论文阅读|ViTAE
ViTAE: Vision Transformer Advanced by Exploring Intrinsic Inductive Bias
代码
目录
Abstract
Introduction
Contributions:
2.Related work
2.1CNNs with intrinsic IB
2.2 Vision transformers with learned IB
3 Methodology
3.1 Revisit vision transformer
3.2 Overview architecture of ViTAE
3.3 Reduction cell
3.4 Normal cell
3.5Model details
4. Experiments
4.1 Implementation details
4.2 Comparison with the state-of-the-art
4.3 Ablation study
4.4 Data efficiency and training efficiency
4.5 Generalization on downstream tasks
4.6 Visual inspection of ViTAE
5 Limitation and discussion
6Conclusion
Abstract
Transformer在各种计算机视觉任务中显示出巨大的潜力,这是因为它们在利用自我注意机制对远程依赖进行建模方面具有很强的能力。然而,vision transformer将图像视为一维视觉表征序列,在建模局部视觉结构和处理尺度变化时缺乏内在的感应偏差(inductive bias,IB)。或者,他们需要大规模的训练数据和更长的训练时间表来隐含地学习IB。
在本文中,我们通过从卷积中探索内在 IB 提出了一种新的 Vision Transformer Advanced,即 ViTAE。 从技术上讲,ViTAE 有几个空间金字塔缩减模块,通过使用具有不同膨胀率的多个卷积,对输入图像进行下采样并将其嵌入到具有丰富多尺度上下文的tokens中。 通过这种方式,它获得了内在的尺度不变性 IB,并且能够学习各种尺度下对象的鲁棒特征表示。 此外,在每个 Transformer 层中,ViTAE 都有一个与多头自注意力模块并行的卷积块,其特征被融合并馈入前馈网络。 因此,它具有内在的局部性 IB,并且能够协同学习局部特征和全局依赖关系。在ImageNet以及下游任务上的实验证明了VITAE算法相对于基线变换和并行工作的优越性。
Introduction
Transformer[75,17,36,14,42,57]在NLP研究中显示出主导趋势,这是因为他们有很强的能力通过自我注意机制来模拟长期依赖[63,77,47]。Transformer的这种成功和良好的特性启发了许多将其应用于各种计算机视觉任务的作品[19,95,92,76,7]。其中,VIT[19]是首创的纯transformer模型,它将图像嵌入到一系列可视token来中,并使用堆叠的transformer block模拟它们之间的全局依赖关系。尽管它在图像分类方面取得了可喜的表现,但它需要大规模的训练数据和更长的训练计划。 一个重要的原因是 ViT 在建模局部视觉结构(例如,边缘和角落)和处理各种尺度的对象(如卷积)时缺乏内在的归纳偏差 (IB)。 或者,ViT 必须从大规模数据中隐式学习此类 IB。
