国科大高级人工智能-总结
文章目录
- 1.概论
- 2. 搜索
-
- A\*最优性
- 三个传教士与野人
- 3.神经网络
-
- RBM DBN DBM hopfield比较
- 结构及特性
- 逐层贪婪训练与CD
- BP
- GAN
- 4.逻辑
-
- 一个永远无法归结结束的FOL
- 合取范式规范化
- 归结原理
- 4.1resolution是完备的、可靠的
- Modus ponens
- 4.1 蕴含与包含的证明
- 蕴含与implication的关系
- 5. 模糊数学和遗传算法
- 6. 强化学习
- 7. 群体智能
- 8. 博弈
-
- 田忌赛马
- 剪刀石头布
-
- 性别之战
- 拍卖
- 讨价
-
- 讨价的情形
- 打官司
- 海盗分金币
- 匹配问题分宿舍
- 中介
1.概论
- 图灵测试:表明其智能水平从表现来看,难以和人区分开来
- 三个学派:
- 符号学派
- 联结学派
- 行为学派
2. 搜索
- 广度优先搜索是代价一致搜索的特例(无权的)
- UCS是A*的特例
- A*=UCS+贪婪搜索
- UCS:看已经花费的
- 贪婪搜索:启发搜索,看未来(TSP-距离目标的直线距离)
- A*:过去未来都看
- 贪婪最佳优先搜索:是不完备的
- 爬山法:可以任意位置起始,移动到最好的相邻状态。
- 最优条件:
- A*树搜索:h(n)可采纳
- h(n)<=h*(n)
- A*图搜索:h(n)是一致的
- h(A)-h©<=cost(A to C)
- h(A)>h©–递减
- f(A)
- A*树搜索:h(n)可采纳
- 避免重复状态
- 如果算法不检测重复状态,线性问题会变成指数问题
| 算法名称 | 算法策略 | 时间复杂度 | 空间复杂度 | 完备性 | 最优性 | 存储 |
|---|---|---|---|---|---|---|
| DFS(深度优先) | 深度优先(从左往右,得到最左结果, | O ( b m ) O(b^m) O(bm) | O ( b m ) O(bm) O(bm) | (不完备)有限就有解 | 无 | 堆栈 |
| Depth-limited(深度优先) | 深度优先,限制最长搜索深度,超过就换一条 | O ( b l ) O(b^l) O(bl) | O ( b l ) O(bl) O(bl) | (不完备)m有限就有解 | 无 | 堆栈 |
| Iterative-Depth(深度优先) | 逐层限制深度,使用DFS(DFS的空间+BFS的最优) | O ( b d ) O(b^d) O(bd) | O ( b d ) O(bd) O(bd) | 有解,s必然有限 | 无 | 堆栈 |
| BFS | 宽度优先,会得到最浅层的解 | O ( b d ) O(b^d) O(bd) | O ( b d ) O(b^d) O(bd) | 有解,s必然有限(完备) | 最优(无权时才最优 | 队列 |
| UCS(代价一致搜索 | 优先队列BFS,考虑当前代价(优先级),BFS是UCS的特例,g(x) | O ( b [ C ∗ / ϵ ] ) O(b^[C^*/\epsilon]) O(b[C∗/ϵ]) | O ( b [ C ∗ / ϵ ] ) O(b^[C^*/\epsilon]) O(b[C∗/ϵ]) | 完备 | 最优 | 优先队列 |
| 启发式搜索 | 使用额外信息(如到终点的长度)–启发函数h(x) | - | - | - | - | - |
| 贪婪搜索 | h(x)最好的先扩展 | 快速,最坏同DFS(全树扩展) | - | (完备) | 最大问题在于往往找不到最优解 | 优先队列 |
| A* | UCS+贪婪,优先级用f(x)=g(x)+h(x),目标出列时才停止 | 指数 | 指数 | (完备) | 实际h>估计h,且目标出列时结束的情况,最优(往好了估计) | 花费的话小的优先队列 |
| A*图搜索 | 去除树中重复节点(一个状态则不扩展)(保证h(A)<=实际,且h(A)-h©<=弧cost(一致性) | 指数 | 指数 | (不完备)完备(树有的状态他都有) | 弧一致时最优 | 优先队列 |
| 算法名称 | 方向 | 最优 |
|---|---|---|
| 贪婪 | 快速地向目标方向扩展, | 不一定能够得到最优解 |
| UCS | 所有方向等可能扩展 | 能够得到最优解 |
| A* | 朝着最优解方向扩展 | 能够得到最优解 |
| 算法名称 | 算法策略 | 时间复杂度 | 空间复杂度 | 完备性 | 最优性 |
|---|---|---|---|---|---|
| 爬山法(如SGD) | 1.任意位置起始,2.移动到最好的相邻位置,3.无最好则结束 | - | - | (不完备) | 无 |
| 模拟退火(从爬山法改进) | 1.任意位置起始,2.移动到最好的相邻位置,3.不好的状态则以 e Δ E / T e^{\Delta E/T} eΔE/T概率接受 | - | - | (不完备) | 下降够慢,则最优 |
| 遗传算法 | 1.选最好的N个(基于适应度函数),2.这几个配对,并杂交,3.随机变异各串中的一个,重复 | - | - | (不完备) | ? |
A*最优性
- 证明A*树搜索最优(使用了可采纳启发)
- B-次优,A-最优,h-可采纳的,证明A在B前离开边缘集合(出队列)
- 假设B和A的祖先n在边缘集合上
- 那么,n会在B之前被扩展
- f(n)<=f(A)(因为还未到达终点,f(A)=g(A)就是实际全程耗散)
- f(A)
- 所以,n先扩展
- 所以A的所有祖先都在B之前扩展
- A在B之前扩展
- 所以,A*最优
- B-次优,A-最优,h-可采纳的,证明A在B前离开边缘集合(出队列)
- A*图搜索最优?
- 前提:一致性–就是可采纳性
- h(A)<=实际,
- 且h(A)-h©<=弧cost(一致性)
- 采用一致的h(启发函数,所以
- f单调递增
- 对每个状态s,到达s最优的节点,优于次优
- 所以是最优的
- 证明
- 假定到达G*(最优值)的路径上某个n不能进入队列,因为某个具有相同状态且较差的n’先被扩展了
- 找到树中最高的这个节点n
- p是n的祖先,且n’出列时在队列里
- f§
- f(n)
- p应该在n’之前被扩展
- 矛盾
- 得证先到达G*
- f(n)
- 前提:一致性–就是可采纳性
三个传教士与野人

- M-左岸传教士数目
- C-左岸野人数目
- B-左岸是否有船
- Pcm-有c个传教士,m个野人从左岸到右岸
- Qcm-有c个传教士,m个野人从右岸到左岸
- 问题有解所必须的特性
- M>=C且(3-M)>=(3-C)<==>M=C
- 或者M=0,M=3
- 安全状态(以左岸为例):
- 传教士与野人的数目相等;
- 传教士都在左岸;
- 传教士都不在左岸。
- 完全状态图:不满足约束的不在图内)

