最先进的实体对齐方法的实验研究综述 An Experimental Study of State-of-the-Art Entity Alignment Approaches
最先进的实体对齐方法的实验研究
An Experimental Study of State-of-the-Art Entity Alignment Approaches
Xiang Zhao, Weixin Zeng, Jiuyang Tang, Wei Wang, and Fabian M. Suchanek
摘 要 摘要 摘要实体对齐 (EA) 寻找位于不同知识图谱 (KG) 中的等价实体,这是提高 KG 质量的重要步骤,因此对下游应用程序(例如,问答和推荐)具有重要意义。近年来,EA 方法迅速增加,但它们的相对性能仍不清楚,部分原因是经验评价不完整,以及比较是在不同设置(即数据集、用作输入的信息等)下进行的。在本文中,我们通过对最先进的 EA 方法进行全面评价和详细分析来填补空白。我们首先提出了一个包含所有当前方法的通用 EA 框架,然后将现有方法分为三大类。接下来,我们根据其有效性、效率和稳健性,在广泛的用例中审慎地评价这些解决方案。最后,我们构建了一个新的 EA 数据集来反映现实生活中的对齐挑战,这些挑战在很大程度上被现有文献所忽视。本研究力求清晰地展示当前 EA 方法的优缺点,以激发高质量的后续研究。
1. 简介
近年来,知识图谱 (KG) 及其应用日益增多。典型的 KG 以三元组的形式存储世界知识(即 ⟨ entity, relation, entity ⟩ \lang \text{entity, relation, entity}\rang ⟨entity, relation, entity⟩),其中实体(entity)指的是真实世界中的独特对象,而关系描述了将这些对象联系起来的关系。使用实体作为锚点,KG 中的三元组在本质上是相互关联的,因此构成了一个大的知识图谱。目前,我们有大量的 通 用 通用 通用KG(例如,DBpedia [1]、YAGO [52]、Google 的Knowledge Vault [14])和特定 领 域 领域 领域KG(例如,Medical [48] 和 Scientific KG [56])。这些 KG 已被用于增强各种下游应用,例如关键字搜索 [64]、事实检查 [30]、问答 [12] [28] 等。
在实践中,知识图谱通常由单个数据源构建,因此不太可能完全覆盖该领域 [46]。为了增加其完整性,一种流行的方法是整合来自其他 KG 的知识,这些知识可能包含额外的或补充的信息。例如,一般 KG 可能只涉及有关科学家的基本信息,而更多细节(例如个人简介和出版物列表)可以在科学领域 KG 中找到。为了巩固 KG 之间的知识,一个关键步骤是对齐不同 KG 中的等价实体,这称为 实 体 对 齐 实体对齐 实体对齐(EA) [7]、[25]。1
一般来说,当前的EA 方法主要通过假设不同 KG 中的等价实体具有相似的相邻结构,并采用表示学习方法将实体作为数据点嵌入到低维特征空间中来解决该问题。通过执行有效的(实体)嵌入,可以轻松地用数据点之间的距离来评价实体的成对差异,以确定两个实体是否匹配。
虽然该方向正在迅速发展(例如,在过去三年中发表了 20 多篇论文),但没有对这些解决方案进行系统和全面的比较。本文对最先进的 EA 方法进行经验评价,具有以下特征:
(1) 类 别 内 和 类 别 间 的 公 平 比 较 类别内和类别间的公平比较 类别内和类别间的公平比较。几乎所有最近的研究[5], [24], [38], [55], [60], [61], [62], [63], [67] 都仅限于与一部分方法进行比较。此外,不同的方法遵循不同的设置:一些仅使用 KG 结构进行对齐,而另一些还使用附加信息,一些在一轮比较中对齐 KG,而另一些则采用迭代(重新)训练策略。尽管文献中报道的这些方法的直接比较证明了解决方案的整体有效性,但更可取和更公平的做法是将这些方法分组,然后比较类别内和类别间的结果。
在这项研究中,我们对大多数最先进的方法进行横向比较,包括那些最近提出的但尚未与其他方法进行比较的方法。通过将它们分为三组,并对组内和组间评价进行详细分析,我们能够更好地定位这些方法并评价其有效性。
(2) 代 表 性 数 据 集 的 综 合 评 价 代表性数据集的综合评价 代表性数据集的综合评价。为了评价 EA 系统的性能,已经构建了几个数据集,这些数据集可以大致分为以DBP15K [53]为代表的 跨 语 言 跨语言 跨语言基准测试和以DWY100K [54] 为代表的 单 语 言 单语言 单语言基准测试。最近的一项研究 [24] 指出,以前数据集中的KG比现实生活中的要 稠 密 稠密 稠密得多,因此它创建了SRPRS数据集,其实体度数遵循 正 态 正态 正态分布。尽管有多种数据集可供选择,但现有研究仅报告他们在一个或两个特定数据集上的结果,因此难以评价它们在各种可能场景中的有效性,例如跨语言/单语言、稠密/正态、大型/中型 KG。
作为回应,本研究对包含 9 个 KG 对的所有代表性数据集(即DBP15K、DWY100K和SRPRS)进行了全面的实验评价,并在有效性、效率和稳健性方面进行了深入分析。
(3) 应 对 现 实 生 活 挑 战 的 新 数 据 集 应对现实生活挑战的新数据集 应对现实生活挑战的新数据集。对于源 KG 中的每个实体,现有的 EA 数据集在目标 KG 中仅包含一个对应实体。然而,这是一个不现实的场景。在现实生活中,一个KG 中常常包含其他 KG 不包含的实体。例如,在对齐 YAGO 4 和 IMDB 时,YAGO 4 中只有 1% 的实体与电影相关,而 YAGO 4 中其他 99% 的实体在 IMDB 中不包含匹配项。这些无法匹配的实体会增加 EA 的难度。
此外,我们观察到现有单语数据集中的不同KG 使用相同的命名约定,依赖实体名称之间字符串相似度的基线方法可以达到 100% 的准确率。然而,在现实生活中,不同 KG 中的等价实体的名称可能不相似,例如,“America”与“U.S.”。此外,KG 中的不同实体可能具有相同的名称,这对EA 构成了一个被忽视的障碍,因为无法保证源 KG 中名称为“Paris”的实体与目标 KG 中具有相同名称的实体相同——仅仅因为一个可能是法国的城市,另一个可能是德克萨斯的城市。
由于这些原因,我们认为 EA 的现有数据集过于简化了无法匹配的实体和有歧义的实体名称所面临的现实挑战。为了更好地反映这些挑战,我们提出了一个反映这些实际困难的新数据集。
贡 献 贡献 贡献。总体而言,本文既面向科学界也面向业界。这篇文章的主要贡献是:
- 据我们所知,本研究是系统和全面评价最先进的 EA 方法的首批尝试之一。这通过以下方式实现: (1) 确定现有 EA 方法的主要组成部分,并提供一个通用 EA 框架,(2)将最先进的方法分为三类,并进行详细的组内和组间评价,从而更好地定位不同的EA 解决方案, (3)在广泛的用例上检查这些方法,包括跨/单语言对齐,以及在稠密/正态、大/中规模数据上的对齐。经验结果揭示了每个解决方案的 有 效 性 有效性 有效性、 效 率 效率 效率和 稳 健 性 稳健性 稳健性。
- 我们从研究中获得的经验和见解让我们发现当前 EA 数据集的不足之处。作为补救措施,我们构建了一个新的单语数据集来反映无法匹配的实体和有歧义的实体名称的现实挑战。我们希望这个新数据集能够作为评价 EA 系统的更好基准。
组 织 组织 组织。第 2 节形式化了 EA 任务,并定义了本研究的范围。第 3 节介绍了一个包含最新 EA 方法的一般框架。第 4 节详细阐述了分类、实验设置、结果和讨论。第 5 节提供了一个新的数据集和进一步的实验,第 6 节总结了这篇文章。
2 预备知识
本节正式定义了本研究的任务和范围。
2.1 任务定义
A KG $G = (E, R, T) 是 一 个 有 向 图 , 包 括 一 组 实 体 是一个有向图,包括一组实体 是一个有向图,包括一组实体E$ 、关系 R R R和三元组 T ⊆ E × R × E T \subseteq E \times R \times E T⊆E×R×E 。三元组 ( h , r , t ) ∈ T ( h, r, t )\in T (h,r,t)∈T表示头实体 h h h通过关系 r r r连接到尾实体 t t t。每个实体被分配了一个唯一的标识符,例如DBpedia中的http://dbpedia.org/resource/Spain。
