FFNs网络理解(部分)
第一段总结:
普通的图像分割方法,先阈值处理,再使用watershed或connected components算法进行目标提取。FFN方法通过3d卷积神经网络直接从源图像中单个目标片段。并且提高了准确率。FFN的主要目的,3d图像的分割,优点端到端,准确率高
第二段总结:
经典的图像分割方法,最简单的,根据像素强度做阈值处理,然后用watershed或connected components算法进行目标提取,比较先进的方法是,使用监督学习分类的方法生成边界图,再用分水岭方法分割。
相对于FFN这些方法的缺点,生成边界图与分割步骤分开,未考虑单个图像的分割怎样集成到全局区域中。虽然改进了损失函数,但依然保留了生成目标片段的步骤。
本文分割方法放弃了明显的边界检测算法,而是把原始图像处理为单个目标掩膜,主要贡献是:提出目标掩膜通道概念,一是指定目标,二是提供分割区域的明显标记 ;网络迭代在多个重叠视图上动态推理,目的是从单个种子像素扩展到已经初始化的任意大对象;
通过3d连接体数据证明FFN比上述图像分割法效果好
第三段总结:
‘’instance‘’分割方法,使用前馈wangluo 直接从原图中生成完整的目标掩膜,但是分辨率较低,然后使用上采样模块以原始图像分辨率重新分配这些掩膜。
对象的掩膜可以在多次迭代中变大或缩小并且输出,并且要分割对象的大小不受限制,此属性对于连接体的应用很重要,在连接体中,单个对象可能跨越数百万个体素。
这一结构训练是端到端的
通过对象掩膜通道指定分割的对象,而不是图像的中心像素
第四段总结:
FFN使用3d原图子数据作为输入,生成对象掩膜概率图,并且该图输出的大小和输入原图数据的大小一样,输入包含两个通道,一个原图,另一个目标掩膜概率图,输入的掩膜概率图一般不完整,FFN通过训练,在可视化范围内对掩膜进行扩展,在推理开始时,在没有任何关于对象形状的先验信息的情况下,不完整的对象掩膜可以由单个活动体素组成。然后,网络对该体素覆盖的对象执行单个对象分割。
网络的每一次迭代必然提供一个概率图,大小限制在可视化范围内,(大图),可以通过让概率图写入到一个虚拟的大图中,以此可以构建任意大的目标。在移动FOV的中心时,重复执行推理过程,并在输入目标掩膜的通道中提供大图的当前状态。
该网络是包含非线性RELU3d深层卷积网络。由于FFN输入和输出的空间大小是相同的,所有卷积都使用相同的模式,并且网络中的任何地方都不使用池——这是一种几乎与第一个工作中使用的架构相同的架构,该架构应用卷积网络来连接逻辑重组。
网络FOV的空间大小设置为33×33×17个体素,由于底层图像数据的各向异性,大致相当于物理空间中的一个立方体。所有卷积使用3×3×3过滤器。网络深度的设置使得来自整个输入子卷的信息有助于输出的中心体素的值,这意味着至少有17个卷积层。改变深度,并根据经验确定较低的深度会导致网络在评估时表现更差,超过最小值17的额外层不会产生进一步的改进。
在内部,网络被组织成两个卷积层的模块,它们之间有跳跃连接,从而获得最佳网络性能。
第五段总结:
网络把输入的目标掩膜扩展到包含该目标的可视化范围,特殊的,网络的第一次迭代前,输入的目标掩膜是要分割目标的单个已被编码的中心像素点,然后用以扩展,一个训练实例,一张49*48*25的图片包含目标片段,且该目标片段的中心点与整个图片中心像素重合,该网络的目标是预测目标体素掩膜,感兴趣的目标区域值为0.95,其他区域为0.05,这两个值相当于0,1,0.05参数确保网络内部激活不会被推向无穷。
在训练的第一步中,网络的FOV设置为当前训练示例的49×49×25子卷的中心,输入对象遮罩通道的中心体素设置为目标值为0.95。其余体素设置为0.05。然后网络以正向模式运行,产生覆盖当前视野的部分预测掩膜。此遮罩保存在覆盖整个训练子卷的“画布”中,并且网络的FOV移动到新位置
