目标检测Faster R-CNN+YOLO
目标检测
当做回归任务:一个框4个值,输出层的节点个数为4k,节点数无法确定,可以准确地具体框的大小
当做分类任务:滑动窗口,对每个窗口的物体分类,则节点数就是分类数,但框的大小是固定的,因此需要设计大小不同的框,计算量大
回归+分类,多任务学习:框出一个区域+分类是object,则回归框
图像金字塔:框大小固定,缩放图片
古典目标识别(没有回归,只有分类)
选择搜索:图像中物体可能存在的区域应该是具有某些相似性或者连续性区域的,ss基于这样想法采用子区域合并的方法进行提取boundingboxes 候选框区域。(将层次聚类的思想应用与区域合并)
①对输入图像进行分割算法产生许多小的子区域
②根据这些子区域之间的相似性(颜色、纹理、大小等)进行区域合并,不断进行区域迭代合并。
③每次迭代过程中对这些合并的子区域做boundingboxes(外切矩形),这些子区域外切矩形就是通常所说的候选框。
Select Search+cls
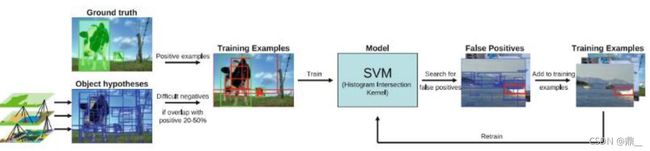
①训练集构造
负样本:ss提取出来的候选框与gt的重合度(IOU)在20%-50%之间,且与其他的任何一个已经生成的负样本的重合度不大于70%,则为负样本。(正负例均衡,如果负样本太多,将会影响模型偏向学习负样本,模型泛化能力减弱)正样本:gt
②将样本输入分类器svm分类
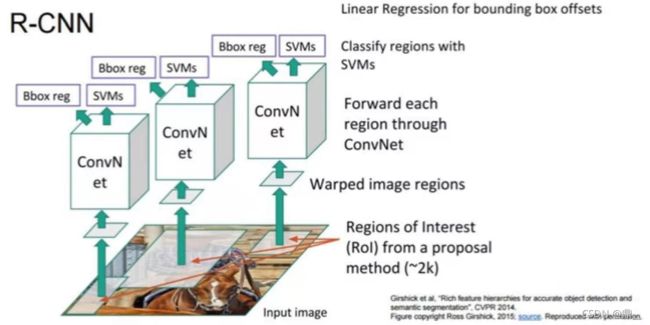
R-CNN
与古典目标检测相比:①增加了卷积网络提取特征②增加回归校正框的大小和坐标
校正:学习相对于候选框的残差△x,△y,△w,△h,而不是从头开始学习一个从正无穷到负无穷的值,更加容易学习
ss提取候选框约2000,resize成相同大小(svm和回归器需要固定大小),输入卷积网络(每个候选框对应一个卷积网络参数),然后将特征图输入回归器和分类器,分别做框的校正和目标的分类
训练:先在卷积网路连接交叉熵损失训练网络,然后接上回归器和分类器训练(分开训练,svm无法用神经网络表达)
问题:①不是端到端②提特征的loss和分类回归的loss不同,cnn和分类回归学习目标不同
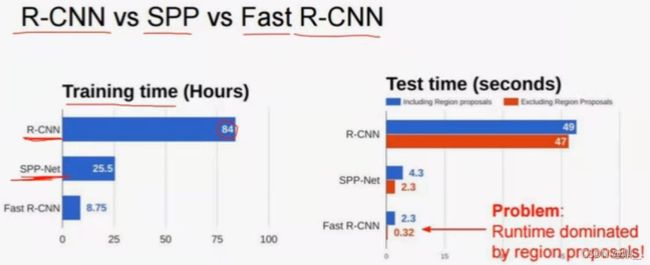
①resize导致信息丢失②2000次计算,计算量大,信息重复计算③ss秒级时间
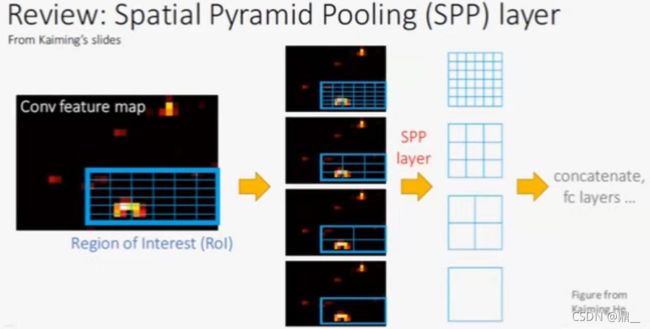