给定一个源 KG G 1 = ( E 1 , R 1 , T 1 ) G_1 = ( E_1 , R_1 , T_1 ) G1=(E1,R1,T1),目标 KG $G_2 = ( E_2 , R_2 , T_2 ) , 种 子 实 体 对 ( 训 练 集 ) , 即 ,种子实体对(训练集),即 ,种子实体对(训练集),即S = {( u, v )| u \in E_1, v_2\in E_2, u \leftrightarrow v }$ ,其中 ↔ \leftrightarrow ↔表示等价(即 u u u和 v v v指代相同的现实世界对象),EA 的任务可以定义为在测试集中发现等价的实体对。
例 1。图 1 显示了关于导演 Alfonso Cuar o ˊ n \text{Alfonso Cuar}\acute{\text o}\text n Alfonso Cuaroˊn 的部分英语 KG (KG EN _\text{EN} EN ) 和部分西班牙语 KG (KG ES _\text{ES} ES) 。给定种子实体对,即来自 KG EN _\text{EN} EN的 Mexico \verb+Mexico+ Mexico和来自 KG ES _\text{ES} ES的 Mexico \verb+Mexico+ Mexico,EA 旨在在测试集中找到等价的实体对,例如,返回KG ES _\text{ES} ES中的 Roma(ciudad) \verb+Roma(ciudad)+ Roma(ciudad) 作为KG EN _\text{EN} EN中的源实体 Roma(city) \verb+Roma(city)+ Roma(city)对应的目标实体。

图 1. EA 示例。实体标识符放在方括号中。为清楚起见,省略了实体标识符和完整关系标识符的前缀,种子实体对由虚线连接。
2.2 范围及相关工作
虽然 EA 问题是几年前提出的,但该问题的更通用版本——识别来自不同数据源的同一现实世界实体的实体记录——已经由不同社区从不同角度进行了研究,包括实体消解 (ER) [15]、[18]、[45]、实体匹配 [13]、[42] ,记录链接 [8]、[34]、去重 [16]、实例/本体匹配 [20]、[35]、[49]、[50]、[51]、链接发现 [43]、[44],实体链接/实体消歧[11]、[29]。接下来,我们描述这项实验研究的相关工作和范围。
实 体 链 接 实体链接 实体链接。实体链接(EL)的任务也称为实体消歧。它关注识别自然语言文本中的实体提及(mention),并将它们映射到给定参考目录(大多数情况下为 KG)中的实体。例如,目标是将某些自然语言文本中的字符串“Rome”识别为实体提及,并找出它是指意大利的首都还是名字为“Rome”的众多电影中的一部。现有方法 [21]、[22]、[29]、[36]、[68] 利用大量信息,包括实体提及周围的单词、某些目标实体的先验概率、已经消歧的实体提及、维基百科等背景知识,以消除链接目标的歧义。但是,大多数信息在我们的 KG 对齐场景中不可用(例如,实体描述的嵌入,或着给定提及的实体链接的先验分布)。此外,EL 涉及自然语言文本和 KG 之间的映射。相比之下,我们的工作研究了两个 KG 之间的实体映射。
实 体 消 解 实体消解 实体消解。实体消解(ER)的任务,也被称为实体匹配、去重或记录链接,假定输入是 关 系 数 据 关系数据 关系数据,每个数据对象通常都有大量的文本信息,用多个属性来描述。因此,许多已知的相似度或距离函数(例如,名称的 Jaro-Winkler 距离和日期之间的数字距离)用于量化两个对象之间的相似度。基于此,基于规则或基于机器学习的方法能够解决将两个对象分类为匹配或不匹配的问题[9]。
更具体地说,对于主流的 ER 解决方案,为了匹配实体记录,首先手动或自动对齐属性,然后计算相应属性值之间的相似度,最后汇总对齐属性之间的相似度得分以得出记录之间的相似度 [32]、[45] 。
KG 实 体 消 解 实体消解 实体消解。一些 ER 方法旨在处理 KG 并专门处理二元关系,即图数据。这些方法也经常被称为实例/本体匹配方法[49]、[50]。图数据有其自身的挑战:(1)关于实体的文本描述信息通常较少存在,或者以实体名称的形式减少到最低限度,(2)KG 在开放世界假设下运作,其中实体的属性可能不存在于 KG 中,尽管它们在现实中存在。这将 KG 与经典数据库区分开来,后者通常假设记录的所有字段都存在,(3)KGs 有额外的预定义语义。在最简单的情况下,它们采用类别分类表(taxonomy of classes)的形式。在更复杂的情况下,KG 可以配备逻辑公理的本体。
在过去二十年里,特别是在语义网和关联开放数据云 [26] 兴起的背景下,已经开发了许多专门用于KG的方法。这些可以分为几个维度:
-
范 围 范围 范围。一些方法对齐两个 KG 的实体,其他方法对齐关系名(也称为模式),还有其他方法对齐两个 KG 的类别分类表。一些方法同时完成所有三个任务。在这项工作中,我们专注于这些任务中的第一个,即实体对齐。
-
背 景 知 识 背景知识 背景知识。一些方法使用本体(T-box)作为背景信息。对于参与本体对齐评价倡议 (Ontology Alignment Evaluation Initiative, OAEI) 的方法尤其如此。2 在这项工作中,我们专注于无需此类知识即可工作的方法。
-
训 练 训练 训练。 有些方法是无监督的,直接操作输入数据,不需要训练数据或训练阶段。 例如 PARIS [51] 和 SiGMa [35]。 另一方面,其他方法基于预定义的映射来学习实体之间的映射。 在这项工作中,我们专注于后一类方法。
在监督或半监督方法中,大多数基于深度学习的最新进展 [23]。他们主要依靠图表示学习技术来对 KG 结构进行建模并生成用于对齐的实体嵌入。我们用“实体对齐(EA)方法”来指这些方法,它们也是本研究的重点。尽管如此,我们在比较中包括了PARIS [51],作为无监督方法的代表系统。我们还将 AgreementMakerLight ( AML ) [17] 作为使用背景知识的代表性无监督系统。对于其他系统,我们建议读者参考其他综述 [9]、[33]、[41]、[43]。
此外,由于 EA 追求与 ER 相同的目标,因此可以将其视为 ER 的一个特殊但非平凡的例子。有鉴于此,一般的 ER 方法可以适用于EA 问题,我们将有代表性的 ER 方法包含进来进行比较(将在第 4 节中详细说明)。
现 有 基 准 现有基准 现有基准。为了评价 EA 方法的有效性,使用 DBpedia 中现有的跨语言和参考链接构建了几个合成数据集(例如, DBP15K和DWY100K )。这些数据集的更详细统计数据可以在第 4.2 节中找到。
值得注意的是,本体对齐评价倡议(OAEI)促进了知识图谱的发展。3与仅提供实例级信息的现有 EA 基准相比,这些数据集中的 KG 同时包含模式和实例信息,这对于评价当前假定本体信息不可用的 EA 方法不公平。因此,本文不介绍这类方法。
3 通用EA框架
本节,我们将介绍一个通用 EA 框架,该框架旨在包含最先进的 EA 方法。
通过仔细检查当前 EA 解决方案的框架,我们确定了以下四个主要组件(如图 2 所示):
- 嵌 入 学 习 模 块 嵌入学习模块 嵌入学习模块。该组件旨在学习实体的嵌入,大致可分为两类:基于KG 表示的模型,例如,TransE [4] 和基于图神经网络 (GNN) 的模型,例如,图卷积网络 (GCN) [31]。
- 对 齐 模 块 对齐模块 对齐模块。该组件旨将(上一个模块中学到的)不同 KG 中的实体嵌入映射到一个统一的空间中。大多数方法使用基于边界(margin)的损失来强制来自不同 KG 的种子实体嵌入接近。另一个经常使用的方法是语料库融合,它在语料库级别对齐 KG,并将不同 KG 中的实体直接嵌入到同一向量空间中。
