by unifying nodes that form specific triangular relations, which are instances of a set of carefully designed triangular motifs with underlying semantics (shown in Fig. 2) 从技术上讲,我们通过统一节点来构建超图,这些节点形成特定的三角关系,这些三角关系是一组精心设计的具有潜在语义的三角图案的实例(如图2所示)。

-
(9) As we define multiple categories of motifs which concretize different types of high-order relations such as‘having a mutual friend’,‘friends purchasing the same item’, and‘strangers but purchasing the same item’ in social recommender systems, each channel of the proposed hypergraph convolutional network under-takes the task of encoding a different motif-induced hypergraph (我们定义了多个主题类别,这些主题将不同类型的高阶关系具象化,比如“拥有共同的朋友”、“朋友购买相同的物品”、以及社交推荐系统中的“陌生人购买相同的物品”,所提出的超图卷积网络的每个通道都承担着编码不同主题诱导的超图的任务)(解释一下三角形对应的真实例子)
-
(10) By aggregating multiple user embeddings learned through multiple channels, we can obtain the comprehensive user representations which are considered to contain multiple types of high-order relation information and have the great potentials to generate better recommendation results with the item embeddings.(将通过多种渠道学习到的多个用户嵌入信息进行聚合,可以得到综合的用户表示形式,该表示形式被认为包含了多种类型的高阶关系信息,有很大潜力通过项目嵌入产生更好的推荐结果。)
-
(11) However, despite the benefits of the multi-channel setting, the ag- gregation operation might also obscure the inherent characteristics of different types of high-order connectivity information [54], as different channels would learn embeddings with varying distributions on different hypergraphs.(然而,尽管多通道设置的好处,聚合操作也可能掩盖了不同类型的高阶连通性信息[54]的固有特性,因为不同的通道在不同超图上学习的嵌入分布不同)(聚合面临的难点,引出解决方案)
-
(12) To address this issue and fully inherit the rich information in the hypergraphs, we innovatively integrate a self-supervised task [15, 37] into the training of the multi-channel hypergraph convolutional network(我们创新性地将一个自监督任务[15,37]集成到多通道超图卷积网络的训练中)
-
(13) Unlike existing studies which enforce perturbations on graphs to augment the ground-truth [53], we propose to construct self-supervision signals by exploiting the hypergraph structures, with the intuition that the comprehensive user representation should reflect the user node’s local and global high-order connectivity patterns in different hypergraphs.(现有的研究通过对图施加扰动来增强基本真理[53],与之不同的是,我们提出利用超图结构构造自我监督信号,全面用户表示应该反映不同超图中用户节点的局部和全局高阶连接模式的直觉)
- Concretely, we leverage the hierarchy in the hypergraph structures and hierarchically maximizes the mutual information between representations of the user, the user-centered sub-hypergraph, and the global hypergraph. (具体来说,我们利用超图结构中的层次结构,分层地最大化用户、以用户为中心的子超图和全局超图表示之间的互信息。)
- The mutual information here measures the structural informativeness of the sub- and the whole hypergraph towards inferring the user features through the reduction in local and global structure uncertainty.(这里的互信息通过减少局部和全局的结构不确定性来 度量子超图和整体超图的结构信息量,从而推断用户特征。)
- Finally, we unify the recommendation task and the self-supervised task under a p r i m a r y & a u x i l i a r y primary \& auxiliary primary&auxiliary learning framework. By jointly optimizing the two tasks and leveraging the interplay of all the components, the performance of the recommendation task achieves significant gains. (最后,我们将推荐任务和自我监督任务统一在一个初级和辅助学习框架下。通过共同优化两个任务,并利用所有组件的相互作用,推荐任务的性能得到显著提高)
-
(14) The major contributions of this paper are summarized as follows:
- We investigate the potentials of fusing hypergraph modeling and graph neural networks in social recommendation by exploiting multiple types of high-order user relations under a multi-channel setting.(我们研究了融合超图建模和图神经网络在社交推荐中的潜力,利用多通道设置下的多种高阶用户关系。)
- We innovatively integrate self-supervised learning into the training of the hypergraph convolutional network and show that a self-supervised auxiliary task can significantly improve the social recommendation task.(我们创新性地将自我监督学习整合到超图卷积网络的训练中,并表明自我监督辅助任务可以显著提高社会推荐任务。)
- We conduct extensive experiments on multiple real-world datasets to demonstrate the superiority of the proposed model and thoroughly ablate the model to investigate the effectiveness of each component with an ablation study.(做了消融实验)
2 Related Work
2.1 Social Recommendation
-
(1) Early exploration of social recommender systems mostly focuses on matrix factorization (MF), which has a nice probabilistic interpretation with Gaussian prior and is the most used technique in social recommendation regime.(社会推荐系统的早期探索主要集中在矩阵分解(MF),它具有良好的高斯先验概率解释,是社会推荐系统中最常用的技术)
-
(2) The common ideas of MF-based social recommendation algorithms can be categorized into three groups:
- co-factorization methods [22, 46], (协因子分解方法)
- ensemble methods [20], (集成方法)
- and regularization methods [23]. (正则化方法)
Besides, there are also studies using
- socially-aware MF to model point-of-interest [48, 51, 52], (使用社会感知的MF建模兴趣点)
- preference evolution [39], (偏好进化)
- item ranking [55, 61], (项目排名)
- and relation generation [11, 57].(关系生成) -
(3) Many research efforts demonstrate that deep neural models are more capable of capturing high-level latent preferences [49, 50]
- Specifically, graph neural networks (GNNs) [63] have achieved great success in this area, owing to their strong capability to model graph data.
- GraphRec [9] is the first to introduce GNNs to social recommendation by modeling the user-item and user-user interactions as graph data
- DiffNet [41] and its extension DiffNet++ [40] model the recursive dynamic social diffusion in social recommendation with a layer-wise propagation structure.
- Wu et al. [42] propose a dual graph attention network to collaboratively learn representations for two-fold social effects
- Song et al. develop DGRec [34] to model both users’ session-based interests as well as dynamic social influences.
- Yu et al. [58] propose a deep adversarial framework based on GCNs to address the common issues in social recommendation (一个基于GCNs的深度对抗框架来解决社会推荐中的共同问题)
- In summary, the common idea of these works is to model the user-user and user-item interactions as simple graphs with pairwise connections and then use multiple graph neural layers to capture the node dependencies.(这些工作的思想是将用户-用户和用户-项目交互建模为具有成对连接的简单图,然后使用多个图神经层来捕获节点依赖关系)
2.2 Hypergraph in Recommender Systems
-
(1) Hypergraph [4] provides a natural way to model complex high-order relations and has been extensively employed to tackle various problems. With the development of deep learning, some studies combine GNNs and hypergraphs to enhance representation learning.(超图[4]为复杂的高阶关系建模提供了一种自然的方法,并被广泛应用于解决各种问题。随着深度学习的发展,一些研究结合gnn和超图来增强表示学习。)
- HGNN [10] is the first work that designs a hyperedge convolution operation to handle complex data correlation in representation learning from a spectral perspective. (HGNN[10]是第一个从谱的角度设计超边缘卷积运算来处理表示学习中的复杂数据相关性的作品)
- Bai et al. [2] introduce hyper-graph attention to hypergraph convolutional networks to improve their capacity. However, despite the great capacity in modeling complex data, the potentials of hypergraph for improving recommender systems have been rarely explored.
