pytorch、tensorflow对比学习—功能组件(优化器、评估指标、Module管理)
功能组件(优化器、评估指标、Module管理)
前言
本文是《pytorch-tensorflow-Comparative study》,pytorch和tensorflow对比学习专栏,第三章——功能组件(优化器、评估指标、Module管理部分)。
虽然说这两个框架在语法和接口的命名上有很多地方是不同的,但是深度学习的建模过程确实基本上都是一个套路的。
所以该笔记的笔记方式是:在使用相同的处理功能模块上,对比记录pytorch和tensorflow两者的API接口,和语法。

1,有利于深入理解深度学习建模过程流程。
2,有利于理解pytorch,和tensorflow设计上的不同,更加灵活的使用在自己的项目中。
3,有利于深入理解各个功能模块的使用。
本章节主要对比学习pytorch 和tensorflow有关功能组件(优化器、评估指标、Module管理)部分的API接口,和语法。

优化器optimizer
神经网络优化器,主要是为了优化我们的神经网络,使他在我们的训练过程中快起来(主要是让梯度下降的速度更快),节省社交网络训练的时间。在pytorch中提供了torch.optim方法优化我们的神经网络,torch.optim是实现各种优化算法的包。最常用的方法都已经支持,接口很常规,所以以后也可以很容易地集成更复杂的方法。
模型优化算法的选择直接关系到最终模型的性能。有时候效果不好,未必是特征的问题或者模型设计的问题,很可能就是优化算法的问题。
深度学习优化算法大概经历了 SGD -> SGDM -> NAG ->Adagrad -> Adadelta(RMSprop) -> Adam -> Nadam 这样的发展历程。
详见《一个框架看懂优化算法之异同 SGD/AdaGrad/Adam》
https://zhuanlan.zhihu.com/p/32230623
对于一般新手炼丹师,优化器直接使用Adam,并使用其默认参数就OK了。
一些爱写论文的炼丹师由于追求评估指标效果,可能会偏爱前期使用Adam优化器快速下降,后期使用SGD并精调优化器参数得到更好的结果。
此外目前也有一些前沿的优化算法,据称效果比Adam更好,例如LazyAdam, Look-ahead, RAdam, Ranger等。
SGD和Adam
内置优化器
**在pytorch中:**optim模块,提供了多种可直接使用的深度学习优化器,内置算法包括Adam、SGD、RMSprop等,无需人工实现随机梯度下降算法,直接调用即可。
**在tensorflow中:**在keras.optimizers子模块中,它们基本上都有对应的类的实现。
| 名称 | pytorch | tensorflow |
|---|---|---|
| 随机梯度下降算法 | torch.optim.SGD() | SGD |
| 弹性反向传播算法 | torch.optim.Rprop() | |
| 平均随机梯度下降算法 | torch.optim.ASGD() | |
| 考虑了二阶动量 | torch.optim.RMSprop() | RMSprop |
| 考虑了自适应二阶动量 | torch.optim.Adadelta() | Adadelta |
| 考虑了二阶动量 | torch.optim.Adagrad() | Adagrad |
| 同时考虑了一阶动量和二阶动量 | torch.optim.Adam() | Adam |
| Adamax算法 | torch.optim.Adamax() | |
| L-BFGS算法 | torch.optim.LBFGS() |
- SGD, 默认参数为纯SGD, 设置momentum参数不为0实际上变成SGDM, 考虑了一阶动量, 设置 nesterov为True后变成NAG,即 Nesterov Accelerated Gradient,在计算梯度时计算的是向前走一步所在位置的梯度。
- Adagrad, 考虑了二阶动量,对于不同的参数有不同的学习率,即自适应学习率。缺点是学习率单调下降,可能后期学习速率过慢乃至提前停止学习。
- RMSprop, 考虑了二阶动量,对于不同的参数有不同的学习率,即自适应学习率,对Adagrad进行了优化,通过指数平滑只考虑一定窗口内的二阶动量。
- Adadelta, 考虑了二阶动量,与RMSprop类似,但是更加复杂一些,自适应性更强。
- Adam, 同时考虑了一阶动量和二阶动量,可以看成RMSprop上进一步考虑了一阶动量。
- Nadam, 在Adam基础上进一步考虑了 Nesterov Acceleration。
优化器的使用
pytroch
要构造一个Optimizer,你必须给它一个包含参数(必须都是Variable对象)进行优化。然后,您可以指定optimizer的参 数选项,比如学习率,权重衰减等。具体参考torch.optim中文文档。
import torch.optim
optimizer = optim.SGD(model.parameters(), lr = 0.01, momentum=0.9)
optimizer = optim.Adam([var1, var2], lr = 0.0001)
import torch
# 创建样本
x = torch.randn(64 1000)
y = torch.randn(64, 10)
# 定义模型
model = torch.nn.Sequential(
torch.nn.Linear(D_in, H),
torch.nn.ReLU(),
torch.nn.Linear(H, D_out),
)
loss_fn = torch.nn.MSELoss(size_average=False)