- 预 测 模 块 预测模块 预测模块。给定统一的嵌入空间,对于测试集中的每个源实体,预测最有可能的目标实体。常见的策略包括使用余弦相似度、曼哈顿距离或实体嵌入间的欧几里得距离来代表实体之间的距离(相似度),然后选择距离最小(相似度最高)的目标实体作为对应实体。
- 额 外 信 息 模 块 额外信息模块 额外信息模块。在基本模块之上,一些解决方案建议利用额外信息来增强 EA 性能。一种常见的做法是引导(bootstrapping,或自学习)策略,它利用预测模块生成的可信对齐结果作为后续对齐迭代的训练数据(图 2 中的黑色虚线)。此外,其他人建议利用多类型文字信息,例如属性、实体描述和实体名称,来补充 KG 结构(蓝色虚线)。

图 2. 通用 EA 框架。
例 2。在例 1 的基础上,我们将解释这些模块。 嵌 入 学 习 模 块 嵌入学习模块 嵌入学习模块分别为 KG EN _\text{EN} EN和 KG ES _\text{ES} ES中的实体生成嵌入。然后 对 齐 模 块 对齐模块 对齐模块将实体嵌入投影到相同的向量空间中,这样KG EN _\text{EN} EN和 KG ES _\text{ES } ES 中的实体嵌入可以直接比较。最后,利用统一的嵌入, 预 测 模 块 预测模块 预测模块为KG EN _\text{EN} EN 中的每个源实体预测 KG ES _\text{ES} ES中的等价目标实体。 额 外 信 息 模 块 额外信息模块 额外信息模块利用多种技术来提高 EA 性能。具体来说,引导策略旨在将从上一轮检测到的可信 EA 对,例如,KaTeX parse error: Expected '}', got 'EOF' at end of input: \text{(\text{Spain}KaTeX parse error: Expected 'EOF', got '}' at position 7: , Espa}̲\tilde {\text{n… 包含到训练集中,以用于下一轮学习。另一种方法是使用额外的文本信息来补充实体嵌入以进行对齐。
为了提供模块级的比较,我们在每个模块的介绍下组织最先进的方法(表 1)。在这种情况下,我们建议感兴趣的读者参考附录 B4中简明而完整的视图。接下来,我们介绍了这些模块是如何通过不同的最先进的方法实现的。
表1 本研究中涉及的 EA 方法总结
1 C-L代表跨语言评价,M-L代表单语言评价。
2 TransE ∗ ^* ∗表示TransE模型的变体。
3.1 嵌入学习模块
在本小节中,我们将详细介绍用于嵌入学习模块的方法,该模块利用 KG 结构为每个实体生成嵌入。
从表 1 可以看出,TransE [4] 和 GCN [31] 是主流模型。在这里,我们提供这些基本模型的简要说明。
TransE。TransE将关系解释为对实体的低维表示间的平移(translation)操作。更具体地说,给定一个关系三元组( h , r , t h, r, t h,r,t ),TransE建议尾实体的嵌入应该接近头实体 h h h的嵌入加上关系 r r r的嵌入,即 h ⃗ + r ⃗ ≈ t ⃗ \vec h+\vec r \approx \vec t h+r≈t。因此,实体的结构信息得以保留,并且共享相似邻居的实体将在嵌入空间中具有近似的表示。
GCN。图卷积网络(GCN)是一种直接对图结构数据进行操作的卷积网络。它通过对节点邻域信息进行编码来生成节点级嵌入。GCN的输入包括 KG 中每个节点的特征向量,以及矩阵形式的图结构的代表性描述,即邻接矩阵。输出是一个新的特征矩阵。GCN 模型通常包含多个堆叠的 GCN 层,因此它可以捕获距离实体多跳的部分KG 结构。
在这些基本模型之上,一些方法进行了修改。对于基于TransE的模型,MTransE在训练过程中去除了负三元组,BootEA和NAEA用基于限制的目标函数替换了原始的基于边界的损失函数,MuGNN使用logistic损失代替基于边界的损失,JAPE设计了一个新的损失函数。
对于基于 GCN 的模型,注意到 GCN 忽略了 KG 中的关系,RDGCN采用双原始图卷积神经网络(dual-primal graph convolutional neural network, DPGCNN)[40] 作为补救。另一方面, MuGNN利用基于注意力的 GNN 模型为不同的相邻节点分配不同的权重。KECG结合了图注意力网络 (GAT) [58] 和TransE来捕获图内结构和图间对齐信息。
还有一些方法设计了新的嵌入模型。RSNs认为三元组级的学习不能捕捉实体的长距离关系依赖,并且不足以在实体之间传播语义信息。因此,它使用带有残差学习的循环神经网络 (RNN) 来学习实体之间的长距离关系路径。在TransEdge中,设计了一种新的能量函数来度量实体嵌入间的边平移误差,用于学习 KG 嵌入,其中边嵌入通过上下文压缩和投影来建模。
3.2 对齐模块
在本小节中,我们介绍用于对齐模块的方法,该模块旨在统一的不同KG各自的嵌入。
最常见的策略是在嵌入学习模块之上添加基于边界(margin)的损失函数。基于边界的损失函数要求 正 对 正对 正对实体间的距离应该很小, 负 对 负对 负对实体间的距离应该很大,并且正对间距离和负对间距离之间应该存在一个边界。这里 正 对 正对 正对表示种子实体对,而 负 对 负对 负对是通过破坏正对来构造的。这样,两个KG各自的嵌入空间可以被放入一个向量空间。表 1 表明,大多数基于 GNN 的方法都采用这种基于边界的对齐模型来统一两个 KG 嵌入空间,而在GM-Align中,对齐过程是通过一个最大化种子实体对的匹配概率的匹配框架来实现的。
另一种常用的方法是语料库融合,它利用种子实体对来连接两个 KG 的训练语料库。给定两个 KG 的三元组,一些方法(例如BootEA和NAEA)交换种子实体对中的实体并生成新的三元组以将嵌入校准到统一空间中。其他方法将种子实体对中的实体视为同一实体,并构建连接两个 KG 的覆盖(overlay)图,然后将其用于学习实体嵌入。
一些早期的研究设计了转换函数来将一个 KG 中的嵌入向量映射到另一个,另一些使用附加信息,例如实体的属性,将实体嵌入转移到相同的向量空间中。
3.3 预测模块
给定统一的嵌入空间,该模块旨在为每个源实体确定最可能的目标实体。
最常见的方法是根据实体嵌入之间的特定距离度量返回每个源实体的目标实体的排名列表,其中排名最高的实体被视为匹配项。常用的距离度量包括欧几里得距离、曼哈顿距离和余弦相似度。请注意,可以通过1减实体之间的相似度得分轻松得到距离得分,反之亦然。5在GM-Align中,匹配概率最高的目标实体与源实体对齐。
此外,最近的一种方法CEA指出,不同的 EA 决策之间通常存在额外的相互依赖关系,即,如果目标实体与具有更高置信度的另一个源实体对齐,则目标实体与当前源实体匹配的可能性较小。为了对这样的集体信号进行建模,它将这个过程表述为建立在距离度量基础上的稳定匹配问题,从而减少了不匹配并提高了准确性。
3.4 额外信息模块
虽然嵌入学习、对齐和预测模块已经可以构成一个基本的 EA 框架,但仍有改进的余地。在本小节中,我们介绍了额外信息模块中使用的方法。
一种常见的方法是引导策略(通常也称为迭代训练或自学习策略),它迭代地将可能的 EA 对标记为下一轮的训练集,从而逐步改进对齐结果。已经设计了几种方法,主要区别在于选择置信 EA 对。ITransE采用基于阈值的策略,而BootEA、NAEA和TransEdge将选择表示为一一映射约束下的最大似然匹配过程。
一些方法使用多类型文字信息来提供更全面的对齐视图。与实体相关的属性经常被使用。虽然有些仅使用属性名称的统计特征(例如,JAPE、GCN-Align和HMAN),但其他方法通过编码属性值的字符(例如,AttrE和MultiKE)来生成属性嵌入。
越来越倾向于使用“实体名称”。6 GM-Align、RDGCN和HGCN使用实体名称作为学习实体嵌入的输入特征,而CEA则利用实体名称的语义和字符串级两方面作为单独的特征。此外,KDCoE和HMAN的描述增强版本将实体描述编码为向量表示,这被认为是对齐的新特征。
值得注意的是,多类型信息并不总是可用的。此外,由于 EA 强调使用图结构进行对齐,大多数现有的 EA 数据集包含非常有限的文本信息,这限制了KDCoE、MultiKE和AttrE等一些方法的适用性。
4 实验和分析
本节介绍了深入的经验研究。7