3.神经网络
- DBN(深度置信网络)网络结构由多个RBM层叠而成
- CNN的特点
- 局部连接
- 参数共享
- 子采样
- 决策树
- 信息熵
- 系统不确定性的度量
- 系统永久恒定在某一状态后,该系统的信息熵最小
- 除了香农熵,有多种定义方式
- E n t ( D ) = − Σ k = 1 ∣ y ∣ p k l o g p k Ent(D)=-\Sigma_{k=1}^{|y|} p_klogp_k Ent(D)=−Σk=1∣y∣pklogpk
- 纯度越高,值越小
- 信息增益
- 决策树划分节点依据信息增益来
- G a i n ( D , a ) = E n t ( D ) − Σ v = 1 V ∣ D v ∣ ∣ D ∣ E n t ( D v ) Gain(D,a)=Ent(D)-\Sigma_{v=1}^V\frac{|D^v|}{|D|}Ent(D^v) Gain(D,a)=Ent(D)−Σv=1V∣D∣∣Dv∣Ent(Dv)
- 选择增益大的划分
- 条件熵
- 是 条 件 熵 Σ v = 1 V ∣ D v ∣ ∣ D ∣ E n t ( D v ) 是条件熵\Sigma_{v=1}^V\frac{|D^v|}{|D|}Ent(D^v) 是条件熵Σv=1V∣D∣∣Dv∣Ent(Dv)
- 信息增益应该是使得条件熵变小
- –>决策树让条件熵变小
- 信息熵
- 感知机不可解决异或问题
- 因为感知机只在线性可分问题下收敛(有限步内收敛)
- 感知机收敛定理:线性可分则收敛
- w、x是增广得到的
- 若数据集可分,
- 存在 w ∗ ( ∣ ∣ w ∗ ∣ ∣ = 1 ) , γ > 0 , 使 得 y t w ∗ x t ≥ γ w^*(||w^*||=1),\gamma>0,使得y_tw^*x_t\geq \gamma w∗(∣∣w∗∣∣=1),γ>0,使得ytw∗xt≥γ
- 令最终分离超平面参数为 w ∗ ( ∣ ∣ w ∗ ∣ ∣ = 1 ) w^*(||w^*||=1) w∗(∣∣w∗∣∣=1)
- w k w ∗ = ( w k − 1 + x t y t ) w ∗ ≥ w k − 1 w ∗ + γ ≥ . . . ≥ k γ w_kw^*=(w_{k-1}+x_ty_t)w^* \geq w_{k-1}w^* + \gamma \geq ...\geq k\gamma wkw∗=(wk−1+xtyt)w∗≥wk−1w∗+γ≥...≥kγ
- ∣ ∣ w k ∣ ∣ 2 = ∣ ∣ w k + 1 + x t y t ∣ ∣ 2 = ∣ ∣ w k − 1 ∣ ∣ 2 + 2 w k − 1 T x t y t + ∣ ∣ x t ∣ ∣ 2 ||w_k||^2=||w_{k+1}+x_ty_t||^2=||w_{k-1}||^2+2w_{k-1}^Tx_ty_t+||x_t||^2 ∣∣wk∣∣2=∣∣wk+1+xtyt∣∣2=∣∣wk−1∣∣2+2wk−1Txtyt+∣∣xt∣∣2——yt=1
- ≤ ∣ ∣ w k − 1 ∣ ∣ 2 + ∣ ∣ x t ∣ ∣ 2 ≤ ∣ ∣ w k − 1 ∣ ∣ 2 + R 2 ≤ . . . ≤ k R 2 \leq ||w_{k-1}||^2+||x_t||^2\leq ||w_{k-1}||^2+R^2 \leq ...\leq kR^2 ≤∣∣wk−1∣∣2+∣∣xt∣∣2≤∣∣wk−1∣∣2+R2≤...≤kR2
- 所以 k γ ≤ w k w ∗ ≤ ∣ ∣ w k ∣ ∣ ∣ ∣ w ∗ ∣ ∣ ≤ k R k\gamma \leq w_kw^* \leq ||w_k||||w^*|| \leq \sqrt{k} R kγ≤wkw∗≤∣∣wk∣∣∣∣w∗∣∣≤kR
- k ≤ R 2 γ 2 k\leq \frac{R^2}{\gamma^2} k≤γ2R2
- 以超平面来划分两类样本
- 感知机收敛定理:线性可分则收敛
- 感知机学习是在假设空间中选取使得损失函数最小的参数模型
- 训练 w = w + / − x , 小 了 就 调 大 一 点 , 大 了 就 调 小 一 点 , 一 个 x 调 整 一 次 w=w+/-x,小了就调大一点,大了就调小一点,一个x调整一次 w=w+/−x,小了就调大一点,大了就调小一点,一个x调整一次
- 感知机存在的问题
- 噪声(线性不可分)
- 泛化性
- 异或问题是非线性问题(带进去看一下)
- 证明
- 假设可以解,y=ω1x1+ω2x2+θ则ω1、 ω2 和θ 必须满足如下方程组:
- ω1 + ω2 - θ < 0–(1,1,)–0
- θ > ω1 + ω2
- ω1 + 0 - θ ≥ 0
- 0 ≥ θ - ω1
- 0 + 0 - θ < 0
- θ > 0
- 0 + ω2 - θ ≥ 0
- 0 ≥ θ - ω2
- ω1 + ω2 - θ < 0–(1,1,)–0
- 显然,该方程组是矛盾的,无解!这就说明单层感知器是无法解决异或问题的。
- 假设可以解,y=ω1x1+ω2x2+θ则ω1、 ω2 和θ 必须满足如下方程组:
- 证明
- 因为感知机只在线性可分问题下收敛(有限步内收敛)
- BP遇到的困难,为什么会出现梯度消失
- 困难:
- 梯度消失,梯度爆炸
- 局部极小
- 只能用于标注数据
- why梯度消失
- 因为BP算法采用链式法则,从后层向前层传递信息时,
- 若每层神经元对上一层神经元偏导乘以w均小于1,多次链式法则,多级导数权值相乘结果会越来越小,导致loss传递到越前方越小。
- w采用正态分布初始化<1
- ∂ y i ∂ z i < 1 \frac{\partial y_i}{\partial z_i}<1 ∂zi∂yi<1
- 困难:
RBM DBN DBM hopfield比较
| 网络结构 | 状态 | …目标函数… | 特点 | |
|---|---|---|---|---|
| Hopfield网络 | 单层,全连接(有权,无向图)wij=wji,wii=0 | 1,-1(0),确定性地取1、0 | E = − 1 2 S T ω S E=-\frac{1}{2}S^T\omega S E=−21STωS | 1.确定性地接受能量下降方向;2.会达到局部极小(模拟退火解决,以一定概率接受能量上升) |
| Boltzman机器 | p(v)符合玻尔兹曼分布,生成模型,有隐层(与外部无连接),有可见层(输入层、输出层)(与外部有链接,收到外部约束),全连接(同层也有)(有权无向图)wij=wji,wii=0 | 1(on),0(off),状态满足boltzman分布,以p取1(二值神经元) | P α P β = e x p ( − ( E ( S α ) − E ( S β ) ) / T ) \frac{P_\alpha}{P_\beta}=exp(-(E(S^\alpha)-E(S^\beta))/T) PβPα=exp(−(E(Sα)−E(Sβ))/T) | 1.接受能量下降,以p( p ( s i = 1 ) = 1 1 + e x p ( − b i − Σ j s j w j i ) p(s_i=1)=\frac{1}{1+exp(-b_i-\Sigma_js_jw_{ji})} p(si=1)=1+exp(−bi−Σjsjwji)1)接受能量上升(模拟退火)2.训练时间长,3.结构复杂,4.也可能局部极小;5.功能强大 |
| RBM(受限Boltzman机 | p(v)符合玻尔兹曼分布,生成模型,区别:同层无连接,其他全连接,可见层1(输入v)、隐藏层1(h,给定可视层下,条件独立)(二部图) | vi,hj,{0,1},以p取1(二值神经元) | 联合组态能量函数 E ( v , h ; θ ) = − Σ i j w i j v i h j − Σ i b i v i − Σ j a j h j , p θ ( v , h ) = 1 Z ( θ ) e x p ( − E ) , 目 标 函 数 l o g ( p θ ( v ) ) ( 极 大 似 然 ) E(v,h;\theta)=-\Sigma_{ij}w_{ij}v_ih_j-\Sigma_{i}b_{i}v_i-\Sigma_{j}a_{j}h_j, p_\theta(v,h)=\frac{1}{Z(\theta)}exp(-E),目标函数log(p_\theta(v))(极大似然) E(v,h;θ)=−Σijwijvihj−Σibivi−Σjajhj,pθ(v,h)=Z(θ)1exp(−E),目标函数log(pθ(v))(极大似然) | |
| DBN | 生成模型,多层,顶层无向图(RBM)(hn-1-hn),低层(v<-hn-1),去除上层,下层是个RBM | (二值神经元) | 从下到上逐层当做RBM训练 | 低层是单向的与RBM不一致,所以提出了DBM |
| DBM | p(v)符合玻尔兹曼分布,生成模型,多层,全无向图 | (二值神经元) | 双向,每层需要考虑上下层神经元(多层) E ( v , h 1 , h 2 ; θ ) = − v T W 1 h 1 − h 1 T W 2 h 2 ; p ( v ) = Σ h 1 , h 2 1 Z e x p ( − E ) E(v,h^1,h^2;\theta)=-v^TW^1h^1-h^{1T}W^2h^2;p(v)=\Sigma_{h1,h2}\frac {1}{Z}exp(-E) E(v,h1,h2;θ)=−vTW1h1−h1TW2h2;p(v)=Σh1,h2Z1exp(−E) | 低层是单向的与RBM不一致,所以提出了DBM |
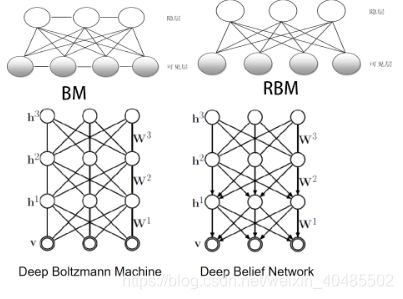
结构及特性
- DNN 全连接
- Hopfield 全连接,确定性阈值神经元
- 参数计算得到
- BM 全连接,二值神经元
- RBM/DBM 无向图,层间全连接,二值神经元
- 逐层贪婪训练
- DBN 低层有向<–,高层无向(高->低)
- 逐层贪婪训练
- RNN 权值共享的多层前向神经网络(循环)
- 序列、时间
- 不同时间的RNN权值一样
- BPTT训练(LSTM也是)
- CNN 局部连接,参数共享,子采样
- 图
- 改进:用relu和dropout