# Use the optim package to define an Optimizer that will update the weights of
# the model for us. Here we will use Adam; the optim package contains many other
# optimization algoriths. The first argument to the Adam constructor tells the
# optimizer which Tensors it should update.
# 创建优化器
learning_rate = 1e-4
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
# 开始训练
for t in range(500):
# Forward pass: compute predicted y by passing x to the model.
y_pred = model(x)
# Compute and print loss.
loss = loss_fn(y_pred, y)
print(t, loss.item())
# Before the backward pass, use the optimizer object to zero all of the
# gradients for the Tensors it will update (which are the learnable weights
# of the model)
# 优化器优化过程
optimizer.zero_grad()
# Backward pass: compute gradient of the loss with respect to model parameters
loss.backward()
# Calling the step function on an Optimizer makes an update to its parameters
optimizer.step()
tensorflow
优化器主要使用apply_gradients方法传入变量和对应梯度从而来对给定变量进行迭代,或者直接使用minimize方法对目标函数进行迭代优化。
当然,更常见的使用是在编译时将优化器传入keras的Model,通过调用model.fit实现对Loss的的迭代优化。
初始化优化器时会创建一个变量optimier.iterations用于记录迭代的次数。因此优化器和tf.Variable一样,一般需要在@tf.function外创建。
import numpy as np
import tensorflow as tf
# 求f(x) = a*x**2 + b*x + c的最小值
# 使用optimizer.apply_gradients
x = tf.Variable(0.0,name = "x",dtype = tf.float32)
optimizer = tf.keras.optimizers.SGD(learning_rate=0.01)
@tf.function
def minimizef():
a = tf.constant(1.0)
b = tf.constant(-2.0)
c = tf.constant(1.0)
while tf.constant(True):
with tf.GradientTape() as tape:
y = a*tf.pow(x,2) + b*x + c
dy_dx = tape.gradient(y,x)
optimizer.apply_gradients(grads_and_vars=[(dy_dx,x)])
#迭代终止条件
if tf.abs(dy_dx)<tf.constant(0.00001):
break
if tf.math.mod(optimizer.iterations,100)==0:
printbar()
tf.print("step = ",optimizer.iterations)
tf.print("x = ", x)
tf.print("")
y = a*tf.pow(x,2) + b*x + c
return y
tf.print("y =",minimizef())
tf.print("x =",x)
# 求f(x) = a*x**2 + b*x + c的最小值
# 使用optimizer.minimize
x = tf.Variable(0.0,name = "x",dtype = tf.float32)
optimizer = tf.keras.optimizers.SGD(learning_rate=0.01)
def f():
a = tf.constant(1.0)
b = tf.constant(-2.0)
c = tf.constant(1.0)
y = a*tf.pow(x,2)+b*x+c
return(y)
@tf.function
def train(epoch = 1000):
for _ in tf.range(epoch):
optimizer.minimize(f,[x])
tf.print("epoch = ",optimizer.iterations)
return(f())
train(1000)
tf.print("y = ",f())
tf.print("x = ",x)
# 求f(x) = a*x**2 + b*x + c的最小值
# 使用model.fit
tf.keras.backend.clear_session()
class FakeModel(tf.keras.models.Model):
def __init__(self,a,b,c):
super(FakeModel,self).__init__()
