R语言图片有中文保存为PDF乱码怎么解决
获取更多R语言知识,请关注公众号:医学和生信笔记
医学和生信笔记,专注R语言在临床医学中的使用,R语言数据分析和可视化。主要分享R语言做医学统计学、meta分析、网络药理学、临床预测模型、机器学习、生物信息学等。
文章目录
-
- 安装
- 使用
-
- 使用谷歌字体
- 使用系统自带字体
由于编码的问题,导致R和Rstudio会遇到很多字体相关的问题,而且都不太容易解决,比如当你使用RMarkdown写中文文档时,导出就会遇到中文乱码问题。再比如如果你画的图有中文,那么导出为PDF时也会遇到乱码!
就很烦!
谢益辉大神的showtext包就是专治这些疑难杂症的。
安装
install.packages("showtext")
使用
使用谷歌字体
(需要科学网络)。
library(showtext)
## 载入需要的程辑包:sysfonts
## 载入需要的程辑包:showtextdb
font_add_google("Gochi Hand", "gochi")
font_add_google("Schoolbell", "bell")
font_add_google("Covered By Your Grace", "grace")
font_add_google("Rock Salt", "rock")
在画图之前先提前设置好,这样后面就会自动使用字体。
showtext_auto()
# 也可以使用showtext_begin()和showtext_end()精确控制某一段代码
# 设置图形设备分辨率,只有位图 需要,默认96
showtext_opts(dpi = 96)
下面就是画图:
set.seed(123)
x <- rnorm(10)
y <- 1+x+rnorm(10, sd = 0.2)
y[1] <- 5
mod <- lm(y ~ x)
op <- par(cex.lab = 2, cex.axis = 1.5, cex.main = 2)
plot(x, y, pch = 16, col = "steelblue",
xlab = "X variable", ylab = "Y variable", family = "gochi")
grid()
title("Draw Plots Before You Fit A Regression", family = "bell")
text(-0.5, 4.5, "This is the outlier", cex = 2, col = "steelblue",
family = "grace")
abline(coef(mod))
abline(1, 1, col = "red")
par(family = "rock")
text(1, 1, expression(paste("True model: ", y == x + 1)),
cex = 1.5, col = "red", srt = 20)
text(0, 2, expression(paste("OLS: ", hat(y) == 0.79 * x + 1.49)),
cex = 1.5, srt = 15)
legend("topright", legend = c("Truth", "OLS"), col = c("red", "black"), lty = 1)
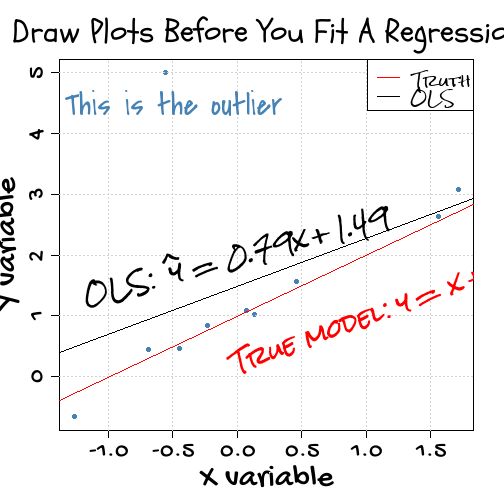
par(op)
这幅图你保存成pdf格式,也不会出现乱码,但是你不用这个包就会出现乱码。
使用系统自带字体
library(showtext)
## 使用Windows自带字体
font_add("heiti", "simhei.ttf")
font_add("constan", "constan.ttf", italic = "constani.ttf")
library(ggplot2)
p = ggplot(NULL, aes(x = 1, y = 1)) + ylim(0.8, 1.2) +
theme(axis.title = element_blank(), axis.ticks = element_blank(),
axis.text = element_blank()) +
annotate("text", 1, 1.1, family = "heiti", size = 15,
label = "\u4F60\u597D\uFF0C\u4E16\u754C") +
annotate("text", 1, 0.9, label = 'Chinese for "Hello, world!"',
family = "constan", fontface = "italic", size = 12)
## 自动设置好
showtext_auto()
## 打印在屏幕上
x11()
print(p)

dev.off()
## png
## 2
## PDF
pdf("showtext-example-3.pdf", 7, 4)
print(p)
dev.off()
## png
## 2
## PNG
ggsave("showtext-example-4.png", width = 7, height = 4, dpi = 96)
## 用完了关闭
showtext_auto(FALSE)
完美,一切都像想象中那样美好!中文字题也完美输出了!
以后如果遇到输出图片乱码问题,记得使用这个包!
获取更多R语言知识,请关注公众号:医学和生信笔记
医学和生信笔记,专注R语言在临床医学中的使用,R语言数据分析和可视化。主要分享R语言做医学统计学、meta分析、网络药理学、临床预测模型、机器学习、生物信息学等。