逐层贪婪训练与CD
- DBN 逐层贪婪训练
- 仅保留v,h1层,使用CD-1训练得到W1
- 增加h2层,保持W1不变,h1右Q(h1|v)采样得到作为输入。h1/h2使用CD-1训练得到W2
- 类比
- DBM 逐层贪婪训练
- 训练时采用双方向(上下两层),同时考虑两个或多个隐层
- 由能量模型也可以得到p(v)——也符合boltzman分布
- p ( v ) = Σ h 1 , h 2 , h 3 1 Z e x p ( v T W 1 h 1 + h 1 T W 2 h 2 + h 2 T W 3 h 3 ) p(v)=\Sigma_{h1,h2,h3}\frac {1}{Z}exp(v^TW^1h^1+h^{1T}W^2h^2+h^{2T}W^3h^3) p(v)=Σh1,h2,h3Z1exp(vTW1h1+h1TW2h2+h2TW3h3)
- 两层的能量: E ( v , h 1 , h 2 ; θ ) = − v T W 1 h 1 − h 1 T W 2 h 2 E(v,h^1,h^2;\theta)=-v^TW^1h^1-h^{1T}W^2h^2 E(v,h1,h2;θ)=−vTW1h1−h1TW2h2
- p ( v ) = Σ h 1 , h 2 1 Z e x p ( − E ) p(v)=\Sigma_{h1,h2}\frac {1}{Z}exp(-E) p(v)=Σh1,h2Z1exp(−E)
- p ( h j 1 = 1 ∣ v , h 2 ) = σ ( Σ i W i j 1 v i + Σ W j m 2 h j 2 ) p(h^1_j=1|v,h^2)=\sigma(\Sigma_iW^1_{ij}v_i+\Sigma W^2_{jm}h_j^2) p(hj1=1∣v,h2)=σ(ΣiWij1vi+ΣWjm2hj2)
- p ( h m 2 = 1 ∣ h 1 ) = σ ( Σ i W i m 2 h i 1 ) p(h_m^2=1|h^1)=\sigma(\Sigma_iW^2_{im}h_i^1) p(hm2=1∣h1)=σ(ΣiWim2hi1)
- p ( v i = 1 ∣ h 1 ) = σ ( Σ i W i j 1 h j ) p(v_i=1|h^1)=\sigma(\Sigma_iW^1_{ij}h_j) p(vi=1∣h1)=σ(ΣiWij1hj)
- CD-1
- p ( v ∣ θ ) 极 大 似 然 估 计 , 得 到 导 数 ∂ p ( v ) ∂ w i j ∂ p ( v ) ∂ b i ∂ p ( v ) ∂ a j p(v|\theta)极大似然估计,得到导数\\\frac{\partial p(v)}{\partial w_{ij}}\\\frac{\partial p(v)}{\partial b_{i}}\\\frac{\partial p(v)}{\partial a_{j}} p(v∣θ)极大似然估计,得到导数∂wij∂p(v)∂bi∂p(v)∂aj∂p(v)
- 依 据 导 数 , 对 观 测 变 量 的 所 有 维 度 的 梯 度 求 和 平 均 , 来 更 新 参 数 依据导数,对观测变量的所有维度的梯度求和平均,来更新参数 依据导数,对观测变量的所有维度的梯度求和平均,来更新参数
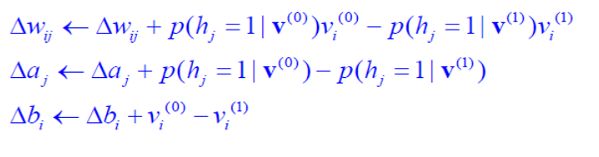
BP
- BP算法流程:
- 选取训练数据输入网络
- 根据权重与激活函数计算输出
- 算出实际输出与目标输出之间的误差
- 反向传播误差使全局误差最小
- BPTT
- 不同时间的相加一起更新
GAN
- GAN
- 核心思想:博弈论的纳什均衡——对抗达到平衡(共同进步)
- 生成器:尽量生成真实的分布——努力让判别器认不出来
- 输入向量,输出图或序列。。。
- 不同的向量表示不同的特征
- 想要发现数据的分布 P d a t a ( x ) P_{data}(x) Pdata(x)
- 假设一个分布 P d a t a ( x ; θ ) , 用 极 大 似 然 去 找 θ P_{data}(x;\theta),用极大似然去找\theta Pdata(x;θ),用极大似然去找θ
- 判别器:区分是生成的还是真实的(努力让他能认出生成器生成的数据)
- 输入:图片
- 输出:标量评分
- 分越大,越真实–1
- 分小则假–0.1
- 生成器:尽量生成真实的分布——努力让判别器认不出来
- 基本原理:有一个判别器有一个生成器,生成器生成图片让判别器判别,生成器提升自己让判别器无法判别,判别器则提升自己努力识别出生成器生成的图片/序列,双方对抗达到平衡
- 学习算法
- 固定生成器G0,训练判别器,提升判别器的判别能力得到D1
- 固定判别器D1,训练生成器,提升生成器的生成能力,目标让判别器无法识别,得到G1
- 再回到1中用G1训练判别器得到D2,…,依次迭代,直至两者平衡。
- V ( G , D ) = 1 m Σ i = 1 m [ l o g ( D ( x i ) ) ] + 1 m Σ i = 1 m [ l o g ( 1 − D ( G ( z i ) ) ) ] ( G 固 定 ) V(G,D)=\frac{1}{m}\Sigma_{i=1}^m[log(D(x^i))]+\frac{1}{m}\Sigma_{i=1}^m[log(1-D(G(z^i)))] (G固定) V(G,D)=m1Σi=1m[log(D(xi))]+m1Σi=1m[log(1−D(G(zi)))](G固定)
- V ( G , D ) = 1 m Σ i = 1 m [ l o g ( 1 − D ( G ( z i ) ) ) ] ( d 固 定 ) V(G,D)=\frac{1}{m}\Sigma_{i=1}^m[log(1-D(G(z^i)))] (d固定) V(G,D)=m1Σi=1m[log(1−D(G(zi)))](d固定)
- 核心思想:博弈论的纳什均衡——对抗达到平衡(共同进步)