4.1 分类
根据主要组成部分,我们可以将当前方法大致分为三组:第一组,仅利用 KG 结构进行对齐,第二组,利用迭代训练策略来改善对齐结果,第三组,利用除了 KG 结构之外的信息。我们使用例 1 介绍和比较这三个类别。
第 一 组 第一组 第一组。此类方法仅利用 KG 结构来对齐实体。再次考虑例 1。在 KG EN _\text{EN} EN中,实体 Alfonso Cuar o ˊ n \text{Alfonso Cuar}\acute{\text o}\text n Alfonso Cuaroˊn与实体 Mexico \verb+Mexico+ Mexico等三个实体相连,而KaTeX parse error: Expected '}', got 'EOF' at end of input: \text{\text{Spain}KaTeX parse error: Expected 'EOF', got '}' at position 1: }̲连接到 Mexico \verb+Mexico+ Mexico和另外一个实体。在 KG ES _\text{ES} ES中可以观察到相同的结构信息。由于我们已经知道KG EN _\text{EN} EN中的 Mexico \verb+Mexico+ Mexico与 KG ES _\text{ES} ES中的 Mexico \verb+Mexico+ Mexico对齐,因此利用KG 结构,很容易得出结论:KaTeX parse error: Expected '}', got 'EOF' at end of input: \text{\text{Spain}KaTeX parse error: Expected 'EOF', got '}' at position 1: }̲的等价目标实体是 Espan a ~ \text{Espan}\tilde{\text{a}} Espana~ , Alfonso Cuar o ˊ n \text{Alfonso Cuar}\acute{\text o}\text n Alfonso Cuaroˊn的等价目标实体是 Alfonso Cuar o ˊ n \text{Alfonso Cuar}\acute{\text o}\text n Alfonso Cuaroˊn 。
第 二 组 第二组 第二组。此类别中的方法迭代地将可能的 EA 对标记为下一轮的训练集,并逐步改进对齐结果。他们也可以分入第一组或第三组,这取决于他们是否仅使用 KG 结构。然而,它们都以使用引导策略为特征。
我们仍然使用例 1 来说明引导机制。如图1所示,使用KG结构,很容易发现源实体 Spain \text{Spain} Spain对应目标实体 Espan a ~ \text{Espan}\tilde{\text{a}} Espana~, Alfonso Cuar o ˊ n \text{Alfonso Cuar}\acute{\text o}\text n Alfonso Cuaroˊn对应 Alfonso Cuar o ˊ n \text{Alfonso Cuar}\acute{\text o}\text n Alfonso Cuaroˊn。尽管如此,对于源实体 Madrid \text{Madrid} Madrid,其目标实体仍不清楚,因为目标实体 Roma(ciudad) \text{Roma(ciudad)} Roma(ciudad)和 Madrid \text{Madrid} Madrid都具有与源实体 Madrid \text{Madrid} Madrid相同的结构信息——距离种子实体两跳,度数为 1。为了解决这个问题,基于引导的方法进行了几轮对齐,其中从上一轮检测到的置信对被视为下一轮的种子实体对。更具体地说,他们将在第一轮中检测到的实体对,即 ( Spain \text{Spain} Spain, Espan a ~ \text{Espan}\tilde{\text{a}} Espana~ ) 和 ( Alfonso Cuar o ˊ n \text{Alfonso Cuar}\acute{\text o}\text n Alfonso Cuaroˊn, Alfonso Cuar o ˊ n \text{Alfonso Cuar}\acute{\text o}\text n Alfonso Cuaroˊn ) 视为下一轮中的种子对。因此,在第二轮中,对于源实体 Madrid \text{Madrid} Madrid,只有目标实体 Madrid \text{Madrid} Madrid与它共享相同的结构信息——距离种子实体对( Mexico \verb+Mexico+ Mexico, Mexico \verb+Mexico+ Mexico)两跳,距离种子实体对(KaTeX parse error: Expected '}', got 'EOF' at end of input: \text{\text{Spain}KaTeX parse error: Expected 'EOF', got '}' at position 1: }̲, Espan a ~ \text{Espan}\tilde{\text{a}} Espana~)一跳。
第 三 组 第三组 第三组。尽管使用 KG 结构来对齐给定图格式的输入数据源是直观的,KGs 还包含丰富的语义,可用于补充结构信息。该类别中的方法还通过使用除KG结构之外的信息来区分自己。
参考例 1,在使用 KG 结构甚至引导策略后,仍然难以确定源实体 Gravity(film) \verb+Gravity(film)+ Gravity(film)的目标实体,因为两个目标实体 Gravity(pel 1 ˊ cula) \text{Gravity(pel}\acute{\text 1}\text{cula)} Gravity(pel1ˊcula)和 Roma(pel 1 ˊ cula) \text{Roma(pel}\acute{\text 1}\text{cula)} Roma(pel1ˊcula)具有相同的结构信息(连接到实体 Alfonso Cuar o ˊ n \text{Alfonso Cuar}\acute{\text o}\text n Alfonso Cuaroˊn以及度为 2) 。在这种情况下,使用标识符中的名称来补充 KG 结构可以轻松区分这两个实体并返回 Gravity(pel 1 ˊ cula) \text{Gravity(pel}\acute{\text 1}\text{cula)} Gravity(pel1ˊcula)作为源实体 Gravity(film) \verb+Gravity(film)+ Gravity(film)的目标实体。
4.2 实验设置
数 据 集 数据集 数据集。我们采用三个常用且具有代表性的数据集,包括九个 KG 用于评价:
DBP15K [53]。该数据集由从 DBpedia 提取的三个多语言 KG 对组成:英文到中文 ( DBP15K ZH-EN _\text{ZH-EN} ZH-EN )、英文到日文 ( DBP15K JA-EN _\text{JA-EN} JA-EN ) 和英文到法语 ( DBP15K FR-EN _\text{FR-EN} FR-EN )。每个KG对包含15,000个跨语言链接作为黄金标准。
DWY100K [54]。该数据集包含两个单语 KG 对,DWY100K DBP-WD _\text{ DBP-WD} DBP-WD和DWY100K DBP- YG _\text{ DBP- YG} DBP- YG ,它们是从 DBpedia、Wikidata 和 YAGO 3 中提取的。每个 KG 对包含 100,000 个实体对。提取过程和DBP15K一样,只是语言间链接替换为KG间链接。