-
(2) There are only several studies focusing on the combination of these two topics
- Bu et al. [5] introduce hypergraph learning to music recommender systems, which is the earliest attempt
- The most recent combinations are HyperRec [38] and DHCF [16], which borrow the strengths of hypergraph neural networks to model the short-term user preference for next-item recommendation and the high-order correlations among users and items for general collaborative filtering, respectively.
- As for the applications in social recommendation, HMF [62] uses hypergraph topology to describe and analyze the interior relation of social network in recommender systems, but it does not fully exploit high-order social relations since HMF is a hybrid recommendation model.
- LBSN2Vec [47] is a social-aware POI recommendation model that builds hyperedges by jointly sampling friendships and check-ins with random walk, but it focuses on connecting different types of entities instead of exploiting the high-order social network structures
2.3 Self-Supervised Learning
-
(1) Self-supervised learning [15] is an emerging paradigm to learn with the ground-truth samples obtained from the raw data. (自我监督学习[15]是一种新兴的学习范式,利用从原始数据中获得的ground-truth样本进行学习。)
-
(2) It was firstly used in the image domain [1, 59] by rotating, cropping and colorizing the image to create auxiliary supervision signals
- The latest advances in this area extend self-supervised learning to graph representation learning [28, 29, 35, 37]. These studies mainly develop self-supervision tasks from the perspective of investigating graph structure.
- Node properties such as degree, proximity, and attributes, which are seen as local structure information, are often used as the ground truth to fully exploit the unlabeled data [17](节点属性如度、邻近度和属性等被视为局部结构信息,通常被用作ground truth来充分利用未标记数据[17])
- For example, InfoMotif [31] models attribute correlations in motif structures with mutual information maximization to regularize graph neural networks. (使用互信息最大化方法对motif结构中的属性相关性进行建模,以正则化图神经网络)
- Meanwhile, global structure information like node pair distance is also harnessed to facilitate representation learning [35]. (同时,还利用节点对距离等全局结构信息来促进表示学习[35]。)
-
(3) Besides, contrasting congruent and incongruent views of graphs with mutual information maximization [29, 37] is another way to set up a self-supervised task, which has also shown promising results. (此外,对比具有互信息最大化的图的一致视图和不一致视图是另一种建立自我监督任务的方法,该方法也取得了良好的效果)
-
(4) As the research of self-supervised learning is still in its infancy, there are only several works combining it with recommender systems [24, 44, 45, 64]. (由于对自我监督学习的研究还处于起步阶段,将其与推荐系统相结合的研究只有几篇[24,44,45,64)
- These efforts either mine self-supervision signals from future/surrounding sequential data [24, 45], or mask attributes of items/users to learn correlations of the raw data [64].(这些努力要么从未来/现在的序列数据中挖掘自我监督信号,要么从物品/用户的掩码属性中学习原始数据的相关性)
- However, these thoughts cannot be easily adopted to social recommendation where temporal factors and attributes may not be available.(但是,由于时间因素和属性的限制,这些思想很难应用到社会推荐中。)
- The most relevant work to ours is GroupIM [32], which maximizes mutual information between representations of groups and group members to overcome the sparsity problem of group interactions.(与我们最相关的工作是GroupIM,它最大化了群体和群体成员表示之间的互信息,以克服群体交互的稀疏性问题)
-
(5) As the group can be seen as a special social clique, this work can be a corroboration of the effectiveness of social self-
supervision signals. (由于群体可以看作是一个特殊的社交小圈子,这项工作可以证实社会自我监督信号的有效性。)
3 Proposed Model
3.1 Preliminaries
- (1) 阐述一下符号表示
- Let U = { u 1 , u 2 , . . . , u m } U = \{u_1, u_2, ..., u_m\} U={u1,u2,...,um} denote the user set ( ∣ U ∣ = m |U|=m ∣U∣=m)
- and I = { i 1 , i 2 , . . . , i n } I = \{i_1, i_2, ..., i_n\} I={i1,i2,...,in} denote the item( ∣ I = n ∣ |I=n| ∣I=n∣)
- I ( u ) I(u) I(u) is the set of user consumption in which items consumed by user u u u are included.
- R ∈ R m × n R\in R^{m\times n} R∈Rm×n is a binary matrix that stores user-item interactions.
- For each pair ( u , i ) , r u i = 1 (u, i), r_{ui}=1 (u,i),rui=1 indicates that user u u u consumed item i i i
- while r u i = 0 r_{ui}=0 rui=0 means that item i i i is unexposed to user u u u, or user u u u is not interested in item i i i
- (2) In this paper, we focus on top- K K K recommendation, and r ^ u i \hat{r}_{ui} r^ui denotes the probability of item i i i to be recommended to user u u u
- (3) As for the social relations, we use S ∈ R m × m S\in R^{m\times m} S∈Rm×m to denote the relation matrix which is asymmetric because we work on directed social networks.(表示非对称的关系矩阵,因为我们的社交网络是有向的)
- (4) In our model, we have multiple convolutional layers, and we use { P ( 1 ) , P ( 2 ) , . . . , P ( l ) } ∈ R m × d \{P^{(1)}, P^{(2)}, ..., P^{(l)}\} \in R^{m\times d} {P(1),P(2),...,P(l)}∈Rm×d and { Q ( 1 ) , Q ( 2 ) , . . . . , Q ( l ) } ∈ R n × d \{Q^{(1)}, Q^{(2)}, ...., Q^{(l)} \} \in R^{n\times d} {Q(1),Q(2),....,Q(l)}∈Rn×d to denote the user and item embeddings of size d d d learned at each layer, respectively.(分别表示在每一层中学习到的大小为d维的用户和项目的嵌入)
- (5) In this paper, we use bold capital letters to denote matrices and bold lowercase letters to denote vectors.(在本文中,我们用粗体大写字母表示矩阵,用粗体小写字母表示向量。)
Defininton 1
- (1) Let G = ( V , E ) G=(V, E) G=(V,E) denote a hypergraph, where V V V is the vertex set containing N N N unique vertices and E E E is the edge set containing M M M hyperedges.(设=(,)表示超图,其中是包含个顶点的顶点集,是包含个超边的边集)
- (2) Each hyperedge ε ∈ E \varepsilon\in E ε∈E can contain any number of vertices and is assigned a positive weight W ε ε W_{\varepsilon \varepsilon} Wεε , and all the weights formulate a diagonal matrix W ∈ R M × M W\in R^{M\times M} W∈RM×M.(每个超边∈都可以包含任意数量的顶点,并被分配了一个正向的权重。所有的权重都形成了一个对角矩阵)
- The hypergraph can be represented by an incidence matrix H ∈ R N × M H\in R^{N\times M} H∈RN×M where H i ε H_{i\varepsilon} Hiε = 1 if the hyperedge ε ∈ E \varepsilon\in E ε∈E contains a vertex v i ∈ V v_i \in V vi∈V , otherwise 0.(超图可以用入射矩阵来表示)
- The vertex and edge degree matrices are diagonal matrices denoted by D D D and L L L, respectively.
- where D i i = ∑ ε = 1 M W ε ε H i ε D_{ii} =\sum^{M}_{\varepsilon=1}W_{\varepsilon \varepsilon}H_{i\varepsilon} Dii=∑ε=1MWεεHiε; L ε ε = ∑ i = 1 N H i ε L_{\varepsilon \varepsilon}=\sum^{N}_{i=1}H_{i\varepsilon} Lεε=∑i=1NHiε
- It should be noted that, in this paper, W ε ε W_{\varepsilon \varepsilon} Wεε is uniformly assigned 1 and hence W W W is an identity matrix.(因此是一个单位矩阵)
3.2 Multi-Channel Hypergraph Convolutional Network for Social Recommendation
In this section, we present our model M H C N MHCN MHCN, which stands for Multi-channel Hypergraph Convolutional Network. In Fig. 3, the schematic overview of our model is illustrated.