4.逻辑
- 一阶谓词逻辑下机器自动证明的正确步骤:(?)
- 结论取反
- 量词前束
- 合取范式标准化
- 归结树归结
- 一阶谓词逻辑表示
- 胜者为王,败者为寇
- ( ∀ x , W i n n e r ( x ) = > K i n g ( x ) ) ∧ ( ∀ y , L o s e r ( y ) = > K o u ( y ) ) (∀ x,Winner(x)=>King(x))∧(∀ y,Loser(y)=>Kou(y)) (∀x,Winner(x)=>King(x))∧(∀y,Loser(y)=>Kou(y))
- ∀ x ∀ y , W i n ( x , y ) = > K i n g ( x ) ∧ K o u ( y ) ∀ x∀ y,Win(x,y)=>King(x)∧Kou(y) ∀x∀y,Win(x,y)=>King(x)∧Kou(y)
- 胜者为王,败者为寇
- 模糊逻辑表示
- 画图表示
- 很少有成绩好的学生特别贪玩
- 很少就可以是量词
- Δ x G ( x ) = > P ′ ( x ) \Delta x G(x)=>P'(x) ΔxG(x)=>P′(x)
- '–加强了变成了原来的平方
- 大多数成绩好的学生学习都很刻苦。
Σ x G ( x ) = > H ′ ( x ) \Sigma x G(x)=>H'(x) ΣxG(x)=>H′(x)
一个永远无法归结结束的FOL

合取范式规范化
- ¬ (∀ x){P(x)=>{(∃y)[p(y)=>P(f(x,y))]∧¬(∀ y)(∃w)[Q(x,y)=>P(y,w)]}}
- 去除=>
- 否定内移
- 改换符号y->z
- 去除存在量词
- 全局的:A
- 局部的:g(z)
- 全称量词前移
- 消除全称量词
- 变换成CNF

归结原理
- 一阶谓词逻辑要合一化(置换)

4.1resolution是完备的、可靠的
- 可靠性:|- --> |=
- 归结的过程是可靠的
- 归结过程:C1、C2中有互补文字==》C1∨C2
- 已知C1,C2 |- C1∨C2
- 证明C1,C2 |= C1∨C2
- 因为推理规则是可靠的(检查真值表)
| C1 | C2 | C1∨C2 |
|---|---|---|
| false | false | false |
| true | false | true |
| false | true | true |
| true | true | true |
-
完备性:
- 已知C1,C2 |= C1∨C2
- 证明C1,C2 |- C1∨C2
- RC(S)–归结闭集 resolution closure–所有S归结出来的都在RC(S)中=PL-Resolution(KB, α \alpha α)的最终clauses
- S={KB,¬ α \alpha α}
- KB |= α \alpha α<>KB∧ ¬ α \alpha α不可满足(永假)<=>S不可满足
- S={KB,¬ α \alpha α}
- ground resolution theorem:S不可满足==>RC(S)中包含空子句
- 证明:从逆否命题入手:S可满足<==RC(S)中不包含空子句
- 因为RC(S)是有限的,所以PL-Resolution(KB, α \alpha α)总是可以终止的
- PL-Resolution(KB, α \alpha α)的终止条件是clauses中包含空子句
-
ground resolution theorem:S不可满足==>RC(S)中包含空子句
- 证明:从逆否命题入手:RC(S)中不包含空子句==>S可满足