SRPRS。Guo等人[24]指出,以前的EA数据集中的KGs,例如DBP15K和DWY100K,过于稠密,并且度数分布与现实生活中的KGs有偏差。因此,他们通过使用DBpedia中的参考链接建立了一个遵循真实分布的新EA基准。最终评价基准包括跨语言(SRPRS EN-FR _\text{EN-FR} EN-FR、SRPRS EN-DE _\text{EN-DE} EN-DE)和单语 KG 对 ( SRPRS DBP-WD _\text{ DBP-WD} DBP-WD、SRPRS DBP-YG _\text{ DBP-YG} DBP-YG ),其中EN、FR、DE、DBP、WD和YG分别代表DBpedia(英文)、DBpedia(法文)、DBpedia(德语)、DBpedia、Wikidata 和 YAGO3。每个 KG 对包含 15,000 个实体对。
数据集的摘要可以在表 2 中找到。在每个 KG 对中,有关系三元组、跨 KG 实体对(黄金标准,其中 30% 是种子实体对并用于训练)和属性三元组。
表 2 EA 基准和我们构建的数据集的统计
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-omaqRBio-1654052649313)(https://docimg7.docs.qq.com/image/mPgUcOA2exLKiEX5S6J9Vw.png?w=535&h=600)]
度 分 布 度分布 度分布。为了深入了解数据集,我们在图 3 中显示了这些数据集中实体的度数分布。实体的度数定义为实体所涉及的三元组的数量。度数越高意味着相邻结构越丰富。在每个数据集中,由于不同的 KG 对非常相似,出于空间的考虑,我们仅在图 3 中展示了一个 KG 对的分布。 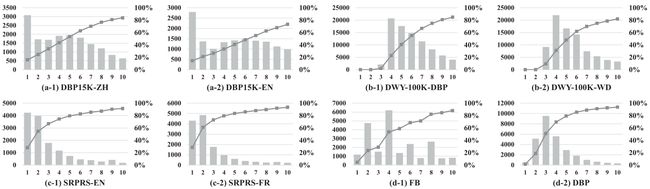
图 3. 不同数据集上的度数分布。X轴表示实体的度。左边的 Y 轴代表实体的数量(对应于条形图),而右边的 Y 轴代表度数低于给定 x x x值的实体的百分比(对应于线)。
(a) 系列子图对应于DBP15K。可以看出,度数为1的实体占比最大,随着度数的增加,实体数波动,但总体呈下降趋势。值得注意的是,覆盖曲线近似于一条直线,因为当度数从 2 增加到 10 时,实体数量的变化很小。
(b) 系列子图对应于DWY100K。该数据集中的 KG 结构与 (a) 非常不同,因为没有度数为 1 或 2 的实体。此外,实体数在度数 4 时达到峰值,并且随着实体度数的增加而持续下降。
© 系列子图对应于SRPRS。显然,该数据集中实体的度数分布更真实,其中度数较低的实体占较高的百分比。这可以归因于其精心设计的采样策略。请注意,(d)系列子图对应于我们构建的数据集,将在第 5 节中介绍。
评 价 指 标 评价指标 评价指标。按照现有的 EA 解决方案,我们使用 Hits@ k k k ( k k k =1, 10) 和排名倒数均值 (mean reciprocal rank, MRR) 作为评价指标。在预测阶段,对于每个源实体,目标实体根据它们与源实体的距离得分以升序排列。Hits@ k k k反映了前 k k k个最接近的目标实体中包含正确对齐的实体的百分比。特别是Hits@1代表了对齐结果的准确性,这是最重要的指标。
MRR 表示基本事实排名的倒数的平均值。请注意,较高的 Hits@ k k k和 MRR 表示更好的性能。除非另有说明,否则 Hits@ k k k的结果以百分比表示。
比 较 的 方 法 比较的方法 比较的方法。我们的比较包括了上述方法,除了KDCoE和MultiKE,因为评价基准不包含实体描述。我们还排除了 AttrE,因为它仅适用于单语设置。此外,我们报告了JAPE和GCN-Align的仅结构变体的结果,即JAPE-Stru和GCN。
如第 2.2 节所述,为了展示 ER 方法应对 EA 的能力,我们还与几种基于名称的启发式方法进行了比较,因为这些相关任务 [13]、[42]、[47] 的典型方法严重依赖对象名称之间的相似性来发现等价性。具体来说,我们使用: (1) Lev ,它使用 L e v e n s h t e i n 距 离 Levenshtein 距离 Levenshtein距离[37]对齐实体,这是一种用于测量两个序列之间差异的字符串度量, (2) Embed,它根据两个实体的名称嵌入(平均词嵌入)之间的余弦相似度来对齐实体。按照[65],我们使用预训练的fastText嵌入 [2] 作为词嵌入,对于多语言 KG 对,我们使用 MUSE 词嵌入 [10]。
实 现 细 节 实现细节 实现细节。实验在配备 Intel Core i7-4790 CPU、NVIDIA GeForce GTX TITAN X GPU 和 128 GB 内存的PC上进行。所有程序都是用 Python 实现的。
我们直接使用作者提供的源代码进行复现,并通过使用他们原始论文中报告的参数集执行模型获得结果。8我们在原始论文中未包含的数据集上使用相同的参数集。
在DBP15K数据集上,除了MTransE和ITransE之外,所有评价的方法都在其原始论文中提供了结果。我们将我们实现的结果与他们报告的结果进行比较。如果差异超出合理范围,即超过原始结果的$\pm 5 5%,我们用 5 标 记 该 方 法 。 请 注 意 , 理 论 上 不 应 该 有 很 大 的 差 异 , 因 为 我 们 使 用 相 同 的 源 代 码 和 相 同 的 实 现 参 数 。 在 S R P R S 上 , 只 有 R S N 在 其 原 始 论 文 [ 24 ] 中 报 告 了 结 果 。 我 们 在 S R P R S 上 运 行 所 有 方 法 , 并 在 表 4 中 提 供 结 果 。 在 D W Y 100 K 上 , 我 们 运 行 所 有 方 法 , 并 将 B o o t E A 、 M u G N N 、 N A E A 、 K E C G 和 T r a n s E d g e 的 性 能 与 其 原 始 论 文 中 提 供 的 结 果 进 行 比 较 。 具 有 显 著 差 异 的 方 法 用 标记该方法。请注意,理论上不应该有很大的差异,因为我们使用相同的源代码和相同的实现参数。在SRPRS 上,只有RSN在其原始论文 [24] 中报告了结果。我们在SRPRS上运行所有方法,并在表 4 中提供结果。在DWY100K 上,我们运行所有方法,并将BootEA、MuGNN、NAEA、KECG和TransEdge的性能与其原始论文中提供的结果进行比较。具有显著差异的方法用 标记该方法。请注意,理论上不应该有很大的差异,因为我们使用相同的源代码和相同的实现参数。在SRPRS上,只有RSN在其原始论文[24]中报告了结果。我们在SRPRS上运行所有方法,并在表4中提供结果。在DWY100K上,我们运行所有方法,并将BootEA、MuGNN、NAEA、KECG和TransEdge的性能与其原始论文中提供的结果进行比较。具有显著差异的方法用$标记。
在每个数据集上,每组内的最佳结果用粗体表示。我们用 ▲ ^\blacktriangle ▲标记所有方法中最佳的Hits@1性能,因为该指标最能反映 EA 方法的有效性。
4.3 DBP15K的结果和分析
跨语言数据集DBP15K的实验结果如表 3 所示。CEA的 Hits@10 和 MRR 结果缺失,因为它直接生成对齐的实体对,而不是返回排名实体的列表。9然后,我们比较每个类别和不同类别的表现。
表3 DBP15K的实验结果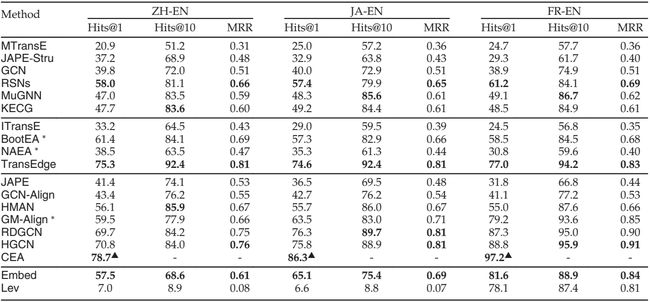
第 一 组 第一组 第一组。在仅使用 KG 结构的方法中,RSN在 Hits@1 和 MRR 方面始终取得最佳结果,这可以归因于它捕获的长距离关系路径为对齐提供了更多的结构信号。MuGNN 和 KECG 的结果相当,部分原因是它们的共同目标是KG补全和调和结构差异。 MuGNN 利用 AMIE+ [19] 来导出补全规则,而 KECG 利用 TransE 来隐含地实现这一目标。
其他三种方法获得的结果相对较差。MTransE和JAPE-Stru都采用TransE来捕获 KG 结构,而JAPE-Stru优于MTransE,因为MTransE对不同向量空间中的 KG 结构进行建模,并且在向量空间之间进行转换时会发生信息丢失[53]。GCN获得了比MTransE和JAPE-Stru相对更好的结果。