与vision transformer不同,卷积神经网络 (CNN) 自然具备尺度不变性和局部性的内在 IB,并且仍然作为视觉任务中的普遍主干[25、66、58、8、91]。 CNN 的成功激励我们探索vision transformer中的内在 IB。 我们首先分析 CNN 的上述两个 IB,即局部性和尺度不变性。 计算相邻像素之间的局部相关性的卷积擅长提取边缘和角落等局部特征。 因此,CNN 可以在浅层 [89] 提供丰富的低级特征,然后通过大量顺序卷积逐渐聚合成高级特征 [29,64,67]。此外,CNN 具有层次结构,可以在不同层提取多尺度特征 [64、34、25]。 此外,层内卷积还可以通过改变内核大小和膨胀率来学习不同尺度的特征[24、66、8、41、91]。 因此,可以通过层内或层间特征融合获得尺度不变的特征表示。 然而,CNN 并不适合模拟远程依赖,这是 Transformer 的关键优势。 出现了一个有趣的问题:我们能否通过利用 CNN 的良好特性来改进vision transformer? 最近,DeiT [72] 探索了将知识从 CNN 提取到转换器的想法,以促进训练和提高性能。 但是,它需要一个现成的 CNN 模型作为教师,并消耗额外的训练成本。
与 DeiT 不同,我们通过重新设计本文中的网络结构,将内在 IB 明确引入视觉转换器。当前的视觉转换器总是获得具有单尺度上下文 [19、88、76、82、43、65、73] 的tokens,并从数据中学习适应不同尺度的对象。例如,T2T-ViT [88] 通过以软拆分方式精细地生成令牌来改进 ViT。具体来说,它使用一系列 Tokens-to-Token 转换层来聚合单尺度相邻上下文信息,并逐步将图像结构化为标记。受 CNN 在处理尺度方差方面的成功启发,我们探索了变压器中的类似设计,即具有不同感受野的层内卷积 [66, 86],将多尺度上下文嵌入到令牌中。这样的设计允许令牌在各种尺度上携带对象的有用特征,从而自然地具有内在的尺度不变性 IB 并明确地促进转换器更有效地从数据中学习尺度不变特征。
例如,T2T-ViT [88] 通过以软拆分方式精细地生成tokens来改进 ViT。 具体来说,它使用一系列 Token-to-Token 转换层来聚合单尺度相邻上下文信息,并逐步将图像结构化为tokens。 受 CNN 在处理尺度变化方面的成功启发,我们探索了transformer中的类似设计,即具有不同感受野的层内卷积 [66, 86],将多尺度上下文嵌入到tokens中。 这样的设计允许token在各种尺度上携带对象的有用特征,从而自然地具有内在的尺度不变性 IB 并明确地促进transformer更有效地从数据中学习尺度不变特征。
另一方面,低级局部特征是生成高级判别特征的基本要素。 尽管 Transformer 也可以从数据的浅层学习这些特征,但它们在设计上不如卷积。 最近,LocalViT,LeViT依次堆叠卷积和注意力层,并证明局部性是对全局依赖性的合理补偿。 然而,这种序列结构在局部建模期间忽略了全局上下文(反之亦然)。 为了避免这样的困境,我们遵循“分而治之”的思想,提出并行建模局部性和远程依赖关系,然后融合特征来解释两者。 通过这种方式,我们使transformer能够更有效地学习每个块内的局部和远程特征。
从技术上讲,我们提出了一种通过探索内在感应偏置 的新型vision transformer(ViTAE),它是两种基本单元的组合,即还原单元 ( reduction cell,RC) 和正常单元 (normal cell, NC)。 RC 用于对输入图像进行下采样并将其嵌入到具有丰富多尺度上下文的tokens中,而 NC 旨在联合建模tokens序列中的局部性和全局依赖性。此外,这两种类型的单元共享一个简单的基本结构,即并行注意模块和卷积层,然后是前馈网络(FFN)。值得注意的是,RC 有一个额外的金字塔缩减模块,该模块具有不同扩张率的空洞卷积,可以将多尺度上下文嵌入到tokens中。按照Tokens-to-Token ViT中的设置,我们堆叠三个RC以将空间分辨率降低 1/16,并使用一系列 NC 来从数据中学习判别特征。 ViTAE 在数据效率和训练效率(参见图 1)以及下游任务的分类准确性和泛化性方面优于具有代表性的vision transformer。