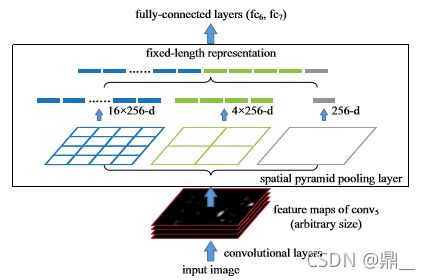
SPP-net
空间金字塔池化(resize作用)
相当于将候选框对应的特征图上的区域平均分成36、9、4、1份,再在每份中取均值或取最大
只有一个卷积网络,将SS提出的候选框映射到卷积之后的特征图上,做空间金字塔池化,每个候选框做回归和分类
 |
 |
|---|---|
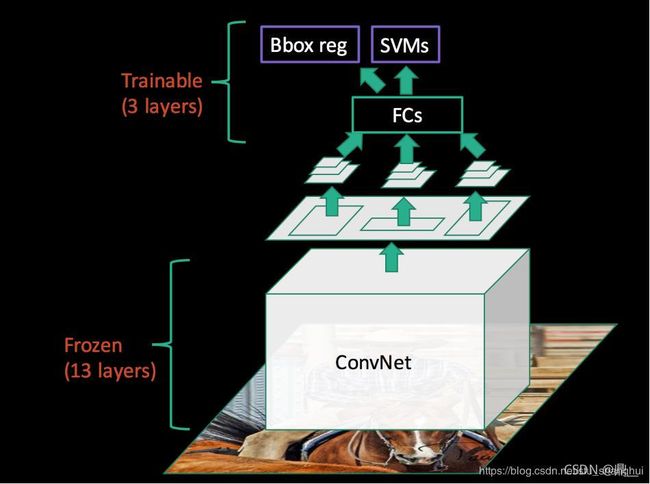 |
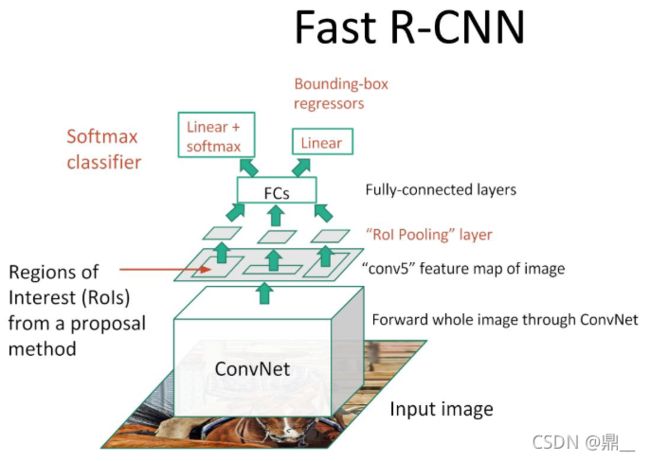
Fast R-CNN
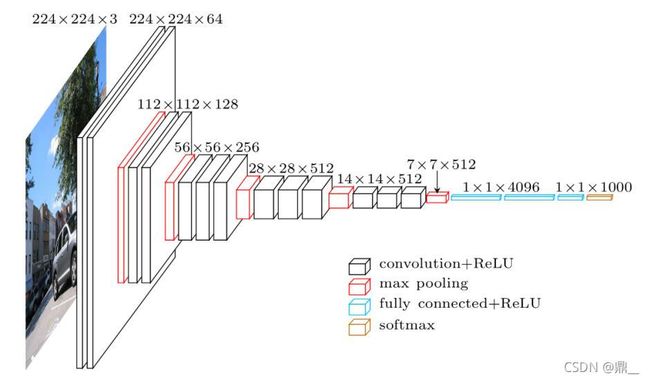
backbone使用VGG16
SS+vgg16+ROI Pooling +fcs+softmax,linear
ROI Pooling:只使用SPP layer中的一个尺度池化
softmax替换SVM
log loss + smooth L1 loss
 |
 |
|---|---|
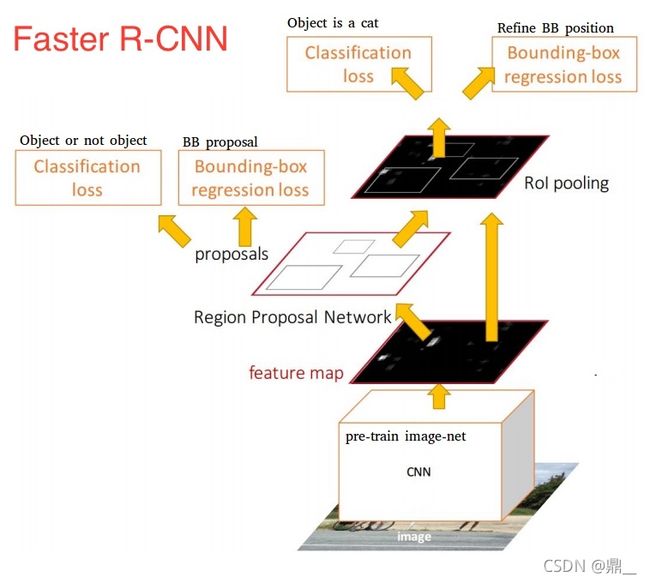
Faster R-CNN
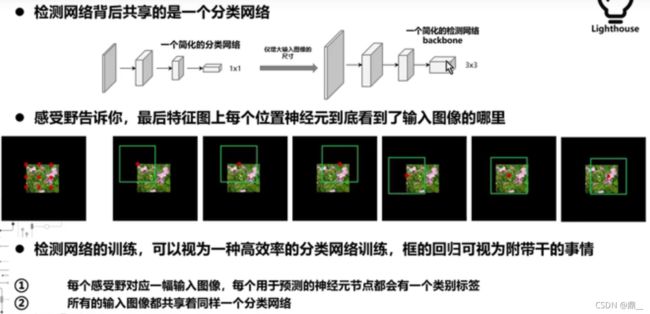
提出候选框,分类,微调边框
通过CNN提取候选框:RPN(注意力机制作用)
RPN做二分类,判断每一个滑动窗口对应的位置是不是物体,是物体,则作为候选框,是候选框则回归校正位置(粗校正)
分类器对9个锚框都做二分类
anchor与任意ground truth的IOU大于0.7则认为是正例
再在特征图上做映射,然后做ROI Pooling然后进行多分类和二次校正细校正
3×3×512×256 1×1×256×(2k+4k=18+36,k=9)
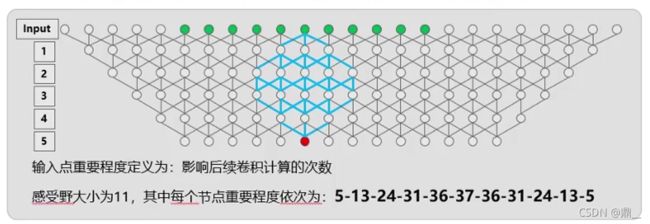
映射:14×14一个点对应原图16×16
感受野:228×288(做分类)
 |
 |
|---|---|
 |
 |
| – | – |
 |
 |
 |
|
| – | – |
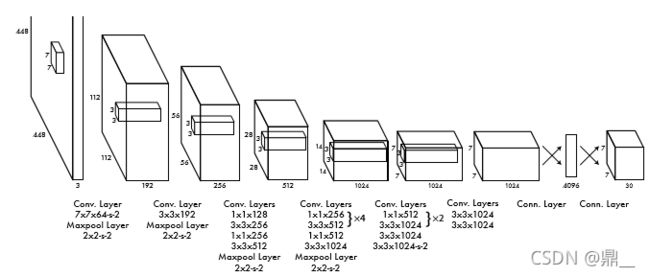
yolov1
在图片中划分cell,目标中心位置落在那个cell,就由哪个cell预测该物体
原图片中的一个cell与特征图的每个点一一对应
S ×S ×(B ∗5 + C)
网络架构受GoogLeNet模型的启发,网络有24个卷积层,其后是2个全连接的层。我们没用GoogLeNet使用的inception模块,只使用3×3和1×1卷积层。

