0x00000006 MMClassification 源码阅读 01 总览
文章目录
- 写在开头的话
- 代码文件组织
- References:
写在开头的话
- 本系列是MMClassification个人源码学习和分析。
- 阅读源码版本以博客公布时的MMClassification最新系列: V0.23.0为准。
- 个人学习目的:
a. 希望能够更好的使用MMClassification,甚至能够针对源码,修改部分代码实现个人特殊需求。
b. 借鉴好的编程风格和设计经验在自己的项目中。
c. 回顾深度学习基础backbone。
鉴于以上目的,个人撰写可能倾向与从设计和实现角度来解析。
阅读源码Tips
源码阅读通常是需要有一定需求下进行,如:
a. 优化业务流程。
b. 为项目添加新特性。
c. 技术提升。
d. 寻找问题。
e. …
在阅读前,建议完成以下步骤(或达到以下目标):
- 了解项目背景,需求:
这一部分在项目中有介绍:MMClassification is an open source image classification toolbox based on PyTorch. It is a part of the OpenMMLab project.
- 将项目运行起来,并且能够实现自己需求:
这一部分可以阅读官方文档的Get Started。
按照操作步骤训练出一个model。 - 确定好自己的目标去阅读代码:有一个目标阅读代码能够让我们有的放矢。能够优化我们阅读流程。
- 推荐前置学习过的知识点(这里主要针对本项目,看个人需求来修改,仅供参考):
a. 了解并能够简单使用源码包含的基本语言,需要使用的框架,库API。(本项目使用Python语言,Pytorch框架,中间也有部分其他库支持,如OpenCV,NumPy)
b. 对数据结构和基础算法有大致了解。(比如栈,递归,分治)
c. 对设计模式大致了解。(比如设计模式的七大原则,装饰器模式)。
由于MMClassification系列都是基于MMCV完成。
这里只会针对必要的部分进行分析(如:Register机制)。
代码文件组织
1. 对于一个全监督分类任务而言。我们主要完成进行以下环节:
- 模型训练
- 模型推理
- 模型测试(性能)
所以我们能够将以上环节进行拆分,基于已有的Pytorch框架,主要需要完成一下功能:
a. Datasets加载
b. DataAugmentation 实现
c. Backbone构建
d. Classifier构建
e. 训练和推理流程控制
f. 性能测试
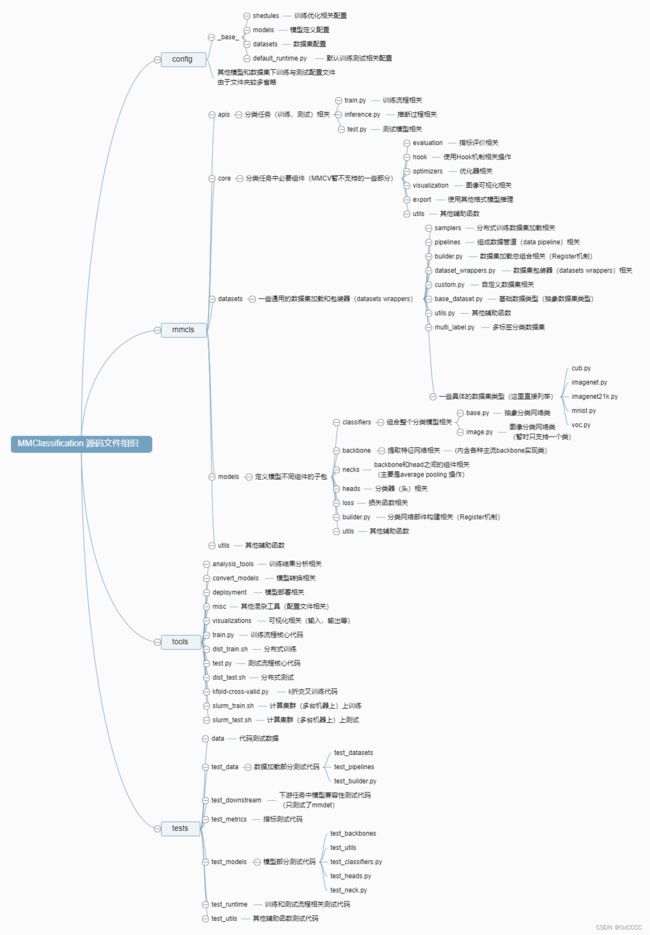
将这些部分根据官方文档和源码找到相关文件浏览后,代码组织结构如下:
2. 核心功能代码文件组织展示:
- config:主要是训练配置文件,文件包含模型,数据集,训练优化相关配置参数。
- mmcls:主要是将分类任务各部分组件实现,是该toolbox核心部分。
- tools:训练和测试流程中工具(主要将mmcls总的流程合并,并且提供一些辅助结果工具,如:CAM可视化)。
- test:项目主体测试代码。
BTW,对于一个较大项目,个人认为撰写测试代码是一个很重要的part。这是由于:
a. 每一个功能不一定写出来就没有问题。
b. 添加新功能可能会导致旧功能的问题。
c. 累积更多bug经验,(从长远角度看)加快开发进度。
(当然,这也要和开发时间和团队整体安排相一致。比如使用敏捷开发,或者有专业测试团队等等。这些都是现实工程中的trade off。需要就事论事分析。)
后面我们开始准备进入正式的分析。
大致思路:config->datasets->model->train & eval -> other tools (中间穿插测试代码)。
References:
- mmclassification 官方API文档参考:https://mmclassification.readthedocs.io/en/master/
- mmclassfication 源代码地址:https://github.com/open-mmlab/mmclassification