Modus ponens


4.1 蕴含与包含的证明

蕴含与implication的关系

5. 模糊数学和遗传算法
- 遗传算法
- 遗传算法模拟自然界优胜劣汰过程进行优化问题的求解
- 利用选择、交叉、变异产生更多可能的解
- 目标函数:天然可作为遗传算法的适应度函数
- 选择-受适应度函数控制
- 交叉、变异–不受适应度函数控制
- 以某种概率进行交叉、变异
6. 强化学习
| 方法 | 确定性? | 特性 | |
|---|---|---|---|
| 贪心策略 | A t = a r g m a x a Q t ( a ) ( 均 值 ) At=argmax_aQ_t(a)(均值) At=argmaxaQt(a)(均值) | 确定性算法 | 目标是当前行为的期望收益 |
| ϵ \epsilon ϵ贪心策略 | 1 − ϵ 1-\epsilon 1−ϵ:贪心选择; ϵ \epsilon ϵ:随机选择 | 确定性算法 | - |
| 乐观初值法Optimistic initial values | 每个行为的初值都高Q1高, ϵ = 0 \epsilon=0 ϵ=0, | 确定性算法 | 初始只探索,最终贪心 |
| UCB | A T = a r g m a x a ( Q t ( a ) + c l n t N t ( a ) ) , N t ( a ) − a 被 选 择 的 次 数 A_T=argmax_a(Q_t(a)+c\sqrt{\frac{lnt}{N_t(a)}}),N_t(a)-a被选择的次数 AT=argmaxa(Qt(a)+cNt(a)lnt),Nt(a)−a被选择的次数 | 确定性算法 | 最初差,后比贪心好,收敛于贪心 |
| 梯度赌博机算法 | $P(A_t=a)=\frac{e{H_t(a)}}{\Sigma_b=1k e^{H_t(b)}}=\pi_t(a).优化目标 E(R_t)=\Sigma_b\pi_t(b)q(b) $ | 不确定性算法 | 更新Ht |
- 多臂赌博机:累积收益最大=每次摇臂的平均期望收益最大
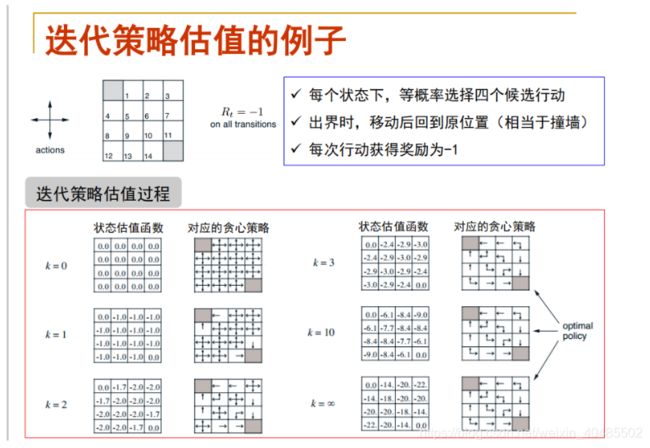
-
计算时,还是按照上下左右的策略计算的–贝尔曼方程,而不是贝尔曼最优方程
-
方法比较
- 蒙特卡罗:深
- 动态规划:宽
- 时序差分,只有一个

7. 群体智能
| 蚁群优化算法 | 粒子群优化算法 | |
|---|---|---|
| 基本原理 | 局部随机搜索与正反馈相结合 | |
| 算法过程 | 1.随机放置蚂蚁;2.对每个蚂蚁,依据概率P(与邻接路径的信息素浓度和启发式信息有关)选择下一步移动位置;3.当所有蚂蚁跑完一轮(所有城市跑完一次),更新信息素浓度(与蚂蚁跑过的路径和路过的蚂蚁的数目有关,并且随时间减少);3.重复至收敛 | 1.随机放置粒子,设置其初始速度;2.计算各粒子的f(xi)(f(x)是目标函数值),记录其当前最优g*及各个粒子历史最右xi*;3.依据xi*和g*和当前速度改变速度,移动到下一位置;4.重复23至收敛 |
| 适用范围 | 离散问题 | 连续问题 |
| 更新 | 一轮一更新(batch) | 一步一计算(随机) |
| 优点 | 易于实现; 可调参数较少; 所需种群或微粒群规模较小;计算效率高,收敛速度快。 | |
| 缺点 | 收敛速度慢(找最优解的情况下);易于陷入局部最优;对于解空间为连续的优化问题不适用 | 和其它演化计算算法类似,不保证收敛到全局最优解 |
| 粒子群优化算法 | 遗传算法 |
|---|---|
| 协同合作,不好的向好的学习 | 适者生存,不好的淘汰掉 |
| 最好的个体通过吸引其他个体向他靠近来施加影响 | 最好的个体产生后代来传播基因 |
| 除了速度位置外,还有过去的历史信息 | 只与上一代有关,与历史无关,markov链的过程 |
8. 博弈
- 议价范围
- 双方估价之差
- 成本100,标价200,买方估价160,卖方估价120
- 议价范围:120~160
- 网络交换博弈–均衡结局
- 均衡结局:全部满足均衡议价解的结局
- 双方备胎x,y,x+y<=1才能议价
- 议价空间s=1-x-y
- A=x+s/2
- B=y+s/2
- A-B-C-D
- 均衡结局:A=1/3=D,B=C=2/3
- 稳定结局:未配对的边两节点的效用和<1
- 均衡结局:全部满足均衡议价解的结局
- 最优
- 帕累托最优
- 以意大利经济学家维尔弗雷多·帕累托的名字命名
- 对于一组策略选择(局势),若不存在其他策略选择使所有参与者得到至少和目前一样高的回报,且至少一个参与者会得到严格较高的回报,则这组策略选择为帕累托最优
- 社会最优
- 使参与者的回报之和最大的策略选择(局势)
- 社会最优的结果一定也是帕累托最优的结果
- 帕累托最优不一定是社会最优
- 社会:是所有局中人构成的社会
- 帕累托最优
- minmax和max min
- minmax:最小化对手最好情况下的收益—对象时对方的效用
- 用于零和博弈
- maxmin:最大化自己最坏情况下的收益–对象是自己的效用
- 零和博弈下:二者等价
- minmax:最小化对手最好情况下的收益—对象时对方的效用
- 纳什均衡
- 每个人的策略都是当前策略的最佳应对
- 混合:让对手各个情况下的收益都一样。
- 纯:谁动谁输
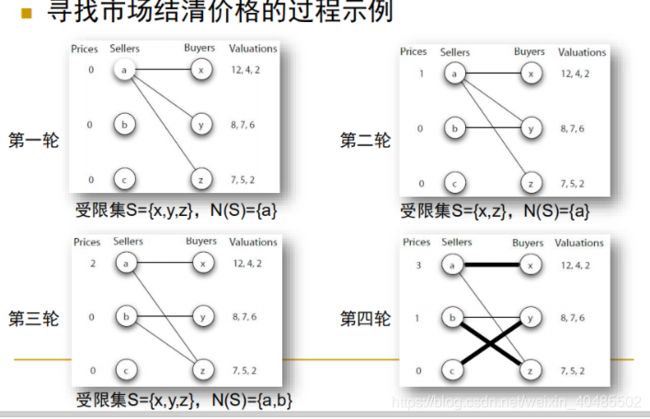
- 市场结清价格
- 完全匹配是否存在可以通过寻找受限集来判断
- 价格能够引导市场优化配置
- 市场结清价格总是存在
- 市场结清价格使得买卖双方总效用最优
| maxmin策略 | minmax策略 | 混合纳什均衡策略 | |
|---|---|---|---|
| 公式 | a r g m a x s i m i n s − i u i ( s i , s − i ) argmax_{s_i}min_{s_{-i}}u_i(s_i,s_{-i}) argmaxsimins−iui(si,s−i) | a r g m i n s i m a x s j u j ( s i , s j ) argmin_{s_i}max_{s_{j}}u_j(s_i,s_{j}) argminsimaxsjuj(si,sj) | a的分布不变情况下,使得b的各种策略的期望都一样 |
| 目的 | 损失最小化,预防对手不理性情况 | 把对手弄趴下,自己就赢了 | 自己的策略让对手无路可走(走哪里都一样) |
| 用于 | 多人博弈 | 零和博弈 | - |
| 特点 | 稳妥,以我为主 | 抑制对手 | 抑制对手 |
田忌赛马
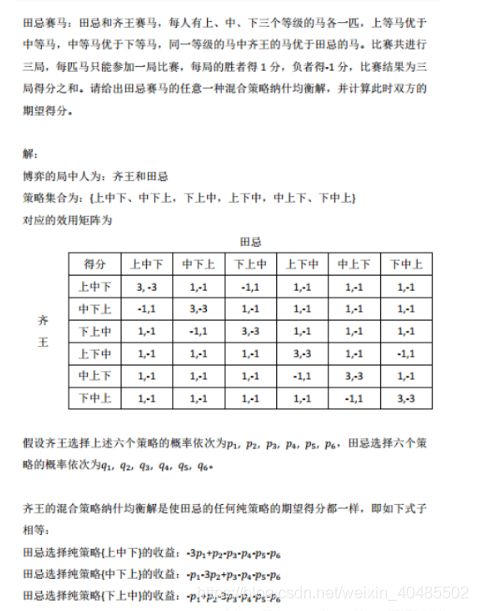