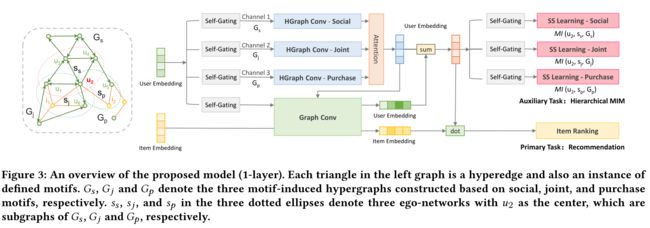
图3:提出模型的概述(1层)。左图中的每个三角形都是一个超边,也是一个已定义图的实例。, 和 分别表示基于社交图、联合图和购买图构建的三个图(主题)诱导超图。三个虚线椭圆号中的、和,表示以2为中心的三个自我网络。它们分别是、和的子图
3.2.1 Hypergraph Construction
-
(1) To formulate the high-order information among users, we first align the social network and user-item interaction graph in social recommender systems and then build hypergraphs over this heterogeneous network.(为了表示用户之间的高阶信息,我们首先在社交推荐系统中对齐社交网络和用户-项目交互图,然后在这个异构网络上构建超图)
-
(2) Unlike prior models which construct hyperedges by unifying given types of entities [5, 47], our model constructs hyperedges according to the graph structure(与以往的模型通过统一给定的实体类型来构建超边不同[5,47],我们的模型根据图的结构来构建超边)
-
(3) As the relations in social networks are often directed, the connectivity of social networks can be of various types(由于社交网络中的关系往往是有向的,因此社交网络的连通性可以是多种类型的)
-
(4) In this paper, we use a set of carefully designed motifs to depict the common types of triangular structures in social networks, which guide the hypergraph construction.(在本文中,我们使用一组精心设计的主题来描述社会网络中常见的三角结构类型,从而指导超图的构建。)
-
(5) Motif, as the specific local structure involving multiple nodes, is first introduced in [26]. It has been widely used to describe complex structures in a wide range of networks.(Motif是涉及多个节点的特定局部结构,首先在[26]中引入。它被广泛用于描述各种网络的复杂结构。)
-
(6) In this paper, we only focus on triangular motifs because of the ubiquitous triadic closure in social networks, but our model can be seamlessly extended to handle on more complex motifs(在本文中,由于社交网络中普遍存在的三元封闭,我们只关注三角图案,但我们的模型可以无缝地扩展到处理更复杂的图案)
- Fig. 2 shows all the used triangular motifs.
- It has been revealed that M 1 − M 7 M1− M7 M1−M7 are crucial for social computing [3], (研究表明,M1−M7对社交计算至关重要,)
- and we further design M 8 − M 10 M8− M10 M8−M10 to involve user-item interactions to complement (同时我们进一步设计了M8−M10以包含用户-物品交互来进行补充)
- Given motifs M 1 − M 10 M1− M10 M1−M10, we categorize them into three groups according to the underlying semantics.
- M 1 − M 7 M1− M7 M1−M7 summarize all the possible triangular relations in explicit social networks and describe the high-order social connectivity like ‘having a mutual friend’, We name this group ‘Social Motifs’. ( M 1 − M 7 M1−M7 M1−M7总结了显性社会网络中所有可能的三角关系,并描述了高阶社交连接,如“拥有共同的朋友”,我们称之为“社交主题(图)”)
- M 8 − M 9 M8− M9 M8−M9 represent the compound relation, that is,‘friends purchasing the same item’. This type of relation can be seen as a signal of strengthened tie, and we name M 8 − M 9 M8− M9 M8−M9 ‘Joint Motifs’. ( M 8 M 9 M8~M9 M8 M9表示联合关系,即“朋友购买同一件物品”。这种类型的关系可以看作是加强联系的信号,我们将 M 8 M 9 M8 ~ M9 M8 M9命名为“联合主题(图)”)
- Finally, we should also consider users who have no explicit social connections. So, M 10 M10 M10 is non-closed and defines the implicit high-order social relation that users who are not socially connected but purchased the same item. We name M 10 M10 M10 ‘Purchase Motif’. (所以, M 10 M10 M10是非封闭的,它定义了一种隐性的高阶社会关系,即没有社交联系但购买了相同商品的用户。我们将 M 10 M10 M10命名为‘purchase Motif’。)
-
(7) Under the regulation of these three types of motifs, we can construct three hypergraphs that contain different high-order user relation patterns. We use the incidence matrices H s H^s Hs, H j H^j Hj and H p H^p Hp to represent these three motif-induced hypergraphs, respectively, where each column of these matrices denotes a hyperedge (在这三种主题的约束下,我们可以构造出包含不同高阶用户关系模式的三个超图。我们分别使用矩阵、和来表示这三个主题(图)诱导的超图, 这些矩阵的每一列表示一个边)
- For example, For example, in Fig. 3, { u 1 , u 2 , u 3 } \{u_1, u_2, u_3\} {u1,u2,u3} is an instance of M 4 M4 M4, and we use e 1 e_1 e1 to denote this hyperedge. Then, according to definition 1, we have H u 1 , e 1 s H^s_{u_1, e_1} Hu1,e1s, H u 2 , e 1 s = 1 H^s_{u_2,e_1} = 1 Hu2,e1s=1, H u 3 , e 1 s = 1 H^s_{u_3, e_1} = 1 Hu3,e1s=1.(这里可以理解为,e3是一个有边界的面, u 1 , u 2 , u 3 u_1, u_2, u_3 u1,u2,u3再和 e 3 e_3 e3相连, e 3 e_3 e3就代表这个 M 4 M4 M4样例)
3.2.2 Multi-Channel Hypergraph Convolution
-
(1) In this paper, we use a three-channel setting, including ‘ S o c i a l C h a n n e l ( s ) ’ ‘Social Channel (s)’ ‘SocialChannel(s)’, ‘ J o i n t C h a n n e l ( j ) ’ ‘Joint Channel (j)’ ‘JointChannel(j)’, and ‘ P u r c h a s e C h a n n e l ( p ) ’ ‘Purchase Channel (p)’ ‘PurchaseChannel(p)’, in response to the three types of triangular motifs, but the number of channels can be adjusted to adapt to more sophisticated situations. (在本文中,我们使用了三种渠道设置,包括 “社会渠道(s)”、“联合渠道(j)”和“购买渠道(p )”,以响应三种类型的三角图案,但渠道的数量可以调整以适应更复杂的情况)
-
(2) Each channel is responsible for encoding one type of high-order user relation pattern. As different patterns may show different importances to the final recommendation performance, directly feeding the full base user embeddings P ( 0 ) P^{(0)} P(0) to all the channels is unwise (每个通道负责编码一种高阶用户关系模式。因为不同的模式可能会对最终的推荐性能表现出不同的重要性,所以直接将整个基本的用户嵌入 P ( 0 ) P^{(0)} P(0)提供给所有通道是不明智的)
-
(3) To control the information flow from the base user embeddings P ( 0 ) P^{(0)} P(0) to each channel, we design a pre-filter with self-gating units (SGUs), which is defined as: (为了控制从基本的用户嵌入 P ( 0 ) P^{(0)} P(0) 到每个通道的信息流,我们设计了一个具有自门控单元(SGU)的预过滤器)
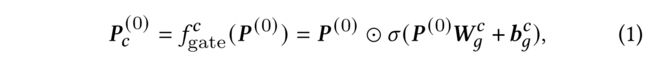