每个FFN都有一个相关的∆向量,用于确定移动FOV时在每个方向上要采取的步长,以及一个阈值tmove,该阈值需要在要成为FOV新中心的体素的当前对象遮罩中达到或超过。对于本工程中使用的网络,~∆=(∆x,∆y,∆x)=(8,8,4)和tmove=0.9。为了简洁起见,我们将网络FOV中心的位置简单地称为FFN的位置。如果我们表示当前位置(X0、Y0、Z0),则通过检查6个平面x=X0±∆x、y=Y0±∆y和z=Z0±∆z处掩模的当前状态来搜索潜在的新位置,进一步限制为[X0−∆x≤X≤X0+∆x]×[Y0−∆y≤Y≤Y0+∆y]×[Z0−∆z≤Z0+∆z]。对于每一个这样的平面,都会找到具有最高值v的对象遮罩体素,如果v≥tmove,则会将该体素的位置添加到FFN的新位置列表中。检查完所有6个平面后,列表将按相应遮罩体素激活的降序排序,并附加到新位置的队列中。推理通过从队列中拉出新的位置并将FFN移动到它们来进行。每次移动后,都会重复搜索相对于网络当前位置的新位置。当队列为空时,推理结束。为了防止网络卡在环路中,将维护一组已访问的位置v。为了提高效率,位置以降低的分辨率存储为(bx0/∆xc,by0/∆yc,bz0/∆zc)。禁止网络访问已在V中的位置。
在训练过程中,使用上述推理过程,但网络移动受到限制,因此FOV不会离开训练示例49×49×25子卷。在每次FOV移动后,根据目标对象掩模计算体素对数损失,并通过随机梯度下降更新网络权重。如果vi是网络输出时当前fov的i-th体素的预测遮罩值,mi是该i-th体素的目标值,则在训练期间优化的损失为

推理过程与训练过程相似,但网络不再局限于一个小的子卷,我们明确地通过使分割决策不可能逆转来使网络不受合并错误的影响。在推理过程中,网络可以多次更新对象掩膜体素V。如果我们表示该体素vt的t值,其中v0代表在推断的第一步之前体素的初始状态,并且如果v0 t是网络根据先前状态vt−1预测的值,则分割偏差实现为:
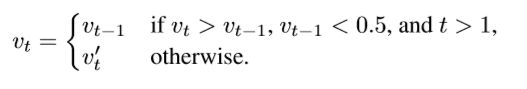
推理还需要一种方法来选择初始种子点的位置,网络将从中尝试增长对象掩膜。有多种方法可以做到这一点,例如随机选择点或在网格上选择点。在我们的实验中,我们发现使用一种简单的启发式方法,试图找出距离可疑物体边界最远的点是有益的。为了确定这些点,我们使用三维Sobel过滤器处理原始图像数据,计算结果的距离变换,并选择距离变换的局部最大值作为FFN的种子点。
为了将网络生成的对象概率图转换为真实分割,我们建议在tmove处阈值化概率图,并根据用于运行ffn推断的种子数将ID分配给生成的段
我们在TensorFlow[1]中实现了FFN模型,并使用32 Nvidia K40 GPU在分布式环境中对其进行异步梯度下降训练,利用数据并行性。收益率设置为0.001,批量大小设置为4(进一步增加并没有提高GPU的性能)。三维卷积由CUDNNR4执行,使用单精度浮点数。
从33卷密集注释的培训卷中随机抽取49×49×25个子卷的培训实例。如上文所述,子体积的大小被选择为允许FOV向各个方向移动一步。通过将与子体积中心体素属于同一对象的体素设置为0.95,其余体素设置为0.05,对每个子体积内的地面真值分割进行二值化,从而为所需的对象遮罩概率图提供软目标。对于每一个训练实例,都计算了主动遮罩体素fa的分数。然后将训练示例分为17个类,这样,如果ti−1≤fa 为了监控培训程序的进度,每1小时保存一次权重检查点,并自动对每个检查点执行覆盖密集骨架子卷的推理过程(见第4.1节)。然后使用骨架指标评估分割结果(见第4.3节)。当指标停止改善时,培训终止。 我们评估了利用高分辨率体积电磁数据对大脑组织进行连接体重建的功能。由于纳米分辨率成像技术上的差异以及目前分析所需的人工神经突重建过程,绘制神经电路布线图(“连接体”)的能力仍然有限。尤其是,在太体素尺度的3D图像中分割密集交织的神经元和轴突的任务对于算法方法来说仍然是一个特别的问题[24],在算法方法中,即使是最先进的深度学习管道,到目前为止也已经为纯粹的自动化产生了非常精确的结果。分析[12]。因此,体电磁数据集的三维分割是机器感知能力持续发展的一个重要领域。该领域的地面实况数据在解释上也很清晰,能够对不同的图像分割算法进行精确的比较。