数据结构Day6--pandas(1)
series

创建series
pd.Series(data=None,index=None,dtype=None,name=None,copy=False)

例子:
#数组作为数据源创建
np_rand=np.arange(1,6)
s1=pd.Series(np_rand)
print(s1)
#使用索引标签访问多个元素值
print(s1[[0,1,2]])
结果:
0 1
1 2
2 3
3 4
4 5
dtype: int32
0 1
1 2
2 3
DataFrame()
**pandas.DataFrame(data=None,index=None,dtype=None,copy=None)

例子:
#创建数据
data={
"Name":pd.Series(['a','b','c','d']),
"Age":pd.Series([20,30,40,50]),
"gender":pd.Series(["男","女","男","女"]),
"salary":pd.Series([5000,8000,10000,15000])
}
df=pd.DataFrame(data)
print(df)
结果:
Name Age gender salary
0 a 20 男 5000
1 b 30 女 8000
2 c 40 男 10000
3 d 50 女 15000
列操作
![]()
行操作
行索引
df.loc()使用行标签索引
df.iloc()使用行位置索引
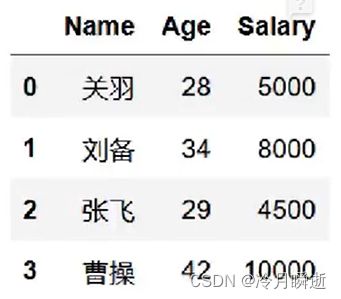
数据行添加–追加字典
df.append(other,ignore_index=False,verify_integrity=False,sort=False)

在行末追加新数据行需要添加ignore_index=True
例如:df_new=df.append(d2,index=True)
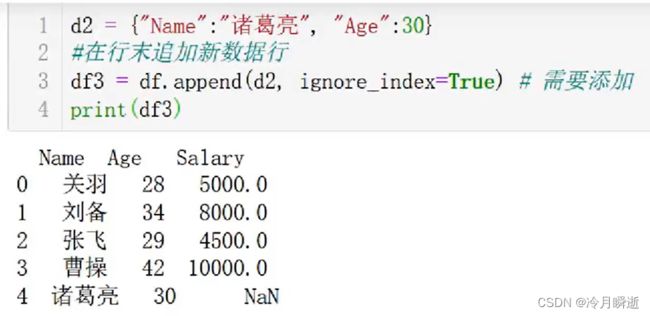
追加列表

#一维
data=[
[1,2,3,4],
[5,6,7,8]
]
df=pd.DataFrame(data)
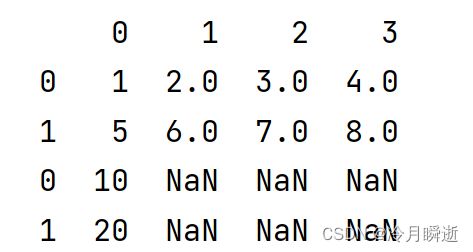
#一维
a_1=[10,20]
df1=df.append(a_1)
print(df1)
#三维
s=[[[10,20,30,40]]]
df3=df.append(s)
print(df3)
结果:

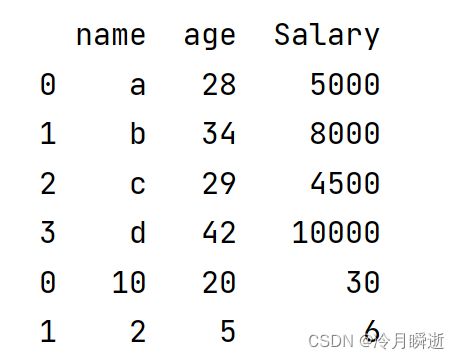
data={
'name':['a','b','c','d'],
'age':[28,34,29,42],
"Salary":[5000,8000,4500,10000]
}
#二维
a_2=[[10,20,30],[2,5,6]]
df2=pd.DataFrame(a_2,columns=["name","age","Salary"])
df4=df.append(df2)
print(df4)
删除数据行df.drop()
可以使用行索引标签,从DataFrame中删除某一行数据。如果索引标签存在重复,那么它们将被一起删除。
DataFrame属性和方法