self.a = a
self.b = b
self.c = c
def build(self):
self.x = tf.Variable(0.0,name = "x")
self.built = True
def call(self,features):
loss = self.a*(self.x)**2+self.b*(self.x)+self.c
return(tf.ones_like(features)*loss)
def myloss(y_true,y_pred):
return tf.reduce_mean(y_pred)
model = FakeModel(tf.constant(1.0),tf.constant(-2.0),tf.constant(1.0))
model.build()
model.summary()
# keras的Model,通过调用model.fit实现
model.compile(optimizer =
tf.keras.optimizers.SGD(learning_rate=0.01),loss = myloss)
history = model.fit(tf.zeros((100,2)),
tf.ones(100),batch_size = 1,epochs = 10) #迭代1000次
tf.print("x=",model.x)
tf.print("loss=",model(tf.constant(0.0)))
评估指标metrics
损失函数除了作为模型训练时候的优化目标,也能够作为模型好坏的一种评价指标。但通常人们还会从其它角度评估模型的好坏。
这就是评估指标。通常损失函数都可以作为评估指标,如MAE,MSE,CategoricalCrossentropy等也是常用的评估指标。
但评估指标不一定可以作为损失函数,例如AUC,Accuracy,Precision。因为评估指标不要求连续可导,而损失函数通常要求连续可导。
编译模型时,可以通过列表形式指定多个评估指标。
如果有需要,也可以自定义评估指标。
**tensorflow中:**可以对tf.keras.metrics.Metric进行子类化,重写初始化方法, update_state方法, result方法实现评估指标的计算逻辑,从而得到评估指标的类的实现形式。
**pytroch中:**是没有metrics的API接口的!pytorch_lightning.metric已经被废弃了,里面的一些函数以及包被作者放到了另外一个包里面。这个包就是TorchMetrics,这个玩意也是同一个团队开发的,但是并不属于同一个库。所以这里不讲解pytorch的接口。可以自定义实现。
由于训练的过程通常是分批次训练的,而评估指标要跑完一个epoch才能够得到整体的指标结果。因此,类形式的评估指标更为常见。即需要编写初始化方法以创建与计算指标结果相关的一些中间变量,编写update_state方法在每个batch后更新相关中间变量的状态,编写result方法输出最终指标结果。
如果编写函数形式的评估指标,则只能取epoch中各个batch计算的评估指标结果的平均值作为整个epoch上的评估指标结果,这个结果通常会偏离整个epoch数据一次计算的结果。

内置评估指标
tensorflow
内置评估指标只有tensorflow有,pytorch没有,所以pytorch实现评估指标可以引用TorchMetrics包中的函数实现,或者自定义。这里列的函数都是tensorflow中有的。
- MeanSquaredError(均方误差,用于回归,可以简写为MSE,函数形式为mse)
- MeanAbsoluteError (平均绝对值误差,用于回归,可以简写为MAE,函数形式为mae)
- MeanAbsolutePercentageError (平均百分比误差,用于回归,可以简写为MAPE,函数形式为mape)
- RootMeanSquaredError (均方根误差,用于回归)
- Accuracy (准确率,用于分类,可以用字符串"Accuracy"表示,Accuracy=(TP+TN)/(TP+TN+FP+FN),要求y_true和y_pred都为类别序号编码)
- Precision (精确率,用于二分类,Precision = TP/(TP+FP))
- Recall (召回率,用于二分类,Recall = TP/(TP+FN))
- TruePositives (真正例,用于二分类)
- TrueNegatives (真负例,用于二分类)
- FalsePositives (假正例,用于二分类)
- FalseNegatives (假负例,用于二分类)
- AUC(ROC曲线(TPR vs FPR)下的面积,用于二分类,直观解释为随机抽取一个正样本和一个负样本,正样本的预测值大于负样本的概率)
- CategoricalAccuracy(分类准确率,与Accuracy含义相同,要求y_true(label)为onehot编码形式)
- SparseCategoricalAccuracy (稀疏分类准确率,与Accuracy含义相同,要求y_true(label)为序号编码形式)
- MeanIoU (Intersection-Over-Union,常用于图像分割)
- TopKCategoricalAccuracy (多分类TopK准确率,要求y_true(label)为onehot编码形式)
- SparseTopKCategoricalAccuracy (稀疏多分类TopK准确率,要求y_true(label)为序号编码形式)
- Mean (平均值)
- Sum (求和)

自定义评估指标
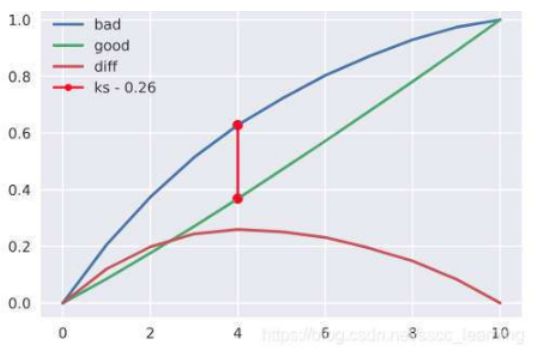
我们以金融风控领域常用的KS指标为例,示范自定义评估指标。
KS指标适合二分类问题,其计算方式为 KS=max(TPR-FPR).