where W g c ∈ R d × d W^c_g \in R^{d\times d} Wgc∈Rd×d, b g c ∈ R d b^c_g\in R^d bgc∈Rd are parameters to be learned, c ∈ { s , j , p } c\in \{s,j,p\} c∈{s,j,p} represents the channel, ⊙ \odot ⊙ denotes the element-wise product and σ \sigma σ is the sigmoid nonlinearity. The self-gating mechanism effectively serves as a multiplicative skip-connection [8] that learns a nonlinear gate to modulate the base user embeddings at a feature- wise granularity through dimension re-weighting, then we obtain the channel-specific user embeddings P c ( 0 ) P^{(0)}_c Pc(0) (有效地作为乘法跳过式连接[8],它学习非线性门,通过维度重新加权,以特征调整基本用户嵌入,然后获得特定于通道的用户嵌入 P c ( 0 ) P^{(0)}_c Pc(0)) -
(4) Referring to the spectral hypergraph convolution proposed in [10], we define our hypergraph convolution as: (参照摘要[10]中提出的谱超图卷积,我们将超图卷积定义为:)
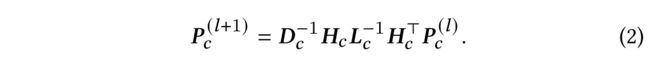
-
(5) The difference is that we follow the suggestion in [6, 14] to remove the learnable matrix for linear transformation and the nonlinear activation function (e.g. leaky ReLU) (不同的是,我们按照摘要建议,去掉了线性变换的可学习矩阵和非线性激活函数ReLU)
-
(6) By replacing H c H_c Hc with any of H s H^s Hs , H j H^j Hj and H p H^p Hp, we can borrow the strengths of hypergraph convolutional networks to learn user representations encoded high-order information in the corresponding channel. (通过用、和替换,我们可以利用超图卷积网络的优势来学习在相应通道中编码的高阶信息的用户表示)
-
(7) As D c D_c Dc and L c L_c Lc are diagonal matrices which only re-scale embeddings, we skip them in the following discussion.
-
(8) The hypergraph convolution can be viewed as a two-stage refinement performing‘node-hyperedge-node’ feature transformation upon hypergraph structure. (超图卷积可以看作是对超图结构进行“节点-超边-节点”特征变换的两阶段精化)
-
(9) The multiplication operation H c T P c l H^T_cP^{l}_c HcTPcl defines the message passing from nodes to hyperedges and then premultiplying H c H_c Hc is viewed to aggregate information from hyperedges to nodes. (乘法运算 H c T P c l H^T_cP^{l}_c HcTPcl定义从节点传递到超边的消息,然后预乘 H c H_c Hc 看作是从超边到节点聚合信息
-
(10) However, despite the benefits of hypergraph convolution, there are a huge number of motif-induced hyperedges (e.g. there are 19,385 social triangles in the used dataset, LastFM), which would cause a high cost to build the incidence matrix H c H_c Hc. (然而,尽管超图卷积有很多好处,但仍存在大量由图诱导的超边(例如,在使用的数据集LastFM中有19,385个社交三角形),这会导致构建矩阵 H c H_c Hc的高成本
-
(11) But as we only exploit triangular motifs, we show that this problem can be solved in a flexible and efficient way by leveraging the associative property of matrix multiplication. (但是,由于我们只利用三角形的motif(主题),我们证明了这个问题可以通过利用矩阵乘法的结合性以一种灵活而有效的方式来解决。)
-
(12) Following [60], we let B = S ⊙ S T B=S\odot S^T B=S⊙ST and U = S − B U = S - B U=S−B (Table 1 中用到了) be the adjacency matrices of the bidirectional and unidirectional social networks respectively. We use A M k A_{M_k} AMk to represent the motif-induced adjacency matrix and ( A M k ) i , j = 1 ({A_{M_k}})_{i,j} = 1 (AMk)i,j=1 means that vertex i i i and vertex h h h appear in one instance of M k M_k Mk .( B = S ⊙ S T B=S\odot S^T B=S⊙ST and U = S − B U = S - B U=S−B分别是 双向和单向社交网络的邻接矩阵。我们用 A M k A_{M_k} AMk去表示motif诱导的邻接矩阵, ( A M k ) i , j = 1 ({A_{M_k}})_{i,j} = 1 (AMk)i,j=1是指顶点和顶点出现在 M k M_k Mk 的一个实例中)
-
(13) As two vertices can appear in multiple instances of M k M_k Mk, ( A M k i , j ) ({A_{M_k}}_{i,j}) (AMki,j) is computed by: (因为两个顶点可以出现
的多个实例中)
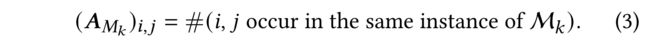
-
(14) Table 1 shows how to calculate A M k A_{M_k} AMk in the form of matrix multiplication.

-
(15) As all the involved matrices in Table 1 are sparse matrices, A M k A_{M_k} AMk can be efficiently calculated
- Specifically, the basic unit in Table 1 is in a general form of X Y ⊙ Z XY\odot Z XY⊙Z, which means A M 1 A_{M_1} AM1 to A M 9 A_{M_9} AM9 may be sparser than Z Z Z (i.e. B B B or U U U ) or as sparse as Z Z Z. (具体地说,表1中的基本单元是⊙的一般形式,这意味着 A M 1 A_{M_1} AM1 to A M 9 A_{M_9} AM9可能比(或)更稀疏,或者是和Z一样稀疏)
- A M 1 0 A_{M_10} AM10 could be a little denser, but we can filter out the popular items (we think consuming popular items might not reflect the users’ personalized preferences) when calculating A M 1 0 A_{M_10} AM10 and remove the entries less than a threshold (e.g. 5) in A M 1 0 A_{M_10} AM10 to keep efficient calculation. ( A M 1 0 A_{M_10} AM10可能有点稠密,但我们可以在计算 A M 1 0 A_{M_10} AM10 时,过滤掉流行项目(我们认为消费流行项目可能不会反映用户的个性化偏好),删除低于阈值的记录时,(比如5),从而在 A M 1 0 A_{M_10} AM10 中保持有效的计算)
- For symmetric motifs, A M = C A_M=C AM=C, and for the asymmetric ones A M = C + C T A_M=C+C^T AM=C+CT. Obviously, without considering self-connection, the summation of A M 1 A_{M_1} AM1 to A M 7 A_{M_7} AM7 is equal to H S H S ⊤ H^S H^{S\top} HSHS⊤, as each entry of H S H S ⊤ ∈ R m × m H^S H^{S\top} \in R^{m\times m} HSHS⊤∈Rm×m also indicates how many social triangles contain the node pair represented by the row and column index of the entry (表示这个节点对参与了多少个社交三角形的表示)
- Analogously, the summation of A M 8 A_{M_8} AM8 to A M 9 A_{M_9} AM9 is equal to H j H j ⊤ H^j H^{j\top} HjHj⊤ without self-connection
- and A M 10 A_{M_{10}} AM10 is equal to H p H p ⊤ H^p H^{p\top} HpHp⊤
- Taking the calculation of A M 1 A_{M_1} AM1 as an example, it is evident that U U UU UU constructs a unidirectional path connecting three vertices, and the operation ⊙ U \odot U ⊙U makes the path a closed-loop, which is an instance of A M 1 A_{M_1} AM1.