第 二 组 第二组 第二组。在这一类别中,ITransE获得的结果比其他方法差得多,这可归因于嵌入空间之间的转换过程中的信息丢失及其更简单的引导策略(详见第 3.4 节)。BootEA、NAEA和TransEdge使用相同的引导策略。BootEA的性能略逊于报告的结果,而NAEA的结果则差很多。从理论上讲,NAEA应该比BootEA获得更好的性能,因为它利用注意力机制来获取邻居级别的信息。TransEdge采用以边为中心的嵌入模型来捕获结构信息,从而生成更精确的实体嵌入,从而获得更好的对齐结果。
第 三 组 第三组 第三组。JAPE和GCN-Align都利用属性来补充实体嵌入,并且它们的结果超过了它们的仅结构版本的结果,验证了属性信息的有用性。同样利用这些属性,HMAN优于JAPE和GCN-Align,因为它还将关系类型视为模型输入。
其他四种方法利用实体名称信息而不是属性来对齐,并获得更好的结果。其中,RDGCN和HGCN的结果接近,超过了GM-Align。这部分是因为他们使用关系来优化实体嵌入的学习,这在以前的基于 GNN 的 EA 模型中很大程度上被忽略了。CEA在该组中获得了最佳性能,因为它有效地利用和融合了可用的特征。
基 于 名 称 的 启 发 式 基于名称的启发式 基于名称的启发式。在密切相关语言的 KG 对上,Lev获得了很好的结果,而它在不太相关的语言对上效果不好,即DBP15K ZH-EN _\text{ZH-EN} ZH-EN和DBP15K JA-EN _\text{JA-EN} JA-EN。至于Embed,它在所有 KG 对上实现了一致的性能。
类 别 内 比 较 类别内比较 类别内比较。CEA在所有数据集上实现了最佳 Hits@1 性能。至于其他指标,TransEdge、RDGCN和HGCN取得了领先的结果。这验证了使用额外信息(即引导策略和文本信息)的有效性。
基于名称的启发式的性能(即Embed ) 非常有竞争力,在Hits@1指标上超过了大部分不使用 实体名称信息的方法。这表明典型的 ER 解决方案仍然可以处理 EA 的任务。尽管如此,Embed仍然不如大多数包含实体名称信息的 EA 方法,即RDGCN、HGCN和CEA。
还可以观察到,前两组的方法,例如TransEdge,在所有三个 KG 对上都获得了一致的结果,而利用实体名称信息的解决方案,例如HGCN,在密切相关语言(FR-EN)KG 对上比不太相关语言(ZH-EN)KG对上的结果更好。这表明语言障碍会阻碍文本信息的使用,进而损害整体效果。
4.4 SRPRS的结果和分析
SRPRS的结果见表 4。有一些类似于DBP15K的观察结果,我们将不再详述。我们关注与DBP15K的差异,以及特定于该数据集的模式。
表 4 SRPRS上的实验结果 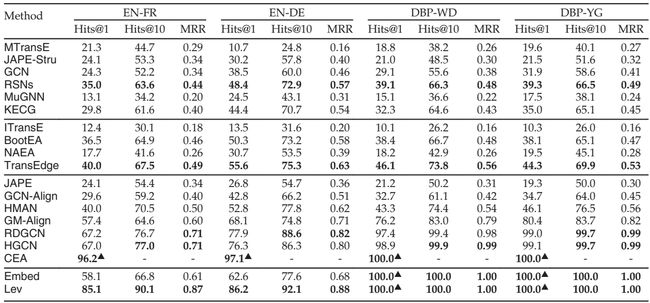
第 一 组 第一组 第一组。很明显,SRPRS 的整体性能低于DBP15K ,这表明这些方法在相对稀疏的 KG 上可能表现不佳。RSNs仍然优于其他方法, KECG紧随其后。值得注意的是,与 DBP15K 上的不错结果相比,MuGNN在SRPRS上的结果要差得多,因为在SRPRS上没有对齐的关系,规则迁移失效。此外,由于稀疏的 KG 结构,检测到的规则数量要少得多。
第 二 组 第二组 第二组。在这些解决方案中,TransEdge仍能产生始终如一的卓越结果。
第 三 组 第三组 第三组。与GCN和JAPE-Stru相比,结合属性可以为GCN-Align带来更好的结果,但对JAPE的性能没有贡献。这是因为这个数据集的属性个数比较少。相比之下,使用实体名称可以将结果提高到一个更高的水平。请注意,CEA在SRPRS DBP-WD _\text{DBP-WD} DBP-WD和SRPRS DBP-YG _\text{DBP-YG} DBP-YG上获得了100%的性能指标。
基 于 名 称 的 启 发 式 基于名称的启发式 基于名称的启发式。Lev和Embed在单语言 EA 数据集上实现了100%的性能指标,因为对于 DBpedia、Wikidata 和 YAGO,不同 KG 中的等价实体具有来自实体标识符的相同名称,并且这些名称的简单比较就可以实现100%的性能指标。Lev还在密切相关的语言对的跨语言 KG 对上取得了可喜的结果。
类 别 内 比 较 类别内比较 类别内比较。与DBP15K不同,包含实体名称(第三组)的方法在SRPRS上占主导地位。这是因为:(1)KG 结构在这个数据集上效果较差(与DBP15K相比要稀疏得多), (2)实体名称信息在单语言数据集和密切相关语言对的跨语言数据集上起着非常重要的作用,其中等价实体的名称非常相似。
4.5 DWY100K的结果与分析
大规模单语言数据集DWY100K的结果如表 5 所示。在我们的实验环境下,我们无法获得RDGCN和NAEA的结果,因为它们需要非常大的内存空间。
表 5 DWY100K和DBP-FB 的实验结果 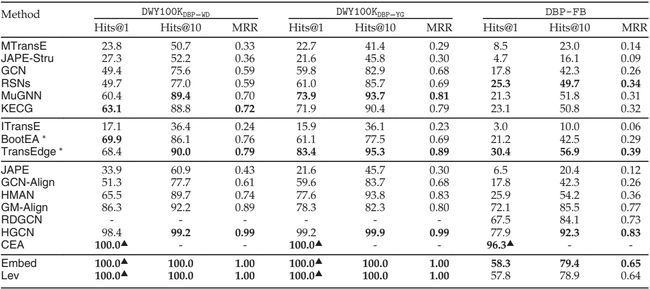
第一组的方法在这个数据集上取得了更不错的结果,这可以归因于相对更丰富的 KG 结构(如图 3 所示)。其中,MuGNN和KECG在DWY100K DBP-WD _\text{DBP-WD} DBP-WD和DWY100K DBP-YG _\text{DBP-YG} DBP-YG上的Hits@1都分别超过 60 和70,因为丰富的结构有利于KG补全的过程,这反过来又增强了整体 EA 性能。
在迭代训练策略的帮助下,第二组的方法进一步提高了结果,而BootEA和TransEdge的结果略低于他们报告的值。对于第三组中的方法,CEA实现了百分百的性能指标。与SRPRS类似,基于名称的启发式Lev和Embed也获得了百分百的结果。
4.6 效率分析
为了评价的全面性,我们在表 6 中报告了每个数据集的平均运行时间,以比较最先进的解决方案的效率,这也可以反映它们的 可 扩 展 性 可扩展性 可扩展性。我们知道不同的参数设置,例如学习率和 epoch 的数量,可能会影响最终的时间成本。然而,在这里,我们的目标只是通过采用它们原始论文中报告的参数来提供这些方法效率的总体图景。同样,我们未能在我们的实验环境中获得RDGCN和NAEAD在WY100K上的结果,因为它们需要非常大的内存空间。
表 6 每个数据集的平均时间成本(以秒为单位) 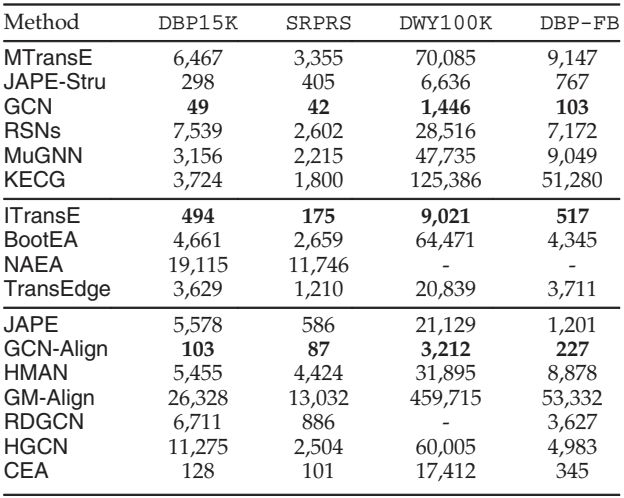
在DBP15K和SRPRS 上,GCN是最有效率的方法,具有一致的对齐性能,紧随其后的是JAPE-Stru和ITransE。对于其他方法,它们中的大多数具有相同数量级的时间成本(1,000-10,000 秒),但NAEA和GM-Align除外,它们需要极高的运行时间。
在更大的数据集DWY100K上,由于更多的参数和更高的计算成本,所有解决方案的时间成本都急剧攀升。其中,由于内存限制, MuGNN、KECG、HMAN无法使用 GPU 工作,我们按照这些方法的作者的建议报告了使用 CPU 的时间成本。需要注意的是,只有三种方法可以在 10,000s 内完成对齐过程,大多数方法的时间成本在 10,000s 和 100,000s 之间。GM-Align甚至需要 5 天才能生成结果。这揭示了最先进的 EA 方法在处理非常大规模的数据时仍然效率低下。其中一些,例如NAEA、RDGCN和GM-Align的可扩展性相当差。
4.7 与无监督方法的比较
如第 2.2 节所述,有许多无监督方法设计用于 KG 之间的对齐,它们不使用表示学习技术。为了研究的全面性,我们与一个具有代表性的系统PARIS [51] 进行了比较。基于文字之间的相似性比较,PARIS使用概率算法以无监督的方式联合对齐实体。此外,我们还与 AgreementMakerLight ( AML ) [17] 进行了比较,这是一种利用 KGs 背景知识的无监督本体对齐系统。10
因为PARIS和AML不会为每个源实体输出一个目标实体,我们使用 F1 分数作为评价指标,以便处理在另一个 KG 中没有匹配的实体。F1 分数是精度(即正确对齐的实体对的数量除以方法返回目标实体的源实体的数量)和召回率(即方法返回目标实体的源实体的数量除以源实体的总数)之间的调和平均值。
如图 4 所示,PARIS和AML的整体表现略逊于CEA。然而,尽管CEA具有更强大的性能,但它依赖于训练数据(种子实体对),这在现实世界的 KG 中可能不存在。相比之下,无监督系统不需要任何训练数据即可工作,并且仍然可以输出非常不错的 结果。此外,通过比较PARIS和AML的结果,表明本体信息确实提高了对齐结果。
