【分布外检测】《Energy-based Out-of-distribution Detection》 NIPS‘20
《Energy-based Out-of-distribution Detection》 NIPS’20
不改变模型结构,在任意模型上用能量函数替代softmax函数,识别输入数据是否为异常样本。还提出一个基于能量的正则化项,用来针对性fine-tuning模型。
解决什么问题
当模型遇到和训练数据差别很大的数据时,就会出现out-of-distribution (OOD)uncertainty,这个时候模型表现很差。识别出这些OOD数据很重要,比如对抗样本、异常检测。
传统的OOD检测方法是基于softmax confidence,即对于ID数据,模型会给一个高可信度的结果,对于可信度低的就是OOD样本。但是也可能会给OOD样本高可信度(比如对抗样本)。
这篇文章提出一个energy function来替换softmax函数识别OOD,ID样本能量低,OOD样本能量高。
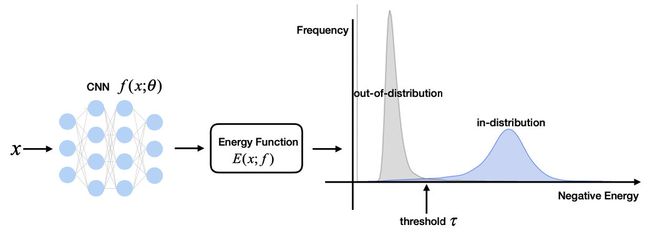
什么是能量模型(EBM)
能量模型最早由LeCun在2006年提出,本质构建一个能连函数 E ( x ) : R D → R E(x): \mathbb{R}^{D} \rightarrow \mathbb{R} E(x):RD→R,将输入空间的每个样本 x x x映射到一个表示能量的非概率标量上。然后通过Gibbs分布可以将能量转化为概率密度:
p ( y ∣ x ) = e − E ( x , y ) / T ∫ y ′ e − E ( x , y ′ ) / T = e − E ( x , y ) / T e − E ( x ) / T (1) p(y \mid \mathbf{x})=\frac{e^{-E(\mathbf{x}, y) / T}}{\int_{y^{\prime}} e^{-E\left(\mathbf{x}, y^{\prime}\right) / T}}=\frac{e^{-E(\mathbf{x}, y) / T}}{e^{-E(\mathbf{x}) / T}} \tag{1} p(y∣x)=∫y′e−E(x,y′)/Te−E(x,y)/T=e−E(x)/Te−E(x,y)/T(1)
其中分母被称为配分函数, T T T是温度参数。此时对于任意样本的能量 E ( x ) E(x) E(x)为:
E ( x ) = − T ⋅ log ∫ y ′ e − E ( x , y ′ ) / T (2) E(\mathbf{x})=-T \cdot \log \int_{y^{\prime}} e^{-E\left(\mathbf{x}, y^{\prime}\right) / T} \tag{2} E(x)=−T⋅log∫y′e−E(x,y′)/T(2)
对于一个 K K K类的神经网络分类器 f ( x ) : R D → R K f(x): \mathbb{R}^{D} \rightarrow \mathbb{R}^{K} f(x):RD→RK将输入映射到 K K K个对数值,通过softmax得到当前样本属于某一类的概率:
p ( y ∣ x ) = e f y ( x ) / T ∑ i = 1 K e f i ( x ) / T (3) p(y \mid x)=\frac{e^{f_{y}(x) / T}}{\sum_{i=1}^{K} e^{f_{i}(x) / T}} \tag{3} p(y∣x)=∑i=1Kefi(x)/Tefy(x)/T(3)
这里 f y ( x ) f_y(x) fy(x)对应第 y y y类标签的logit值。到这里我们可以将输入 ( x , y ) (x,y) (x,y)的能量值表示为负的 f y ( x ) f_y(x) fy(x),这样就在原始神经网络分类器和能量模型之间建立起了联系,我们可以用softmax函数的分母来表示当前输入样本 x x x的能量:
E ( x ; f ) = − T ⋅ log ∑ i K e f i ( x ) / T (4) E(\mathbf{x} ; f)=-T \cdot \log \sum_{i}^{K} e^{f_{i}(\mathbf{x}) / T} \tag{4} E(x;f)=−T⋅logi∑Kefi(x)/T(4)
这里样本 x x x的能量已经与样本的标签无关了,就是关于 f ( x ) f(x) f(x)的一个标量。