- As A M 1 0 A_{M_10} AM10 also contains the triangles in A M 8 A_{M_8} AM8 and A M 9 A_{M_9} AM9 . So, we remove the redundance from A M 10 A_{M10} AM10
- Finally, we use A s = ∑ k = 1 7 A M k A_s = \sum^{7}_{k=1} A_{M_k} As=∑k=17AMk, A j = A M 8 + A M 9 A_j = A_{M_8} + A_{M_9} Aj=AM8+AM9, and A p = A M 1 0 − A j A_p = A_{M_10} - A_j Ap=AM10−Aj to replace H s H s ⊤ H^s H^{s\top} HsHs⊤, H j H j ⊤ H^j H^{j\top} HjHj⊤ and H p H p ⊤ H^p H^{p\top} HpHp⊤ in Eq.(2), respectively.
- (16) Then we have a transformed hypergraph convolution, defined as:
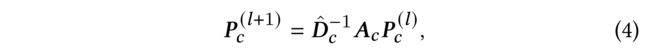
where D ^ c ∈ R m × m \hat{D}_c \in R^{m\times m} D^c∈Rm×m is the degree matrix of A c A_c Ac . Obviously, Eq (2) is equivalent to Eq (4), and can be a simplified substitution of the hypergraph convolution (是超图卷积的简化替换)
-
(17) Since we follow the design of LightGCN which has subsumed the effect of self-connection, and thus skipping self-connection in adjacency matrix does not matter too much (因为我们遵循LightGCN的设计,它包含了自连接的效果,因此在邻接矩阵中跳过自连接并不会有太大的影响)
-
(18) In this way, we bypass the individual hyperedge construction and computation, and greatly reduce the computational cost. (这种方法绕过了单个超边的构造和计算,大大降低了计算量。)
3.2.3 Learning Comprehensive User Representations
- (1) After propagating the user embeddings through L L L layers, we average the embeddings obtained at each layer to form the final channel-specific user representation: P c ∗ = 1 L + 1 ∑ l = 0 L P c ( l ) P^{*}_c = \frac{1}{L+1} \sum^L_{l=0} P^{(l)}_c Pc∗=L+11∑l=0LPc(l) to avoid the over-smoothing problem [14] (在通过层传播用户嵌入后,我们平均每一层获得的嵌入,以形成最终的特定于通道的用户表示, 去避免过度平滑问题)
- (2) Then we use the attention mechanism [36] to selectively aggregate information from different channel-specific user embeddings to form the comprehensive user embeddings. (然后我们利用注意力机制对不同通道的用户嵌入信息进行选择性聚合,形成全面的用户嵌入)
- (3) For each user u u u, a triplet ( α s , α j , α p ) (\alpha^s, \alpha^j, \alpha^p) (αs,αj,αp) is learned to measure the different contributions of the three channel-specific embeddings to the final recommendation performance. (来度量三个特定于通道的嵌入对最终推荐性能的不同贡献)。
- (4) The attention function f a t t f_{att} fatt is defined as
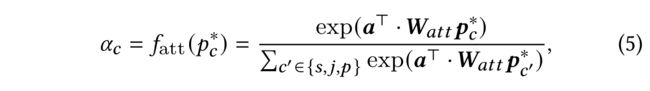
where α ∈ R d \alpha\in R^d α∈Rd and W a t t ∈ R d × d W_{att}\in R^{d\times d} Watt∈Rd×d are trainable parameters, and the comprehensive user representation p ∗ = ∑ c ∈ { s , j , p } α c p c ∗ p^* = \sum_{c\in \{{s,j,p}\}}\alpha_c p^*_c p∗=∑c∈{s,j,p}αcpc∗. - (5) Note that, since the explicit social relations are noisy and isolated relations are not a strong signal of close friendship [55, 56], we discard those relations which are not part of any instance of defined motifs (需要注意的是,由于显性的社交关系是嘈杂的,孤立的关系并不是亲密友谊的强烈信号,我们丢弃了那些不属于以上定义的motifs的实例)
- So, we do not have a convolution operation directly working on the explicit social network S S S. (因此,我们不能直接对显式社交网络做卷积操作)
- Besides, in our setting, the hypergraph convolution cannot directly aggregate information from the items (we do not incorporate the items into A j A_j Aj and A p A_p Ap ). (此外,在我们的设置中,超图卷积不能直接从项聚合信息)
- To tackle this problem, we additionally perform simple graph convolution on the user-item interaction graph to encode the purchase information and complement the multi-channel hypergraph convolution. (此外,我们在用户-物品交互图上进行简单的图卷积,对购买信息进行编码,并补充多通道超图卷积)
- The simple graph convolution is defined as:
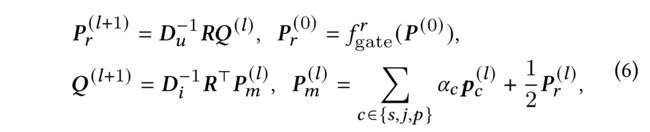
- where P r ( l ) P^{(l)}_r Pr(l) is the gated user embeddings for simple graph convolution,
- P m ( l ) P^{(l)}_m Pm(l) is the combination of the comprehensive user embeddings and P r ( l ) P^{(l)}_r Pr(l)
- D u ∈ R m × m D_u\in R^{m\times m} Du∈Rm×m and D i ∈ R n × n D_i \in R^{n\times n} Di∈Rn×n are degree matrices of R R R and R ⊤ R^{\top} R⊤, respectively,
- Finally, we obtain the final user and item embeddings P P P and Q Q Q defined as:
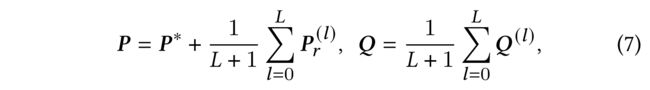
where P ( 0 ) P^{(0)} P(0) and Q ( 0 ) Q^{(0)} Q(0) are randomly initialized.
3.2.4 Model Optimization
-
(1) To learn the parameters of MHCN, we employ the Bayesian Personalized Ranking (BPR) loss [30], which is a pairwise loss that promotes an observed entry to be ranked higher than its unobserved counterparts: (为了学习MHCN的参数,我们使用了贝叶斯个性化排序(BPR)损失,这是一个成对的损失,它使得了一个观测到的条目比未观测到的条目更高)
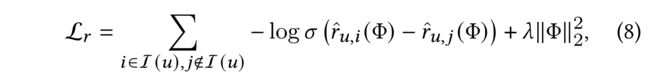
- where Φ \Phi Φ denotes the parameters of MHCN, r ^ u , i = p u ⊤ q i \hat{r}_{u,i} = p^{\top}_u q_i r^u,i=pu⊤qi is the predicted score of u u u on i i i,
- and σ ( ⋅ ) \sigma(\cdot) σ(⋅) here is the sigmoid function.