剪刀石头布
- 剪刀石头布
- 局中人
- 两个玩家
- 策略
- 剪刀、石头、布
- 效用函数矩阵
- 不存在纯策略的纳什均衡
- 在任何情况下,对方都能找到更好的策略
- 混合策略下的纳什均衡
- 混合策略
- 玩家一的策略选择分布记为 ={ 1, 2, 1 − 1 − 2 },玩家二的策略选择分布记为 = 1, 2, 1 − 1 − 2
- 假设玩家一的策略分布不变,玩家二策略选择的效用为
- 剪刀:0 ∗ 1 + −1 ∗ 2 + 1 ∗( 1 − 1 − 2) = 1 − 1 − 22 —2的得分,1的概率—2的期望
- 石头:1 ∗ 1 + 0 ∗ 2 + −1 ∗ ( 1 − 1 − 2) = 21 + 2 − 1
- 布: −1 ∗ 1 + 1 ∗ 2 + 0 ∗ ( 1 − 1 − 2) = 2 − 1
- 令玩家二的各个策略的效用相等,得到1 = 2 = 1/3
- 同理可得1 = 2 = 1/3
- 剪刀-石头-布的混合纳什均衡态
- 每个玩家各以1/3的概率
- 选择剪刀、石头和布
- 期望收益均为0
- 混合策略
- 局中人
| 剪刀 | 石头 | 布 | |
|---|---|---|---|
| 剪刀 | 0,0 | -1,1 | 1,-1 |
| 石头 | 1,-1 | 0,0 | -1,1 |
| 布 | -1,1 | 1,-1 | 0,0 |
性别之战
- 性别之战
- 局中人
- 夫妻双方
- 策略
- 看韩剧、看体育
- 效用函数矩阵
- 纳什均衡1:双方都同意看韩剧
- 妻子保持策略不变(看韩剧),丈夫如果改变策略(看体育),其效用会降低(从1变成0)
- 丈夫保持策略不变(看韩剧),妻子如果改变策略(看体育),其效用会降低(从2变成0)
- 纳什均衡2:双方都同意看体育
- maxmin策略:(以我为主)
- 妻子:p选择韩剧,1-p选择体育
- 丈夫:q选择韩剧,1-q选择体育
- 妻子的期望: u w ( p , q ) = 2 p q + ( 1 − p ) ( 1 − q ) = 3 p q − p − q + 1 u_w(p,q)=2pq+(1-p)(1-q)=3pq-p-q+1 uw(p,q)=2pq+(1−p)(1−q)=3pq−p−q+1
- 先min : m i n q ( 3 p q − p − q + 1 ) min_q(3pq-p-q+1) minq(3pq−p−q+1)
- 求导, u w ( p , q ) u_w(p,q) uw(p,q)单调(不知递增递减)—极值点为q=0或1
- 带入q: m i n q u w ( p , q ) = m i n ( 1 − p , 2 p ) − − 这 个 可 以 画 出 折 线 图 , 找 图 中 最 大 的 点 min_q u_w(p,q)=min(1-p,2p)--这个可以画出折线图,找图中最大的点 minquw(p,q)=min(1−p,2p)−−这个可以画出折线图,找图中最大的点
- 再max:找 m i n ( 1 − p , 2 p ) min(1-p,2p) min(1−p,2p)的最大点–p=1/3
- 所以
- 妻子:1/3选择韩剧,2/3选择体育
- 丈夫:2/3选择韩剧,1/3选择体育
- –考虑到对方是最稳妥的策略
- minmax策略:(抑制对手,此种错误,因为性别之战不是零和博弈)
- 妻子:p选择韩剧,1-p选择体育
- 丈夫:q选择韩剧,1-q选择体育
- 丈夫的期望: u f ( p , q ) = p q + 2 ( 1 − p ) ( 1 − q ) = 3 p q − 2 p − 2 q + 2 u_f(p,q)=pq+2(1-p)(1-q)=3pq-2p-2q+2 uf(p,q)=pq+2(1−p)(1−q)=3pq−2p−2q+2
- 先min m a x q ( 3 p q − 2 p − 2 q + 2 ) max_q(3pq-2p-2q+2) maxq(3pq−2p−2q+2)
- 求导, u f ( p , q ) u_f(p,q) uf(p,q)单调(不知递增递减)—极值点为q=0或1
- 带入q: m a x q u f ( p , q ) = m a x ( 2 − 2 p , p ) − − 这 个 可 以 画 出 折 线 图 , 找 图 中 最 大 的 点 max_q u_f(p,q)=max(2-2p,p)--这个可以画出折线图,找图中最大的点 maxquf(p,q)=max(2−2p,p)−−这个可以画出折线图,找图中最大的点
- 再max:找 m a x ( 2 − 2 p , p ) max(2-2p,p) max(2−2p,p)的最大点–p=2/3
- 所以
- 妻子:2/3选择韩剧,1/3选择体育
- 丈夫:1/3选择韩剧,2/3选择体育
- –考虑到对方是最稳妥的策略
- 混合纳什均衡策略(抑制对手)
- 妻子:p选择韩剧,1-p选择体育
- 丈夫:q选择韩剧,1-q选择体育
- 假设妻子策略分布不变,丈夫的期望为
- 丈夫看韩剧:p
- 丈夫看体育:2(1-p)
- 令相同p=2(1-p)==>p=2/3
- 所以
- 妻子:2/3选择韩剧,1/3选择体育
- 丈夫:1/3选择韩剧,2/3选择体育
- 局中人