其中TPR=TP/(TP+FN) , FPR = FP/(FP+TN)
TPR曲线实际上就是正样本的累积分布曲线(CDF),FPR曲线实际上就是负样本的累积分布曲线(CDF)。
KS指标就是正样本和负样本累积分布曲线差值的最大值。
pytorch
pytorch实现ks评估指标,可以自定义函数实现,在训练过程中在相应的epoch完成后调用,传入y_pre,y_ture,实现评估效果。
import numpy as np
import pandas as pd
def ks(df, y_true, y_pre, num=10, good=0, bad=1):
# 1.将数据从小到大平均分成num组
df_ks = df.sort_values(y_pre).reset_index(drop=True)
df_ks['rank'] = np.floor((df_ks.index / len(df_ks) * num) + 1)
df_ks['set_1'] = 1
# 2.统计结果
result_ks = pd.DataFrame()
result_ks['group_sum'] = df_ks.groupby('rank')['set_1'].sum()
result_ks['group_min'] = df_ks.groupby('rank')[y_pre].min()
result_ks['group_max'] = df_ks.groupby('rank')[y_pre].max()
result_ks['group_mean'] = df_ks.groupby('rank')[y_pre].mean()
# 3.最后一行添加total汇总数据
result_ks.loc['total', 'group_sum'] = df_ks['set_1'].sum()
result_ks.loc['total', 'group_min'] = df_ks[y_pre].min()
result_ks.loc['total', 'group_max'] = df_ks[y_pre].max()
result_ks.loc['total', 'group_mean'] = df_ks[y_pre].mean()
# 4.好用户统计
result_ks['good_sum'] = df_ks[df_ks[y_true] == good].groupby('rank')['set_1'].sum()
result_ks.good_sum.replace(np.nan, 0, inplace=True)
result_ks.loc['total', 'good_sum'] = result_ks['good_sum'].sum()
result_ks['good_percent'] = result_ks['good_sum'] / result_ks.loc['total', 'good_sum']
result_ks['good_percent_cum'] = result_ks['good_sum'].cumsum() / result_ks.loc['total', 'good_sum']
# 5.坏用户统计
result_ks['bad_sum'] = df_ks[df_ks[y_true] == bad].groupby('rank')['set_1'].sum()
result_ks.bad_sum.replace(np.nan, 0, inplace=True)
result_ks.loc['total', 'bad_sum'] = result_ks['bad_sum'].sum()
result_ks['bad_percent'] = result_ks['bad_sum'] / result_ks.loc['total', 'bad_sum']
result_ks['bad_percent_cum'] = result_ks['bad_sum'].cumsum() / result_ks.loc['total', 'bad_sum']
# 6.计算ks值
result_ks['diff'] = result_ks['bad_percent_cum'] - result_ks['good_percent_cum']
# 7.更新最后一行total的数据
result_ks.loc['total', 'bad_percent_cum'] = np.nan
result_ks.loc['total', 'good_percent_cum'] = np.nan
result_ks.loc['total', 'diff'] = result_ks['diff'].max()
result_ks = result_ks.reset_index()
return result_ks
通过sklearn.metrics中函数roc_curve直接获取。
from sklearn.metrics import roc_curve
fpr, tpr, thresholds= roc_curve(df.label, df.score)
ks_value = max(abs(fpr-tpr))
tensorflow
#函数形式的自定义评估指标
@tf.function
def ks(y_true,y_pred):
y_true = tf.reshape(y_true,(-1,))
y_pred = tf.reshape(y_pred,(-1,))
length = tf.shape(y_true)[0]
t = tf.math.top_k(y_pred,k = length,sorted = False)
y_pred_sorted = tf.gather(y_pred,t.indices)
y_true_sorted = tf.gather(y_true,t.indices)
cum_positive_ratio = tf.truediv(
tf.cumsum(y_true_sorted),tf.reduce_sum(y_true_sorted))
cum_negative_ratio = tf.truediv(
tf.cumsum(1 - y_true_sorted),tf.reduce_sum(1 - y_true_sorted))
ks_value = tf.reduce_max(tf.abs(cum_positive_ratio - cum_negative_ratio))
return ks_value
y_true = tf.constant([[1],[1],[1],[0],[1],[1],[1],[0],[0],[0],[1],[0],[1],[0]])
y_pred = tf.constant([[0.6],[0.1],[0.4],[0.5],[0.7],[0.7],[0.7],
[0.4],[0.4],[0.5],[0.8],[0.3],[0.5],[0.3]])
tf.print(ks(y_true,y_pred))
# 0.625
#类形式的自定义评估指标
class KS(metrics.Metric):
def __init__(self, name = "ks", **kwargs):
super(KS,self).__init__(name=name,**kwargs)
self.true_positives = self.add_weight(
name = "tp",shape = (101,), initializer = "zeros")
self.false_positives = self.add_weight(
name = "fp",shape = (101,), initializer = "zeros")
@tf.function
def update_state(self,y_true,y_pred):
