nuScenes数据集标注格式
文章目录
- 一、标注格式
- 二、一些基本的使用
-
- 1、官方接口数据初始化
- 2、数据遍历
- 3、NuScenes转Kitti
- 4、数据下载
Nuscenes自动驾驶数据集的标注非常全面,分为很多场景,每个场景都是一段20s视频拆帧之后的照片集。但同时标注也比较分散,划分了很多的数据表,每个表存为一个json文件,下面总结一下这些json文件的标注格式,还有训练、测试时的一些常见问题。
一、标注格式
很久没有更新过了,今天去官网看发现官方已经更新了数据结构和各个文件的组织关系,比之前版本要清晰的多,所以建议此部分直接移步官方数据标注说明。
官方提供的标注数据一共有15个json文件,下面我也结合官方给的数据格式,和自己实际应用的一些经验,按自己的思路总结一下,和官方一样,直接就按照json文件来说了:
1、category.json
这个json里面是所有出现在数据集中的物体的类别,文件内容如下图所示:

包含了三个key,分别是:
(1)token: 唯一标识;
(2)name:物体类别名称 ;
(3)description :类别详细描述。
其中物体类别一共有23类,涵盖了行人、汽车、楼房、动物等等,详细类别在这里。
2、attribute.json
描述了物体本身的一些状态,比如行驶、停下等等,内容如下图:

包含三个key,分别是:
(1)token :唯一标识;
(2)name :属性名称 ;
(3)description :属性详细描述。
其中属性一共有8种,每种属性的具体名称在这里
3、visibility.json
描述一个物体可视的程度,即被遮挡、截断的程度。在kitti中就是那两个遮挡、截断的数字,nuscences中用一个百分比来表示的,内容如下图:

包含三个key,分别是:
(1)token :唯一标识;
(2)level:可视化级别,是一个百分数,越高则越清晰,即识别越简单 ;
(3)description: 详细描述。一共有4个等级,分别是0到40%,40到60%,60到80%,80到100%。
4、instance.json
以实例为单位,记录某个实例出现的帧数、初始token、结尾token等,内容如下图:

包含5个key,分别是:
(1)token:唯一表示
(2)category_token:类别标识,可以找到category.json里的对应类别
(3)nbr_annotations:出现的数量,即该实例在此数据集一共出现了多少帧
(4)fist_annotation_token:第一帧的annotation标识,在sample_annonation.json里可以找到对应标注,下同
(5)last_annotation_token:最后一帧的annotation标识
5、sensor.json
保存所有传感器的数据表,包含一些简单的传感器类型,内容如下图:
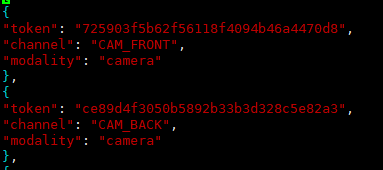
包含3个key,分别是:
(1)token:唯一标识;
(2)channel:位置;
(3)modality:类型(camera、lidar、radar)。
6、calibrated_sensor.json
一个比较大的数据表,存放了所有场景下相机的标注信息,包括了外参和内参。虽然说相机大部分场景下都是同一个,但是相机外参难免会发生微调,内参也会出现细微的变动,因此对于每一个照片,都有一个对应的相机标注,内容如下图:
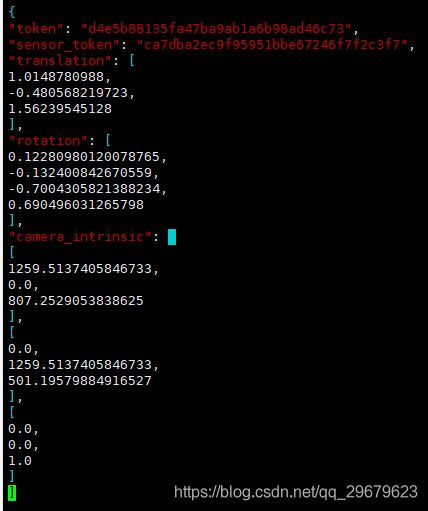
包含5个key,分别是:
(1)token:唯一标识;
(2)sensor_token:从sensor.json中对应得到相机类型;
(3)translation:相机外参,偏移矩阵,单位为米;
(4)rotation:相机外参,四元数旋转角;
(5)camera_intrinsic:相机内参(似乎只有camera会有)。
两个相机外参都是相对于ego,也就是相机所在车的坐标系的参数,即一个相对量,这里在ego_pose.json中还会提到。
7、ego_pose.json
相机所在车的标注信息,内容如下图:

包含4个key,分别是:
(1)token:唯一标识;
(2)timestamp:Unix时间戳,应该是保存数据表时候的一个时间戳,怀疑与图片名的后缀一一对应,没有详细考证;
(3)rotation:车辆外参,四元数旋转角;
(4)translation:车辆外参,偏移矩阵,单位为米。
ego车辆,还有照片中其他车辆(sample_annotation.json)的外参,参考坐标系是世界坐标系,世界坐标系的原点是lidar或radar定义的,没有什么规律,所以要求其他车辆的相机坐标系坐标,就需要在这三个外参(ego、camera、sample)换算一下,具体方法下面会讲。
8、log.json
一些场景、日期的日志信息,大部分情况没有太大作用,内容如下图:

包含5个key,分别是:
(1)token:唯一标识;
(2)logfile:日志文件;
(3)vehicle:车辆名称(咱也不知道是个啥);
(4)data_captured:拍摄日期;
(5)location:拍摄地点(新加坡和波士顿)。
9、scene.json
场景数据表,Nuscenes的标注集包括850段场景视频,每个场景20s,这个表标注了该场景的一些简单描述和出现的头尾车辆token,内容如下图:

包含7个key,分别是:
(1)token:唯一标识;
(2)log_token:日志token,从log.json索引出对应日志;
(3)nbr_samples:场景中出现的sample的数量,就是该场景下一共出现过多少个标注的物体,同一物体就算一次;
(4)first_sample_token:第一个sample的token,从sample.json中可以索引出唯一sample,下同;
(5)last_sample_token:场景下的最后一个sample;
(6)name:场景名;
(7)description:场景描述。
10、sample.json
照片的标注,以照片为单位,一张照片对应一个sample,内容如下:
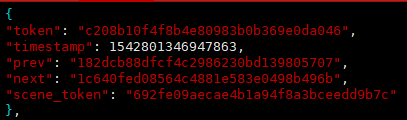
包含5个key,分别是:
(1)token,唯一标识;
(2)timestamp:时间戳;
(3)prev:上一张照片token;
(4)next:下一张照片的token;
(5)scene_token:场景标识,从scene.json中对应唯一场景。
11、sample_data.json
sample对应的简单信息,不包括标注,可以索引出同一个物体前后帧的信息,内容如下图:
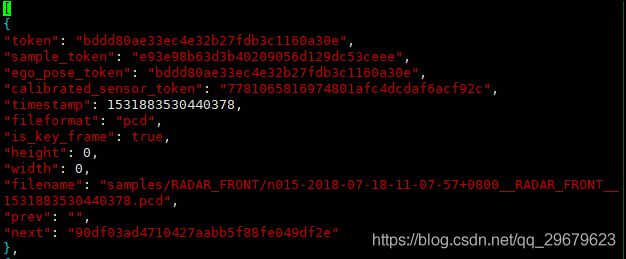
包含12个key,分别是:
(1)token:唯一标识;
(2)sample_token:可以从sample.json中索引出唯一对应的sample;
(3)ego_pose_token:对应的ego车辆的token,可以从ego_pose中索引出来,据我观察,1和3都是相同的;
(4)calibrated_sensor_token:可以从calibrated_sensor.json中索引出对应的相机外参和内参,3和4就对应索引出上文所说的ego和camera的外参,sample的外参并不在这个表里,而是在sample_annotation.json中,见下文;
(5)timestamp:时间戳;
(6)fileformat:文件格式,照片和雷达格式;
(7)is_key_frame:是否是关键帧,Nuscenes中,每秒两帧关键帧,提供标注信息;
(8)heihgt:照片像素高度,似乎只有jpg才会有,都是900;
(9)width:同上,像素宽度,都是1600;
(10)filename:照片名;
(11)prev:上一个sample_data的token,从本数据表中可以索引出对应的数据,是同一个物体的上一个标注,即上一次出现这个物体是在哪里,下同;
(12)next:下一个sample_data的token。
12、sample_annotation.json
保存了物体的标注信息,内容如下图:

包含了12个key,分别是:
(1)token:唯一标识;
(2)sample_token:从sample.json中索引出唯一对应的sample;
(3)instance_token:从instance.json中索引出唯一对应的instance;
(4)visibility_token:从visibility.json中索引出唯一对应的visibility;
(5)attribute_token:从attribute.json中索引出唯一对应的attribute;
(6)translation:物体外参,偏移矩阵,单位为米;
(7)size:物体大小,单位为米,顺序为宽、长、高;
(8)rotation:物体外参,四元数旋转矩阵;
(9)prev:同一个物体,上一帧标注的token,在本数据表中索引出唯一对应的标注信息,下同;
(10)next:下一帧的标注token;
(11)num_lidar_pts:bbox中出现的lidar点数量,下同;
(12)num_radar_pts:bbox中出现的radar点数量。
不是搞lidar或radar的,所以11和12这两个量并不是很懂,只知道测试的时候需要保证这两个至少有一个是非零的。
13、map.json
地图相关的一些标注信息,数据集的map文件夹里面会包括map的图片,内容如下图:

包含4个key,分别是:
(1)category:地图类别,似乎都是sematic的,因为提供的地图图片都是分割的,Nuscenes本身也包括了道路分割的数据集;
(2)token:唯一标识;
(3)filename:对应的地图文件名;
(4)log_tokens:地图中的日志文件。
14、image_annotations.json
这个表是没有出现在官方的标注格式说明中的,可以看出还是有一点冗余的,但是如果不用官方接口,自己写dataloader,还是很重要的,本表包括了2DBbox等信息,内容如下图:
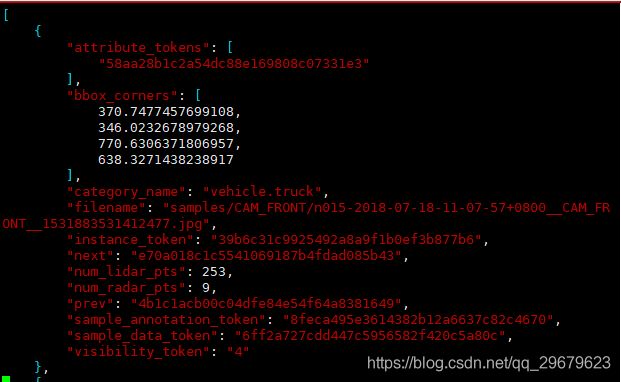
包含12个key,分别是:
(1)attribute_token:从attribute.json中索引出唯一对应的attribute;
(2)bbox_corners:2DBbox像素坐标,分别是x1,y1,x2,y2;
(3)category_name:类别名称(谢天谢地终于不用索引了);
(4)filename:图片名;
(5)instance_token:从instance.json中索引出唯一对应的instance;
(6)next:下一个物体的信息,这个应该是没有规律的,最多是按照顺序来依次记录每个出现的物体,通过这个文件可以遍历整个数据集中的所有物体;
(7)num_lidar_pts:bbox中出现的lidar点数量,下同;
(8)num_radar_pts:bbox中出现的radar点数量;
(9)prev:上一个物体,同6;
(10)sample_annotation_token:从sample_annotation.json中索引出唯一对应的sample_annotation;
(11)sample_data_token:从sample_data.json中索引出唯一对应的sample_data;
(12)visivility_token:从visibility.json中索引出唯一对应的visibility。
总结
Nuscenes数据集中存在很多token之间的互相引用跳转,要仔细看好token索引的到底是哪一个数据表,不然容易出错。
Nuscenes的数据表,总的来说感觉还是存在一些冗余的,如果要遍历所有数据,给两个思路,一个是通过image_annotations.json来遍历,一个是通过sample_data.json来遍历,似乎后者更好一些,因为官方的方法是通过sample_data。
另外,官方提供了一个pytorch的开发包来写dataloader,同时因为数据都是公开的,也完全可以自己写一个。博主实验之后发现自己写的dataloader效率可能比官方提供的包还要高一些(毕竟省去了一些不必要的初始化)但建议还是用官方的,更加标准同时也更加准确,因为不熟悉数据标注,我自己写的出了很多错误,特别是外参转换上。