-
(2) Each time a triplet including the current user u u u, the positive item i i i purchased by u u u, and the randomly sampled negative item j j j which is disliked by u u u or unknown to u u u, is fed to MHCN (每次一个三元组都被输入到MHCN,这个三元组包括当前用户、被购买的正项和随机抽取的负项目 ,负项目是用户不喜欢的或未知的项目)
-
(3) he model is optimized towards ranking i i i higher than h h h in the recommendation list for u u u. (该模型经过优化,在的推荐列表中排名高于)
-
(4) In addition, L 2 L_2 L2 regularization with the hyper-parameter λ \lambda λ is imposed to reduce generalized errors. (此外,还采用了具有超参数的2正则化方法来减少广义误差)
3.3 Enhancing MHCN with Self-Supervised Learning
Owing to the exploitation of high-order relations, MHCN shows great performance (reported in Table 3 and 4).
阐述为什么要引入自监督学习
- (1) However, a shortcoming of MHCN is that the aggregation operations (Eq. 5 and 6) might lead to a loss of high-order information, as different channels would learn embeddings with varying distributions on different hyper-graphs [54] (由于利用了高阶关系,MHCN表现出了很好的性能(见表3和表4),然而,MHCN的一个缺点是聚合操作(公式 5和6)可能会导致高阶信息的丢失,因为不同的通道会在不同的超图上学习不同分布的嵌入) (遇到的困难,过程中的一个挑战)
- (2) . Concatenating the embeddings from different channels could be the alternative, but it uniformly weighs the contributions of different types of high-order information in recommendation generation, which is not in line with the reality and leads to inferior performance in our trials. (将来自不同渠道的嵌入信息拼接是一种选择,但它统一衡量(认为贡献都是一样的)了不同类型高阶信息在推荐生成中的贡献,这与实际情况不符,导致我们的试验性能较差)
- (3) To address this issue and fully inherit the rich information in the hypergraphs, we innovatively integrate self-supervised learning into the training of MHCN. (为了解决这个问题,并充分继承超图中丰富的信息,我们创新地将自监督学习融入到MHCN的训练中。)
本文是如何引入的
-
(4) In the scenarios of representation learning, self-supervised task usually either serves as a pretraining strategy or an auxiliary task to improve the primary task [17] (在表示学习中,自监督任务通常作为训练前的策略,或者作为改善主要任务的辅助任务)
-
(5) In this paper, we follow the p r i m a r y & a u x i l i a r y primary \& auxiliary primary&auxiliary paradigm, and set up a self-supervised auxiliary task to enhance the recommendation task (primary task). (在本文中,我们遵循主、辅范例,设置一个自监督的辅助任务来增强推荐任务(主任务))
-
(6) The recent work Deep Graph Infomax (DGI) [37] is a general and popular approach for learning node representations within graph-structured data in a self-supervised manner. (Deep Graph Infomax (DGI)是一种通用和流行的方法,用于以自我监督的方式学习图结构数据中的节点表示)
- It relies on maximizing mutual information (MI) between node representations and corresponding high-level summaries of graph . (它依赖于去最大化节点表示和相应的图的高级摘要之间的互信息)
-
(7) However, we consider that the graph-node MI maximization stays at a coarse level and there is no guarantee that the encoder in DGI can distill sufficient information from the input data. (然而,我们认为图节点互信息最大化停留在一个粗糙的级别,并不能保证DGI中的编码器能够从输入数据中提取足够的信息)
-
(8) Therefore, with the increase of the graph scale, the benefits brought by MI maximization might diminish. For a better learning method which fits our scenario more, we inherit the merits of DGI to consider mutual information and further extend the graph-node MI maximization to a fine-grained level by exploiting the hierarchical structure in hypergraphs. (因此,随着图规模的增加,互信息最大化带来的效果可能会减少。为了更好地适应我们的场景,我们继承了DGI考虑互信息的优点,并利用超图中的层次结构将图节点互信息最大化扩展到精确的级别。)
-
(9) Recall that, for each channel of MHCN, we build the adjacency matrix A c A_c Ac to capture the high-order connectivity information.
- Each row in A c A_c Ac represents a subgraph of the corresponding hypergraph centering around the user denoted by the row index. (中的每一行都表示以行索引表示的用户为中心的相应超图的子图)
- Then we can induce a hierarchy:‘user node← user-centered sub-hypergraph← hypergraph’ and create self-supervision signals from this structure. (然后我们可以引出一个层次结构:“用户节点←以用户为中心的子超图←超图”,并从该结构创建自监督信号)
- Our intuition of the self-supervised task is that the comprehensive user representation should reflect the user node’s local and global high-order connectivity patterns in different hypergraphs, and this goal can be achieved by hierarchically maximizing the mutual information between representations of the user, the user-centered sub-hypergraph, and the hypergraph in each channel. (我们对自我监督任务的直觉是,全面的用户表示应该反映用户节点在不同超图中的局部和全局的高阶连接模式,可以通过分层最大化(用户表示、以用户为中心的子超图和每个通道中的超图)之间的互信息来实现这一目标。)
- The mutual information measures the structural informativeness of the sub- and the whole hypergraph towards inferring the user preference through the reduction in local and global structure uncertainty. (互信息测量子图和整个超图的结构信息量,以通过降低局部和全局结构的不确定性来推断用户偏好)
-
(10) To get the sub-hypergraph representation, instead of averaging the embeddings of the users in the sub-hypergraph, we design a readout function f o u t 1 : R k × d → R d f_{out_1} : R^{k\times d} \to R^d fout1:Rk×d→Rd , which is permutation-invariant and formulated as: (为了获得子超图的表示,而不是平均用户在子超图中的嵌入,我们设计了一个函数 ,它的序列是不变的,并表述为:)
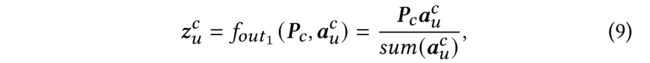
- where P c = f g a t e c ( P ) P_c=f^c_{gate}(P) Pc=fgatec(P) is to control the participated magnitude of P P P to avoid overfitting and mitigate gradient conflict between the primary and auxiliary tasks, (是控制的参与幅度,以避免过拟合 且减轻主任务和辅助任务之间的梯度冲突)
- α u c \alpha^c_u αuc is the is the row vector of A c A_c Ac corresponding to the center user u u u (与中心用户 u u u对应的 A c A_c Ac的行向量)
- and s u m ( α u c ) sum(\alpha^c_u) sum(αuc) denotes how many connections in the sub-hypergraph (表示子超图中有多少个连接)
- In this way, the weight (importance) of each user in the sub-hypergraph is considered to form the sub-hypergraph embedding z u z_u zu. (这样,就考虑了子超图中每个用户的权重,形成子超图嵌入 z u z_u zu)
-
(11) Analogously, we define the other readout function f o u t 2 : R m × d → R d f_{out_2} : R^{m\times d} \to R^d fout2:Rm×d→Rd, which is actually an average pooling to summarize the obtained sub-hypergraph embeddings into a graph-level representation: (类似地,我们定义了另一个函数, 这实际上是一个平均池化,将获得的子超图嵌入到一个图级表示中)

-