y_true = tf.cast(tf.reshape(y_true,(-1,)),tf.bool)
y_pred = tf.cast(100*tf.reshape(y_pred,(-1,)),tf.int32)
for i in tf.range(0,tf.shape(y_true)[0]):
if y_true[i]:
self.true_positives[y_pred[i]].assign(
self.true_positives[y_pred[i]]+1.0)
else:
self.false_positives[y_pred[i]].assign(
self.false_positives[y_pred[i]]+1.0)
return (self.true_positives,self.false_positives)
@tf.function
def result(self):
cum_positive_ratio = tf.truediv(
tf.cumsum(self.true_positives),tf.reduce_sum(self.true_positives))
cum_negative_ratio = tf.truediv(
tf.cumsum(self.false_positives),tf.reduce_sum(self.false_positives))
ks_value = tf.reduce_max(tf.abs(cum_positive_ratio - cum_negative_ratio))
return ks_value
y_true = tf.constant([[1],[1],[1],[0],[1],[1],[1],[0],[0],[0],[1],[0],[1],[0]])
y_pred = tf.constant([[0.6],[0.1],[0.4],[0.5],[0.7],[0.7],
[0.7],[0.4],[0.4],[0.5],[0.8],[0.3],[0.5],[0.3]])
myks = KS()
myks.update_state(y_true,y_pred)
tf.print(myks.result())
# 0.625
nn.Module和tf.Module
在pytorch中:module是一个类,是对functional中的函数的功能扩展,添加了参数和信息管理等功能,但是它的计算功能还是通过调用functional中的函数来实现的。Conv,pool,Batchnorm,ReLU等方法都是神经网络中常见的操作,我们可以根据这些方法来自定义网络模型,也可以根据需求对经典模型进行调整,他们都继承共同的抽象类nn.Module来实现。
nn.Module除了可以管理其引用的各种参数,还可以管理其引用的子模块,功能十分强大。
在tensorflow中:tf.keras中的模型和层(models,layers,losses,metrics)都是继承tf.Module实现的,也具有变量管理和子模块管理功能。

使用Module来管理参数
pytorch
在Pytorch中,模型的参数是需要被优化器训练的,因此,通常要设置参数为 requires_grad = True 的张量。
同时,在一个模型中,往往有许多的参数,要手动管理这些参数并不是一件容易的事情。
Pytorch一般将参数用nn.Parameter来表示,并且用nn.Module来管理其结构下的所有参数。
import torch
from torch import nn
import torch.nn.functional as F
from matplotlib import pyplot as plt
# nn.Parameter 具有 requires_grad = True 属性
w = nn.Parameter(torch.randn(2,2))
print(w)
print(w.requires_grad)
# Parameter containing:
# tensor([[ 0.3544, -1.1643],
# [ 1.2302, 1.3952]], requires_grad=True)
# True
# nn.ParameterList 可以将多个nn.Parameter组成一个列表
params_list = nn.ParameterList([nn.Parameter(torch.rand(8,i)) for i in range(1,3)])
print(params_list)
print(params_list[0].requires_grad)
# ParameterList(
# (0): Parameter containing: [torch.FloatTensor of size 8x1]
# (1): Parameter containing: [torch.FloatTensor of size 8x2]
# )
# True
# nn.ParameterDict 可以将多个nn.Parameter组成一个字典
params_dict = nn.ParameterDict({"a":nn.Parameter(torch.rand(2,2)),
"b":nn.Parameter(torch.zeros(2))})
print(params_dict)
print(params_dict["a"].requires_grad)
# ParameterDict(
# (a): Parameter containing: [torch.FloatTensor of size 2x2]
# (b): Parameter containing: [torch.FloatTensor of size 2]
# )
# True
# 可以用Module将它们管理起来
# module.parameters()返回一个生成器,包括其结构下的所有parameters
module = nn.Module()
module.w = w
module.params_list = params_list
module.params_dict = params_dict
num_param = 0
for param in module.parameters():
print(param,"\n")
num_param = num_param + 1
print("number of Parameters =",num_param)
# Parameter containing:
# tensor([[ 0.3544, -1.1643],
# [ 1.2302, 1.3952]], requires_grad=True)
#
# Parameter containing:
# tensor([[0.9391],
# [0.7590],
# [0.6899],
# [0.4786],
# [0.2392],
# [0.9645],
# [0.1968],
# [0.1353]], requires_grad=True)
#
# Parameter containing:
# tensor([[0.8012, 0.9587],
# [0.0276, 0.5995],
# [0.7338, 0.5559],
# [0.1704, 0.5814],
# [0.7626, 0.1179],
# [0.4945, 0.2408],
# [0.7179, 0.0575],
# [0.3418, 0.7291]], requires_grad=True)
#
# Parameter containing:
# tensor([[0.7729, 0.2383],
# [0.7054, 0.9937]], requires_grad=True)
#
# Parameter containing:
# tensor([0., 0.], requires_grad=True)
#
# number of Parameters = 5
#实践当中,一般通过继承nn.Module来构建模块类,并将所有含有需要学习的参数的部分放在构造函数中。