二、一些基本的使用
官方提供了开发包,链接在这里,建议一定要看一下,或者直接看开发包的源码,源码在这里。
1、官方接口数据初始化
首先,运行pip install nuscenes-devkit下载安装开发包。
然后,运行如下程序
from nuscenes.nuscenes import NuScenes
nusc = NuScenes(version='v1.0-trainval', dataroot='/data/sets/nuscenes', verbose=True)
第一个参数是数据版本,可以根据自己的数据版本调整(比如v1.0-mini),第二个参数就是数据路径,第三个参数暂时不用管它。
2、数据遍历
要想遍历NuScenes数据集,加载内参外参,肯定是要取访问表12的。如前文所说,访问表12只能通过表14。这里提供有三种遍历方式,各有优缺点:
(1)直接遍历表14 image_annotation.json
官方没有提供这个表的接口,所以用这种方法就需要自己写dataloader了,手动加载所有json,保存下来,并且需要保存一些索引关系。
因为表中有sample_annotation_token这个key,所以可以直接得到对应物体的外参。相机参数也需要通过不同表格的不同token来互相索引得到。
优点:比较自由,可以根据自己想要的东西来写。
缺点:有点复杂,而且索引来索引去很容易出错。
(2)遍历表4 instance.json
这个表存放的是以实例为单位的记录,每个出现过的实例是一个元素。
优点:使用本表遍历的好处在于,可以使用官方的接口,并且instance表中记录了同一个物体的前后帧信息,如果需要上下文信息,用这种方式很方便。
缺点:仅限于训练,如果使用官方给的测试方法,则需要另写dataloader。另外,如果希望得到类似kitti那种一张照片对应一个标注文件格式,这种方法就非常麻烦了。
方式如下:
for instance in nusc.instance:
first_sample_annotation = nusc.get('sample_annotation',instance['first_annotation'])
last_sample_annotation = nusc.get('sample_annotation',instance['last_annotation'])
(3)遍历表10 sample.json
这个表是以图片为单位的,官方给出的测试方法也是以图片为单位进行测试,因此这种方法的优点就是测试方便,非常类似于kitti的标注使用。
方法如下:
for sample in nusc.sample:
for ann in sample['anns']:
sample_annotation = nusc.get('sample_annotation',ann)
3、NuScenes转Kitti
官方接口里也提供了NuSncenes数据集标注格式,转Kitti数据集标注格式的方法,在这里。另外,github上也有人把接口里的方法提取出来,单独写了一个文件,在github上搜Nuscenes就能搜到。
PS:NuScenes的数据标注格式和kitti差别还是很大的,因为NuScenes标注给出的外参坐标系不一致,切非相机坐标系,后面有时间会总结一下NuScenes标注转Kitti的具体方法。
4、数据下载
官网给提供了两部分数据集,一个是mini版主要用来熟悉数据集标注格式之类的,还有一个就是完整的数据集,如下图,把所有场景分了十个压缩包,每个压缩包里都包含了对应场景下的雷达、相机数据,使用的时候需要全部下载下来。可以单独下载关键帧数据,因为train、val的时候只会用到关键帧,这样需要下载的数据规模会小很多。

下载完以后,Linux系统下tar -zxvf解压,直接自动合并成一个sample文件夹,包括六路camera、四路Lidar和一个Radar,里面就是需要用到的数据了。