yolov2
引入了anchor
使用kmeans聚类聚类出5个初始化anchor
bx = σ(tx) + cx by = σ(ty) + cy bw = pwetw bh = pheth
Pr(object)∗IOU(b,object) = σ(to)

yolov3
使用多个二分类代替softmax,如此以来,每个类别的概率相加就不需要等于1,类别概率之间不需相关。
加入颈部,相当于特征金字塔FPN
Darknet-53 has some short cut connections as well and is significantly larger
yolov4
曾经参与YOLO项目维护的Alexey Bochkovskiy接过了YOLO这面大旗,在arXiv上提交了YOLO v4,而且这篇论文已经被拉入原来YOLO之父建立的项目主线。YOLOv4是YOLO系列的集大成者,里面涉及了许多tricks的组合。YOLOv4主要是选取了许多features进行组合的形式来对数据集进行测试训练,从而来验证性能效果。
BOF
数据增强;focal loss 解决各类别样本数量不平衡;IOU,使位置四个值之间有关联->GIOU,解决框无重叠时,无梯度的问题->DIOU,中心电之间的关系->CIOU,宽高比例
BOS
SAM,空间注意力模块,激活函数Mish(与Ranger优化器同用);SoftNMS
使用CSPDarknet53(跨阶段局部网络)作为Backbone,并且使用了PANET(路径聚合网络)和SPP(空间金字塔池化)作为Neck,使用YOLO V3的Head。
yolov5
相对于yolov4的改进
1、Data Augmentation
YOLO V4使用了多种数据增强技术的组合,对于单一图片,使用了几何畸变,光照畸图像,遮挡(Random Erase,Cutout,Hide and Seek,Grid Mask ,MixUp)技术,对于多图组合,作者混合使用了CutMix与Mosaic 技术。除此之外,作者还使用了Self-Adversarial Training (SAT)来进行数据增强。
YOLOV5会通过数据加载器传递每一批训练数据,并同时增强训练数据。数据加载器进行三种数据增强:缩放,色彩空间调整和马赛克增强。据悉YOLO V5的作者Glen Jocher正是Mosaic Augmentation的创造者,故认为YOLO V4性能巨大提升很大程度是马赛克数据增强的功劳,也许你不服,但他在YOLO V4出来后的仅仅两个月便推出YOLO V5,不可否认的是马赛克数据增强确实能有效解决模型训练中最头疼的“小对象问题”,即小对象不如大对象那样准确地被检测到。