#以下范例为Pytorch中nn.Linear的源码的简化版本
#可以看到它将需要学习的参数放在了__init__构造函数中,并在forward中调用F.linear函数来实现计算逻辑。
class Linear(nn.Module):
__constants__ = ['in_features', 'out_features']
def __init__(self, in_features, out_features, bias=True):
super(Linear, self).__init__()
self.in_features = in_features
self.out_features = out_features
self.weight = nn.Parameter(torch.Tensor(out_features, in_features))
if bias:
self.bias = nn.Parameter(torch.Tensor(out_features))
else:
self.register_parameter('bias', None)
def forward(self, input):
return F.linear(input, self.weight, self.bias)
tensorflow
tf.keras中的模型和层都是继承tf.Module实现的,也具有变量管理功能。
import tensorflow as tf
from tensorflow.keras import models,layers,losses,metrics
# 继承关系
print(issubclass(tf.keras.Model,tf.Module))
print(issubclass(tf.keras.layers.Layer,tf.Module))
print(issubclass(tf.keras.Model,tf.keras.layers.Layer))
# True
# True
# True
tf.keras.backend.clear_session()
model = models.Sequential()
model.add(layers.Dense(4,input_shape = (10,)))
model.add(layers.Dense(2))
model.add(layers.Dense(1))
model.summary()
# Model: "sequential"
# _________________________________________________________________
# Layer (type) Output Shape Param #
# =================================================================
# dense (Dense) (None, 4) 44
# _________________________________________________________________
# dense_1 (Dense) (None, 2) 10
# _________________________________________________________________
# dense_2 (Dense) (None, 1) 3
# =================================================================
# Total params: 57
# Trainable params: 57
# Non-trainable params: 0
# _________________________________________________________________
# 查看变量
model.variables
# [
# array([[-0.06741005, 0.45534766, 0.5190817 , -0.01806331],
# [-0.14258742, -0.49711505, 0.26030976, 0.18607801],
# [-0.62806034, 0.5327399 , 0.42206633, 0.29201728],
# [-0.16602087, -0.18901917, 0.55159235, -0.01091868],
# [ 0.04533798, 0.326845 , -0.582667 , 0.19431782],
# [ 0.6494713 , -0.16174704, 0.4062966 , 0.48760796],
# [ 0.58400524, -0.6280886 , -0.11265379, -0.6438277 ],
# [ 0.26642334, 0.49275804, 0.20793378, -0.43889117],
# [ 0.4092741 , 0.09871006, -0.2073121 , 0.26047975],
# [ 0.43910992, 0.00199282, -0.07711256, -0.27966842]],
# dtype=float32)>,
# ,
#
# array([[ 0.5022683 , -0.0507431 ],
# [-0.61540484, 0.9369011 ],
# [-0.14412141, -0.54607415],
# [ 0.2027781 , -0.4651153 ]], dtype=float32)>,
# ,
#
# array([[-0.244825 ],
# [-1.2101456]], dtype=float32)>,
#
# dtype=float32)>]
model.layers[0].trainable = False #冻结第0层的变量,使其不可训练
model.trainable_variables
# [
# array([[ 0.5022683 , -0.0507431 ],
# [-0.61540484, 0.9369011 ],
# [-0.14412141, -0.54607415],
# [ 0.2027781 , -0.4651153 ]], dtype=float32)>,
# ,
#
# array([[-0.244825 ],
# [-1.2101456]], dtype=float32)>,
# ]
使用Module管理子模块
pytorch
一般情况下,我们都很少直接使用 nn.Parameter来定义参数构建模型,而是通过一些拼装一些常用的模型层来构造模型。
这些模型层也是继承自nn.Module的对象,本身也包括参数,属于我们要定义的模块的子模块。
nn.Module提供了一些方法可以管理这些子模块。
- children() 方法: 返回生成器,包括模块下的所有子模块。
- named_children()方法:返回一个生成器,包括模块下的所有子模块,以及它们的名字。
- modules()方法:返回一个生成器,包括模块下的所有各个层级的模块,包括模块本身。
- named_modules()方法:返回一个生成器,包括模块下的所有各个层级的模块以及它们的名字,包括模块本身。
其中chidren()方法和named_children()方法较多使用。
modules()方法和named_modules()方法较少使用,其功能可以通过多个named_children()的嵌套使用实现。