Contributions:
首先,我们探索了 Transformer 中的两种内在 IB,即尺度不变性和局部性,并证明了这种思想在提高 Transformer 特征学习能力方面的有效性。
其次,我们设计了一种名为 ViTAE 的新型transformer架构,该架构基于新的RC和NC,以内在地结合上述两个 IB。 提议的 ViTAE 将多尺度上下文嵌入到token中,并有效地学习本地和远程特征。
第三,ViTAE 在分类准确性、数据效率、训练效率和下游任务泛化方面优于代表性视觉转换器。 ViTAE 在 ImageNet 上分别以 4.8M 和 23.6M 参数实现了 75.3% 和 82.0% 的 top-1 准确率。
2.Related work
2.1CNNs with intrinsic IB
CNN 在图像分类和下游计算机视觉任务方面取得了一系列突破。 CNN 中的卷积操作从由内核大小确定的感受野内的相邻像素中提取局部特征 。根据直觉认为图像中的局部像素更可能相关,CNN 在建模局部性方面具有内在的 IB。除了局部性之外,视觉任务中的另一个关键主题是尺度不变性,其中需要多尺度特征来有效地表示不同尺度的对象。例如,为了有效地学习大型对象的特征,需要通过使用大型卷积核或更深架构中的一系列卷积层来获得大的感受野。为了构建多尺度特征表示,经典思想是使用图像金字塔[8,1,51,4,35,16],其中特征是手工制作或分别从不同分辨率的图像金字塔中学习[40,8 , 48 , 59 , 31, 3 ]。因此,来自小尺度图像的特征主要对大物体进行编码,而来自大尺度图像的特征更多地响应于小物体。 除了上述的层间融合方式外,另一种方式是在单层内使用具有不同感受野的多个卷积来聚合多尺度上下文,即层内融合[91、67、66、66、68] . 层间融合或层内融合使 CNN 在建模尺度不变性方面具有内在的IB。 本文通过遵循层内融合的思想并利用RC中具有不同膨胀率的多个卷积将多尺度上下文编码到每个视觉标记中,将这种 IB 引入vision transformer。
2.2 Vision transformers with learned IB
ViT [19] 是将纯transformer应用于视觉任务并取得可喜成果的开创性工作。然而,由于 ViT 在建模局部视觉结构时缺乏内在的归纳偏差,它从大量数据中隐式地学习了 IB。沿着这个方向的后续工作是用更少的内在 IB 简化模型结构,并直接从大规模数据中学习它们,这些数据取得了可喜的成果并得到了积极的研究。另一个方向是利用 CNN 的内在 IB 来促进vision transformer的训练,例如,使用更少的训练数据或更短的训练计划。例如,DeiT [72] 建议在训练期间将知识从 CNN 提取到transformer。然而,它需要一个现成的 CNN 模型作为教师,在训练期间引入了额外的计算成本。最近,一些工作试图将 CNN 的内在 IB 明确地引入vision transformer [Conformer,LeViT,LocalViT,ConViT,ConTNet,CvT,CrossViT,Swin]。例如,LocalViT,LeViT,CvT依次堆叠卷积和注意力层,形成串行结构并相应地对局部性和全局依赖性进行建模。但是,这种串行结构可能会在局部建模期间忽略全局上下文(反之亦然)。相反,我们遵循“分而治之”的思想,并建议通过每个 Transformer 层内的并行结构同时对局部性和全局依赖性进行建模。 Conformer [54] 是与我们最相关的并发工作,它使用一个单元来探索并行卷积和Transformer块之间的块间交互。相比之下,在 ViTAE 中,卷积和注意力模块被设计为在transformer块内相互补充。此外,Conformer 并未设计为具有固有的尺度不变性 IB。
