TOPSIS法 —— python
目录
1.TOPSIS法介绍
2. 计算步骤
(1)数据标准化
(2)得到加权后的矩阵
(3)确定正理想解和负理想解
(4)计算各方案到正(负)理想解的距离
(5)计算综合评价值
3.实例研究
3.1 导入相关库
3.2 读取数据
3.3 读取行数和列数
3.4 数据标准化
3.5 得到信息熵
3.6 计算权重
3.7 计算权重后的数据
3.8 得到最大值最小值距离
3.9 计算评分
总代码
1.TOPSIS法介绍
TOPSIS法(Technique for Order Preference by Similarity to Ideal Solution),可翻译为逼近理想解排序法,国内常简称为优劣解距离法,TOPSIS 法是一种常用的综合评价方法,其能充分利用原始数据的信息,其结果能精确地反映各评价方案之间的差距。
2. 计算步骤
(1)数据标准化
设决策矩阵为X=(xij)m×n,(在进行决策时,因决策属性类型的不同、属性量纲不同和属性值的大小不同,决策与评价的结果会受影响)进行属性值的规范化(方法不唯一,可视具体情况而定),设规范化决策矩阵(也就是标准化后的矩阵)X=(xij)m×n ,其中

(2)得到加权后的矩阵
计算信息熵:

权重为:
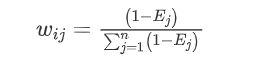
设标准化后的数据矩阵元素为rij ,由上可得指标正向化后数据矩阵元素为xij' :

(3)确定正理想解和负理想解
处理过后可以构成数据矩阵 R=(rij)m*n
-
定义每个指标即每列的最大值为正理想解

- 定义每个指标即每列的最大值为负理想解

(4)计算各方案到正(负)理想解的距离
- 定义第i个对象与最大值距离为正理想解的距离

- 定义第i个对象与最大值距离为负理想解的距离

(5)计算综合评价值
得分为:

明显可以看出0<=score<=1 ,当scorei越大时,d+越小,说明指标离最大值距离越小,越接近最大值
3.实例研究
数据来源:蓝奏云

3.1 导入相关库
#导入相关库
import pandas as pd
import numpy as np3.2 读取数据
读取文件中所有数据:
#导入数据
data=pd.read_excel('D:\桌面\TOPSIS.xlsx')
print(data)返回:

得到数据的变量名:
label_need=data.keys()[1:]
print(label_need)返回:
![]()
得到刨除变量名后的数据值:
data1=data[label_need].values
print(data1)
[m,n]=data1.shape返回:

3.3 读取行数和列数
[m,n]=data1.shape
print('行数:',m)
print('列数:',n)返回:

3.4 数据标准化
#数据标准化
data2=data1.astype('float')
for j in range(0,n):
data2[:,j]=data1[:,j]/np.sqrt(sum(np.square(data1[:,j])))
print(data2)返回:

3.5 得到信息熵
#计算信息熵
p=data2
for j in range(0,n):
p[:,j]=data2[:,j]/sum(data2[:,j])
print(p)
E=data2[0,:]
for j in range(0,n):
E[j]=-1/np.log(m)*sum(p[:,j]*np.log(p[:,j]))
print(E)返回:

3.6 计算权重
# 计算权重
w=(1-E)/sum(1-E)
print(w)返回:
![]()
3.7 计算权重后的数据
#得到加权后的数据
R=data2*w
print(R)返回:

3.8 得到最大值最小值距离
#得到最大值最小值距离
r_max=np.max(R, axis=0) #每个指标的最大值
r_min=np.min(R,axis=0) #每个指标的最小值
d_z = np.sqrt(np.sum(np.square((R -np.tile(r_max,(m,1)))),axis=1)) #d+向量
d_f = np.sqrt(np.sum(np.square((R -np.tile(r_min,(m,1)))),axis=1)) #d-向量
print('每个指标的最大值',r_max)
print('每个指标的最小值',r_min)
print('d+向量',d_z)
print('d-向量',d_f)返回:

3.9 计算评分
#得到评分
s=d_f/(d_z+d_f )
Score=100*s/max(s)
for i in range(0,len(Score)):
print(f"第{i+1}个投标者百分制得分为:{Score[i]}")返回:

总代码
import copy
import pandas as pd
import numpy as np
#导入数据
data=pd.read_excel('D:\桌面\TOPSIS.xlsx')
label_need=data.keys()[1:]
data1=data[label_need].values
#计算行数和列数
[m,n]=data1.shape
#print('行数:',m)
#print('列数:',n)
#数据标准化
data2=data1.astype('float')
for j in range(0,n):
data2[:,j]=data1[:,j]/np.sqrt(sum(np.square(data1[:,j])))
#print(data2)
#计算信息熵
p=data2
for j in range(0,n):
p[:,j]=data2[:,j]/sum(data2[:,j])
#print(p)
E=data2[0,:]
for j in range(0,n):
E[j]=-1/np.log(m)*sum(p[:,j]*np.log(p[:,j]))
#print(E)
# 计算权重
w=(1-E)/sum(1-E)
#print(w)
#得到加权后的数据
R=data2*w
#得到最大值最小值距离
r_max=np.max(R, axis=0) #每个指标的最大值
r_min=np.min(R,axis=0) #每个指标的最小值
d_z = np.sqrt(np.sum(np.square((R -np.tile(r_max,(m,1)))),axis=1)) #d+向量
d_f = np.sqrt(np.sum(np.square((R -np.tile(r_min,(m,1)))),axis=1)) #d-向量
#得到评分
s=d_f/(d_z+d_f )
Score=100*s/max(s)
for i in range(0,len(Score)):
print(f"第{i+1}个投标者百分制得分为:{Score[i]}")