(12) We follow DGI and use InfoNCE [27] as our learning objective to maximize the hierarchical mutual information. But we find that, compared with the binary cross-entropy loss, the pairwise ranking loss, which has also been proved to be effective in mutual information estimation[18], is more compatible with the recommendation task. We then define the objective function of the self-supervised task as follows: (我们遵循DGI,使用InfoNCE作为我们的学习目标,以最大化层次互信息。但我们发现,与二元交叉熵损失相比,成对排序损失(在互信息估计中也被证明是有效的)更适合推荐任务。因此定义自监督任务的目标函数如下:)
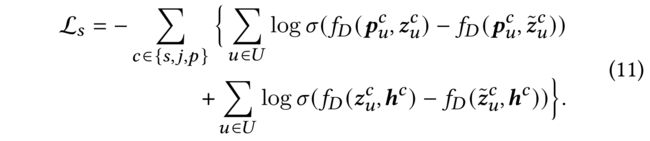
- f D ( ⋅ ) : R d × R d → R f_D(\cdot): R_d \times R^d \to R fD(⋅):Rd×Rd→R is the discriminator function that takes two vectors as the input and then scores the agreement between them. (是一种鉴别器函数,它以两个向量作为输入,然后对它们之间的一致性进行评分)
- We simply implement the discriminator as the dot product between two representations. (我们简单地将鉴别器实现为两个表示之间的点积)
- Since there is a bijective mapping between P c P_c Pc and Z c Z_c Zc , they can be the ground truth of each other. (由于在和之间有一个双射映射,它们可以相互推出彼此)
- We corrupt Z c Z^c Zc by both row-wise and column-wise shuffling to create negative examples Z ~ c \tilde{Z}_c Z~c (我们破坏,通过行顺序和列顺序的打乱来创建负样本 Z ~ c \tilde{Z}_c Z~c)
-
(13) We consider that, the user should have a stronger connection with the sub-hypergraph centered with her (local structure), so we directly maximize the mutual information between their representations. (我们认为,用户应该与以它为中心的子超图(局部结构)有更强的联系,所以我们直接最大化了他们的表示之间的互信息)
-
(14) By contrast, the user would not care all the other users too much (global structure), so we indirectly maximize the mutual information between the representations of the user and the complete hypergraph by regarding the sub-hypergraph as the mediator. (相比之下,用户不会太关心其他所有用户(全局结构),因此我们以子超图为中介,间接地最大化了用户表示与完全超图之间的互信息)
-
(15) Compared with DGI which only maximizes the mutual information between node and graph representations, our hierarchical design can preserve more structural information of the hypergraph into the user representations (comparison is shown in Section 4.3) (与仅最大化节点与图表示之间互信息的DGI相比,我们的分层设计可以将更多超图的结构信息保留到用户表示中(对比见4.3节))
- Figure 4 illustrates the hierarchical mutual information maximization.(分层互信息最大化)

- Figure 4 illustrates the hierarchical mutual information maximization.(分层互信息最大化)
-
(16) Finally, we unify the objectives of the recommendation task (primary) and the task of maximizing hierarchical mutual information (auxiliary) for joint learning. The overall objective is defined as:. (最后,我们将推荐任务的目标(主要的)和最大化层次互信息的任务(辅助的)统一起来进行联合学习。总体目标定义为:)
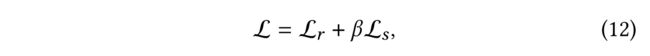
- where β \beta β is a hyper-parameter used to control the effect of the auxiliary task and L s \mathcal{L}_s Ls can be seen as a regularizer leveraging hierarchical structural information of the hypergraphs to enrich the user representations in the recommendation task for a better performance. (其中,是一个用于控制辅助任务效果的超参数,而L可以看作是一个正则化器,利用超图的层次结构信息来丰富推荐任务中的用户表示,以获得更好的性能)
3.4 Complexity Analysis
In this section, we discuss the complexity of our model.
3.4.1 Model size
-
(1) The trainable parameters of our model consist of three parts: (们的模型的可训练参数由三个部分组成:)
- user and item embeddings, (用户和项目嵌入)
- gate parameters, and (门参数)
- attention parameters. (注意力参数)
-
(2) For the first term, we only need to learn the 0 t h 0^{th} 0th layer user embeddings P ( 0 ) ∈ R m × d P^{(0)}\in R^{m\times d} P(0)∈Rm×d and item embeddings Q ( 0 ) ∈ R n × d Q^{(0)} \in R^{n\times d} Q(0)∈Rn×d
-
(3) As for the second term, we employ 7 gates
- 4 for MHCN and
- 3 for the self-supervised task
- Each of the gate has parameters of size ( d + 1 ) × d (d+1)\times d (d+1)×d, while the attention parameters are of the same size. (每个门都有(+1)×个参数,注意力参数的也是相同的大小)
-
(4) To sum up, the model size approximates ( m + n + 8 d ) d (m+n+8d) d (m+n+8d)d in total. As m i n ( m , n ) ≫ d min(m, n) \gg d min(m,n)≫d, our model is fairly light.
3.4.2 Time complexity
-
(1) The computational cost mainly derives from 4 parts:
- hypergraph/graph convolution, (超图/图卷积)
- attention, (注意力)
- self-gating, (门控) and
- mutual information maximization (互信息最大化)
-
(2) For the multi-channel hyper-graph convolution through퐿 layers, the propagation consumption is less than O ( ∣ A + ∣ d L ) O(|A^+|dL) O(∣A+∣dL)
- where A + A^+ A+ denotes the number of nonzero elements in A A A, (表示中非零元素的数量)
- and here ∣ A + ∣ = m a x ( ∣ A s + ∣ , ∣ A j + ∣ , ∣ A p + ∣ ) |A^+| = max(|A^+_s|, |A^+_j|, |A^+_p|) ∣A+∣=max(∣As+∣,∣Aj+∣,∣Ap+∣)
-
(3) Analogously, the time complexity of the graph convolution is O ( ∣ R + ∣ d L ) O(|R^+|dL) O(∣R+∣dL).
-
(4) As for the attention and self gating mechanism, they both contribute O ( m d 2 ) O(md^2) O(md2) time complexity
-
(5) The cost of mutual information maximization is mainly from f o u t 1 f_{out_1} fout1, which is O ( ∣ A + ∣ d ) O(|A^+|d) O(∣A+∣d).
-
(6) Since we follow the setting in LigthGCN to remove the learnable matrix for linear transformation and the nonlinear activation function, the time complexity of our model is much lower than that of previous GNNs-based social recommendation models. (由于我们按照LightGCN中的设置, 去除了线性变换的可学习矩阵和非线性激活函数,我们的模型的时间复杂度大大低于以往基于GNNs的社会推荐模型)
4 EXPERIMENTS AND RESULTS
In this section, we conduct extensive experiments to validate our model. The experiments are unfolded by answering the following three questions:
- (1) Does MHCN outperform the state-of-the-art baselines?
- (2) Does each component in MHCN contribute?
- (3) How do the hyper-parameters ( β \beta β and the depth of MHCN) influence the performance of MHCN?
4.1 Experimental Protocol
4.1.1 Datasets.
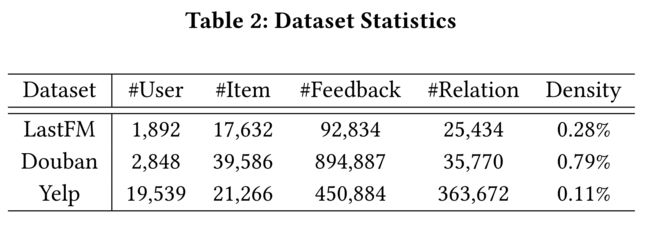
Three real-world datasets: LastFM1, Douban2, and Yelp [49] are used in our experiments. As our aim is to generate Top-K recommendation, for Douban which is based on explicit ratings, we leave out ratings less than 4 and assign 1 to the rest(这个操作有点迷啊!!!!????). The statistics of the datasets is shown in Table 2. We perform 5-fold cross-validation on the three datasets and report the average results.