3 Methodology
3.1 Revisit vision transformer
为了使transformer适应视觉任务,ViT将输入的图片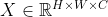 分成tokens
分成tokens![]() ,p代表缩减率,D=Cp^2是token的维度。然后,在以元素方式添加位置嵌入之前,将一个额外的class token连接到visual tokens当中。生成的tokens被传入下面的transformer layers当中。每个transformer layer由两部分组成,及多头自注意力层MHSA和前馈层FFN。
,p代表缩减率,D=Cp^2是token的维度。然后,在以元素方式添加位置嵌入之前,将一个额外的class token连接到visual tokens当中。生成的tokens被传入下面的transformer layers当中。每个transformer layer由两部分组成,及多头自注意力层MHSA和前馈层FFN。
3.2 Overview architecture of ViTAE
ViTAE 旨在将 CNN 中的内在IB引入vision transformer。 如图 2 所示,ViTAE 由两种类型的结构组成,即 RC 和 NC。 RC 负责将多尺度上下文和本地信息嵌入到tokens中,而 NC 用于进一步建模令牌中的局部性和长期依赖关系。 以图像 作为输入,使用三个 RC 将X分别逐步下采样4倍、2倍和2倍。 因此,RC 的输出token大小为 [H/16, W/16, D],其中 D 是token维度(在我们的实验中为 64)。 然后将 RC 的输出token展平为 R^(HW/256×D ),与class token连接,并添加正弦位置编码。 接下来,将tokens馈送到下面的 NC,这些 NC 保持token的长度。 最后,使用来自最后一个 NC 的class token上的线性分类层获得预测概率。
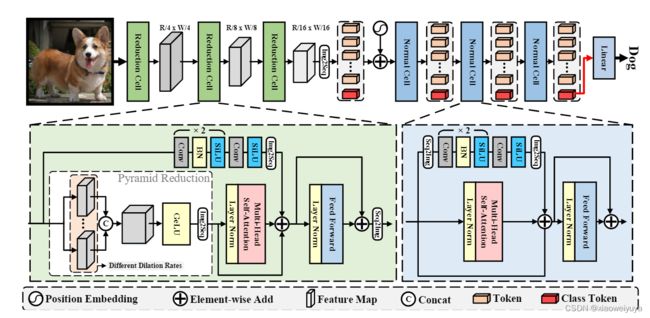
*图2:ViTAE 的结构。 它由三个 RC 和几个 NC 堆叠而成。 两种类型的单元共享一个简单的基本结构,即一个 MHSA 模块和一个并行卷积模块,然后是一个 FFN。 特别是,RC 有一个额外的金字塔缩减模块,它使用具有不同膨胀率的空洞卷积将多尺度上下文嵌入到令牌中。
3.3 Reduction cell
不是基于线性的patch embedding层来直接将图像分割和展平为visual tokens,我们设计了RC以将多尺度上下文和局部信息嵌入到visual tokens中,这从卷积中引入了内在的尺度不变性和局部性 IB。 从技术上讲,RC 有两个并行的分支,分别负责对局部性和远程依赖进行建模,然后是一个 FFN 用于特征转换。
第i层RC的输入特征表示为![]() ,第一层RC的输入为图像x,在全局依赖分支中,
,第一层RC的输入为图像x,在全局依赖分支中, 首先被传入一个Pyramid Reduction Module (PRM)来提取多尺度上下文,即
首先被传入一个Pyramid Reduction Module (PRM)来提取多尺度上下文,即
![]()
![]() 它使用与第i个 RC 对应的预定义扩张率集合Si中的扩张率 sij。请注意,我们使用stride convolution将特征的空间维度从预定义的缩减比率集R中缩减一个比率ri。 卷积特征沿通道维度连接,即