2、Auto Learning Bounding Box Anchors-自适应锚定框
yolo3中的锚框是预先利用kmeans定义好的,yolo4沿用了yolo3;
yolo5锚定框是基于训练数据自动学习的。个人认为算不上是创新点,只是手动改代码改为自动运行。
对于COCO数据集来说,YOLO V5 的配置文件*.yaml 中已经预设了640×640图像大小下锚定框的尺寸
对于自定义数据集来说,由于目标识别框架往往需要缩放原始图片尺寸,并且数据集中目标对象的大小可能也与COCO数据集不同,因此YOLO V5会重新自动学习锚定框的尺寸。
3、Activation Function
yolo5的作者使用了 Leaky ReLU 和 Sigmoid 激活函数。yolo5中中间/隐藏层使用了 Leaky ReLU 激活函数,最后的检测层使用了 Sigmoid 形激活函数。而YOLO V4使用Mish激活函数。
4、Optimization Function
YOLO V5的作者提供了两个优化函数Adam和SGD(默认),并都预设了与之匹配的训练超参数。
YOLO V4使用SGD。
YOLO V5的作者建议是,如果需要训练较小的自定义数据集,Adam是更合适的选择,尽管Adam的学习率通常比SGD低。但是如果训练大型数据集,对于YOLOV5来说SGD效果比Adam好。
实际上学术界上对于SGD和Adam哪个更好,一直没有统一的定论,取决于实际项目情况。
5、Cost Function
YOLO 系列的损失计算是基于 objectness score, class probability score,和 bounding box regression score.
YOLO V5使用 GIOU Loss作为bounding box的损失。
YOLO V5使用二进制交叉熵和 Logits 损失函数计算类概率和目标得分的损失。同时我们也可以使用fl_ gamma参数来激活Focal loss计算损失函数。
YOLO V4使用 CIOU Loss作为bounding box的损失,与其他提到的方法相比,CIOU带来了更快的收敛和更好的性能。
YOLO V4和YOLO V5实际上整合了计算机视觉领域的State-of-the-art,从而显著改善YOLO对象检测的性能。