# 自创模型,继承自Model
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.embedding = nn.Embedding(num_embeddings = 10000,embedding_dim = 3,padding_idx = 1)
self.conv = nn.Sequential()
self.conv.add_module("conv_1",nn.Conv1d(in_channels = 3,out_channels = 16,kernel_size = 5))
self.conv.add_module("pool_1",nn.MaxPool1d(kernel_size = 2))
self.conv.add_module("relu_1",nn.ReLU())
self.conv.add_module("conv_2",nn.Conv1d(in_channels = 16,out_channels = 128,kernel_size = 2))
self.conv.add_module("pool_2",nn.MaxPool1d(kernel_size = 2))
self.conv.add_module("relu_2",nn.ReLU())
self.dense = nn.Sequential()
self.dense.add_module("flatten",nn.Flatten())
self.dense.add_module("linear",nn.Linear(6144,1))
self.dense.add_module("sigmoid",nn.Sigmoid())
def forward(self,x):
x = self.embedding(x).transpose(1,2)
x = self.conv(x)
y = self.dense(x)
return y
net = Net()
# 查看子模块
i = 0
for child in net.children():
i+=1
print(child,"\n")
print("child number",i)
# Embedding(10000, 3, padding_idx=1)
#
# Sequential(
# (conv_1): Conv1d(3, 16, kernel_size=(5,), stride=(1,))
# (pool_1): MaxPool1d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
# (relu_1): ReLU()
# (conv_2): Conv1d(16, 128, kernel_size=(2,), stride=(1,))
# (pool# _2): MaxPool1d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
# (relu_2): ReLU()
# )
#
# Sequential(
# (flatten): Flatten()
# (linear): Linear(in_features=6144, out_features=1, bias=True)
# (sigmoid): Sigmoid()
# )
#
# child number 3
# i = 0
for name,child in net.named_children():
i+=1
print(name,":",child,"\n")
print("child number",i)
# embedding : Embedding(10000, 3, padding_idx=1)
#
# conv : Sequential(
# (conv_1): Conv1d(3, 16, kernel_size=(5,), stride=(1,))
# (pool_1): MaxPool1d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
# (relu_1): ReLU()
# (conv_2): Conv1d(16, 128, kernel_size=(2,), stride=(1,))
# (pool_2): MaxPool1d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
# (relu_2): ReLU()
# )
#
# dense : Sequential(
# (flatten): Flatten()
# (linear): Linear(in_features=6144, out_features=1, bias=True)
# (sigmoid): Sigmoid()
# )
#
# child number 3
i = 0
for module in net.modules():
i+=1
print(module)
print("module number:",i)
# Net(
# (embedding): Embedding(10000, 3, padding_idx=1)
# (conv): Sequential(
# (conv_1): Conv1d(3, 16, kernel_size=(5,), stride=(1,))
# (pool_1): MaxPool1d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
# (relu_1): ReLU()
# (conv_2): Conv1d(16, 128, kernel_size=(2,), stride=(1,))
# (pool_2): MaxPool1d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
# (relu_2): ReLU()
# )
# (dense): Sequential(
# (flatten): Flatten()
# (linear): Linear(in_features=6144, out_features=1, bias=True)
# (sigmoid): Sigmoid()
# )
# )
# Embedding(10000, 3, padding_idx=1)
# Sequential(
# (conv_1): Conv1d(3, 16, kernel_size=(5,), stride=(1,))
# (pool_1): MaxPool1d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
# (relu_1): ReLU()
# (conv_2): Conv1d(16, 128, kernel_size=(2,), stride=(1,))
# (pool_2): MaxPool1d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
# (relu_2): ReLU()
# )
# Conv1d(3, 16, kernel_size=(5,), stride=(1,))
# MaxPool1d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
# ReLU()
# Conv1d(16, 128, kernel_size=(2,), stride=(1,))
# MaxPool1d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
# ReLU()
# Sequential(
# (flatten): Flatten()
# (linear): Linear(in_features=6144, out_features=1, bias=True)
# (sigmoid): Sigmoid()
# )
# Flatten()
# Linear(in_features=6144, out_features=1, bias=True)
# Sigmoid()
# module number: 13
下面我们通过named_children方法找到embedding层,并将其参数设置为不可训练(相当于冻结embedding层。