它使用与第i个 RC 对应的预定义扩张率集合Si中的扩张率 sij。请注意,我们使用stride convolution将特征的空间维度从预定义的缩减比率集R中缩减一个比率ri。 卷积特征沿通道维度连接,即![]() ,
,![]() 代表
代表 中的膨胀系数。
中的膨胀系数。
![]() 然后由MHSA模块处理来建模远程依赖关系,即
然后由MHSA模块处理来建模远程依赖关系,即
![]()
Img2Seq()是一个简单的reshape操作将将特征图展平为一个一维序列。以这样的方式,![]() 将多尺度的内容嵌入到每个token中 。此外使用了一个 Parallel Convolutional Module (PCM)来将局部信息嵌入到tokens中,它们与
将多尺度的内容嵌入到每个token中 。此外使用了一个 Parallel Convolutional Module (PCM)来将局部信息嵌入到tokens中,它们与![]() 的融合如下:
的融合如下:

这里,![]() 代表PCM,由三个堆叠的卷积层和一个Img2Seq()操作组成。值得注意的是,并行卷积分支与使用跨步卷积的PRM具有相同的空间下采样率。这样,token特征既可以承载局部上下文,也可以承载多尺度上下文,这意味着RC通过设计获得了局部性IB和尺度不变性IB。
代表PCM,由三个堆叠的卷积层和一个Img2Seq()操作组成。值得注意的是,并行卷积分支与使用跨步卷积的PRM具有相同的空间下采样率。这样,token特征既可以承载局部上下文,也可以承载多尺度上下文,这意味着RC通过设计获得了局部性IB和尺度不变性IB。
然后,融合的tokens由FFN处理,reshape回特征图,并馈送到以下RC或NC中
![]()
Seq2Img()是将token序列重塑回feature map的操作,![]() 代表第i层RC中的FFN。在ViTAE中,三个 RC 依次堆叠,以逐渐将输入图像的空间维度分别减少 4 倍、2 倍和 2 倍。 最后一个 RC 生成的特征图的大小为 [H/16, W/16, D],然后将其展平为visual token并传入接下来的NC。
代表第i层RC中的FFN。在ViTAE中,三个 RC 依次堆叠,以逐渐将输入图像的空间维度分别减少 4 倍、2 倍和 2 倍。 最后一个 RC 生成的特征图的大小为 [H/16, W/16, D],然后将其展平为visual token并传入接下来的NC。
3.4 Normal cell
如图 2 的右下部分所示,NC与RC具有相似的结构,但没有PRM。 由于RC之后特征图的空间尺寸相对较小(1/16倍),因此在 NC 中没有必要使用 PRM。
给定来自第三个RC的f3,首先将它和class token tcls concat,然后将其添加到位置编码中以获得后续NC的输入tokens t。在这里,为了清楚起见,我们忽略了下标,因为所有 NC 具有相同的架构但不同的可学习权重。 tcls 在训练开始时随机初始化,并在推理期间固定。
类似于RC,tokens被传入MHSA模块,即tg=MHSA(t)。同时,tokens被reshape为feature maps传入PCM,即tl=Img2Seq(PCM(Seq2Img(t)))。请注意,class token在PCM中被丢弃,因为它与其他visual tokens没有空间连接。为了进一步减少NCS中的参数,我们在PCM中使用了群卷积。MHSA和PCM的特征然后通过元素求和来融合,即tlg=tg+tl。最后,将tlg输入到FFN中,得到NC的输出特征,即tnc=FFN(tlg)+tlg。与VIT类似,我们对最后一个NC生成的class token进行层归一化,并将其反馈给分类头以获得最终的分类结果。
3.5Model details