4.1.2 Baselines.
We compare MHCN with a set of strong and commonly-used baselines including MF-based and GNN-based models:
- BPR [30] is a popular recommendation model based on Bayesian personalized ranking. It models the order of candidate items by a pairwise ranking loss.(BPR是一种流行的基于贝叶斯个性化排名的推荐模型。它通过成对损失排序来模拟候选项的顺序)
- SBPR [61] is a MF based social recommendation model which extends BPR and leverages social connections to model the relative order of candidate items.(SBPR是一种基于MF的社交推荐模型,它扩展了BPR,并使用社交联系来建模候选项的相对顺序)
- LightGCN [14] is a GCN-based general recommendation model that leverages the user-item proximity to learn node representations and generate recommendations, which is reported as the state-of-the-art method. (LightGCN是一个基于GCN的一般推荐模型,它利用用户-项目的接近性来学习节点表示并生成推荐,这被认为是最先进的方法)
- GraphRec [9] is the first GNN-based social recommendation model that models both user-item and user-user interactions.(GraphRec是第一个基于GNN的社交推荐模型,它同时建模了用户-项目和用户-用户的交互)
- DiffNet++ [40] is the latest GCN-based social recommendation method that models the recursive dynamic social diffusion in both the user and item spaces.(它建模了用户和项目空间的递归动态社交扩散。)
- DHCF [16] is a recent hypergraph convolutional network-based method that models the high-order correlations among users and items for general recommendation. (DHCF是一种最新的基于超图卷积网络的方法,对用户和项目之间的高阶相关性进行建模,用于一般推荐) (可能是根据这篇论文改的)
Two versions of the proposed multi-channel hypergraph convolutional network are investigated in the experiments. MHCN denotes the vanilla version and S 2 S^2 S2-MHCN denotes the self-supervised version. (实验研究了两种版本的多通道超图卷积网络。MHCN表示普通的版本, S 2 S^2 S2-MHCN表示自我监督的版本
4.1.3 Metrics.
To evaluate the performance of all methods, two relevancy-based metrics Precision@10 and Recall@10 and one ranking-based metric NDCG@10 are used. We perform item ranking on all the candidate items instead of the sampled item sets to calculate the values of these three metrics, which guarantees that the evaluation process is unbiased.(为了评估所有方法的性能,我们使用了两个基于相关性的指标Precision@10和Recall@10,以及一个基于排名的指标NDCG@10。我们对所有的候选项目进行项目排序,而不是对抽样的项目集来计算这三个指标,这保证了评估过程是公平的)
4.1.4 Settings
For a fair comparison, we refer to the best parameter settings reported in the original papers of the baselines and then
use grid search to fine tune all the hyperparameters of the baselines to ensure the best performance of them. For the general settings of all the models, the dimension of latent factors (embeddings) is empirically set to 50, the regularization coefficient λ \lambda λ = 0.001, and the batch size is set to 2000. We use Adam to optimize all these models. Section 4.4 reports the influence of different parameters (i.e. β \beta β and the depth) of MHCN, and we use the best parameter settings in Section 4.2, and 4.3 (为了比较公平,我们参考基线原始文献中报道的最佳参数设置,然后使用网格搜索对基线的所有超参数进行微调,以确保基线的最佳性能。对于所有模型的统一设置,将潜在因素嵌入的维数设置为50,正则化系数 = 0.001,批量大小设置为2000。我们使用Adam(优化器)来优化所有这些模型。第4.4节报告了不同参数的影响。我们在第4.2节和第4.3节中使用了最佳
4.2 Recommendation Performance


4.3 Ablation Study
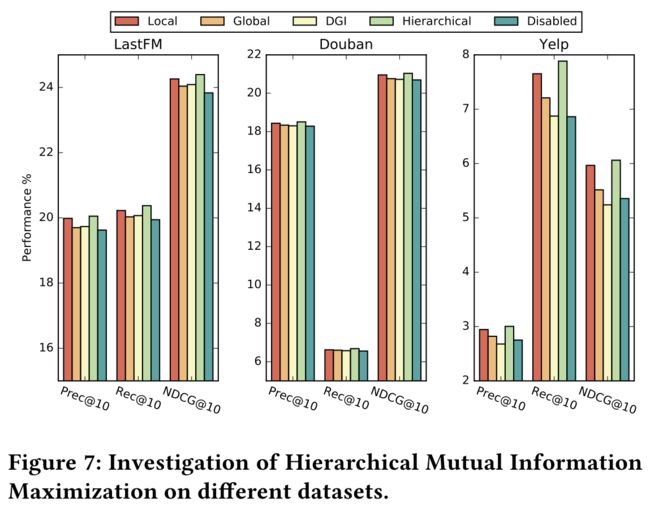
4.3.1 Investigation of Multi-Channel Setting.

4.3.2 Investigation of Self-supervised Task
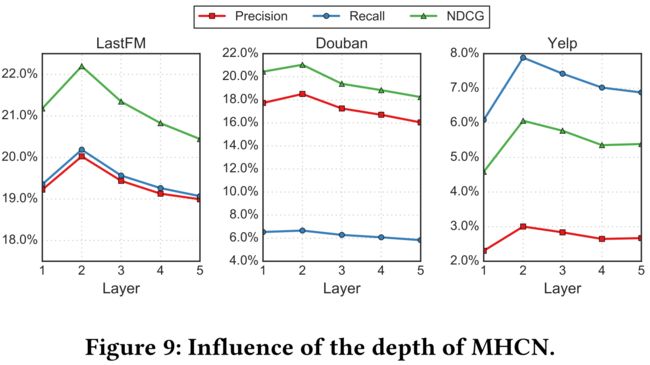
4.4 Parameter Sensitivity Analysis

5 Conclusion
Acknowledgment
- (1) Recently, GNN-based recommendation models have achieved great success in social recommendation. However, these methods simply model the user relations in social recommender systems as pairwise interactions, and neglect that real-world user interactions can be high-order. (近年来,基于GNN的推荐模型在社会推荐中取得了很大的成功。然而,这些方法只是简单地将社交推荐系统中的用户关系建模为成对的交互,而忽略了现实世界中的用户交互可能是高阶的)
- (2) Hypergraph provides a natural way to model high-order user relations, and its potential for social recommendation has not been fully exploited. In this paper,we fuse hypergraph modeling and graph neural networks and then propose a multi-channel hypergraph convolutional network (MHCN) which works on multiple motif-induced hypergraphs to improve social recommendation. (超图提供了一种自然的方式来建模高阶用户关系,但其社交推荐的潜力尚未得到充分开发。本文将超图建模与图神经网络相融合,提出了一种基于多个motif主题(图)诱导的超图的多通道超图卷积网络(MHCN) 来提高社交推荐)
- (3) To compensate for the aggregating loss in MHCN, we innovatively integrate self-supervised learning into the training of MHCN. (为了弥补MHCN中聚合的损失,我们创新性地将自监督学习融入到MHCN的训练中)
- The self-supervised task serves as the auxiliary task to improve the recommendation task by maximizing hierarchical mutual information between the user, user-centered sub-hypergraph, and hypergraph representations .(自监督任务作为辅助任务,通过最大化用户、以用户为中心的子超图和超图表示之间的层级互信息来促进推荐任务)
- (4) The extensive experiments conducted on three public datasets verify the effectiveness of each component of MHCN, and also demonstrate its state-of-the-art performance. (在三个公共数据集上进行的大量实验验证了MHCN各组件的有效性,并展示了其最先进的性能) (说自己很SOTA…)