children_dict = {name:module for name,module in net.named_children()}
print(children_dict)
# {'embedding': Embedding(10000, 3, padding_idx=1), 'conv': Sequential(
# (conv_1): Conv1d(3, 16, kernel_size=(5,), stride=(1,))
# (pool_1): MaxPool1d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
# (relu_1): ReLU()
# (conv_2): Conv1d(16, 128, kernel_size=(2,), stride=(1,))
# (pool_2): MaxPool1d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
# (relu_2): ReLU()
# ), 'dense': Sequential(
# (flatten): Flatten()
# (linear): Linear(in_features=6144, out_features=1, bias=True)
# (sigmoid): Sigmoid()
# )}
embedding = children_dict["embedding"]
embedding.requires_grad_(False) #冻结其参数
#可以看到其第一层的参数已经不可以被训练了。
for param in embedding.parameters():
print(param.requires_grad)
print(param.numel())
# False
# 30000
from torchkeras import summary
summary(net,input_shape = (200,),input_dtype = torch.LongTensor)
# 不可训练参数数量增加
'''
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Embedding-1 [-1, 200, 3] 30,000
Conv1d-2 [-1, 16, 196] 256
MaxPool1d-3 [-1, 16, 98] 0
ReLU-4 [-1, 16, 98] 0
Conv1d-5 [-1, 128, 97] 4,224
MaxPool1d-6 [-1, 128, 48] 0
ReLU-7 [-1, 128, 48] 0
Flatten-8 [-1, 6144] 0
Linear-9 [-1, 1] 6,145
Sigmoid-10 [-1, 1] 0
================================================================
Total params: 40,625
Trainable params: 10,625
Non-trainable params: 30,000
----------------------------------------------------------------
Input size (MB): 0.000763
Forward/backward pass size (MB): 0.287796
Params size (MB): 0.154972
Estimated Total Size (MB): 0.443531
----------------------------------------------------------------
'''
tensorflow
tf.keras.backend.clear_session()
model = models.Sequential()
model.add(layers.Dense(4,input_shape = (10,)))
model.add(layers.Dense(2))
model.add(layers.Dense(1))
model.summary()
'''
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 4) 44
_________________________________________________________________
dense_1 (Dense) (None, 2) 10
_________________________________________________________________
dense_2 (Dense) (None, 1) 3
=================================================================
Total params: 57
Trainable params: 57
Non-trainable params: 0
_________________________________________________________________
'''
model.submodules # 子模块
# (,
# ,
# ,
# )
model.layers # 模型中的层
# [,
# ,
# ]
print(model.name)
print(model.name_scope())
# sequential
# sequential
说明
笔记中很多代码案例来自于:
《20天吃掉那只Pytorch》
- github项目地址: https://github.com/lyhue1991/eat_pytorch_in_20_days
《30天吃掉那只TensorFlow2》
- github项目地址: https://github.com/lyhue1991/eat_tensorflow2_in_30_days
感兴趣的同学可以进入学习。
===========================================================================
我的笔记一部分是将这两项目中内容整理归纳,一部分是相应功能的内容自己找资料整理归纳。
笔记以MD格式存入我的git仓库,另外代码案例所需要数据集文件也在其中:可以clone下来学习使用。
《pytorch-tensorflow对比学习笔记》
github项目地址: https://github.com/Boris-2021/pytorch-tensorflow-Comparative-study
===========================================================================
笔记中增加了很多趣味性的图片,增加阅读乐趣。
===========================================================================
感觉对你的学习有帮助,就点个星,点个赞,点个关注再走把,整理不易,拒绝白嫖从我做起!