我们在实验中使用了两种ViTAE变体,以公平比较具有相似模型大小的其他模型。 它们的详细信息总结在表1中。在第一个RC中,默认卷积核大小为7 × 7,步长为 4,扩张率为S1=[1, 2, 3, 4]。 在以下两个RC中,卷积核大小为3 × 3,步长为 2,扩张率分别为S2= [1, 2, 3] 和S3=[1, 2]。 由于tokens的空间维度减小,因此无需使用大内核和膨胀率。 RC和NC中的PCM都包含三个卷积层,内核大小为 3 × 3。
4. Experiments
4.1 Implementation details
我们在标准ImageNet [34] 数据集上训练和测试提出的 ViTAE 模型。除非明确说明,否则训练期间的图像大小设置为 224 × 224。我们使用 AdamW [44] 优化器和余弦学习率调度器,并使用与T2T [88] 完全相同的数据增强策略进行公平比较。 我们使用 512 的批大小来训练我们所有的模型,并将初始学习率设置为5e-4。 我们模型的结果可以在表2中找到,其中所有模型都在8个V100GPU 上训练了300个epoch。 这些模型建立在PyTorch[53]和TIMM[78]上。
4.2 Comparison with the state-of-the-art

我们在表 2 中将我们的ViTAE与具有相似模型大小的CNN模型和vison transformer进行了比较。报告了ImageNet验证集上的 Top-1/5 准确度和真实Top-1准确度。我们将这些方法分为CNN模型、具有学习IB的vision transformer和具有引入内在IB的vision transformer。与CNN模型相比,我们的 ViTAE-T实现了75.3% 的 Top-1 准确率,优于具有更多参数的ResNet-18。 ViTAE模型的真实 Top-1 准确率为82.9%,与参数比我们的多4倍的 ResNet-50 相当。同样,我们的ViTAE-S以ResNet-101 和 ResNet-152 的一半参数实现了82.0%的Top-1 准确度,显示了通过设计从具有相应内在IB 的特定结构中学习局部和远程特征的优越性。在将ViTAE-T与 MobileNetV1 [28] 和 MobileNetV2 [61] 进行比较时,也可以观察到类似的现象,其中ViTAE以更少的参数获得了更好的性能。与根据 NAS [69] 搜索的较大模型相比,我们的ViTAE-S在使用 384 × 384 图像作为输入时实现了相似的性能,这进一步显示了具有内在IB的vision transformer的潜力。
此外,在具有学习IB的 Transformer 中,ViT是第一个用于视觉识别的纯Transformer模型。 DeiT 与 ViT 具有相同的结构,但使用不同的数据增强和训练策略来促进Transformer的学习。 DeiT⚗表示使用现成的CNN模型作为教师模型来训练 DeiT,它以知识蒸馏的方式将CNN的内在IB隐式引入到 Transformer,在ImageNet数据集上表现出比vanilla ViT 更好的性能。令人兴奋的是,我们的参数更少的ViTAE-T甚至优于蒸馏模型 DeiT⚗,证明了通过设计在transformer中引入内在IB的功效。此外,与其他具有显式内在IB的transformer相比,我们的具有较少参数的ViTAE也实现了相当或更好的性能。例如,ViTAE-T实现了与 LocalVit-T相当的性能,但参数减少了1M,证明了所提出的 RC和NC在引入内在IB方面的优越性。
4.3 Ablation study
在接下来的 ViTAE 消融研究中,我们使用 T2T-ViT [88] 作为我们的baseline模型。 如表3所示,我们通过分别使用它们来研究RC和NC中的超参数设置。 所有模型都在ImageNet上训练了 100 个 epoch,并遵循第4.1节中描述的相同训练设置和数据增强策略。