图 4. EA 数据集上 PARIS、AML 和 CEA 的 F1 分数。 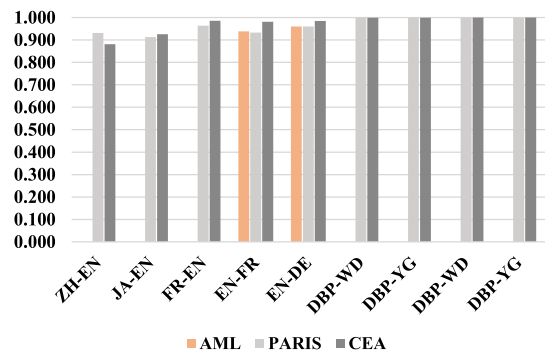
4.8 模块级评价
为了深入了解不同模块中使用的方法,我们进行了模块级评价并报告相应的实验结果。具体来说,我们从每个模块中选择具有代表性的方法,并生成可能的组合。通过比较不同组合的性能,我们可以更清楚地了解这些模块中不同方法的有效性。
关于嵌入学习模块,我们使用GCN和TransE。对于对齐模块,我们采用基于边界的损失函数(Mgn)和语料库融合策略(Cps)。按照目前的方法,我们将GCN与Mgn结合起来,将TransE与Cps结合起来,其中参数分别根据GCN-Align和JAPE进行调整。在预测模块中,我们使用欧几里得距离(Euc)、曼哈顿距离(Manh)和余弦相似度(Cos)。关于额外信息模块,我们通过实现[66]中的迭代方法将引导策略的使用表示为B。多类型信息的使用表示为Mul ,我们采用CEA中实体名称的语义和字符串级特征。
24 种组合的 Hits@1 结果显示在表 7中。11可以观察到,添加引导策略和/或文本信息确实提高了整体性能。关于嵌入模型,GCN + Mgn模型似乎比TransE + Cps更稳健且性能更优。此外,距离度量也会对结果产生影响。与Manh和Euc相比,Cos在基于TransE的模型上带来更好的性能,而在基于GCN的模型上带来更差的结果。然而,在结合实体名称嵌入后,使用Cos会带来始终如一的更好性能。
表 7 Hits@1 模块级评价结果 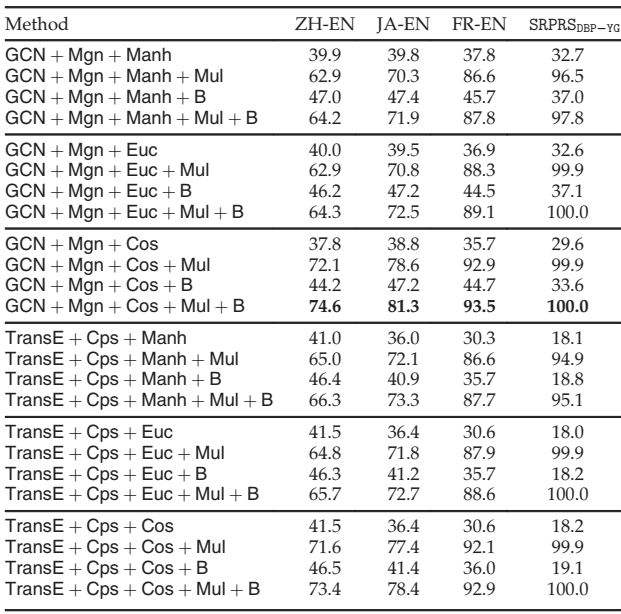
值得注意的是, GCN + Mgn + Cos + Mul + B (简称CombEA ) 实现了最佳性能,展示了现有模块中方法的简单组合可以带来不错的对齐性能。
4.9 总结
我们总结了实验结果的主要发现。
EA 与 ER。EA 与其他相关任务不同,因为它适用于图结构化数据。因此,所有现有的 EA 解决方案都使用 KG 结构来生成实体嵌入以用于对齐实体,这在DBP15K和DWY100K上取得不错的结果。然而,仅依赖 KG 结构有其局限性,因为存在具有非常有限结构信息的长尾实体,或者具有相似相邻实体但不指向相同现实世界对象的实体。作为一种补救措施,最近的一些研究建议结合文本信息,从而获得更好的性能。然而,这提出了一个关于 ER 方法是否可以处理 EA 任务的问题,因为与实体相关的文本经常被典型的 ER 解决方案使用。
我们通过与大多数典型 ER 方法中使用的基于名称的启发式方法进行比较来回答这个问题,实验结果表明:(1) ER 解决方案可以在 EA 上运行,而性能在很大程度上取决于两者之间的文本相似性实体, (2) 尽管 ER 解决方案可以胜过大多数基于结构的 EA 方法, 但 它 们 仍 然 逊 于 但它们仍然逊于 但它们仍然逊于使用名称信息来补充实体嵌入的 EA 方法, (3) 将 ER 中的主要思想,即依靠字面相似性来发现实体之间的等价性,融入 EA 方法,是一个值得探索的有前途的方向(正如CEA所证明的那样)。
数 据 集 的 影 响 数据集的影响 数据集的影响。如图 5 所示,EA 解决方案的性能在不同的数据集上差异很大。通常,EA 方法在稠密数据集上取得相对较好的结果,即在DBP15K和DWY100K上。此外,单语 KG 的结果优于跨语言 KG(DWY100K与DBP15K)。特别是在所有单语数据集上,性能最高的方法CEA以及基于名称的启发式Lev和Embed,达到 100% 的准确度。这是因为这些数据集是从 DBpedia、Wikidata 和 YAGO 中提取的,其中不同 KG 中的等价实体具有来自实体标识符的相同名称,并且这些名称的简单比较可以获得真实的结果。然而,这些数据集未能反映有歧义实体名称的现实挑战。为了填补这一空白,我们构建了一个新的单语基准,将在第 5 节中详细介绍。
图 5. 不同数据集上所有方法的 Hits@1 的箱线图。 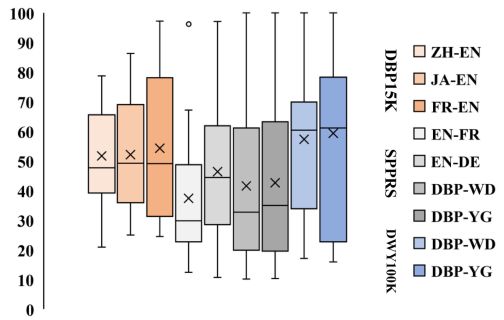
箱线图的绘制方法是:先找出一组数据的上边缘、下边缘、中位数和两个四分位数;然后, 连接两个四分位数画出箱体;再将上边缘和下边缘与箱体相连接,中位数在箱体中间。
4.10 指导方针和建议
在本小节中,我们为 EA 方法的潜在用户提供指南和建议。
从 业 者 指 南 从业者指南 从业者指南。有许多因素可能会影响 EA 模型的选择。我们选择四个最常见的因素并给出以下建议:
-
输 入 信 息 输入信息 输入信息。如果输入仅包含 KG 结构信息,则可能必须从第一组和第二组中的方法中进行选择。反之,如果存在丰富的辅助信息,人们可能希望使用第三组的方法来充分利用这些特征并提供更可靠的对齐信号。
-
数 据 规 模 数据规模 数据规模。如第 4.6 节所述,一些最先进的方法具有相当差的可扩展性。因此,在做出对齐决策之前应考虑数据的规模。对于非常大规模的数据,可以使用一些简单但高效的模型,例如GCN-Align来减少计算开销。
-
对 齐 的 目 标 对齐的目标 对齐的目标。如果只关注实体的对齐,可能会想采用基于GNN的模型,因为它们通常更健壮和可扩展。然而,如果有额外的任务,例如关系对齐,可能需要使用基于 KG 表示的方法,因为它们本质上同时学习实体和关系表示。此外,最近的几项研究 [55]、[60] 表明关系可以帮助实体对齐。
-
引 导 的 权 衡 引导的权衡 引导的权衡。引导过程是有效的,因为它可以逐步增加训练集并导致越来越好的对齐结果。然而,它存在错误传播问题,这可能会引入错误匹配的实体对,并在接下来的轮次中放大它们对对齐的负面影响。此外,它可能很耗时。因此,在决定是否使用引导策略时,可以估计数据集的难度。如果数据集相对简单,例如,具有丰富的文字信息和稠密的KG结构,利用引导策略可能是更好的选择。否则,在使用这种策略时应该小心。
对 未 来 研 究 的 建 议 对未来研究的建议 对未来研究的建议。我们还讨论了一些未来值得探索的开放性问题:
-
长 尾 实 体 长尾实体 长尾实体EA。在现实生活中的 KG 中,只有少数实体与其他实体紧密连接,其余大多数实体具有相当稀疏的邻域结构。这些长尾实体的对齐对整体对齐性能至关重要,然而,当前的 EA 文献在很大程度上忽略了这一点。最近的一项研究[66]利用额外信息来补充结构信息以对齐尾实体。它还建议通过集成到迭代自训练过程中的 KG 补全来增加关系结构以减少长尾实体。尽管如此,仍有很大的改进空间。
-
多 模 态 多模态 多模态EA。一个实体可以与多种形式的信息相关联,例如文本、图片,甚至视频。为了对齐这些实体,多模态实体对齐的任务值得进一步研究[39]。
-
开 放 世 界 开放世界 开放世界EA。当前的 EA 解决方案在封闭域设置下工作 [27],也就是说,他们假设源 KG 中的每个实体在目标 KG 中都有一个等价的实体。然而,在实际环境中,总是存在无法匹配的实体。此外,大多数最先进的方法所需的标记数据可能不可用。因此,在开放世界环境中探索 EA 具有重要意义。
5 新数据集和进一步实验
正如第 4 节中强调的那样,在现有的单语言数据集中,不同 KG 中的等价实体具有来自实体标识符的相同名称。这意味着这些名称的简单比较可以达到相当准确结果( SRPRS DBP-YG _\text{DBP-YG} DBP-YG的 100% 精度)。然而,在现实生活中的 KG 中,实体标识符通常不是人类可读的。例如,Freebase 通过/m/05qtj标识巴黎(法国首都) ,Wikidata 也有类似的策略。然后将这些标识符链接到一个或多个人类可读的名称。例如,/m/05qtj链接到“Paris”、“The City of Light”等。碰巧,只需从 KG 中检索这些名称,并匹配相同名字的实体,即可在DWY100K DBP-WD _\text{ DBP-WD} DBP-WD和SRPRS DBP-WD _\text{ DBP-WD} DBP-WD等数据集上实现100% 的精度。然而,在现实生活中的 KG 中,这种方法是行不通的。原因是不同的实体(具有不同的标识符)可以具有相同的名称。例如,Freebase 实体/m/ 05qtj(法国首都)和/m/0h0_x(特洛伊国王)都使用“Paris”这个名称——美国有 20 个城市被称为“Paris”。这显然给 EA 带来了问题,因为无法保证源 KG 中名称为“Paris”的实体与目标 KG 中名称为“Paris”的实体相同——仅仅是因为一个可能是法国的城市,另一个是特洛伊国王。这是现实 KG 中的一个重要难题:例如,在 YAGO 3 中,34% 的实体名称由多个实体共享。这个问题在 EA 常用的单语数据集中反映不足。