拍卖
- 经济市场
- 解决稀有资源的分配问题
- 一般市场
- 多个卖家、多个买家
- 讨价(Bargaining)
- 多个卖家、一个买家
- 拍卖(Auction)
- 一个卖家、多个买家
- 拍卖活动
- 买家之间的博弈
- 一个卖家向一群买家拍卖一件商品的活动
- 拍卖的基本假设
- 每个竞争者对被拍卖的商品有各自的估值
- 这个估值是竞拍者对商品实际所值的估计
- 如果商品售价<=这个估值,竞拍者会购买,否则不会购买
- –>因为理性自私人
- 每个竞争者对被拍卖的商品有各自的估值
- 拍卖类型
- 拍卖类型
- 增价拍卖,又称英式拍卖
- 拍卖者逐渐提高售价,竞拍者不断退出,直到只剩一位竞拍者,该竞拍者以最后的报价赢得商品
- 减价拍卖,又称荷式拍卖
- 拍卖者逐渐降低售价,直到有竞拍者出价购买
- 首价密封报价拍卖
- 竞拍者同时向拍卖者提交密封报价,拍卖者同时打开这些报价,出价最高的竞拍者以其出价购买该商品
- 纳什均衡:每个竞拍者的价格低于估价
- 共有个竞拍者,竞拍者的估价记为,报价记为,其他竞拍者的估价服从[, ]区间上的均匀分布,且诚实出价
- < 时,竞标失败,收益为0
- 竞拍者i获胜的概率 ( b i − a b − a ) n − 1 \left( \frac{b_i-a}{b-a} \right)^{n-1} (b−abi−a)n−1
- 竞拍者的期望收益 f ( b i ) = ( v i − b i ) ( b i − a b − a ) n − 1 f(b_i)=(v_i-b_i)\left( \frac{b_i-a}{b-a} \right)^{n-1} f(bi)=(vi−bi)(b−abi−a)n−1
- 求导得到最优解 f ′ ( b i ) = − ( b i − a b − a ) n − 1 + ( n − 1 ) ( v i − b i ) ( b i − a b − a ) n − 2 1 b − a = ( b i − a b − a ) n − 2 ( − n b i + a + ( n − 1 ) v i b − a ) f'(b_i)\\=-\left( \frac{b_i-a}{b-a} \right)^{n-1}+(n-1)(v_i-b_i)\left( \frac{b_i-a}{b-a} \right)^{n-2}\frac{1}{b-a}\\=\left( \frac{b_i-a}{b-a} \right)^{n-2}\left(\frac{-nb_i+a+(n-1)v_i}{b-a}\right) f′(bi)=−(b−abi−a)n−1+(n−1)(vi−bi)(b−abi−a)n−2b−a1=(b−abi−a)n−2(b−a−nbi+a+(n−1)vi)
- 最优报价为 b i ∗ = a + ( n − 1 ) v i n < v i b_i^*=\frac{a+(n-1)v_i}{n}
bi∗=na+(n−1)vi<vi - 竞拍者越多越接近于估价
- 次价密封报价拍卖
- 竞拍者同时向拍卖者提交密封报价,出价最高的竞拍者赢得商品但以第二高出价购买该商品
- 纳什均衡:每个竞拍者的价格等于估价
- 给定一个竞拍者,其估价记为,报价记为,其他竞拍者的最高报价记为∗
- 理性行为假设下,报价不会高于估价,即 ≤
- 此时,根据∗的取值有三种情形
- ∗ > :收益为0;—没拍到
- 将报价从提高到,收益不变
- ∗ < :收益为 − ∗ ;
- 将报价从提高到 ,收益不变
- ≤ ∗ ≤ :收益为0;—没拍到
- 将报价从提高到 ,收益变为 − b*–提高后拍到了
- ∗ > :收益为0;—没拍到
- 双方出价
- 股票市场
- 增价拍卖,又称英式拍卖
讨价
- 讨价
- 卖家和买家之间的博弈
- 讨价的对象:是双方对商品估价之差
- 假设所有因素都已经体现在估价中
- 时间、情感、眼缘等
- 例子:
- 衣服进价80,标价200
- 卖家对衣服的估价在80和200之间,譬如120
- 买家的估价假如为160
- 讨价的对象:是双方的估价之差,即160-120=40
- 后续的讨论中,将讨价对象视为整体1
- 卖家的估价为0,买家的估价为1
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZYtdgebF-1578389328371)(attachment:image.png)]
A-卖家
B-买家
- 卖家的估价为0,买家的估价为1
讨价的情形
- 场景1-一口价
- Take-it-or-leave-it:无商谈余地
- 一方报价,另一方要么接受报价达成交易,要么交易失败
- 两个人商量吃蛋糕,一方提出切分比例,另一方如果不同意,双方就都不吃
- 美国参议院:民主党提出增加财政预算到某个值,共和党要么同意,要么拒绝(但不能提新的方案)
- 通过**回滚(rollback)**求解纳什均衡
- Take-it-or-leave-it
- 过程
- 阶段1:甲方提出,按照1-p和p的比例进行分配
- 阶段2:只要p大于0,乙方则会接受p
- 甲方(分配方案提出者)得到几乎所有收益
- 过程
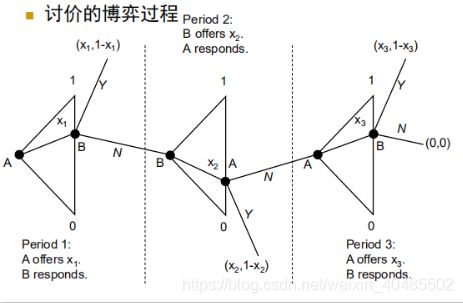
- Take-it-or-counteroffer:要么接受,要么还价
- 过程
- 第一阶段:甲方报价:1-p, p
- 第二阶段:乙方要么接受报价,要么还价 ∗ (1 − ), ∗
- 第三阶段:甲方决定要么接受乙方的还价,要么交易失败