*表3:RC和NC的消融研究。“Pre”表示PCM和MHSA的输出特征在FFN之前进行融合,而“Post”则表示较晚的融合策略。“BN”表示PCM是否使用BN。“[1,2,3,4]↓”表示在较深的RCS中使用较小的扩张率,即S1=[1,2,3,4],S2=[1,2,3],S3=[1,2]。
我们使用√和×来表示在实验过程中是否启用了相应的模块。如果RC和NC下的所有列如第一行所示标有 ×,则该模型成为标准T2T-ViT 模型。 “Pre”表示PCM和MHSA的输出特征在FFN之前融合,“Post”表示相应的后期融合策略。 “BN”表示PCM在卷积层之后是否使用BN。 第一列中的“×3”表示三个RC中的扩张率集相同。 "[1, 2, 3, 4] ↓" 表示在更深的RC中使用较低的膨胀率,即S1= [1, 2, 3, 4], S2 = [1, 2, 3],S3 = [1, 2]。
可以看出,使用预融合策略和BN在其他设置中实现了最好的 69.9% Top-1准确度。值得注意的是,NC的所有变体都优于普通 T2T-ViT,这意味着PCM的有效性,它在transformer中引入了固有局部性IB。对于RC,我们首先研究在PRM中使用不同膨胀率的影响,如第一列所示。可以看出,使用更大的膨胀率(例如,4 或 5)并不能提供更好的性能。我们怀疑,由于特征图的分辨率较小,较大的扩张率可能会导致更深的RC中的简单特征。为了验证假设,我们在更深的RC中使用较小的膨胀率,如 [1, 2, 3, 4] ↓ 所示。可以看出,它实现了与 [1, 2, 3]× 相当的性能。但是相比[1,2,3,4]↓,[1,2,3]×将参数量从4.35M增加到4.6M。因此,我们选择 [1, 2, 3, 4] ↓ 作为默认设置。另外,在RC中使用PCM后,引入了内在局部IB,性能提升到71.7%的Top-1准确率。最后,RCs 和 NCs 的组合达到了 72.6% 的最佳精度,证明了我们的 RCs 和 RCs 之间的互补性。
4.4 Data efficiency and training efficiency
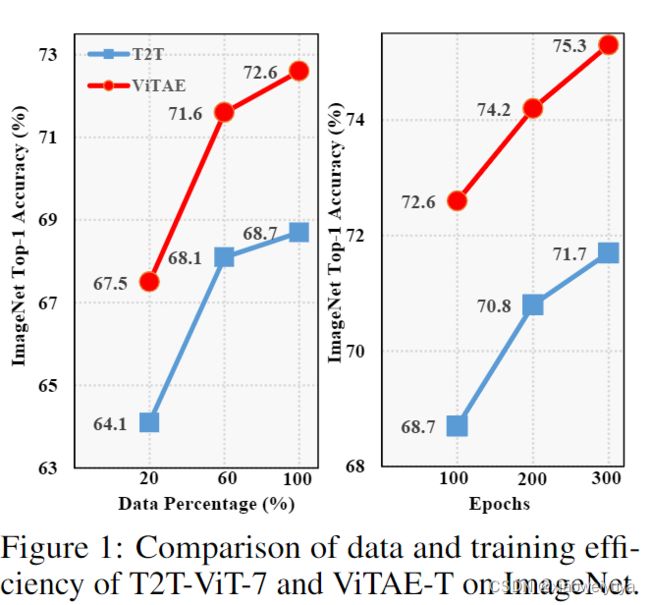
为了验证引入的内在 IB 在提高数据效率和训练效率方面的有效性,我们将我们的ViTAE与 T2T-ViT 在不同的训练设置下进行了比较:
(a) 使用 20%、60% 和 100% ImageNet 训练集对它们进行等效训练完整的ImageNet训练集100 个 epoch;
(b) 使用完整的 ImageNet 训练集分别训练 100、200 和 300 个 epoch。
结果如图1所示。可以看出,ViTAE 在数据效率和训练效率方面始终优于T2T-ViT基线。例如,仅使用20%的训练数据的ViTAE实现了与使用所有数据的T2T-ViT相当的性能。当使用60%的训练数据时,ViTAE在使用所有数据时明显优于T2T-ViT,绝对准确率约为 3%。同样值得注意的是,仅训练了100个epoch的ViTAE优于训练了300个epoch的T2T-ViT。在对ViTAE进行300个epoch训练后,其性能显着提升至 75.3% Top-1准确率。使用提出的RC和NC,我们的ViTAE中的transformer层只需要专注于建模远程依赖关系,将局部性和多尺度上下文建模留给其卷积对应物,即PCM和 PRM。这种“分而治之”的策略有利于vision transformer的训练,从而可以用更少的训练数据和更少的训练时间来更有效地学习。
4.5 Generalization on downstream tasks
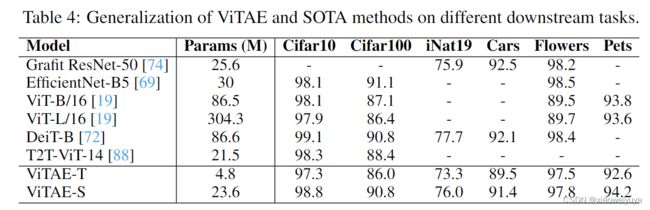