EA 数据集还有第二个问题:对于源 KG 中的每个实体,在目标 KG 中包含一个对应实体。因此,EA 方法可以将源 KG 中的每个实体映射到目标 KG 中最相似的实体。然而,这是一个不切实际的情景。在现实生活中,KG 包含其他 KG 不包含的实体。例如,当尝试对齐 YAGO 3 和 DBpedia 时,会遇到出现在 YAGO 3 中而不是 DBpedia 中的实体,反之亦然。对于不同来源(例如 YAGO 4 和 IMDB)的 KG,这个问题更加明显。YAGO 4 中只有 1% 的实体是电影或与电影相关的实体(例如演员)。YAGO 4 中其他 99% 的实体(如大学、智能手机品牌等)在 IMDB 中必然没有匹配项。当前的 EA 数据集中根本没有考虑这个问题。
因此,我们观察到 EA 的现有数据集是对现实问题的过度简化。作为补救措施,我们提出了一个反映这些困难的新数据集。我们希望这个数据集能够产生更好的 EA 模型,以处理更具挑战性的问题实例,并为研究界提供更好的方向。本节介绍新数据集的构建和我们在其上的实验结果。
5.1 数据集构建
为了反映使用实体名称的难度,我们采用 Freebase [3] 作为目标 KG,因为它表示具有不可理解的标识符(即 Freebase MID)的实体,并且不同的实体可能共享相同的名称。DBpedia 用作源 KG,因为它包含指向 Freebase 的外部链接,可以直接用作黄金标准。具体构建过程详述如下:
确 定 源 实 体 集 确定源实体集 确定源实体集。我们利用 DBpedia 中的消歧记录,收集共享相同消歧术语的实体来构成源 KG 的实体集。例如,对于歧义词Apple,消歧记录涉及Apple Inc.和Apple(fruit)等实体,这些实体都包含在源实体集中。
确 定 链 接 和 目 标 实 体 集 确定链接和目标实体集 确定链接和目标实体集。然后我们使用 DBpedia 和 Freebase 之间的外部链接来检索 Freebase 中与源实体对应的实体,这些实体构成了目标 KG 的实体集。这些外部链接被视为黄金标准。请注意,目标 KG 中的实体由 Freebase MID 标识,并且多个实体可能共享相同的名称,例如Apple。我们使用标签三元组来检索每个实体的名称。
检 索 三 元 组 检索三元组 检索三元组。在确定源 KG 和目标 KG 中的实体集后,我们从各自的 KG 中挖掘涉及这些实体的关系和属性三元组。
精 炼 链 接 和 实 体 集 精炼链接和实体集 精炼链接和实体集。根据之前的工作 [53]、[54],我们保留这样的链接:其源实体和目标实体在各自的 KG 中涉及至少一个三元组,这将链接数量减少到 25,542 个。实体集进行了相应的调整,其中还包括了参与三元组但不参与链接的实体。最终,源 KG 中有 29,861 个实体,其中 4,319 个不匹配,目标 KG 中有 25,542 个可匹配实体。在现有数据集之后,30% 的链接和不匹配的实体被用作训练集。数据集的其他统计数据如表 2 所示。
5.2 DBP-FB实验结果
按照当前的评价范式,我们首先讨论不包含未匹配实体的 EA 性能。表 5 显示,前两组方法的整体性能比SRPRS差,这可归因于DBP-FB更高的结构异质性。这也可以从图 3 中的子图 (d) 中观察到——与 (a)、(b) 或 © 中的 KG 对不同,这些 KG 中的实体分布非常不同,这给利用结构信息带来困难。
利用实体名称的方法仍然产生最好的结果,而与以前的单语数据集的结果相比,性能都下降了。此外,在DBP-FB上,Embed和Lev仅分别达到了 58.3% 和57.8 %的Hits@1 值,而在SRPRS DBP-YG _\text{DBP-YG} DBP-YG 、 SRPRS DBP-WD _\text{DBP-WD} DBP-WD 、DWY100K DBP-YG _\text{DBP-YG} DBP-YG和DWY100K DBP-WD _\text{DBP-WD} DBP-WD上这些数字全部是100%。这验证了,与现有的数据集相比,DBP-FB能够更好地反映实体名称歧义的挑战。因此,DBP-FB可以被认为是更可取的单语数据集。
5.3 未匹配的实体
DBP-FB还包括无法匹配的实体,这是 EA 面临的另一个现实挑战。我们考虑了这些不匹配的实体,并报告了CombEA(来自第 4.8 节)在DBP-FB上的性能。在第 4.7 节之后,我们采用 精 度 精度 精度、 召 回 率 召回率 召回率和F1分数作为评价指标,除了我们将 召 回 率 召回率 召回率定义为方法返回目标实体的可匹配源实体的数量除以可匹配源实体的总数.
表 8 显示,CombEA具有非常高的召回率,但精度相对较低,因为它为每个源实体(包括不匹配的实体)生成一个目标实体。这也反映了当存在无法对齐的源实体时当前 EA 解决方案的执行情况。但是,现有的 EA 数据集忽略了这个问题。
表 8 考虑不匹配实体后DBP-FB上的 EA 性能 
为了缓解这个问题,在当前的 EA 解决方案之上,我们提出了一种直观的策略来处理DBP-FB中不匹配的实体。具体来说,我们设置了一个 NIL 阈值 θ \theta θ来预测不匹配的实体。如第 3.3 节所述,EA 解决方案通常使用特定的距离度量来检索目标实体。如果源实体与其最近的目标实体之间的距离值大于 θ \theta θ,我们认为源实体是不可匹配的并且不为其生成对齐结果。阈值 θ \theta θ可以从训练数据中学习。
如表 8 所示,阈值增强解决方案CombEA + TH获得了更好的 F1 分数。我们希望这项初步研究能够启发对该问题的后续研究。
6 结论
EA 是整合 KG 以提高知识覆盖率和质量的关键步骤。尽管已经提出了许多解决方案,但对其性能的全面评价和详细分析却很少。为了填补这一空白,本文报告了对最先进方法在代表性数据集的有效性和效率方面的经验评价,深入分析了它们的性能,并提供了基于证据的讨论。此外,我们建立了一个新的数据集,以更好地反映未来研究的现实挑战。
就我们所处的位置,EA 可以被视为实体消解 (ER) 的一个特例,这让人想起一大批文献(将在第 2.2 节中讨论)。因此,本研究还涉及一些 ER 方法(为处理 EA 进行了轻微调整),以确保研究的全面性。 ↩︎
http://oaei.ontologymatching.org/ ↩︎
http://oaei.ontologymatching.org/2019/knowledgegraph ↩︎
可在计算机学会数字图书馆上找到,网址 http://doi.ieeecomputersociety.org/10.1109/TKDE.2020.3018741 。 ↩︎
在这项工作中,我们交替使用实体嵌入之间的距离和实体嵌入之间的相似度。 ↩︎
为了获取实体的名称,对于 DBpedia 和 YAGO,目前的方法直接采用标识符中的名称,而对于 Wikidata,它们使用实体标识符来检索相应的 Wikipedia 页面的名称。值得注意的是,这些来自不同 KG 的名称共享相同的命名约定。 ↩︎
用于重现的相关资料可见 https://github.com/DexterZeng/EAE ↩︎
为了篇幅,我们将详细的参数设置放在附录 A 中,可在在线补充材料中找到。 ↩︎
由于同样的原因,表 4 和表 5 中也缺少CEA的 Hits@10 和 MRR 结果。 ↩︎
AML需要本体信息,这在当前的 EA 数据集中不存在。因此,我们为这些 KG 挖掘本体信息。但是,我们只在SRPRS EN-FR _\text{EN-FR} EN-FR和SRPRS EN-DE _\text{EN-DE} EN-DE上成功运行了AML。 ↩︎
其他数据集上的结果表现出类似的趋势,由于空间原因不再赘述。 ↩︎