基于能量的OOD检测
能量异常分数,行
OOD检测实际上是一个二分类问题,用能量函数来构建判别模型的密度函数:
p ( x ) = e − E ( x ; f ) / T ∫ x e − E ( x ; f ) / T (5) p(\mathbf{x})=\frac{e^{-E(\mathbf{x} ; f) / T}}{\int_{\mathbf{x}} e^{-E(\mathbf{x} ; f) / T}} \tag{5} p(x)=∫xe−E(x;f)/Te−E(x;f)/T(5)
其中分母配分函数 Z = ∫ x e − E ( x ; f ) / T Z=\int_{\mathbf{x}} e^{-E(\mathbf{x} ; f) / T} Z=∫xe−E(x;f)/T。上式取对数:
log p ( x ) = − E ( x ; f ) / T − log Z ⏟ constant for all x (6) \log p(\mathbf{x})=-E(\mathbf{x} ; f) / T-\underbrace{\log Z}_{\text {constant for all x }} \tag{6} logp(x)=−E(x;f)/T−constant for all x logZ(6)
上式表明 − E ( x ; f ) -E(x;f) −E(x;f)实际上与对数似然函数是线性对齐的,低能量意味着高似然(ID),高能量意味着低似然(OOD)。那么设置一个阈值 τ \tau τ就可以分类了:
G ( x ; τ , f ) = { 0 if − E ( x ; f ) ≤ τ 1 if − E ( x ; f ) > τ (7) G(\mathbf{x} ; \tau, f)=\left\{\begin{array}{ll} 0 & \text { if }-E(\mathbf{x} ; f) \leq \tau \\ 1 & \text { if }-E(\mathbf{x} ; f)>\tau \end{array}\right. \tag{7} G(x;τ,f)={01 if −E(x;f)≤τ if −E(x;f)>τ(7)
其中阈值 τ \tau τ是从正常样本数据分布统计得到的。
softmax函数,不行
文章里为什么要提上面“与似然函数线性对齐”的事呢?因为可以推出softmax置信分数对不齐。先推导出能量分数和softmax置信分数之间的联系:
max y p ( y ∣ x ) = max y e f y ( x ) ∑ i e f i ( x ) = e f max ( x ) ∑ i e f i ( x ) = 1 ∑ i e f i ( x ) − f max ( x ) ⟹ log max y p ( y ∣ x ) = E ( x ; f ( x ) − f max ( x ) ) = E ( x ; f ) + f max ( x ) (8) \begin{aligned} \max _{y} p(y \mid \mathbf{x}) &=\max _{y} \frac{e^{f_{y}}(\mathbf{x})}{\sum_{i} e^{f_{i}(\mathbf{x})}}=\frac{e^{f^{\max }(\mathbf{x})}}{\sum_{i} e^{f_{i}(\mathbf{x})}} \\ &=\frac{1}{\sum_{i} e^{f_{i}(\mathbf{x})-f^{\max }(\mathbf{x})}} \\ \Longrightarrow \log \max _{y} p(y \mid \mathbf{x}) &=E\left(\mathbf{x} ; f(\mathbf{x})-f^{\max }(\mathbf{x})\right)=E(\mathbf{x} ; f)+f^{\max }(\mathbf{x}) \end{aligned} \tag{8} ymaxp(y∣x)⟹logymaxp(y∣x)=ymax∑iefi(x)efy(x)=∑iefi(x)efmax(x)=∑iefi(x)−fmax(x)1=E(x;f(x)−fmax(x))=E(x;f)+fmax(x)(8)
把公式(6)带入,令 T = 1 T=1 T=1:
log max y p ( y ∣ x ) = − log p ( x ) + f max ( x ) − log Z ⏟ Not constant. Larger for in-dist x (9) \log \max _{y} p(y \mid \mathbf{x})=-\log p(\mathbf{x})+\underbrace{f^{\max }(\mathbf{x})-\log Z}_{\text {Not constant. Larger for in-dist } \mathbf{x}} \tag{9} logymaxp(y∣x)=−logp(x)+Not constant. Larger for in-dist x fmax(x)−logZ(9)
这里后两项 f max ( x ) − log Z f^{\max }(\mathbf{x})-\log Z fmax(x)−logZ不是一个常数,相反,对于ID样本,其负对数似然期望是更小的,但是 f m a x ( x ) f^{max}(x) fmax(x)这个分类之心度却是越大越好,这二种冲突。这一定程度上解释了基于softmax confidence方法的问题。
能量边界学习
在相同模型上,能量函数已经比softmax函数好了,那要是能有针对性的fine-tuning一下就更好了。作者就提出了一种能量边界目标函数来fine-tuning网络:
min θ E ( x , y ) ∼ D in tain [ − log F y ( x ) ] + λ ⋅ L energy (10) \min _{\theta} \mathbb{E}_{(\mathbf{x}, y) \sim \mathcal{D}_{\text {in }}^{\text {tain }}}\left[-\log F_{y}(\mathbf{x})\right]+\lambda \cdot L_{\text {energy }} \tag{10} θminE(x,y)∼Din tain [−logFy(x)]+λ⋅Lenergy (10)
其中第一项是标准的交叉熵损失函数,作用在ID训练数据上。第二项是一个基于能量的正则化项:
L energy = E ( x in , y ) ∼ D in train ( max ( 0 , E ( x in ) − m in ) ) 2 + E x out ∼ D out train max ( 0 , m out − E ( x out ) ) ) 2 \begin{aligned} L_{\text {energy }} &=\mathbb{E}_{\left(\mathbf{x}_{\text {in }}, y\right) \sim \mathcal{D}_{\text {in }}^{\text {train }}}\left(\max \left(0, E\left(\mathbf{x}_{\text {in }}\right)-m_{\text {in }}\right)\right)^{2} \\ &\left.+\mathbb{E}_{\mathbf{x}_{\text {out }} \sim \mathcal{D}_{\text {out }}^{\text {train }}} \max \left(0, m_{\text {out }}-E\left(\mathbf{x}_{\text {out }}\right)\right)\right)^{2} \end{aligned} Lenergy =E(xin ,y)∼Din train (max(0,E(xin )−min ))2+Exout ∼Dout train max(0,mout −E(xout )))2
惩罚能量高于 m i n m_{in} min的ID数据和能量低于 m o u t m_{out} mout的ODD数据,来拉远正常数据和异常数据分布之间的距离。
实验
实验是用SVHN、CIFAR-10和CIFAR-100作为正常样本数据集,另外六个OOD数据集。用WideResNet作为预训练模型。
总的结论就是:不fine-tuning的话好于softmax confidence的方法;fine-tuning的话好于目前的sota-OE方法(而且在ID数据上准确度不掉点):
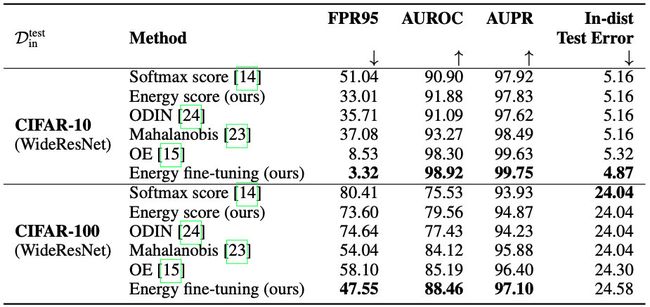
还有一个图我们很熟悉:
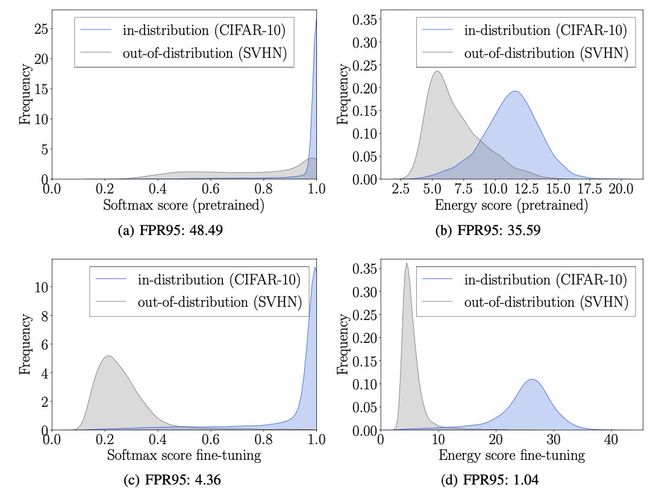
从两个分布的概率直方图上看,Energu score比Softmax score拉得开;energy score fine-tuning的方法比OE fine-tuning拉得开。