我们通过对几个细粒度分类任务的训练集进行微调,进一步研究了所提出的ViTAE模型在下游任务上的泛化,包括Flowers [49]、Cars [32]、Pets[52] 和iNaturalist。 我们还在Cifar10 [33] 和 Cifar100[33]上微调了所提出的ViTAE模型。 结果如表4所示。可以看出,ViTAE在使用可比或更少参数的大多数数据集上实现了SOTA性能。 这些结果表明我们的ViTAE具有良好的泛化能力。
4.6 Visual inspection of ViTAE
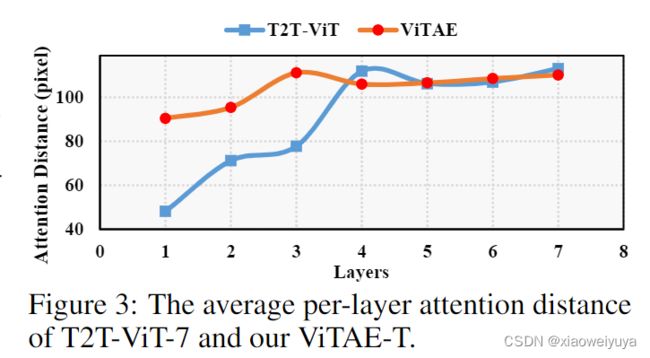
为了进一步分析我们的ViTAE的属性,我们首先在ImageNet测试集上分别计算ViTAE-T和基线 T2TViT-7中每一层的平均注意力距离。 结果如图 3 所示。可以观察到,通过使用侧重于局部建模的PCM,所提出的NC中的transformer层可以更好地专注于建模远程依赖关系,尤其是在浅层中。 在深层,ViTAE-T和T2T-ViT-7的平均注意力距离几乎相同,因为建模远程依赖更为重要。 这些结果证实了所提出的ViTAE中采用的“分而治之”思想的有效性,即将卷积中的固有局部性IB引入vision transformer使得transformer层只需要负责远程依赖成为可能, 因为局部性可以通过PCM中的卷积很好地建模。
此外,我们在最后一次NC的MHSA输出上应用Grad-CAM [62] 以定性检查ViTAE。 可视化结果如图4所示。与基线T2T-ViT相比,我们的ViTAE更精确地覆盖了图像中的单个或多个目标,并且对背景的关注更少。 此外,ViTAE可以更好地处理规模方差问题,如图 4(b) 所示。 即无论小、中、大,都能精准覆盖鸟类。 这些观察表明,将局部性和尺度不变性的固有 IB 从卷积引入到transformer有助于 ViTAE 学习比纯transformer更多的区分特征。
5 Limitation and discussion
在本文中,我们探索了两种类型的IB,并通过提出的RC和NC将它们合并到transformer中。通过这两个单元的协作,我们的ViTAE模型在ImageNet上实现了令人印象深刻的性能,具有快速收敛和高数据效率。然而,由于计算资源的限制,我们没有缩放ViTAE模型并在大型数据集上训练它,例如 ImageNet-21K [34] 和JFT-300M[27]。虽然目前尚不清楚,但从以下初步证据来看,我们对其规模属性持乐观态度。如图2所示,由于跳跃连接和并行结构,我们的ViTAE模型可以看作是互补transformer层和卷积层的单元集合。根据图3所示的注意力距离分析,集成特性使transformer层和卷积层能够专注于它们擅长的领域,即建模远程依赖和局部性。因此,ViTAE很有可能从大规模数据中学习到更好的特征表示。此外,我们在本文中只研究了两个典型的IB。在未来的研究中可以探索更多种类的IB,例如构成视点不变性[60]。
6Conclusion
在本文中,我们通过提出两个新的基本单元(还原单元RC和普通单元NC)重新设计transformer块,将两种类型的固有 (IB) 合并到transformer中,即局部性和尺度不变性,从而产生一个简单的 有效的vision transformer架构,名为 ViTAE。 大量实验表明,ViTAE 在分类精度、数据效率、训练效率和下游任务的泛化能力等各个方面都优于具有代表性的vision transformer。 我们计划将 ViTAE扩展到大型或巨大的模型大小,并在未来的研究中在大型数据集上对其进行训练。 此外,还将研究其他类型的IB。 我们希望这项研究能为以下将内在 IB 引入vision transformer的研究提供有价值的见解,并了解内在和学习IB的影响。