- 约束条件
- 时间成本:刻画可用于分配的总收益随时间衰减(0 ≤ ≤ 1)
- 用来防止甲方不要欺负乙方–不然两人的收益都会变少
- 例子:NBA劳工谈判,分配一个会融化的蛋糕
- 时间成本:刻画可用于分配的总收益随时间衰减(0 ≤ ≤ 1)
- 过程
- Take-it-or-counteroffer过程推演
- 第一阶段之后等同于take-it-or-leave-it讨价
- 假如第一阶段乙方没有接受甲方的报价,那么在接下的take-it-or-leave-it过程中,甲方的收益将趋近于0
- 因此,甲方在第一阶段报价时,分配给乙方的收益不少于乙方拒绝报价后所得到的收益
- p ≥ δ ∗ ( 1 − q ) ≈ δ p\geq \delta*(1-q) \approx \delta p≥δ∗(1−q)≈δ
- p : 第 一 轮 甲 方 报 价 中 , 乙 方 的 收 益 ; p:第一轮甲方报价中,乙方的收益; p:第一轮甲方报价中,乙方的收益;
- δ : 甲 方 拒 绝 后 , 乙 方 报 价 时 可 以 得 到 的 收 益 \delta:甲方拒绝后,乙方报价时可以得到的收益 δ:甲方拒绝后,乙方报价时可以得到的收益
- p ≥ δ ∗ ( 1 − q ) ≈ δ p\geq \delta*(1-q) \approx \delta p≥δ∗(1−q)≈δ
- 启示
- 在时间成本约束下,甲乙双方尽可能会在第一轮达成交易,使双方收益最大
- 甲的报价,要根据时间成本决定
- 乙的收益依赖于对时间成本的容忍度
- 最终的分配比例是:
- 甲方: 1 − δ 1-\delta 1−δ;
- 乙方 δ \delta δ
- 蛋糕融化的越慢,乙方收益越大
- 先发优势,还是后发制人?
- 当时间成本较高(即较小)时,甲方有先发优势
- 例如:炎热的夏天,蛋糕融化得快
- 当时间成本较低(即较大)时,乙方可后发制人
- 例如:寒冷的冬天,蛋糕融化得慢
- 当时间成本较高(即较小)时,甲方有先发优势
- 启示:博弈规则决定最终的结果
打官司
-
打官司
- 原告诉讼被告,要求赔偿100万
- 诉讼费原告和被告各支付10万
- 情形1
- 双方各自认为自己胜诉的概率为1/2
- 开启诉讼E=1/2100+1/20=50
- 原告收益:50万-10万=40万;
- 被告收益:-50万-10万=-60万
- 可以达成庭外和解:譬如被告支付50万给原告
- 原告能接受的最低价是:40万
- 被告能提供的最高价是:60万
- 讨价分配的“蛋糕”大小为20万
- 情形2
- 双方各自认为自己胜诉的概率为3/4
- 开启诉讼
- 原告预期收益:75万-10万=65万;
- 被告预期收益:-25万-10万=-35万
- 无法达成和解——没有交集
- 原告能接受的最低价是:65万
- 被告能提供的最高价是:35万
- 讨价分配的蛋糕大小是:-30万
- 假如诉讼费是30万呢?
- 75-30=45
- -25-30=-45
- 可以和解–45万
- 定价决定一切–规则决定
- 原告诉讼被告,要求赔偿100万
-
博弈规则决定博弈结果
-
各自的“底牌”是对方报价的依据
-
讨价的蛋糕大小由双方的底牌决定
海盗分金币
-
传说,从前有五个海盗抢得了100枚金币.他们通过了一个如何确定选用谁的分配方案的安排.即:
- 抽签决定各人的号码(1,2,3,4,5);
- 先由1号提出分配方案,然后5个人表决.当且仅当超过半数人同意时,方案才算被通过,否则他将被扔入大海喂鲨鱼;
- 当1号死后,再由2号提方案,4个人表决,当且仅当超过半数同意时,方案才算通过,否则2号同样将被扔入大海喂鲨鱼;
- 往下依次类推……
-
根据上面的这个故事,现在提出如下的一个问题.即:
- 我们假定每个海盗都是很聪明的人,并且都能够很理智地判断自己的得失,从而做出最佳的选择,那么第一个海盗应当提出怎样的分配方案才能够使自己不被扔入大海喂鲨鱼,而且收益还能达到最大化呢?
-
Solution:
-
倒推,从后往前推,人数依次增加
- 对于4号来说:如果1-3号强盗都喂了鲨鱼,只剩4号和5号的话。(100,0)
- 对于3号来说:3号知道这一点,就会提(99,0,1)的分配方案,因为他知道5号一无所获但还是会投赞成票,再加上自己一票,他的方案即可通过。
- 对于2号来说:2号推知到3号的方案,就会提出(99,0,1,0)的方案,即放弃3号,而给予4号和5号各一枚金币。由于该方案对于4号和5号来说比在3号分配时更为有利,他们将支持他而不希望他出局而由3号来分配。这样,2号将拿走98枚金币。
- 对于1号来说:2号的方案会被1号所洞悉,1号并将提出(98,0,1,0,1)的方案,即放弃2号,而给3号一枚金币,同时给5号1。由于1号的这一方案对于3号和4号(或5号)来说,相比2号分配时更优,他们将投1号的赞成票,再加上1号自己的票,1号的方案可获通过,97枚金币可轻松落入囊中。这无疑是1号能够获取最大收益的方案了!
-
总结:我们对这种问题要从后向前推,因为我们需要知道后面的会根据什么样的情况做出什么样的决定的时候,我们才可以做出对自己最有利的决定(因为自己的决定使一定数量的海盗得到的比自己死去之后得到的要多),让后面的能支持自己。
-
只要比下一个结果好就行
匹配问题分宿舍
中介
- 纳什均衡状态–中介之间的博弈

- 垄断
- T1–S1/B1
- T2–S3/B3
- 充分竞争
- T1、T2在S2/B2中充分竞争(报价一致了
- 不挣钱
- x=依据市场竞争程度,可能很高也可能很低